SVM详详详解
链接:https://www.zhihu.com/question/21094489/answer/86273196
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
@Han Oliver@Linglai Li 前辈们的解释让人受益许多。
正好最近自己学习机器学习,看到reddit上 Please explain Support Vector Machines (SVM) like I am a 5 year old 的帖子,一个字赞!于是整理一下和大家分享。(如有错欢迎指教!)
什么是SVM?
当然首先看一下wiki.
Support Vector Machines are learning models used for classification: which individuals in a population belong where? So… how do SVM and the mysterious “kernel” work?
好吧,故事是这样子的:
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
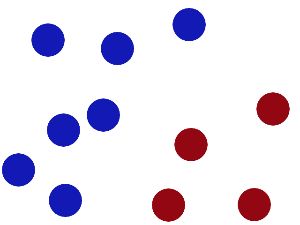
于是大侠这样放,干的不错?

然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
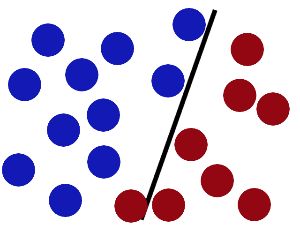
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。

现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。
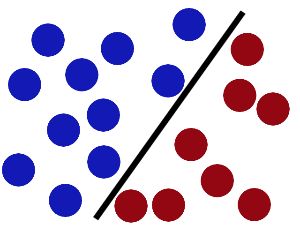
然后,在SVM 工具箱中有另一个更加重要的 trick。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。

现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
<img src="https://pic3.zhimg.com/50/55d7ad2a6e23579b17aec0c3c9135eb3_hd.jpg" data-rawwidth="300" data-rawheight="167" class="content_image" width="300">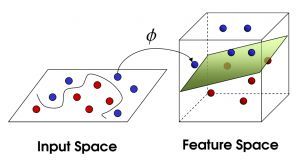
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。

再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
图片来源:Support Vector Machines explained well
直观感受看:https://www.youtube.com/watch?v=3liCbRZPrZA
 <img src="https://pic1.zhimg.com/50/dd8facea0b915fedf9c3690ce67f6cf8_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic1.zhimg.com/dd8facea0b915fedf9c3690ce67f6cf8_r.jpg">
<img src="https://pic1.zhimg.com/50/dd8facea0b915fedf9c3690ce67f6cf8_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic1.zhimg.com/dd8facea0b915fedf9c3690ce67f6cf8_r.jpg">  <img src="https://pic2.zhimg.com/50/c76fafd31978db1744e6286e276fe25b_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/c76fafd31978db1744e6286e276fe25b_r.jpg">
<img src="https://pic2.zhimg.com/50/c76fafd31978db1744e6286e276fe25b_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/c76fafd31978db1744e6286e276fe25b_r.jpg">  <img src="https://pic2.zhimg.com/50/71bd4dfd0a59b50fd1a06523dd281425_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/71bd4dfd0a59b50fd1a06523dd281425_r.jpg">
<img src="https://pic2.zhimg.com/50/71bd4dfd0a59b50fd1a06523dd281425_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/71bd4dfd0a59b50fd1a06523dd281425_r.jpg">  <img src="https://pic3.zhimg.com/50/169230b78232b9e73780174bae2afa86_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic3.zhimg.com/169230b78232b9e73780174bae2afa86_r.jpg">
<img src="https://pic3.zhimg.com/50/169230b78232b9e73780174bae2afa86_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic3.zhimg.com/169230b78232b9e73780174bae2afa86_r.jpg">  <img src="https://pic2.zhimg.com/50/c8f830648ec0a24419ff3c68e9b65484_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/c8f830648ec0a24419ff3c68e9b65484_r.jpg">
<img src="https://pic2.zhimg.com/50/c8f830648ec0a24419ff3c68e9b65484_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/c8f830648ec0a24419ff3c68e9b65484_r.jpg">  <img src="https://pic1.zhimg.com/50/19236d74e67a4e1ea804f6f4d47e8dcd_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic1.zhimg.com/19236d74e67a4e1ea804f6f4d47e8dcd_r.jpg">
<img src="https://pic1.zhimg.com/50/19236d74e67a4e1ea804f6f4d47e8dcd_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic1.zhimg.com/19236d74e67a4e1ea804f6f4d47e8dcd_r.jpg">  <img src="https://pic2.zhimg.com/50/c18864b0ecfe9bf8e9b8d6001b5bbf7c_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/c18864b0ecfe9bf8e9b8d6001b5bbf7c_r.jpg">
<img src="https://pic2.zhimg.com/50/c18864b0ecfe9bf8e9b8d6001b5bbf7c_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic2.zhimg.com/c18864b0ecfe9bf8e9b8d6001b5bbf7c_r.jpg">  <img src="https://pic1.zhimg.com/50/7c19253df763e678cd6377cbfdabc01f_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic1.zhimg.com/7c19253df763e678cd6377cbfdabc01f_r.jpg">
<img src="https://pic1.zhimg.com/50/7c19253df763e678cd6377cbfdabc01f_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic1.zhimg.com/7c19253df763e678cd6377cbfdabc01f_r.jpg">  <img src="https://pic3.zhimg.com/50/87aa4bb4e046b75e37f05b369304b58a_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic3.zhimg.com/87aa4bb4e046b75e37f05b369304b58a_r.jpg">
<img src="https://pic3.zhimg.com/50/87aa4bb4e046b75e37f05b369304b58a_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic3.zhimg.com/87aa4bb4e046b75e37f05b369304b58a_r.jpg">  <img src="https://pic4.zhimg.com/50/cc891d721ee902434f362821091bc496_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic4.zhimg.com/cc891d721ee902434f362821091bc496_r.jpg">
<img src="https://pic4.zhimg.com/50/cc891d721ee902434f362821091bc496_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic4.zhimg.com/cc891d721ee902434f362821091bc496_r.jpg">  <img src="https://pic3.zhimg.com/50/474312c10e1f681f3ff9f928aa59dfaa_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic3.zhimg.com/474312c10e1f681f3ff9f928aa59dfaa_r.jpg">
<img src="https://pic3.zhimg.com/50/474312c10e1f681f3ff9f928aa59dfaa_hd.jpg" data-rawwidth="2560" data-rawheight="1600" class="origin_image zh-lightbox-thumb" width="2560" data-original="https://pic3.zhimg.com/474312c10e1f681f3ff9f928aa59dfaa_r.jpg"> 
参考:
- Please explain Support Vector Machines (SVM) like I am a 5 year old. : MachineLearning
- Support Vector Machines explained well
- https://www.youtube.com/watch?v=3liCbRZPrZA

这篇答案贡献给想捋一捋SVM思路的看官。我的初衷是想直观地捋顺SVM的原理和求最优解,尽可能只用到必需的数学表达,但仿佛所有的数学推导都了然于胸。
先看思维导图:
- 左边是求解基本的SVM问题
- 右边是相关扩展

