轻量级卷积神经网络综述
inception
最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据,
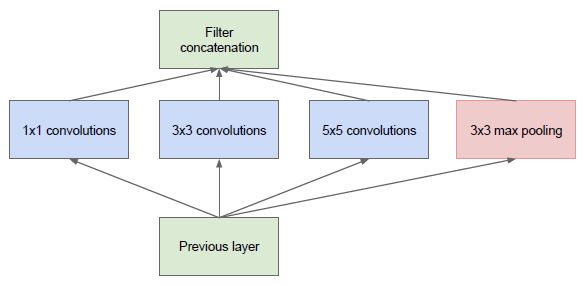
于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。
2.2 Pointwise Conv
为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如 Figure 2。
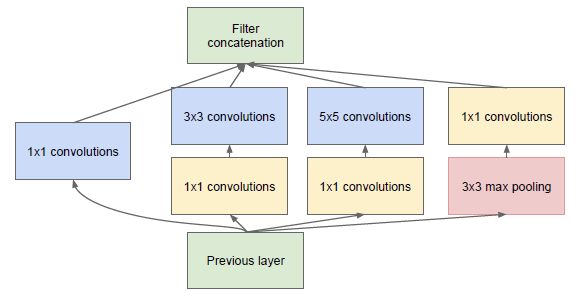
这个 1x1 卷积就是 Pointwise Convolution(逐点卷积),简称 PW。利用它的目的主要是为了减少维度,还用于引入更多的非线性。
我们来简单计算下:假定上一层输出的 feature map 维度为 100x100x128,经过256个大小为 5x5 的卷积后,输出的 feature map 大小为 100x100x256。这里卷积参数为 256∗5∗5∗128=819,200。而假如上一层的输出先经过 32 个大小为 1x1 的卷积后,再经过256个大小为 5x5 的卷积,那么输出维度保持不变的情况下,卷积参数减少为 128∗1∗1∗32 + 32∗5∗5∗256=204,800,降低为原来的1/4。
PW 主要用于数据降维,减少参数量。也有使用 PW 做升维的,在 MobileNet v2 中就使用 PW 将 feature map 的宽度扩张了6倍,丰富输入数据的特征。
2.3 Kernel Replace
Inception V2 和 V3 版本为了进一步降低卷积参数采用小卷积来替换大卷积,同 VGG 套路。
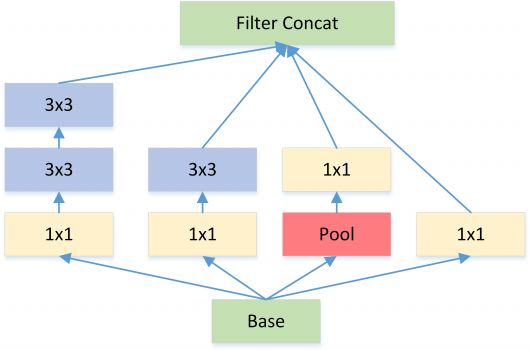
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如 5x5 卷积核的参数有 25 个,3x3 卷积核的参数有 9 个,前者是后者的 25/9=2.78 倍。因此,GoogLeNet 团队提出可以用 2 个连续的 3x3 卷积层组成的小网络来代替单个的 5x5 卷积层(为什么一个5*5的卷积核可以由两个3*3的卷积核替代),即在保持感受野范围的同时又减少了参数量。除了规整的的正方形,还有分解版本的 3x3 = 3x1 + 1x3,这个效果在深度较深的情况下比规整的卷积核更好(feature map 大小建议在 12 到 20 之间)。
2.4 Feature Map Downsample
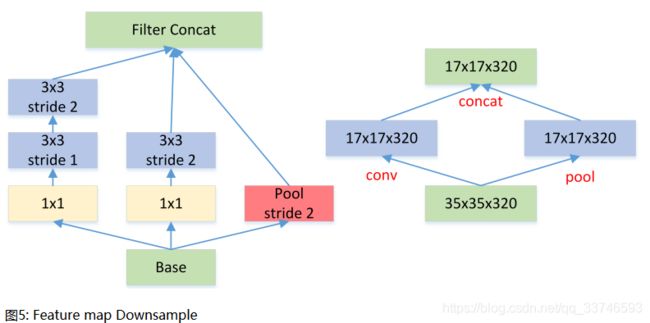
一般情况下,如果想让图像缩小,可以有如下两种方式:
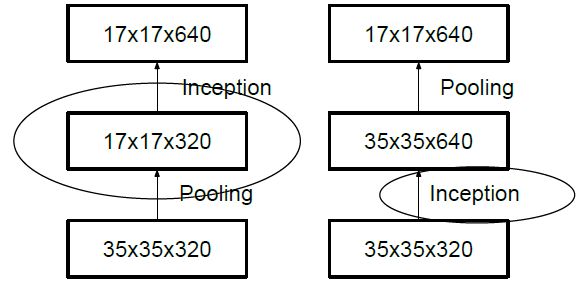
先 pooling 再作 Inception 卷积,或者先作 Inception 卷积再作 Pooling。前者先作 Pooling 会导致特征缺失遇到 bottleneck,后者则相对来说计算量更大。为了同时保持特征表示且降低计算量,将网络结构改为 Figure 5,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)。
