项目:【Boost搜索引擎】
目录
- 功能和框架
- 技术栈和项目环境
- 具体实现代码结构
- 项目背景
- 搜索引擎的宏观原理
- 正排索引 倒排索引-搜索引擎具体原理
- 1、去标签 数据清理模块Parser
- 2、建立索引模块Index
- 3、搜索引擎模块 searcher
- 4、网络服务模块http-server
- 5、前后端交互及html页面模块
- 项目总结
- 项目特点和扩展
- 项目网站页面示例
项目源码:https://gitee.com/zhou-keren/boost-search-engine/tree/master/boost_searcher
项目网址:http://101.43.185.77:8081/
功能和框架
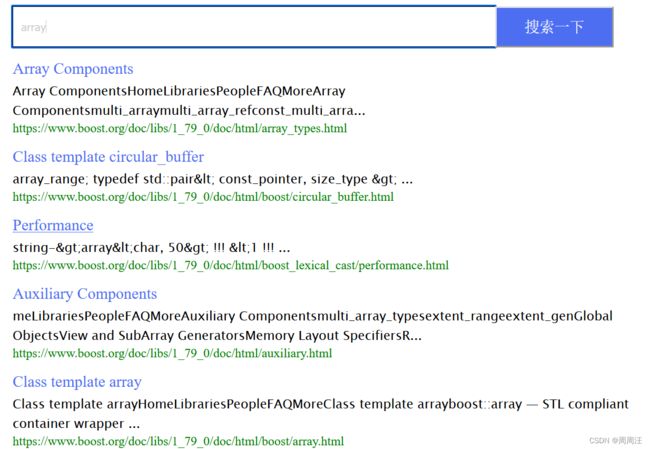
功能:实现boost文档站内搜索引擎,通过输入查询内容,将与查询内容有关文档的网页按该词的权值降序显示出来,包括标题、内容摘要和网页url,通过点击标题可直接跳转boost库网页进行文档阅读。
框架:

技术栈和项目环境
技术栈:
c/c++、c++11、STL、准标准库boost、Jsoncpp、cppjieba、cpp-httplib
项目环境:
Linux CentOS 7云服务器、vim/gcc(g++)/Makefile、vscode

具体实现代码结构

项目背景
目前市面上的搜索引擎不为少数,例如国内的:百度、搜狗、360;国外的:谷歌、火狐等等。那我们自己实现一个全网的像这样的搜索引擎是不太现实的,但是我们可以实现一个站内的【boost搜索引擎】。
简单介绍一下boost库:
Boost是为C++语言标准库提供扩展的一些C++程序库的总称。Boost库是一个可移植、提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一,是为C++语言标准库提供扩展的一些C++程序库的总称。
站内搜索的特点:搜索的数据更垂直,数据量相对较小,比如像cplusplus、boost库、甚至像你校内的网站。
并且boost库官网是没有站内搜索的,正好我们自己做一个。
我们先来看一下一个搜索引擎的画面都有什么功能,拿百度举例:
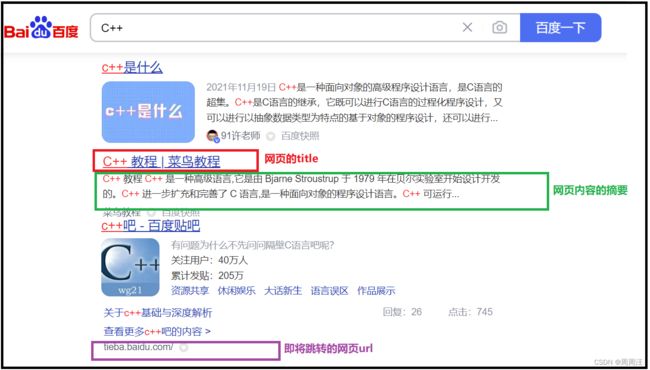
我们发现每条结果需要三部分组成:
网页的title、网页内容的摘要、即将跳转的网页url
当然你像百度,前几个还有广告。
我们的boost搜索引擎主要针对主要的这3部分。
搜索引擎的宏观原理