什么是SVM?
Support Vector Machine, 一个普通的SVM就是一条直线罢了,用来完美划分linearly separable的两类。但这又不是一条普通的直线,这是无数条可以分类的直线当中最完美的,因为它恰好在两个类的中间,距离两个类的点都一样远。而所谓的Support vector就是这些离分界线最近的『点』。如果去掉这些点,直线多半是要改变位置的。可以说是这些vectors(主,点点)support(谓,定义)了machine(宾,分类器)...
<img src="https://pic3.zhimg.com/50/00becdd15361c8e5ceb65da02bcf7fda_hd.jpg" data-caption="" data-rawwidth="1280" data-rawheight="880" class="origin_image zh-lightbox-thumb" width="1280" data-original="https://pic3.zhimg.com/00becdd15361c8e5ceb65da02bcf7fda_r.jpg">
所以谜底就在谜面上啊朋友们,只要找到了这些最靠近的点不就找到了SVM了嘛。
如果是高维的点,SVM的分界线就是平面或者超平面。其实没有差,都是一刀切两块,我就统统叫直线了。
怎么求解SVM?
关于这条直线,我们知道(1)它在离两边一样远,(2)最近距离就是到support vector,其他距离只能更远。
于是自然而然可以得到重要表达 I. direct representation:
,
subject to 所有 正确归类的苹果和香蕉到boundary的距离都
(可以把margin看作是boundary的函数,并且想要找到使得是使得margin最大化的boundary,而margin(*)这个函数是:输入一个boundary,计算(正确分类的)所有苹果和香蕉中,到boundary的最小距离。)
又有最大又有最小看起来好矛盾。实际上『最大』是对这个整体使用不同boundary层面的最大,『最小』是在比较『点』的层面上的最小。外层在比较boundary找最大的margin,内层在比较点点找最小的距离。
其中距离,说白了就是点到直线的距离;只要定义带正负号的距离,是{苹果+1}面为正{香蕉-1}面为负的距离,互相乘上各自的label ,就和谐统一民主富强了。
# ========== 数学表达 begin ========== #
# 定义直线为
# 任意点 到该直线的距离为
# UPDATE: 普通点到面的二位欧式距离写法应该是: (此处允许负数出现),如果升级到更高维度,是不是就和上一行一毛一样?
# 对于N个训练点的信息(点的坐标,苹果还是香蕉)记为
# 上述表达也就是[1]:
#
# 不知为何这是我见过的最喜欢的写法(比心)
# 也可以写成[2]:
#
subject to
# 就是为了表达方便[3],后面会取消这个限制
# ========== 数学表达 end ========== #
到这里为止已经说完了所有关于SVM的直观了解,如果不想看求解,可以跳过下面一大段直接到objective function。
直接表达虽然清楚但是求解无从下手。做一些简单地等价变换(分母倒上来)可以得到 II. canonical representation (敲黑板
subject to 所有苹果和香蕉到boundary的距离
w不过是个定义直线的参数,知道这一步是等价变换出来的表达就可以了。
# ========== 数学表达 begin ========== #
# 为了以后推导方便,一般写成:
#
subject to
# 这个『1』就是一个常数,这样设置是为了以后的方便
# 这个选择的自由来自于直线的参数如果rescale成和不改变距离。
# ========== 数学表达 end ========== #
要得到III. dual representation之前需要大概知道一下拉格朗日乘子法 (method of lagrange multiplier),它是用在有各种约束条件(各种"subject to")下的目标函数,也就是直接可以求导可以引出dual representation(怎么还没完摔)
# ========== 数学表达 begin ========== #
# 稍微解释一下使用拉格朗日乘子法的直观理解,不作深入讨论
# , 其中是橙子(划去)乘子[1]
# 可以这样想:(1) 我们的两个任务:①对参数最小化L(解SVM要求),②对乘子又要最大化(拉格朗日乘子法要求), (2) 如果上面的约束条件成立,整个求和都是非负的,很好L是可以求最小值的;(3) 约束条件不成立,又要对乘子最大化,全身非负的L直接原地爆炸
# 好棒棒,所以解题一定要遵守基本法
# ① 先搞定第一个任务对w,b最小化L
# 凸优化直接取导 => 志玲(划去)置零,得到:
#
# ② 第二个任务对a最大化L,就是dual representation了
# ========== 数学表达 end ========== #
稍微借用刚刚数学表达里面的内容看个有趣的东西:
还记得我们怎么预测一个新的水果是苹果还是香蕉吗?我们代入到分界的直线里,然后通过符号来判断。
刚刚w已经被表达出来了也就是说这个直线现在变成了:
看似仿佛用到了所有的训练水果,但是其中的水果都没有起到作用,剩下的就是小部分靠边边的Support vectors呀。
III. dual representation
把①的结果代回去就可以得到[1]:
subject to ,
如果香蕉和苹果不能用直线分割呢?
<img src="https://pic4.zhimg.com/50/242109e537a220855b33184a6f8de554_hd.jpg" data-caption="" data-rawwidth="1280" data-rawheight="880" class="origin_image zh-lightbox-thumb" width="1280" data-original="https://pic4.zhimg.com/242109e537a220855b33184a6f8de554_r.jpg">
Kernel trick.
其实用直线分割的时候我们已经使用了kernel,那就是线性kernel,
如果要替换kernel那么把目标函数里面的内积全部替换成新的kernel function就好了,就是这么简单。
高票答案武侠大师的比喻已经说得很直观了,低维非线性的分界线其实在高维是可以线性分割的,可以理解为——『你们是虫子!』分得开个p...(大雾)
如果香蕉和苹果有交集呢?
<img src="https://pic4.zhimg.com/50/ca45458396bf807868674316793205b7_hd.jpg" data-caption="" data-rawwidth="1280" data-rawheight="880" class="origin_image zh-lightbox-thumb" width="1280" data-original="https://pic4.zhimg.com/ca45458396bf807868674316793205b7_r.jpg">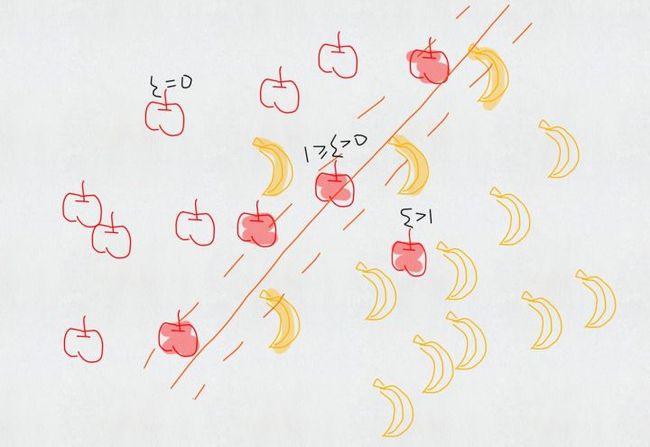
松弛变量 (slack variable )
松弛变量允许错误的分类,但是要付出代价。图中以苹果为例,错误分类的苹果;在margin当中但是正确分类的苹果;正确分类并且在margin外面的苹果。可以看出每一个数据都有一一对应的惩罚。
对于这一次整体的惩罚力度,要另外使用一个超参数 () 来衡量这一次分类的penalty程度。
从新的目标函数里可见一斑[1]:
(约束条件略)
如果还有梨呢?
<img src="https://pic1.zhimg.com/50/b3dec8344863f8e993abdf86cef4c856_hd.jpg" data-caption="" data-rawwidth="1280" data-rawheight="880" class="origin_image zh-lightbox-thumb" width="1280" data-original="https://pic1.zhimg.com/b3dec8344863f8e993abdf86cef4c856_r.jpg">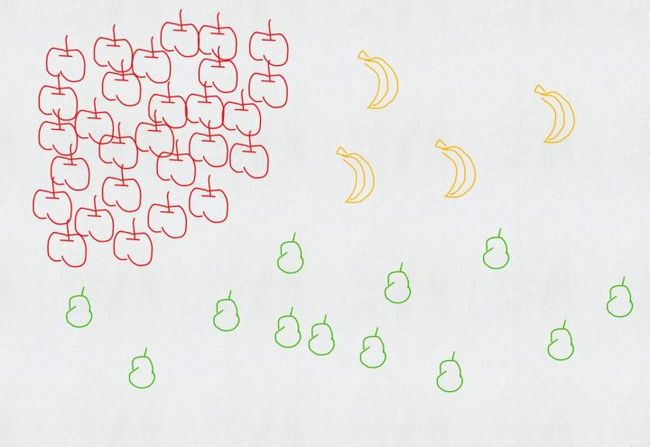
可以每个类别做一次SVM:是苹果还是不是苹果?是香蕉还是不是香蕉?是梨子还是不是梨子?从中选出可能性最大的。这是one-versus-the-rest approach。
也可以两两做一次SVM:是苹果还是香蕉?是香蕉还是梨子?是梨子还是苹果?最后三个分类器投票决定。这是one-versus-one approace。
但这其实都多多少少有问题,比如苹果特别多,香蕉特别少,我就无脑判断为苹果也不会错太多;多个分类器要放到一个台面上,万一他们的scale没有在一个台面上也未可知。
这时候我们再回过头看一下思维导图划一下重点:
<img src="https://pic3.zhimg.com/50/7e49cf765eb3680c85185bc30a9db196_hd.jpg" data-caption="" data-rawwidth="3085" data-rawheight="1280" class="origin_image zh-lightbox-thumb" width="3085" data-original="https://pic3.zhimg.com/7e49cf765eb3680c85185bc30a9db196_r.jpg">
课后习题:
1. vector不愿意support怎么办?
2. 苹果好吃还是香蕉好吃?
最后送一张图我好爱哈哈哈 (Credit: Burr Settles)
<img src="https://pic4.zhimg.com/50/a720d60ae40fd1612f4d458ca963ce66_hd.jpg" data-caption="" data-rawwidth="824" data-rawheight="734" class="origin_image zh-lightbox-thumb" width="824" data-original="https://pic4.zhimg.com/a720d60ae40fd1612f4d458ca963ce66_r.jpg">
[1] Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.
[2] Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.
[3] James G, Witten D, Hastie T, et al. An introduction to statistical learning[M]. New York: springer, 2013.

