python-day9-Excel文件(.xlsx+.xls)读写操作
python-day9-Excel文件后缀名为xlsx的读写
一、使用OS模块读取文件名
(一)导入os模块用到的包-os
import os
(二)用listdir()方法
能够读取指定文件夹下的所有子文件。
file_list = os.listdir('./成都链家二手房数据')
print(file_list, type(file_list))
打印出来的效果:
[‘.ipynb_checkpoints’, ‘成都双流二手房信息.csv’, ‘成都大邑二手房信息.csv’, ‘成都天府新区二手房信息.csv’, ‘成都天府新区南区二手房信息.csv’, ‘成都崇州二手房信息.csv’, ‘成都彭州二手房信息.csv’, ‘成都成华二手房信息.csv’, ‘成都新津二手房信息.csv’, ‘成都新都二手房信息.csv’, ‘成都武侯二手房信息.csv’, ‘成都温江二手房信息.csv’, ‘成都简阳二手房信息.csv’, ‘成都蒲江二手房信息.csv’, ‘成都邛崃二手房信息.csv’, ‘成都郫都二手房信息.csv’, ‘成都都江堰二手房信息.csv’, ‘成都金堂二手房信息.csv’, ‘成都金牛二手房信息.csv’, ‘成都锦江二手房信息.csv’, ‘成都青白江二手房信息.csv’, ‘成都青羊二手房信息.csv’, ‘成都高新二手房信息.csv’, ‘成都高新西二手房信息.csv’, ‘成都龙泉驿二手房信息.csv’]
(三)获取该目录下所有后缀名为.csv的文件
遍历file_list
for i in file_list:
if i[-4:] == '.csv':
print(i)
打印结果:
成都双流二手房信息.csv
成都大邑二手房信息.csv
成都天府新区二手房信息.csv
成都天府新区南区二手房信息.csv
成都崇州二手房信息.csv
成都彭州二手房信息.csv
成都成华二手房信息.csv
成都新津二手房信息.csv
成都新都二手房信息.csv
成都武侯二手房信息.csv
成都温江二手房信息.csv
成都简阳二手房信息.csv
成都蒲江二手房信息.csv
成都邛崃二手房信息.csv
成都郫都二手房信息.csv
成都都江堰二手房信息.csv
成都金堂二手房信息.csv
成都金牛二手房信息.csv
成都锦江二手房信息.csv
成都青白江二手房信息.csv
成都青羊二手房信息.csv
成都高新二手房信息.csv
成都高新西二手房信息.csv
成都龙泉驿二手房信息.csv
二、Excel介绍
微软的Excel有两种后缀名:.xls、.xlsx
.xls: Excel2007以前的文件后缀名。最多容纳256列,16000+行数据。—>xlwt、xlrd
.xlsx: Excel 2007开始文件使用的后缀名。最多容纳16000+列,1048567行数据。—>openpyxl
Excel 2007开始兼容xls、xlsx后缀名。
python 能够操作Excel的模块:
openpyxl、xlsxwriter、xlwt、pandas、xlrd、win32com、xlutils等。
新版本xlsx: openpyxl。
旧版本xls: xlwt、xlrd。
三、第三方模块的安装-对xlsx操作
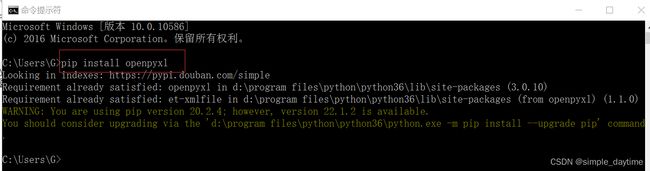
(一)可以使用cmd直接输入下面的命令
windows: pip install 第三方模块
mac、linux: pip3 install 第三方模块
(二)安装模块到虚拟环境
1.激活虚拟环境。
2.有(venv)则表示虚拟环境已激活。直接在>后面输入pip install openpyxl命令

3.没有的话 使用 .venv/scripts/activate 进行虚拟环境激活。
如果·报错:微软禁用了终端执行脚本的功能。
使用Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser解除禁用。
再次执行.venv/scripts/activate
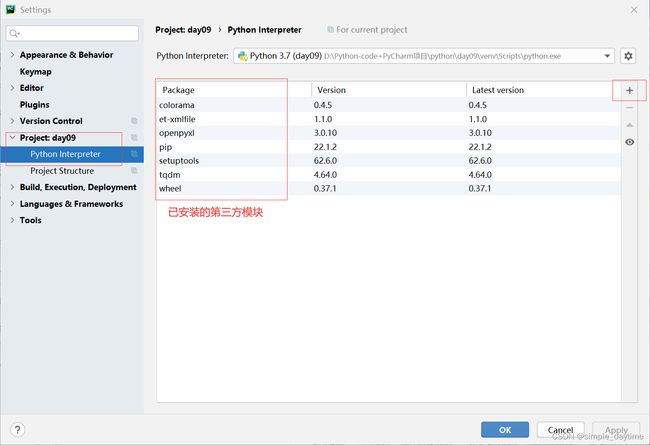
(三)点击pycharm界面
file->Settings
四、Excel文件后缀名.xlsx的写操作
工作簿:一个Excel文件就是一个工作簿。
工作表:一个工作簿的多张表格。
单元格:存储信息的方格
(一)首先导入安装的第三方模块
# 导入三方模块openpyxl 对应xlsx后缀名
import openpyxl
(二)新建一个Excel文件—工作簿
Workbook(): 新建文件