2.5 Bottleneck
Bottleneck 三步走:先 PW 对数据进行降维,再进行常规卷积,最后 PW 对数据进行升维,形如沙漏。
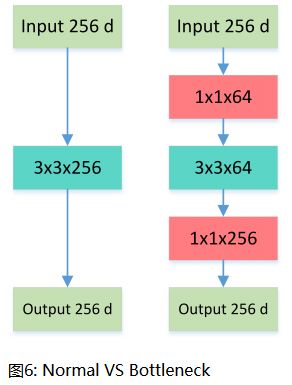
这就是所谓的 Bottleneck 结构,上图中后者的计算量 256∗1∗1∗64+64∗3∗3∗64+64∗1∗1∗256=69,632 远小于前者 256∗3∗3∗256=589,824。
2.6 Inception + ResNet
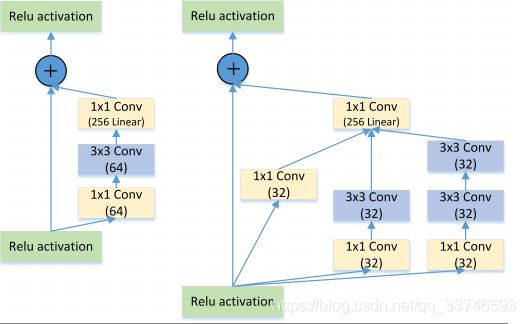
图7: Residual VS Residual+Inception
2.7 Group Conv Depthwise Separable Conv
Group Convolution 分组卷积,最早见于AlexNet,当时受限于硬件,Group Convolution被用来切分网络,使其在2个GPU上并行运行。 对于常规卷积,输入为 IxHxW 大小的 Input Features,经过 O 个 KxKxI 大小的卷积核后,输出 Output Features 的通道数也是 O。这里的卷积参数量为 O∗K∗K∗I,输入和输出 map 的连接方式如下图左所示,输出的每个通道都和输入的所有通道相关联:
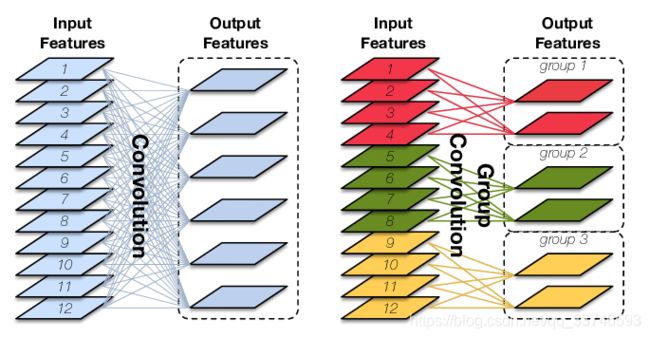
图8 标准卷积(左)和分组卷积(右)。后者通过将输入(和输出)分割成三个不相交的组来实现稀疏模式
Group Conv 顾名思义,则是对输入 feature map 进行分组,然后每组分别卷积。假设输入 feature map 的尺寸仍为 IxHxW,输出 Output Features 的通道数也是 O,如果设定要分成 G 个 groups,则每组的输入 feature map 数量为I/G,每组的输出 feature map 的数量为O/G,每个卷积核的尺寸为 KxKx1/G,每组卷积核的数量为N/G,每组的卷积核数量为 N/G,卷积核的总数仍为 O 个,卷积核只与其同组的输入 map 进行卷积,卷积核的总参数量为 O∗K∗K∗I/G,可见,总参数量减少为原来的 1/G.
其连接方式如上图右所示,group1 输出 map 数为 2,有 2 个卷积核,每个卷积核的 channel 数为 4,与 group1 的输入 map 的 channel 数相同,卷积核只与同组的输入 map 卷积,而不与其他组的输入 map 卷积。
Group Conv 的用途包括:
- 减少参数数量,分成 G 组,则该层的参数量减少为原来的 1/G
- Group Conv 可以看成是一种structured sparse
2.8 Summary
- 多个不同尺寸的卷积核,提高对不同尺度特征的提取。
- PW 卷积,降维或升维的同时,提高网络的表达能力。
- 多个小尺寸卷积核替代大卷积核,加深网络的同时减少参数量。
- Bottleneck 结构,大大减少网络参数量。
- DW 设计,再度减少参数量。
7. Xception
Xception 实际上就是从另一个角度来思考 Inception 的网络结构,同时在 Inception 的基础上将 Depthwise Separable Conv 发扬光大了!