当处理文本分类问题时,你需要不断提炼自己的数据集,甚至会尝试使用朴素贝叶斯。在对数据集满意后,如何更进一步呢?是时候了解支持向量机(SVM)了:一种快速可靠的分类算法,可以在数据量有限的情况下很好地完成任务。在本文中,Bruno Stecanella 将对这一概念进行通俗易懂的解释,希望能对你有所帮助。
或许你已经开始了自己的探索,听说过线性可分、核心技巧、核函数等术语。支持向量机(SVM)算法的核心理念非常简单,而且将其应用到自然语言分类任务中也不需要大部分复杂的东西。在开始前,你也可以阅读朴素贝叶斯分类器指南,其中有很多有关文本处理任务的内容。链接:https://monkeylearn.com/blog/practical-explanation-naive-bayes-classifier/SVM 是如何工作的?支持向量机的基础概念可以通过一个简单的例子来解释。让我们想象两个类别:红色和蓝色,我们的数据有两个特征:x 和 y。我们想要一个分类器,给定一对(x,y)坐标,输出仅限于红色或蓝色。我们将已标记的训练数据列在下图中:
<img src="https://pic4.zhimg.com/50/v2-0afe453ebb001a2263d40cc7b51f7bd8_hd.jpg" data-rawwidth="560" data-rawheight="599" class="origin_image zh-lightbox-thumb" width="560" data-original="https://pic4.zhimg.com/v2-0afe453ebb001a2263d40cc7b51f7bd8_r.jpg">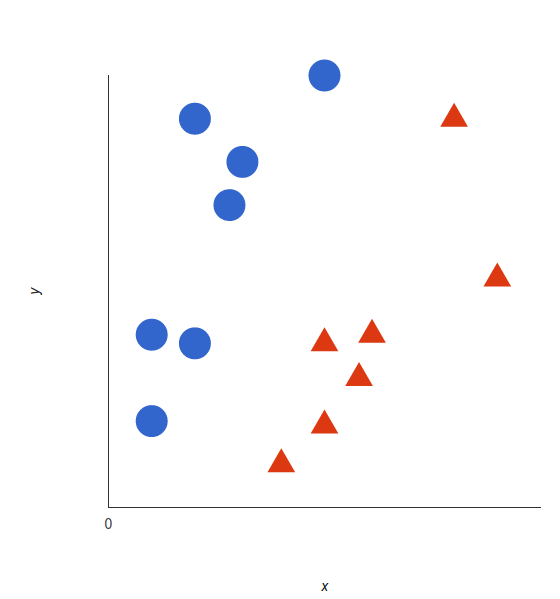
支持向量机会接受这些数据点,并输出一个超平面(在二维的图中,就是一条线)以将两类分割开来。这条线就是判定边界:将红色和蓝色分割开。
<img src="https://pic4.zhimg.com/50/v2-4f3314f5aa3d8bd7f9f918824e3bdc30_hd.jpg" data-rawwidth="560" data-rawheight="599" class="origin_image zh-lightbox-thumb" width="560" data-original="https://pic4.zhimg.com/v2-4f3314f5aa3d8bd7f9f918824e3bdc30_r.jpg">
但是,最好的超平面是什么样的?对于 SVM 来说,它是最大化两个类别边距的那种方式,换句话说:超平面(在本例中是一条线)对每个类别最近的元素距离最远。
<img src="https://pic3.zhimg.com/50/v2-c48093f2d83b60f64880723d88211a6f_hd.jpg" data-rawwidth="560" data-rawheight="599" class="origin_image zh-lightbox-thumb" width="560" data-original="https://pic3.zhimg.com/v2-c48093f2d83b60f64880723d88211a6f_r.jpg">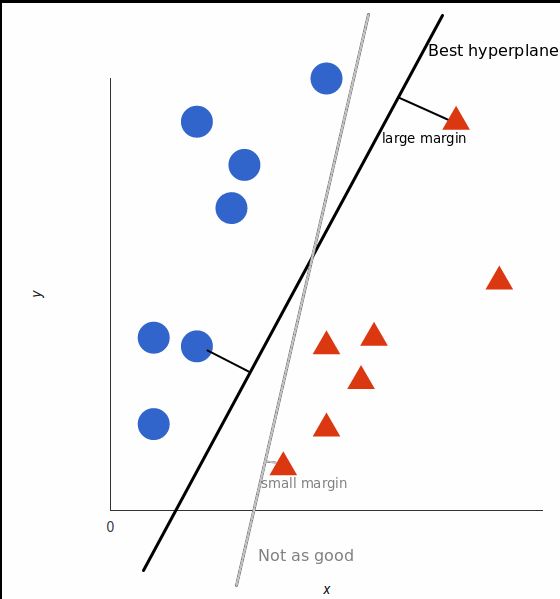
这里有一个视频解释可以告诉你最佳的超平面是如何找到的。