# 写.xlsx文件
# 1.新建一个excel文件--工作簿
# 新建文件:Workbook()
file = openpyxl.Workbook()
# 如果文件存在:openpyxl.load_workbook(文件路径和文件名)
(三)操作工作表
1.create_sheet(表名,下标)
create_sheet(表名,下标): 创建工作表对象。
# 2.操作工作表
# 创建工作表对象:create_sheet(表名, 下标)
# 如果直接在工作簿最后追加工作表,下标参数不用写。
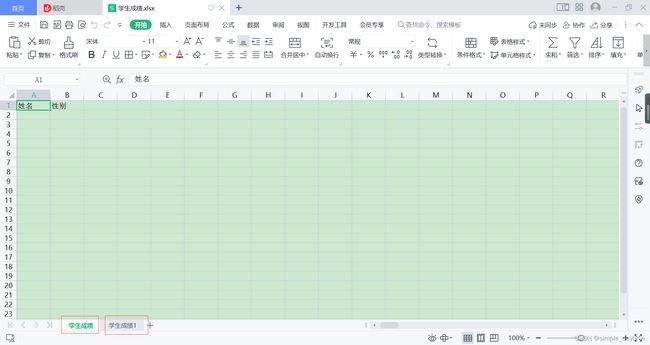
file.create_sheet('学生成绩', 0)
file.create_sheet('学生成绩1')
表格效果:

2.sheetnames
sheetnames: 查看工作表中已经存在的工作表。
# 查看工作簿中已经存在的工作表:sheetnames
print(file.sheetnames)
打印结果:
[‘学生成绩’, ‘Sheet’, ‘学生成绩1’]
3.remove(表)
remove(表): 移除工作表。表:工作簿对象[工作表]
# 移除工作表:remove(表)-->表:工作簿对象[工作表]
file.remove(file['Sheet'])
print(file.sheetnames)
结果:
[‘学生成绩’, ‘学生成绩1’]
4.插入信息
方法一:
使用cell(行号,列号)定位单元格。
value: 获取单元格的内容。
# 从学生成绩工作表插入信息
# 方法一:使用cell(行号, 列号)定位单元格
# cell(行号, 列号) ->定位单元格
# value:获取单元格的内容
print(file['学生成绩'].cell(1, 1).value)
file['学生成绩'].cell(1, 1).value = '姓名'
print(file['学生成绩'].cell(1, 1).value)
file['学生成绩'].cell(1, 2).value = '性别'
打印:
None
姓名
写入效果:
方法二:
使用[列号行号]定位单元格。
# 方法二:使用[列号行号]定位单元格
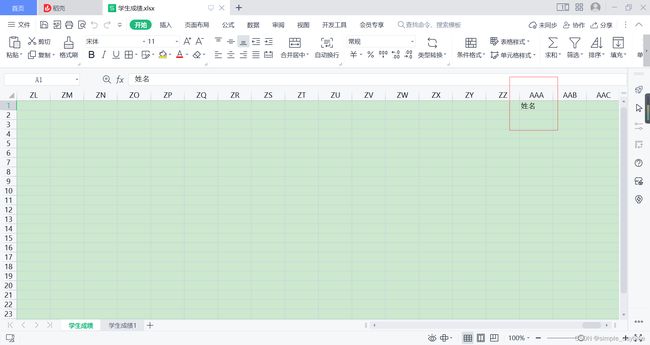
file['学生成绩']['AAA1'] = '姓名'
print(file['学生成绩']['AAA1'].value)
打印:
姓名
表格效果:
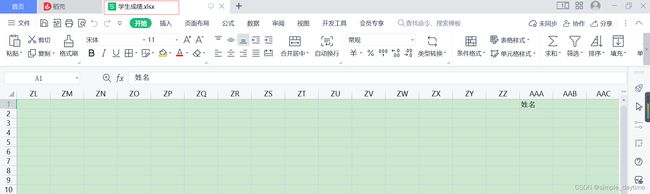
(四)保存文件并重命名文件
# 3.保存文件时才写创建的文件名字
file.save('./学生成绩.xlsx')
最后效果:
(五)总的代码
# 导入三方模块openpyxl 对应xlsx后缀名
import openpyxl
# 写.xlsx文件
# 1.新建一个excel文件--工作簿
# 新建文件:Workbook()
file = openpyxl.Workbook()
# 如果文件存在:openpyxl.load_workbook(文件路径和文件名)
# 2.操作工作表
# 创建工作表对象:create_sheet(表名, 下标)
# 如果直接在工作簿最后追加工作表,下标参数不用写。
file.create_sheet('学生成绩', 0)
file.create_sheet('学生成绩1')
# 查看工作簿中已经存在的工作表:sheetnames
print(file.sheetnames)
# 移除工作表:remove(表)-->表:工作簿对象[工作表]
file.remove(file['Sheet'])
print(file.sheetnames)
# 从学生成绩工作表插入信息
# 方法一:使用cell(行号, 列号)定位单元格
# cell(行号, 列号) ->定位单元格
# value:获取单元格的内容
print(file['学生成绩'].cell(1, 1).value)
file['学生成绩'].cell(1, 1).value = '姓名'
print(file['学生成绩'].cell(1, 1).value)
file['学生成绩'].cell(1, 2).value = '性别'
# 方法二:使用[列号行号]定位单元格
file['学生成绩']['AAA1'] = '姓名'
print(file['学生成绩']['AAA1'].value)
# 遍历加内容
# 3.保存文件时才写创建的文件名字
file.save('./学生成绩.xlsx')
五、Excel文件后缀名.xlsx读操作
(一)首先导入安装的第三方模块
