空间金字塔池化网络SPP-Net
文章目录
-
- 0x01概要介绍
- 0x02 SPP-Net
- 0x03 网络结构
-
- 1x01 卷积层和特征图
- 1x02 空间金字塔池层
- 0x04 训练网络
-
- 1x01 单一尺度训练——single-size
- 1x02 多尺寸训练——multi-size(以两种尺度为例)
- 0x05 Spp-Net在目标检测上的应用
0x01概要介绍
现有的深卷积神经网络(CNNs)需要一个固定大小(如224×224)的输入图像。这种要求是“人为的”,可能会降低对任意大小/比例的图像或子图像的识别精度。在这项工作中,我们为网络配备了另一种池策略“空间金字塔池”,以消除上述要求。这种新的网络结构称为SPP网,它可以生成一个固定长度的表示,而不考虑图像的大小/比例。金字塔池对对象变形也很健壮。有了这些优势,SPP网应该在总体上改进所有基于CNN的图像分类方法。
SPP-net使用单一的完整图像表示而不是精细的方法实现了最先进的分类结果-调音SPP网络的强大功能在目标检测中也很重要。利用SPP网络,我们只需计算一次来自整个图像的特征映射,然后将任意区域(子图像)的特征集合起来生成固定长度的表示,以训练检测器。该方法避免了重复计算卷积特征。在处理测试图像时,我们的方法比R-CNN方法快24-102倍
引出SPP-Net的原因:
在cnn的训练和测试中存在一个技术问题:目前流行的CNNs要求输入图像大小固定(如224×224),这既限制了输入的纵横比,也限制了输入的规模图像。什么时候对于任意大小的图像,当前的方法大多是将输入图像调整为固定大小,通过裁剪或通过翘曲,如图所示。但是裁剪区域可能不包含整个对象,而扭曲的内容可能会导致不需要的几何图形扭曲。识别由于内容丢失或失真,精度可能会受到影响。

为什么需要固定尺寸?
cnn主要由两部分组成:卷积层和随后的完全连接层。卷积层以滑动窗口方式操作,并输出表示激活的空间排列的特征图(图2)。事实上,旋转层不需要固定的图像大小,可以生成任何尺寸的特征图。另一方面,完全连接的层需要有固定大小/长度的定义输入。因此,固定大小约束仅来自完全连接层.
输入本文引入空间金字塔池(SPP)来取消网络固定规模约束
0x02 SPP-Net
我添加了最后一个卷积层上的SPP层。spp层将特征集合起来,生成固定长度的输出,然后输入到完全连接的层(或其他分类器)。换句话说,我们在网络层次结构的高级阶段(在进化层和完全连接层之间)执行一些信息“聚合”,以避免在开始。图1(底部)通过引入SPP层显示了网络体系结构的变化。我们称之为新的网络结构spp-net
SPP的优点
SPP对于深层CNN有几个显著的特性:1)SPP能够生成固定长度的输出,而不考虑输入大小,而以前的deepnetworks中使用的滑动窗口池[3]不能;2)SPP使用多级而滑动窗口池只使用单个窗口大小。多层池对物体变形具有很强的鲁棒性[15];3)由于输入尺度的灵活性,在可变尺度下提取的SPPcan池特征。实验表明,这些因素都提高了深层网络的识别精度。
SPP-net不仅可以从任意大小的图像/窗口生成测试的表示,而且还允许我们在训练期间提供不同大小或比例的图像。使用可变大小的图像进行训练可以提高尺度不变性并减少过拟合。我们开发了一种简单的多尺寸采集方法。当我们接受一个网络输入的单一变量时,我们使用一个固定的网络大小来训练它。在每一个纪元中,我们用一个给定的输入大小训练网络,然后切换到另一个输入大小来进行下一步操作。实验表明,这种多尺度训练与传统的单尺度训练一样收敛,具有更好的测试精度。
与R-CNN对对比:
R-CNN中的特征计算是非常耗时的,因为它反复地将深度卷积网络应用于每幅图像上数千个扭曲区域的原始像素。Spp-Net可以在整个图像上运行卷积层(不考虑窗口数),然后通过SPP网络在特征地图上提取特征。注意 在特征地图(而不是图像区域)上训练/运行探测器实际上是一个更流行的想法。 但SPP网络继承了CNN深层特征映射的强大功能,同时也继承了SPP在任意窗口大小下的灵活性,从而使SPP网络具有了卓越的精度和效率。在我们的实验中,基于SPP网络的系统(建立在CNN管道上)计算的特征比R-CNN快24-102倍,具有更好的或可比性准确。有SPP网络可以促进更深层和更大的各种网络.