正排索引 倒排索引-搜索引擎具体原理
文档1:小明买了五斤苹果
文档2:小明发布了苹果手机
正排索引:就是由文档ID找到文档内容。
| 文档ID | 文档内容 |
|---|---|
| 1 | 小明买了五斤苹果 |
| 2 | 小明发布了苹果手机 |
对目标文档进行分词(目的:方便建立倒排索引和查找):
文档1:小明/买了/五斤/苹果/五斤苹果
文档2:小明/发布/了/苹果/手机/苹果手机
停止词:了、的、a、is…一般分词不考虑(最后分词结果去掉停止词)。
倒排索引:根据文档内容进行分词,整理不重复的各个关键字,对应联系到文档ID
| 关键字(具有唯一性) | 文档ID(weight权值) |
|---|---|
| 小明 | 文档1, 文档2 |
| 买 | 文档1 |
| 五斤 | 文档1 |
| 苹果 | 文档1, 文档2 |
| 五斤苹果 | 文档1 |
| 发布 | 文档2 |
| 苹果手机 | 文档2 |
模拟一次查找的过程:
用户输入:苹果->在倒排索引重查找->提取出文档ID(1、2)->再根据正排索引->找到文档内容->title+content+url->构建相应结果
1、去标签 数据清理模块Parser
具体见代码:https://gitee.com/zhou-keren/boost-search-engine/blob/master/boost_searcher/parser.cc
- 将boost库中的html网页下载到本地
src_path。 - 第一步:
EnumFile(src_path, &files_list)递归式的把每个html文件名带路径,保存到vector中,方便后期进行一个一个的文件进行读取。 - 第二步:
ParseHtml(files_list, &results)按照files_list读取每个文件的内容,并进行解析;按照DocInfo_t结构体格式(title、content、url)进行解析,将每一份解析出来的html对象,都保存到vector里。results - 第三步:
SaveHtml(results, output)把解析完毕的各个文件内容,写入到output文档中,按照\3作为单个文档的title content url分割符\n作为各个html文档之间的分隔符。
2、建立索引模块Index
具体见代码:https://gitee.com/zhou-keren/boost-search-engine/blob/master/boost_searcher/index.hpp
- 定义正排索引:
vector,倒排拉链:forward_index vector,倒排索引:InvertedList unordered_map。 - 构建索引
BuildIndex(const std::string &input)由正排索引和倒排索引构建索引。 - 创建正排索引:
BuildForwardIndex(const std::string &line),解析文档line,字符串切分Split(line, &results, sep),切分结果填充到结构体DocInfo里,最后插入到正排索引的vector。forward_index - 创建倒排索引:
BuildInvertedIndex(const DocInfo &doc),unordered_map用来暂存词频的映射表,对标题进行分词CutString(doc.title, &title_words),分词结果进行词频统计放入映射表,对文档内容进行分词CutString(doc.content, &content_words),分词结果进行词频统计放入映射表,然后计算权值,构建倒排拉链,最后添加到倒排索引unordered_map。 - 根据doc_id找到找到文档内容
GetForwardIndex(uint64_t doc_id),根据关键字string,获得倒排拉链GetInvertedList(const std::string &word)。
3、搜索引擎模块 searcher
具体见代码:https://gitee.com/zhou-keren/boost-search-engine/blob/master/boost_searcher/searcher.hpp
- 首先
InitSearcher(const string &input)完成初始化,GetInstance()创建索引index对象,index->BuildIndex(input)根据index对象建立索引。 - 根据用户输入的查询词进行搜索
Search(const string &query, string *json_string),首先对查询词进行分词CutString(query, &words),再根据分词结果的关键词触发倒排索引GetInvertedList(word),然后合并排序汇总查找结果,按照相关性权值(weight)降序排序sort,之后根据倒排索引的结果,拿到文档ID,通过ID索引到对应文档内容GetForwardIndex(item.doc_id),最终根据查找出来的结果,构建json串输出*json_string = writer.write(root)。
4、网络服务模块http-server
具体见代码:https://gitee.com/zhou-keren/boost-search-engine/blob/master/boost_searcher/http_server.cc
- 初始化搜索引擎模块
InitSearcher(input)。 - 构建http网络服务对象
httplib::Server svr。 - 设置默认网页根目录
svr.set_base_dir(root_path.c_str())。 - Get获取参数
svr.Get()。 - req获取请求的查询词
req.get_param_value("word")。 - 对查询词进行搜索
search.Search(word, &json_string)。 - rsp将结果输出
rsp.set_content(json_string, "application/json")。 - 服务器打开8081访问端口
svr.listen("0.0.0.0", 8081)。
5、前后端交互及html页面模块
具体见代码:https://gitee.com/zhou-keren/boost-search-engine/blob/master/boost_searcher/wwwroot/index.html
html实现网页结构骨架。css实现网页的美化。js中使用jQuery实现动态效果,ajax实现前后端交互。
项目总结
该项目实现了一个Boost搜索引擎,启动服务器,服务器先进行预处理,将boost库中html数据源进行去标签,解析出标题内容和url。然后根据预处理结果建立正排和倒排索引,服务器启动完毕。用户输入查询内容,服务器进行搜索,将查询内容进行分词,分词结果关键字触发索引找到结果,对结果根据权值的降序排序,最后拼装整合新的页面结果展现给用户,用户可以点击要查看的标题跳转到相关页面。
项目特点和扩展
- 该项目的数据源是boost库中doc下的html文件,该数据源是可以随意更换的,用什么数据源,它就是什么搜索引擎。
- 该数据源比较固定,可以实现一下在线更新的方案,比如通过爬虫技术,实时监视网页数据内容是否更新,当发现更新,运用操作系统信号知识,同步更新我们服务器上的数据源,当然我们不想因此让服务器关闭,所以可以使用多进程多线程的方案实现。
- 该项目会根据用户搜索的内容按关键词权值降序显示,也就是权值高的在最开始。所以我们可以在搜索引擎中添加竞价排名,也就是广告(比如百度),根据谁给的价格高,权衡质量品质,可以调整此广告的权值进行排序。
- 另外可以增加登录注册功能,从而引入mysql的使用。
项目网站页面示例