# 导入三方模块openpyxl 对应xlsx后缀名
import openpyxl
(二)加载xlsx文件
# max_row
# max_col
# 加载xlsx文件
file = openpyxl.load_workbook('./成都链家二手房.xlsx')
# 从工作簿中找工作表
ws = file['成都链家二手房数据汇总']
(三)获取最大行和最大列
# max_row:获取xlsx文件中最大行数
rows = ws.max_row # 160283
# max_column:获取xlsx文件中最大列数
col = ws.max_column # 11
(四)遍历输出
# 行
for i in range(1, rows + 1):
# 列
for j in range(1, col + 1):
print(ws.cell(i, j).value)
会输出成都链家二手房数据汇总表里面的所有数据,由于数据量大,就不把结果放这里了,可以自己输出一个数据少的表。
(五)总的代码
import openpyxl
# max_row
# max_col
# 加载xlsx文件
file = openpyxl.load_workbook('./成都链家二手房.xlsx')
# 从工作簿中找工作表
ws = file['成都链家二手房数据汇总']
# max_row:获取xlsx文件中最大行数
rows = ws.max_row # 160283
# max_column:获取xlsx文件中最大列数
col = ws.max_column # 11
# 行
for i in range(1, rows + 1):
# 列
for j in range(1, col + 1):
print(ws.cell(i, j).value)
六、Excel文件后缀名为.xls写操作
(一)安装第三方模块:xlwt、xlrd
pip install xlwt xlrd

(二)导入第三方模块:xlwt-写
# 写操作
import xlwt
import random
(三)创建文件
add_sheet: 创建工作表+调用
# 创建文件
wb = xlwt.Workbook()
# add_sheet:创建工作表 + 调用;
sheet1 = wb.add_sheet('一年级一班成绩')
sheet2 = wb.add_sheet('一年级二班成绩')
sheet3 = wb.add_sheet('一年级三班成绩')
(四)写入数据
工作表.write(row, col, content)
# 写入数据 工作表.write(row, col, content)
names = ['张飞', '刘备', '关羽', '貂蝉', '曹操']
for i in range(len(names)):
# 写入学生名字
sheet1.write(i, 0, names[i])
# 从第二列开始
for j in range(1,4):
# 工作表.write(row, col, content)
sheet1.write(i, j, random.randint(0, 100))
(五)保存关闭
# 保存关闭
wb.save('一年级成绩表.xls')
(六)总的代码和写入效果
# 写操作
import xlwt
import random
# 创建文件
wb = xlwt.Workbook()
# add_sheet:创建工作表 + 调用;
sheet1 = wb.add_sheet('一年级一班成绩')
sheet2 = wb.add_sheet('一年级二班成绩')
sheet3 = wb.add_sheet('一年级三班成绩')
# 写入数据 工作表.write(row, col, content)
names = ['张飞', '刘备', '关羽', '貂蝉', '曹操']
for i in range(len(names)):
# 写入学生名字
sheet1.write(i, 0, names[i])
# 从第二列开始
for j in range(1,4):
# 工作表.write(row, col, content)
sheet1.write(i, j, random.randint(0, 100))
# 保存关闭
wb.save('一年级成绩表.xls')
表格效果:
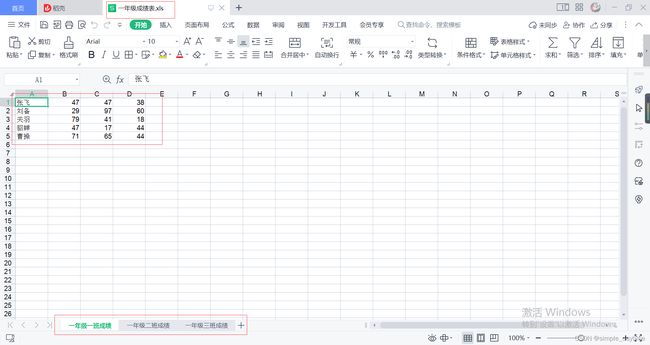
七、Excel文件后缀名为.xls读操作
(一)导入xlrd模块
import xlrd
(二)打开文件
# 打开文件
wb = xlrd.open_workbook('一年级成绩表.xls')
(三)获取数据