0x03 网络结构
1x01 卷积层和特征图
考虑一下流行的七层架构,前五层是卷积的,其中一些是池层。这些池层也可以被认为是“卷积的”,因为它们使用的是滑动窗口。
最后的两层是完全连接的,以N路softmax作为输出,其中N是类别的数目。
上面描述的深度网络需要一个fixedimage大小。然而,我们注意到,固定尺寸的要求仅仅是由于完全连接的层需要固定长度向量作为输入。另一方面,卷积层接受轨道尺寸的输入。卷积层使用滑动过滤器,其输出与输入的aspectratio大致相同。这些输出被称为特征映射[1]——它们不仅涉及到响应的强度,而且涉及到它们的空间位置。
将一些特征地图可视化。它们是由conv5layer的一些过滤器生成的。图2(c)显示了ImageNet数据集中这些过滤器的最强激活图像。我们看到过滤器可以被一些语义内容激活。例如,第55个滤波器(图2,左下角)最易被圆形激活;第66个滤波器(图2,右上角)最易被∧形激活;第118个滤波器(图2,右下角)最易被a∨激活-形状。这些输入图像中的形状(图2(a))激活相应位置的特征映射(图2中的箭头)

生成图2中的featuremaps,而不需要固定输入大小。这些由深卷积层生成的特征映射与传统方法中的特征映射相似[27],[28]。在这些方法中,SIFT向量[29]或图像块[28]被密集地提取和编码,例如通过矢量量化、稀疏编码或费希尔核进行编码。这些编码的特征由特征映射组成,然后由词包(BoW)或空间金字塔集合。类似地,深卷积特征可以以类似的方式汇集在一起。
1x02 空间金字塔池层
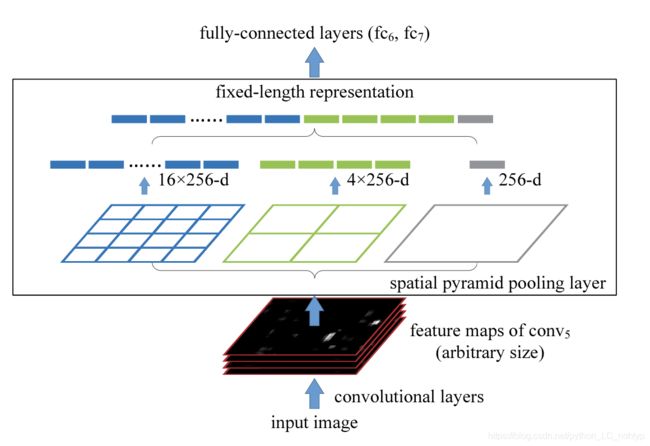
这样的向量可以通过单词包(BoW)方法生成,该方法将这些特征集合在一起。空间金字塔池[14],[15]改进了BoW,因为它可以通过在局部空间容器中的池来保持空间信息。这些空间存储单元的大小与图像大小成比例,因此无论图像大小,存储单元的数量都是固定的。这与以前的深层网络的滑动窗口池[3]不同,其中滑动窗口的数量取决于输入大小。到对于任意大小的图像采用深网络,我们将最后一个池层(例如,在最后一个卷积层之后的pool5)替换为aspatialpyramd池层。图3说明了方法。输入每一个空间单元,我们将每个滤波器的响应集中起来(在本文中我们使用最大池),空间金字塔池的输出是km维向量,其中格数表示为sm(kis是最后一个卷积层中的滤波器数)。固定维向量被输入到全连通层。
0x04 训练网络
Spp-Net的训练过程分为两部
1x01 单一尺度训练——single-size
所谓单一尺寸训练指的是先只对一种固定输入图像进行训练,比如224 x 224,在conv5之后的特征图为:13x13这就是我们的(a x a)而我要得到的输出为4 x 4,2 x 2,1 x 1,怎么办呢?这里金字塔层bins即为 n x n,也就是4 x 4,2 x 2,1 x 1,我们要做的就是如何根据a和n设计一个池化层,使得a x a的输入能够得到n x n的输出。实际上这个池化层很好设计,我们称这个大小和步幅会变化的池化层为sliding window pooling。
它的大小为:windows_size=[a/n] 向上取整 , stride_size=[a/n]向下取整。数据实验如下:
当a x a为13 x 13时,要得到4 x 4的输出,池化层的大小为4,移动步幅为3;
当a x a为13 x 13时,要得到2 x 2的输出,池化层的大小为7,移动步幅为6;