线性数据上面的例子很简单,因为那些数据是线性可分的——我们可以通过画一条直线来简单地分割红色和蓝色。然而,大多数情况下事情没有那么简单。看看下面的例子:
<img src="https://pic1.zhimg.com/50/v2-0b2611281abc149a0d75138f6017cabd_hd.jpg" data-rawwidth="657" data-rawheight="590" class="origin_image zh-lightbox-thumb" width="657" data-original="https://pic1.zhimg.com/v2-0b2611281abc149a0d75138f6017cabd_r.jpg">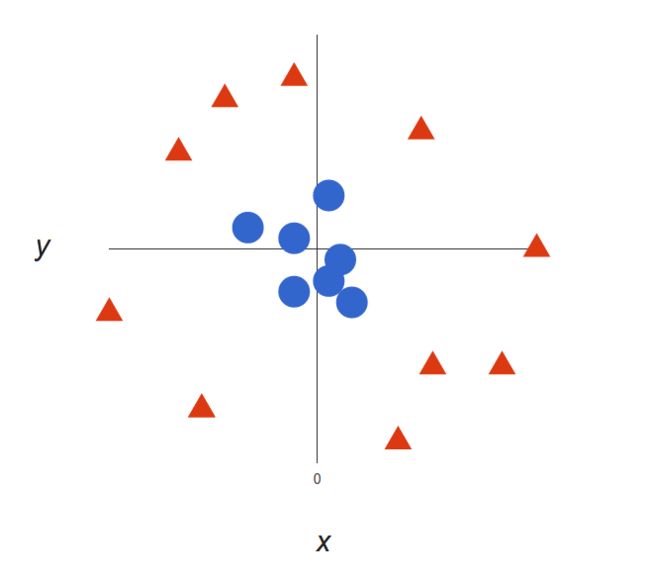
很明显,你无法找出一个线性决策边界(一条直线分开两个类别)。然而,两种向量的位置分得很开,看起来应该可以轻易地分开它们。这个时候我们需要引入第三个维度。迄今为止,我们有两个维度:x 和 y。让我们加入维度 z,并且让它以直观的方式出现:z = x² + y²(没错,圆形的方程式)于是我们就有了一个三维空间,看看这个空间,它就像这样:
<img src="https://pic3.zhimg.com/50/v2-74906b7384d94585efb8bde93159c52b_hd.jpg" data-rawwidth="635" data-rawheight="587" class="origin_image zh-lightbox-thumb" width="635" data-original="https://pic3.zhimg.com/v2-74906b7384d94585efb8bde93159c52b_r.jpg">
支持向量机将会如何区分它?很简单:
<img src="https://pic4.zhimg.com/50/v2-135a5454980145dbec044881e35bdd1b_hd.jpg" data-rawwidth="635" data-rawheight="587" class="origin_image zh-lightbox-thumb" width="635" data-original="https://pic4.zhimg.com/v2-135a5454980145dbec044881e35bdd1b_r.jpg">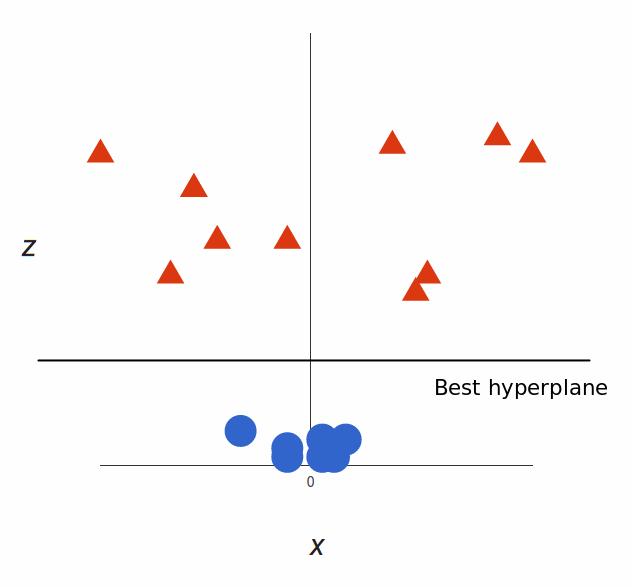
太棒了!请注意,现在我们处于三维空间,超平面是 z 某个刻度上(比如 z=1)一个平行于 x 轴的平面。它在二维上的投影是这样:
<img src="https://pic2.zhimg.com/50/v2-e4feb3baa85ccc75c62cb778049896c8_hd.jpg" data-rawwidth="657" data-rawheight="590" class="origin_image zh-lightbox-thumb" width="657" data-original="https://pic2.zhimg.com/v2-e4feb3baa85ccc75c62cb778049896c8_r.jpg">
于是,我们的决策边界就成了半径为 1 的圆形,通过 SVM 我们将其成功分成了两个类别。下面的视频用 3D 形式展现了一个类似的分类效果:
核函数技巧在以上例子中,我们找到了一种通过将空间巧妙地映射到更高维度来分类非线性数据的方法。然而事实证明,这种转换可能会带来很大的计算成本:可能会出现很多新的维度,每一个都可能带来复杂的计算。为数据集中的所有向量做这种操作会带来大量的工作,所以寻找一个更简单的方法非常重要。还好,我们已经找到了诀窍:SVM 其实并不需要真正的向量,它可以用它们的数量积(点积)来进行分类。这意味着我们可以避免耗费计算资源的境地了。我们需要这样做:想象一个我们需要的新空间:z = x² + y²找到新空间中点积的形式:a · b = xa· xb + ya· yb + za· zba · b = xa· xb + ya· yb + (xa² + ya²) · (xb² + yb²)让 SVM 处理新的点积结果——这就是核函数这就是核函数的技巧,它可以减少大量的计算资源需求。通常,内核是线性的,所以我们得到了一个线性分类器。但如果使用非线性内核(如上例),我们可以在完全不改变数据的情况下得到一个非线性分类器:我们只需改变点积为我们想要的空间,SVM 就会对它忠实地进行分类。注意,核函数技巧实际上并不是 SVM 的一部分。它可以与其他线性分类器共同使用,如逻辑回归等。支持向量机只负责找到决策边界。支持向量机如何用于自然语言分类?有了这个算法,我们就可以在多维空间中对向量进行分类了。如何将它引入文本分类任务呢?首先你要做的就是把文本的片断整合为一个数字向量,这样才能使用 SVM 进行区分。换句话说,什么属性需要被拿来用作 SVM 分类的特征呢?最常见的答案是字频,就像在朴素贝叶斯中所做的一样。这意味着把文本看作是一个词袋,对于词袋中的每个单词都存在一个特征,特征值就是这个词出现的频率。这样,问题就被简化为:这个单词出现了多少次,并把这个数字除以总字数。在句子「All monkeys are primates but not all primates are monkeys」中,单词 mokey 出现的频率是 2/10=0.2,而 but 的频率是 1/10=0.1。对于计算要求更高的问题,还有更好的方案,我们也可以用 TF-IDF。现在我们做到了,数据集中的每个单词都被几千(或几万)维的向量所代表,每个向量都表示这个单词在文本中出现的频率。太棒了!现在我们可以把数据输入 SVM 进行训练了。我们还可以使用预处理技术来进一步改善它的效果,如词干提取、停用词删除以及 n-gram。选择核函数现在我们有了特征向量,唯一要做的事就是选择模型适用的核函数了。每个任务都是不同的,核函数的选择有关于数据本身。在我们的例子中,数据呈同心圆排列,所以我们需要选择一个与之匹配的核函数。既然需要如此考虑,那么什么是自然语言处理需要的核函数?我们需要费线性分类器吗?亦或是数据线性分离?事实证明,最好坚持使用线性内核,为什么?回到我们的例子上,我们有两种特征。一些现实世界中 SVM 在其他领域里的应用或许会用到数十,甚至数百个特征值。同时自然语言处理分类用到了数千个特征值,在最坏的情况下,每个词都只在训练集中出现过一次。这会让问题稍有改变:非线性核心或许在其他情况下很好用,但特征值过多的情况下可能会造成非线性核心数据过拟合。因此,最好坚持使用旧的线性核心,这样才能在那些例子中获得很好的结果。为我所用现在需要做的就是训练了!我们需要采用标记文本集,使用词频将他们转换为向量,并填充算法,它会使用我们选择的核函数,然后生成模型。然后,当我们遇到一段未标记的文本想要分类时,我们就可以把它转化为向量输入模型中,最后获得文本类型的输出。结语以上就是支持向量机的基础。总结来说就是:支持向量机能让你分类线性可分的数据;如果线性不可分,你可以使用 kernel 技巧;然而,对文本分类而言最好只用线性 kernel。相比于神经网络这样更先进的算法,支持向量机有两大主要优势:更高的速度、用更少的样本(千以内)取得更好的表现。这使得该算法非常适合文本分类问题。
原文链接:An introduction to Support Vector Machines (SVM)