1.sheet_names():查看存在的所有工作表
2.sheet_by_index()
3.sheet_by_name()
4.获取行列数:nrows----获取最大行数;ncols----获取最大列数
# 选择工作表
# sheet_names():查看存在的所有工作表
print(wb.sheet_names())
# sheet_by_index()
ws = wb.sheet_by_index(0)
print(ws.cell(0, 0).value)
# sheet_by_name()
ws1 = wb.sheet_by_name('一年级一班成绩')
print(ws1.cell(0, 0).value)
# 获取行列数
# nrows:获取最大行数
# ncols:获取最大列数
print(ws1.nrows, ws1.ncols)
表是上一步创建的表。
输出:
[‘一年级一班成绩’, ‘一年级二班成绩’, ‘一年级三班成绩’]
张飞
张飞
5 4
八、csv文件数据写入xlsx
(一)导入需要用到的包
import os
import csv
import openpyxl
(二)新建工作簿和工作表用来存放数据
# 新建xlsx后缀文件
file = openpyxl.Workbook()
# 新建工作表
file.create_sheet('成都链家二手房数据汇总')
(三)读出csv文件里面的数据
先用os模块的listdir读出所有需要整合的数据文件。
遍历每一个文件用cell(行号,列号)方法写入xlsx文件。
行号 = 循环次数(每遍历一次获取一行数据)。
列号 = 每一行的长度,下标要加一,因为下标从0开始。
# 从源数据文件读数据
# listdir():能够读取指定文件夹下的所有子文件
file_list = os.listdir('./成都链家二手房数据')
print(file_list)
# count作用:计数进行行号的递增
count = 0
for i in file_list:
if i[-9:] == '二手房信息.csv' and i[:2] == '成都':
f = open(f'./成都链家二手房数据/{i}', 'r', encoding='utf-8')
read_data = csv.reader(f)
for j in read_data:
count += 1
for k in range(0, len(j)):
# print(k)
# 根据每一条数据长度判断写n列
file['成都链家二手房数据汇总'].cell(count, k + 1).value = j[k]
f.close()
(四)保存为xlsx文件
file.save('./成都链家二手房.xlsx')
print('数据写入完成!')
(五)总的代码
import os
import csv
import openpyxl
# 新建xlsx后缀文件
file = openpyxl.Workbook()
# 新建工作表
file.create_sheet('成都链家二手房数据汇总')
# --------------------------------------------------
# 从源数据文件读数据
# listdir():能够读取指定文件夹下的所有子文件
file_list = os.listdir('./成都链家二手房数据')
print(file_list)
# count作用:计数进行行号的递增
count = 0
for i in file_list:
if i[-9:] == '二手房信息.csv' and i[:2] == '成都':
f = open(f'./成都链家二手房数据/{i}', 'r', encoding='utf-8')
read_data = csv.reader(f)
for j in read_data:
count += 1
for k in range(0, len(j)):
# print(k)
# 根据每一条数据长度判断写n列
file['成都链家二手房数据汇总'].cell(count, k + 1).value = j[k]
f.close()
# -------------------------------------------
file.save('./成都链家二手房.xlsx')
print('数据写入完成!')
九、openpyxl和xlwt、xlrd对比
1.openpyxl行列号从1开始;xlwt、xlrd行列号从0开始
2.两者都可以对工作表进行操作。
3.两者都可以用单元格定位的形式进行单元格操作。
4.xlwt写操作使用过write()写