faster rcnn:towards real-time object detection with region proposal network
轻松掌握 MMDetection 中常用算法(二):Faster R-CNN|Mask R-CNN - 知乎文@ 0000070 前言在 轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解一文中,对经典 one-stage 目标检测算法 RetinaNet 以及相关配置参数进行了详细说明,本文解读经典 two-stage 算法 Faster R-CNN… https://zhuanlan.zhihu.com/p/349807581
https://zhuanlan.zhihu.com/p/349807581
faster-rcnn属于二阶段检测算法的经典之作了,非常值得一读,这次又读了一波原文,收获还是很多的。mmdet的代码分析写的非常好,结合起来看,基本问题不大。
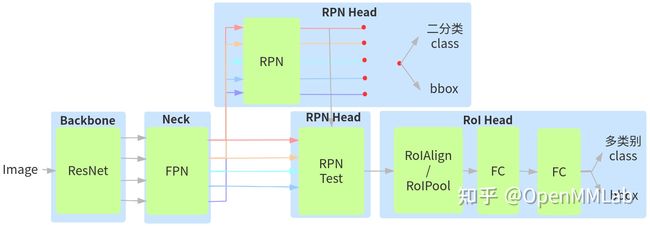
先看个基本流程图吧,如下:
1.Introduction
在卷积层后,通过添加一些卷积层构建了RPN,RPN是为了同时在each location on a regular grid(常规网络的每一个位置)上回归边界和目标的分数。
2.faster rcnn
faster rcnn有两个模块组成,第一个模块是生成proposal regions的fcn(RPN没有用到fc,是一个conv+reg-conv+cls-conv),第二个模块是用proposal region的fast rcnn的检测器(其实就是rcnn).
2.1 region proposal networks
This architecture is naturally implemented with an nxn convolutional layer followed by two sibling 1x1 convolutional layers (for reg and cls, respectively).一个conv后两个1x1conv。
2.1.1 anchors
faster rcnn首提anchor概念,后续检测才分了anchor-based和anchor-free,anchor是每个特征图上像素点对应的一个框,这个框是用来回归预测框的,在每个滑动窗口位置,我们同时预测多个region proposal,每个位置最大可能的数目为k,则reg layer有4k输出编码k个box的坐标,cls layer有2k分数,预测每一个proposal是否为目标。anchor位于滑动窗口的中心,和scale以及aspect ratio有关,默认使用3个scales和3个aspect ratio,每个位置产生9个anchor,对于一个W*H的特征图总共有W*H*k个anchor。
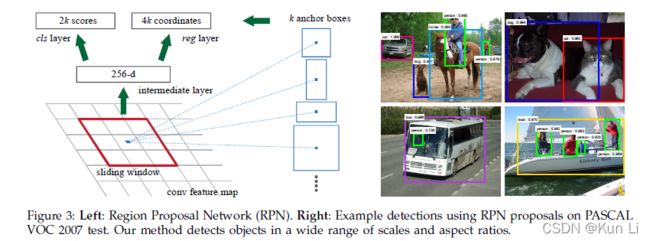
如上图所示,每个像素点都产生了anchor,不过现在的faster rcnn都是带fpn的,mmdet里面只有1个尺度,三个比例了,每个像素点产生3个anchor。这个在mmdet中代码为AnchorGenerator。
产生的anchor有什么用呢?Our method classifies and regresses bounding boxes with reference to anchor boxes of multiple scales and aspect ratios. 不同尺度和比例的anchor是用来分类和回归框的。也就是说anchor作为一种先验帮助model去和真实的gt监督学习。既然anchor用来回归和分类框,那么anchor就存在正负样本的采样和划分。
2.1.2 loss function
为了训练RPN,我们为每个anchor分配了一个二维标签(是目标或否)。这里划分anchor正负是有原则的,采用的是以Iou为标准,anchor和gt框Iou大于0.7,或者anchor和gt之间的有最大Iou的为正样本,可见一个gt框可能对应多个anchor,anchor和gt的Iou小于0.3的为负样本,两者之间的非正非负,不用,这块在mmdet中为MaxIoUAssigner,很多对anchor进行正负样本划分都是采样这个方法。带*是target,不带的是预测的。

cls和reg的损失都做了归一化,为了平衡两个损失,两个损失量级要差不多,不然的话很难收敛了,reg的损失还有一个lambda,cls是cross-entropy,reg是l1损失

边界框的回归为了辅助收敛也采用了一定的编码,带a下标的是anchor的,带*是gt box,不带的是预测的box。这也很常规,yolo也用了不一样的box编码,这个在mmdet中是DeltaXYWHBBoxCoder。
2.1.3 training RPNs
在faster rcnn中一方面是训练RPN,一方面还要调用RPN的前向过程生成RoI,为了实现联合训练,RPN不仅要自己进行训练,还要同时输出Roi,然后利用这些Roi输出的特征图上进行截取,最后输入给rcnn进行分类和回归。这里训练RPN存在一个正负样本采样的问题,前面已经对正负样本进行分配了,分配之后,正负样本很可能失衡,It is possible to optimize for the loss functions of all anchors, but this will bias towards negative samples as they are dominate.负样本可能会占据主导地位导致loss的偏差偏向负样本,怎么办呢?在图像中随机采样256个anchor来计算mini-batch中的损失,正负样本采样比例为1:1,如果图像中正样本少于128个,将小批量的负样本填充为0.这里在mmdet中代码为RandomSmper.