- SVM - support vector machine, 俗称支持向量机,为一种supervised learning算法,属于classification的范畴。
- 在数据挖掘的应用中,与unsupervised的Clustering相对应和区别。
- 广泛应用于机器学习(Machine Learning), 计算机视觉(Computer Vision) 和数据挖掘(Data Mining)当中。
&lt;img src="https://pic2.zhimg.com/50/c8c19796da24f8abfb6ef3a3e405254d_hd.jpg" data-rawwidth="485" data-rawheight="523" class="origin_image zh-lightbox-thumb" width="485" data-original="https://pic2.zhimg.com/c8c19796da24f8abfb6ef3a3e405254d_r.jpg"&gt;

图片引用自: wordpress.com 的页面
- 假设我们要通过三八线把实心圈和空心圈分成两类。
- 那么有无数多条线可以完成这个任务。
- 在SVM中,我们寻找一条最优的分界线使得它到两边的margin都最大。
- 在这种情况下边缘加粗的几个数据点就叫做support vector,这也是这个分类算法名字的来源。
拓展至任意n维乃至无限维空间,如图2,
&lt;img src="https://pic1.zhimg.com/50/11f3c70aec882ee99d81e6f077ca7f97_hd.jpg" data-rawwidth="300" data-rawheight="296" class="content_image" width="300"&gt;
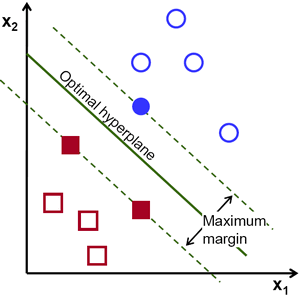 图片引用自OpenCV: Introduction to Support Vector Machines
图片引用自OpenCV: Introduction to Support Vector Machines
- We got a bunch of data points in a n- dimensional to infinite-dimensional space,
- Then one can always find a optimal hyperplane which is always in the n-1 dimension.
最后,
统计方向: Support Vector Machines (SVM)
wiki: Support vector machine
教程: columbia.edu 的页面
以及一个很棒的视频演示。自备梯.子。
http://youtu.be/3liCbRZPrZA