当a x a为13 x 13时,要得到1 x 1的输出,池化层的大小为13,移动步幅为13;
有的小伙伴一定发现,那如果我的输入a x a变化为10 x 10呢,此时再用上面的三个池化核好像得不到固定的理想输出啊,事实上的确如此,这是训练的第二个过程要讲的,因为此过程称之为“单一尺度训练”,针对的就是某一个固定的输入尺度而言的。
1x02 多尺寸训练——multi-size(以两种尺度为例)
虽然带有SPP(空间金字塔)的网络可以应用于任意尺寸,为了解决不同图像尺寸的训练问题,我们往往还是会考虑一些预设好的尺寸,而不是一些尺寸种类太多,毫无章法的输入尺寸。现在考虑这两个尺寸:180×180,224×224,此处只考虑这两个。
我们使用缩放而不是裁剪,将前述的224的区域图像变成180大小。这样,不同尺度的区域仅仅是分辨率上的不同,而不是内容和布局上的不同。
那么对于接受180输入的网络,我们实现另一个固定尺寸的网络。在论文中,conv5输出的特征图尺寸是axa=10×10。我们仍然使用windows_size=[a/n] 向上取整 , stride_size=[a/n]向下取整,实现每个金字塔池化层。这个180网络的空间金字塔层的输出的大小就和224网络的一样了。
当a x a为10 x 10时,要得到4 x 4的输出,池化层的大小为3,移动步幅为2(注意:此处根据这样的一个池化层,10 x 10的输入好像并得不到4 x 4的输出,9 x 9或者是11 x 11的倒可以得到4 x 4的)这个地方我也还不是特别清楚这个点,后面我会说出我的个人理解。
当a x a为10 x 10时,要得到2 x 2的输出,池化层的大小为5,移动步幅为5;
当a x a为10 x 10时,要得到1 x 1的输出,池化层的大小为10,移动步幅为10;
这样,这个180网络就和224网络拥有一样的参数了。换句话说,训练过程中,我们通过使用共享参数的两个固定尺寸的网络实现了不同输入尺寸的SPP-net。
为了降低从一个网络(比如224)向另一个网络(比如180)切换的开销,我们在每个网络上训练一个完整的epoch,然后在下一个完成的epoch再切换到另一个网络(权重保留)。依此往复。实验中我们发现多尺寸训练的收敛速度和单尺寸差不多。
多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。除了上述两个尺度的实现,我们也在每个epoch中测试了不同的s x s输入,s是从180到224之间均匀选取的。后面将在实验部分报告这些测试的结果。
注意,上面的单尺寸或多尺寸解析度只用于训练。在测试阶段,是直接对各种尺寸的图像应用SPP-net的。
0x05 Spp-Net在目标检测上的应用
SPP网络,这个方法的思想在R-CNN、Fast RCNN, Faster RCNN上都起了举足轻重的作用,对于检测算法,论文中是这样做到:使用ss生成~2k个候选框,缩放图像min(w,h)=s之后提取特征,每个候选框使用一个4层的空间金字塔池化特征,网络使用的是ZF-5的SPPNet形式。之后将12800d的特征输入全连接层,SVM的输入为全连接层的输出。这个算法可以应用到多尺度的特征提取:先将图片resize到五个尺度:480,576,688,864,1200,加自己6个。然后在map window to feature map一步中,选择ROI框尺度在{6个尺度}中大小最接近224x224的那个尺度下的feature maps中提取对应的roi feature。这样做可以提高系统的准确率。