2.2 Implementation details
对于anchor,我们使用了vgg的三个特征图128,256,512的9个anchor,在训练时,忽略了cross-boundary的anchor,出界的anchor。对于1000*600图像,总共大约有20000(60*40*9)个anchor,由于忽略了跨界anchor,每个图像大约有6000个左右的anchor。
后面就是正常的rcnn部分,在mmdet中为Roi head,包括了SingleRoIExtractor中的RoIAlign,Roi pooling操作是必须的,为了将RPN提取的不同大小的Roi特征图组成batch输入到后面的rcnn中,在两者中添加的roi pooling,可以保证任意大小特征图输入都可以变成指定大小输出。最后是bbox head,包括了Shared2FCBBoxHead,两个共享的FC模块,之后再对xywh进行编码DeltaXYWHBBoxCoder,最后用loss监督,相当于两次做分类回归。这块有个问题,就是在做roi pooling之前要对RPN在不同特征图上检测出来的框做映射,要利用Roi重映射机制,将nms后的候选框重新到FPN输出的不同特征图上,提取对应的特征图,然后利用插值思想将其变成指定的固定大小输出。有个疑问?假设某个proposal是由4个特征图层检测出来的,为啥proposal不直接去对应的特征图切割就行,还需要重新映射?原因是这些proposal是RPN测试阶段检测出来的,大部分proposal符合前面设定,但是也有不符合的,也就是说测试阶段上述一致性不一定满足,需要重新映射。
到目前为止,我们经历了RPN中的AnchorGenerator,生来生成anchor,有了anchor之后要进行正负样本的分配,MaxIoUAssigner,分配了正负样本之后,并不是所有的负样本都用,那样损失会被负样本占据,因此训练时要做采样,RandomSamper,测试时没有这个问题,测试直接出2000个框,做了这些开始监督RPN训练,loss上对xywh进行编码的DeltaXYWHBBoxCoder,用了cross entropy和l1 loss,边训练边前向,此时RPN有前向的test的阶段,用nms产生1000个框,当然现在的faster rcnn都是配了FPN,实际上经过resnet之后,FPN之后,会有5张图的RPN,也就是产生了5个RPN的结果,目前是全都保留的。后面是正常的rcnn,对于rcnn,首先要去FPN的特征图中提取RPN检测出来的框,RPN前向推测出来的框要经过一个重新映射的过程,会存在FPN上的重新分配,拿到检测框之后,用Roi pooling进行裁剪,经过一个Shared2FCBBoxHead,此处要再次分类和回归,因此过程和RPN训练的过程基本一致的,正负样本分布,采样,xywh编码,loss监督,只是bbox的head和RPN的head是不一样的,RPN是fcn,是conv,bbox head是fc,最后测试都是nms输出。faster rcnn对输入尺寸是没有要求,只要wh是32的倍数,可以做特征提取的下采样就可以,RPN是fcn,rcnn有roi pooling,什么的尺寸输入都可以。
论文整体看来是非常经典的论文,理清rcnn的流程是很重要的。
mmdet中的R-50-FPN的pytorch形式的,在COCO的box ap为37.4.一些指标可以在paperwithcode上看到。
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | Papers With Code https://paperswithcode.com/paper/faster-r-cnn-towards-real-time-object
https://paperswithcode.com/paper/faster-r-cnn-towards-real-time-object