7.1. The Inception Hypothesis
初始的 Inception V 1 结构考虑从多尺度卷积核角度来观察输入数据的特征,Inception V3 则是从参数量和计算量角度来尝试改进。但我们也可以把 Inception V3 结构理解为:通过显式地将操作分解为一系列独立的通道相关性和空间相关性的学习,从而使得学习的过程变得更加简单和高效。具体来说,Inception V1 里各个卷积核需要同时学习空间上的相关性和通道间的相关性,结合了 spatial dimensions 和 channels dimensions;而 Inception V3 结构,先通过一组 1x1 PW 卷积来学习通道相关性,将输入数据映射到多个单独的小空间(降维了),然后对于所有这些小空间,通过常规的 3×3 卷积,5×5 卷积等来学习空间相关性。因此,Inception 结构背后的基本假设是,通道相关性和空间相关性之间的耦合性已经充分分离,这样的话最好不要将它们联合起来学习。于是便有了 Xception:将通道相关性和空间相关性分开学习的结构设计。
7.2. Extreme Inception
在 Inception 中,特征可以通过 1×1 卷积,3×3 卷积,5×5 卷积,pooling 等进行提取,Inception 结构将特征类型的选择留给网络自己训练,也就是将一个输入同时输给几种提取特征方式,然后做 concat 。Inception-v3的结构图如下:
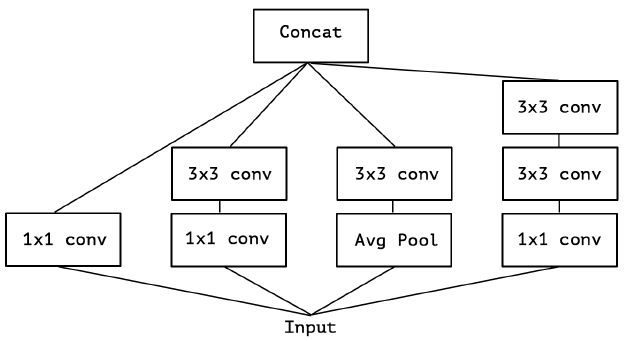
对 Inception-v3 进行简化,去除 Inception-v3 中的 avg pool 后,输入的下一步操作就都是 1×1 PW 卷积了:
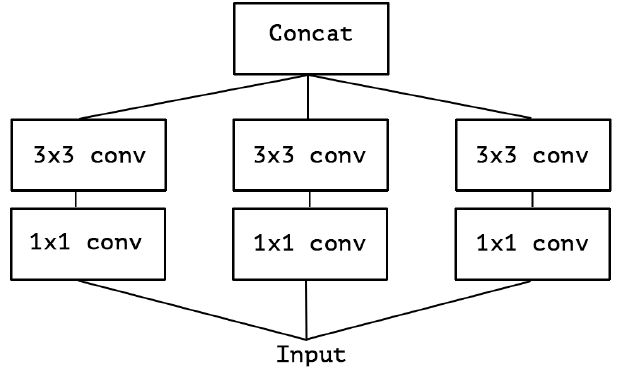
再进一步假设,3 个 PW 卷积核统一起来变成共用一个 PW 卷积,后面的三个 3x3 卷积核则分别”负责“一部分通道(Group Conv):
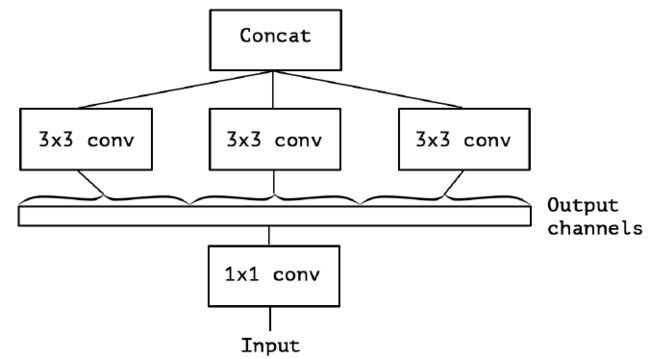
最后 Extreme Inception 闪亮登场,对 PW 卷积后的每个channel分别进行 3×3 卷积操作(Depthwise Conv, DW}),最后将结果 concat:
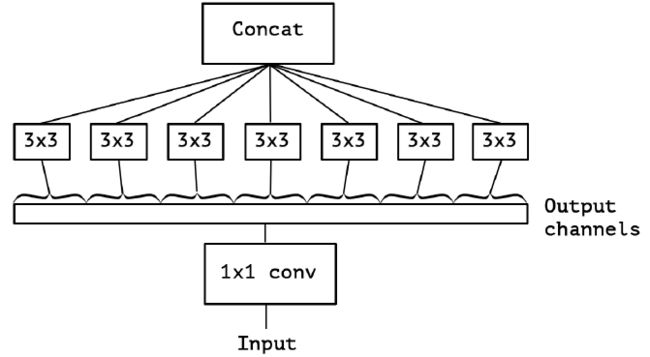
作者发现,在 Extreme Inception 模块中,用于学习空间相关性的 3×3 的 DW 卷积,和用于学习通道间相关性的 1×1 PW 卷积之间,不使用非线性激活函数时,收敛过程更快、准确率更高。