支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力(或称泛化能力)。
以上是经常被有关SVM 的学术文献引用的介绍,我来逐一分解并解释一下。
Vapnik是统计机器学习的大牛,这想必都不用说,他出版的《Statistical Learning Theory》是一本完整阐述统计机器学习思想的名著。在该书中详细的论证了统计机器学习之所以区别于传统机器学习的本质,就在于统计机器学习能够精确的给出学习效果,能够解答需要的样本数等等一系列问题。与统计机器学习的精密思维相比,传统的机器学习基本上属于摸着石头过河,用传统的机器学习方法构造分类系统完全成了一种技巧,一个人做的结果可能很好,另一个人差不多的方法做出来却很差,缺乏指导和原则。
所谓VC维是对函数类的一种度量,可以简单的理解为问题的复杂程度,VC维越高,一个问题就越复杂。正是因为SVM关注的是VC维,后面我们可以看到,SVM解决问题的时候,和样本的维数是无关的(甚至样本是上万维的都可以,这使得SVM很适合用来解决文本分类的问题,当然,有这样的能力也因为引入了核函数)。
结构风险最小听上去文绉绉,其实说的也无非是下面这回事。
机器学习本质上就是一种对问题真实模型的逼近(我们选择一个我们认为比较好的近似模型,这个近似模型就叫做一个假设),但毫无疑问,真实模型一定是不知道的(如果知道了,我们干吗还要机器学习?直接用真实模型解决问题不就可以了?对吧,哈哈)既然真实模型不知道,那么我们选择的假设与问题真实解之间究竟有多大差距,我们就没法得知。比如说我们认为宇宙诞生于150亿年前的一场大爆炸,这个假设能够描述很多我们观察到的现象,但它与真实的宇宙模型之间还相差多少?谁也说不清,因为我们压根就不知道真实的宇宙模型到底是什么。
这个与问题真实解之间的误差,就叫做风险(更严格的说,误差的累积叫做风险)。我们选择了一个假设之后(更直观点说,我们得到了一个分类器以后),真实误差无从得知,但我们可以用某些可以掌握的量来逼近它。最直观的想法就是使用分类器在样本数据上的分类的结果与真实结果(因为样本是已经标注过的数据,是准确的数据)之间的差值来表示。这个差值叫做经验风险Remp(w)。以前的机器学习方法都把经验风险最小化作为努力的目标,但后来发现很多分类函数能够在样本集上轻易达到100%的正确率,在真实分类时却一塌糊涂(即所谓的推广能力差,或泛化能力差)。此时的情况便是选择了一个足够复杂的分类函数(它的VC维很高),能够精确的记住每一个样本,但对样本之外的数据一律分类错误。回头看看经验风险最小化原则我们就会发现,此原则适用的大前提是经验风险要确实能够逼近真实风险才行(行话叫一致),但实际上能逼近么?答案是不能,因为样本数相对于现实世界要分类的文本数来说简直九牛一毛,经验风险最小化原则只在这占很小比例的样本上做到没有误差,当然不能保证在更大比例的真实文本上也没有误差。
统计学习因此而引入了泛化误差界的概念,就是指真实风险应该由两部分内容刻画,一是经验风险,代表了分类器在给定样本上的误差;二是置信风险,代表了我们在多大程度上可以信任分类器在未知文本上分类的结果。很显然,第二部分是没有办法精确计算的,因此只能给出一个估计的区间,也使得整个误差只能计算上界,而无法计算准确的值(所以叫做泛化误差界,而不叫泛化误差)。
置信风险与两个量有关,一是样本数量,显然给定的样本数量越大,我们的学习结果越有可能正确,此时置信风险越小;二是分类函数的VC维,显然VC维越大,推广能力越差,置信风险会变大。
泛化误差界的公式为:
R(w)≤Remp(w)+Ф(n/h)
公式中R(w)就是真实风险,Remp(w)就是经验风险,Ф(n/h)就是置信风险。统计学习的目标从经验风险最小化变为了寻求经验风险与置信风险的和最小,即结构风险最小。
SVM正是这样一种努力最小化结构风险的算法。
SVM其他的特点就比较容易理解了。
小样本,并不是说样本的绝对数量少(实际上,对任何算法来说,更多的样本几乎总是能带来更好的效果),而是说与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。
非线性,是指SVM擅长应付样本数据线性不可分的情况,主要通过松弛变量(也有人叫惩罚变量)和核函数技术来实现,这一部分是SVM的精髓,以后会详细讨论。多说一句,关于文本分类这个问题究竟是不是线性可分的,尚没有定论,因此不能简单的认为它是线性可分的而作简化处理,在水落石出之前,只好先当它是线性不可分的(反正线性可分也不过是线性不可分的一种特例而已,我们向来不怕方法过于通用)。
高维模式识别是指样本维数很高,例如文本的向量表示,如果没有经过另一系列文章(《文本分类入门》)中提到过的降维处理,出现几万维的情况很正常,其他算法基本就没有能力应付了,SVM却可以,主要是因为SVM 产生的分类器很简洁,用到的样本信息很少(仅仅用到那些称之为“支持向量”的样本,此为后话),使得即使样本维数很高,也不会给存储和计算带来大麻烦(相对照而言,kNN算法在分类时就要用到所有样本,样本数巨大,每个样本维数再一高,这日子就没法过了……)。
如果想要一楼的那种图解或者SVM在数据挖掘中的代码例程图,后续可更。
首先,SVM全称是supported vector machine(支持向量机)。我们先不管它的名称,因为这一开始并不是很好理解所谓的支持向量是什么。但是本质上,这就是一个分类器,并且是二类分类器。分类器我想答主一定是理解的吧,我就不赘述了,为什么是二类的分类器呢?因为它最多只能告诉你这个东西要么属于A要么属于B,不能告诉你要么属于A要么属于B要么属于C。
我举个例子吧,当你给SVM一段文本,比如“这款手机屏幕很大,我很喜欢”,你想知道这个文本的情感倾向是积极的还是消极的,你把这个文本扔给SVM分类器,SVM会告诉你说它的情感是积极的。但是现在我们多了一个选项,“中立”。你想让SVM告诉你这个文本是积极还是消极还是中立,这时候SVM就无能为力了。当然,有别的策略可以利用SVM处理多分类的问题,这个留到最后再说。
先开始说SVM的思想。如图的例子,(训练集)红色点是我们已知的分类1,(训练集)蓝色点是已知的分类2,我们想寻找一个分界超平面(图中绿线)(因为示例是二维数据点,所以只是一条线,如果数据是三维的就是平面,如果是三维以上就是超平面)把这两类完全分开,这样的话再来一个样本点需要我们预测的话,我们就可以根据这个分界超平面预测出分类结果。
&lt;img src="https://pic2.zhimg.com/50/4ad1fe7269db6fc2f0a29bd4df9e4003_hd.jpg" data-rawwidth="470" data-rawheight="477" class="origin_image zh-lightbox-thumb" width="470" data-original="https://pic2.zhimg.com/4ad1fe7269db6fc2f0a29bd4df9e4003_r.jpg"&gt;
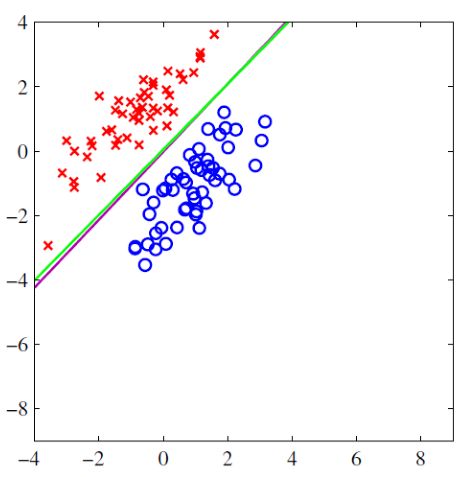
那我们如何选择这个分类超平面呢?从数学上说,超平面的公式是,也就是说如何选取这个(是个向量)。
传统方法是根据最小二乘错误法(least squared error),首先随便定选取一个随机平面,也就是随机选取和,然后想必会在训练集中产生大量的错误分类,也就是说,结果应该大于0的时候小于0,应该小于0的时候大于0。这时候有一个错误损失,也就是说对于所有错误的分类,他们的平方和(least squared error)为:, 最小二乘法的目标就是让这个值趋于最小,对求导取0,采用梯度下降算法,可以求出错误平方和的极值,求出最优的,也就是求出最优的超平面。(可以证明,如果基函数是指数族函数,求出的超平面是全局最优的)
那我们SVM算法的思路是怎样的呢?不同于传统的最小二乘策略的思想,我们采用一种新的思路,这个分界面有什么样的特征呢?第一,它“夹”在两类样本点之间;第二,它离两类样本点中所有“离它最近的点”,都离它尽可能的远。如图所示:
&lt;img src="https://pic1.zhimg.com/50/b21310bea4da968ae77bf0a24c8990d5_hd.jpg" data-rawwidth="357" data-rawheight="229" class="content_image" width="357"&gt;
 在虚线上的点,就是我们所找到的离分解超平面最近的样本点,X类中找到了一个,O类找到了两个。我们需要分类超平面离这三个样本点都尽可能的远,也就是说,它处在两条虚线的中间。这就是我们找到的分界超平面。
在虚线上的点,就是我们所找到的离分解超平面最近的样本点,X类中找到了一个,O类找到了两个。我们需要分类超平面离这三个样本点都尽可能的远,也就是说,它处在两条虚线的中间。这就是我们找到的分界超平面。另外,这里我们就可以解释什么是“支持向量”了,支持向量就是虚线上的离分类超平面最近的样本点,因为每一个样本点都是一个多维的向量,向量的每一个维度都是这个样本点的一个特征。比如在根据身高,体重,特征进行男女分类的时候,每一个人是一个向量,向量有两个维度,第一维是身高,第二维是体重。
介绍完SVM的基本思想,我们来探讨一下如何用数学的方法进行SVM分类。首先我们需要把刚刚说的最大间隔分类器的思想用数学公式表达出来。先定义几何间隔的概念,几何间隔就是在多维空间中一个多维点到一个超平面的距离,根据向量的知识可以算出来:
然后对于所有的支持向量,使他们到超平面的距离最大,也就是
因为对于所有支持向量,他们的值都是一定的,我们假设恒等于1,那么上式变成了,并且对于所有的样本点,满足的约束,因此,可以利用拉格朗日乘数法计算出它的极值。也就是求出这个超平面。
推导过程略为复杂,详细了解可以参考凸二次规划知识,结合SMO算法理解SVM计算超平面的详细过程。
总之,在计算的过程中,我们不需要了解支持向量以外的其他样本点,只需要利用相对于所有样本点来说为数不多的支持向量,就可以求出分类超平面,计算复杂度大为降低。

许多回答太理论了,如果仅针对题目而言,是个名词解释的问题:“支持向量机”为偏正结构,所以分别解释“支持向量”和“机”
(1) “机” —— Classification Machine,分类器,这个没啥好说的了。
(2) “支持向量” —— 现第一名的匿名用户已经用经典的图例解释了,在maximum margin上的这些点就叫支持向量,我想补充的是为啥这些点就叫支持向量,因为最后的classification machine的表达式里只含用这些“支持向量”的信息,而与其他数据点无关:


简介
掌握机器学习算法根本不难。大多数初学者从回归开始学习,虽然学习和使用它很简单,但是这能解决我们的目的吗?当然不能!因为你可以做的不仅仅是回归问题!
我们可以将机器学习算法看作是装满斧头、剑、刀片、弓、匕首等的军械库。你有各种工具,但你应该学会在正确的时间综合使用它们。
 综合使用之典范(误)
综合使用之典范(误)
作为一个类比,我们将“回归”看作一把能够有效切割数据的剑,但它无法处理高度复杂的数据。相反,支持向量机(SVM)算法就像一把锋利的刀 ——它可以在较小的数据集上工作,而在这些小数据集上面,在搭建模型时,它的性能却强大的多。
本文我们一起学习 SVM 机器学习算法从初级到高级的相关知识。示例+代码,一文搞定支持向量机算法。
目录
- 什么是 SVM 算法?
- SVM 算法是如何工作的 ?
- 如何在 Python 和 R 语言中实现 SVM?
- 如何调整 SVM 的参数?
- SVM 的优点和缺点
什么是 SVM 算法?
支持向量机(SVM) 是一个监督学习算法,既可以用于分类问题也可以用于回归问题。但是,SVM算法还是主要用在分类问题中。在 SVM 算法中,我们将数据绘制在 n 维空间中(n 代表数据的特征数),每个特征数的值是特定坐标的值。然后我们通过查找可以将数据分成两类的超平面(请参照下图)。

支持向量指的是观察的样本在 n 维空间中的坐标,SVM 是将样本分成两类的最佳超平面。
SVM 是如何工作的?
上面的简介告诉我们 SVM 是通过超平面将两类样本分开。现在我们的主要问题是:“如何将两类样本分开”。别担心,这个问题并不像你想象的那么难!
首先我们来看:
找出正确的超平面(场景-1):在这里,我们有三个超平面(A,B 和 C)。 现在,找出正确的超平面并用星和圆区分。

对于识别正确的超平面,你需要记住一条经验法则:“选择更好地隔离两个类的超平面”。在我们这里的例子中,超平面“B”非常出色地完成了这项工作。
找出正确的超平面(场景-2):在这里,我们有三个超平面(A,B 和 C),并且所有的类都被进行了很好的隔离。现在,我们如何确定正确的超平面?

在这里,最大化最近数据点(任一类)和超平面之间的距离将有助于我们决定正确的超平面。这个距离被称为边距。请看下图:

在上面,你可以看到,与 A 和 B 相比,超平面 C 的边距很大。因此,我们将这个正确的超平面命名为 C.另一个选择边距更大超平面的原因是鲁棒性更强。如果我们选择一个具有较低边距的超平面,那么很有可能会错误分类。
找出正确的超平面(场景-3):提示:使用上一节讨论的规则来找出正确的超平面。

可能有些朋友会选择超平面 B,因为它比 A 具有更高的边距。但是,这里有一个问题,SVM 算法在选择超平面方面,会优先考虑正确分类而非更大的边距。这里,超平面 B 有分类错误,而 A 已经正确分类。因此,A 才是正确的超平面。
我们能区分两个类别吗?(情景-4):下图中,我无法用一条直线将这两个类别分开,因为其中一个星星位于圈圈的领域之内,也就是离散值。
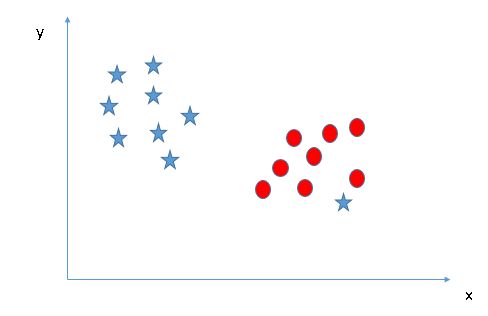
我之前提过,如果一个星跑到了另一边,那么它就是星类别的离散值。SVM 的一个特征就是会忽略离散值并找到具有最大边距的超平面。因此,我们可以说,SVM 对于离散值具有鲁棒性。
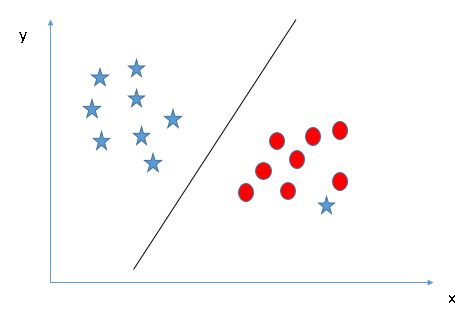
找到超平面以分离不同类(场景-5):在下面的场景中,我们没法让线性超平面区分这两个类,那么 SVM 如何对这两个类进行分类?到现在为止,我们只看到了线性超平面。
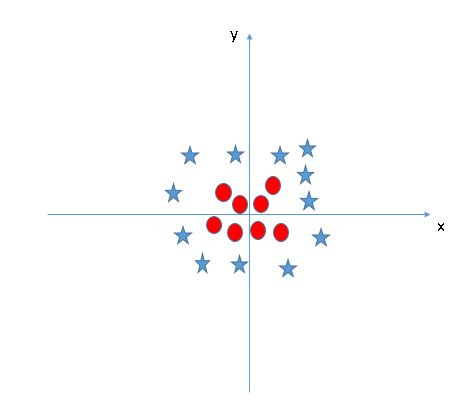
SVM 可以很方便的解决这个问题!它可以通过引入附加特征解决。在这里,我们增加一个新的 z=x^2+y^2 特征。现在,我们绘制轴 x 和 z 上的数据点:
在上面的情节中,要考虑的要点是:
- z 的所有值总是正值,因为它是是 x 和 y 的平方和。
- 在原始图中,红色点离 x 和 y 轴更近,z 值相对较小,星相对较远会有较大的 z 值。
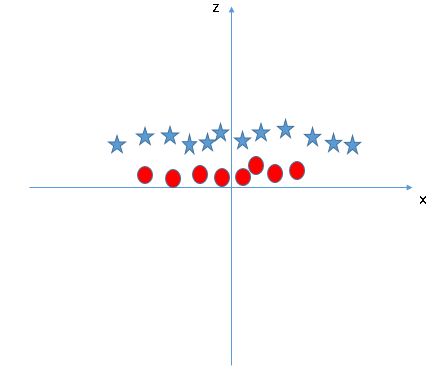
在 SVM 中,这两个类之间很容易有一个线性超平面。但是,另一个亟待解决的问题是,我们是否需要手动添加此功能才能拥有超平面?不需要,SVM 有一个叫核函数的功能。核函数具有将低维数据转化成高维数据的作用。它将不可分离的问题转换成可分离的问题,这些函数被称为内核。它主要用于非线性分离问题。简而言之,它执行一些非常复杂的数据转换,然后根据您定义的标签或输出找出分离数据的过程。
当我们在原始输入空间中查看超平面时,它看起来像一个圆圈:

现在,我们来看看在数据科学挑战中应用 SVM 算法的方法。
如何在 Python 和 R 语言中实现 SVM?
在 Python 中,scikit-learn 是一个在机器学习算法中被广泛使用的库,SVM 也可以在 scikit-learn 库中使用,并遵循相同的结构(导入库,对象创建,拟合模型和预测)。让我们来看下面的代码:
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc(kernel='linear', c=1, gamma=1)
# there is various option associated with it, like changing kernel, gamma and C value. Will discuss more # about it in next section.Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
使用 R 语言中的 e1071 软件包可以轻松创建 SVM。它具有辅助函数以及 Naive Bayes 分类器的代码。在 R 和 Python 中创建 SVM 遵循类似的方法,现在让我们来看看下面的代码:
#Import Library
require(e1071) #Contains the SVM
Train <- read.csv(file.choose())
Test <- read.csv(file.choose())
# there are various options associated with SVM training; like changing kernel, gamma and C value.
# create model
model <- svm(Target~Predictor1+Predictor2+Predictor3,data=Train,kernel='linear',gamma=0.2,cost=100)
#Predict Output
preds <- predict(model,Test)
table(preds)
如何调整 SVM 的参数?
为机器学习算法调整参数值有效地提高了模型性能。我们来看看 SVM 可用的参数列表。
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)
我们来讨论其中最重要的三个参数为: “kernel”, “gamma” 和“C”。
Kernel(核函数):我们已经在上面介绍过了。这里,我们有不少适用的选择,如“linear”,“rbf”,“poly”等等(默认值是“rbf”)。这里“rbf”和“poly”对于非线性超平面很有用。我们来看看这个例子,我们已经使用线性核函数对双特征鸢尾花数据集的两个特征进行了分类。
示例:使用线性核函数
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
# import some data to play with
iris = datasets.load_iris()
X = iris.data[:, :2] # we only take the first two features. We could
# avoid this ugly slicing by using a two-dim dataset
y = iris.target
# we create an instance of SVM and fit out data. We do not scale our
# data since we want to plot the support vectors
C = 1.0 # SVM regularization parameter
svc = svm.SVC(kernel='linear', C=1,gamma=0).fit(X, y)
# create a mesh to plot in
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1)
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()

示例:使用rbf核函数
将核函数类型更改为 rbf,并查看影响。
svc = svm.SVC(kernel='rbf', C=1,gamma=0).fit(X, y)

如果你有大量特征(> 1000),我建议选择线性核函数,因为它更有可能在高维空间中线性分离。此外,也可以使用 rbf,但不要忘记交叉验证其参数以避免过度拟合。
gamma:rbf 函数、Poly 函数和 S 型函数的系数。gamma 值越大,SVM 就会倾向于越准确的划分每一个训练集里的数据,这会导致泛化误差较大和过拟合问题。
例如:让我们区分一下,如果我们有不同的 gamma 值,如 0,10 或 100:
svc = svm.SVC(kernel='rbf', C=1,gamma=0).fit(X, y)

C: 错误项的惩罚参数 C。它还控制平滑决策边界和正确分类训练点之间的权衡。
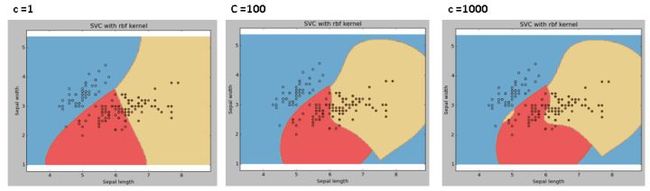
我们应该始终考虑交叉验证分数,以有效组合这些参数并避免过度拟合。
在 R 语言中,SVM 的参数可以像在 Python 中一样进行调整。下面提到的是 e1071 软件包中的相应参数:
内核参数可以调整为“线性”,“聚合”,“rbf”等。
Gamma 值可以通过设置“Gamma”参数进行调整。
Python 中的 C 值由 R 中的“Cost”参数进行调整。
SVM 的优点和缺点
优点:
- 对于边界清晰的分类问题效果好;
- 对高维分类问题效果好;
- 当维度高于样本数的时候,SVM 较为有效;
- 因为最终只使用训练集中的支持向量,所以节约内存
缺点:
- 当数据量较大时,训练时间会较长;
- 当数据集的噪音过多时,表现不好;
- SVM 不直接提供结果的概率估计,它在计算时直接使用 5 倍交叉验证。
实践练习
找到有效的附加特征,以便得到用于分离类的超平面,如下图所示:

在下面的注释部分回答变量名称。
结尾笔记
在本文中,我们详细介绍了机器学习算法 SVM,包括了它的工作概念,Python 中的实现过程,通过调整参数来优化模型的技巧,优点和缺点,以及最后的练习题。建议你亲自使用 SVM 并通过调整参数来分析该模型的功能。
集智主站出品的 Scikit-learn 教程也曾讲过如何用 SVM 算法解决问题: