带你入门nodejs第一天——node基础语法及使用
带你入门nodejs第一天——node基础语法及使用
带你入门nodejs第二天——http 模块化 npm yarm
带你入门nodejs第三天—express路由
带你学习nodejs第四天——身份认证及缓存
1 node概述
为什么要学习node.js
为什么要学习服务端的开发?
- 通过学习Node.js开发理解服务器开发、Web请求和响应过程、 了解服务器端如何与客户端配合
- 作为前端开发工程师(FE )需要具备一定的服务端开发能力
- 全栈工程师的必经之路
服务器端开发语言有很多,为什么要选择nodejs
- 降低编程语言切换的成本(nodejs实质上用的还是javascript)
- NodeJS是前端项目的基础设施,前端项目中用到的大量工具 (大前端) webpack less-css
- nodejs在处理高并发上有得天独厚的优势
- 对于前端工程师,面试时对于nodejs有一定的要求
node.js是什么
node.js,也叫作node,或者nodejs,指的都是一个东西。
- node.js官方网站
- node.js中文网
- node.js 中文社区
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,nodejs允许javascript代码运行在服务端
1. nodejs不是一门新的编程语言,nodejs是在服务端运行javascript的运行环境
2. 运行环境:写得程序想要运行必须要有对应的运行环境
php代码必须要有apache服务器
在web端,浏览器就是javascript的运行环境
在node端,nodejs就是javascript的运行环境
2. javascript并不只是能运行在浏览器端,浏览器端能够运行js是因为浏览器有js解析器,
因此只需要有js解析器,任何软件都可以运行js。
3. nodejs可以在服务端运行js,因为nodejs是基于chrome v8的js引擎。
nodejs的本质:不是一门新的编程语言,nodejs是javascript运行在服务端的运行环境,编程语言还是javascript
简单归纳:
node.js包含的内容:
1. 有一个V8引擎 用来解析我们写好的js代码
2. 还有一些常用的模块 path fs http...
node官方团队发现有很多的功能代码人们都在频繁的使用,于是这将些相同的代码封装成了对应的模块
然后编译成二进制文件封装到node.js安装包中
3. 第三方模块
还有一些常用的功能或许没有来得及封装 别人将它封装好了存在了node第三方托管平台
node.js能做什么
- 用于做服务器端开发 web服务器
- 可以基于node构建一些工具,比如npm,webpack,gulp,less,sass等 vue-cli
- 开发桌面应用程序(借助 node-webkit、electron 等框架实现)
- 下载第三方模块或是包
node.js与浏览器的区别
相同点:
都可以运行js代码 都支持js的基本语法
不同点:
- node服务器端没有BOM和DOM功能
- 浏览器端是不能操作文件的 没有内置模块
思考:
- 在浏览器端,可以使用javascript操作文件么? 不可以
- 在nodejs端,可以使用BOM和DOM的方法么? 不可以
- 我们学习nodejs,学习什么内容?
2 下载安装node
下载与安装node.js
下载地址
- 当前版本
- 历史版本
官网术语解释
- LTS 版本:Long-term Support 版本,长期支持版,即稳定版。
- Current 版本:Latest Features 版本,最新版本,新特性会在该版本中最先加入。
查看node版本
node -v
运行node.js程序
- 创建js文件
helloworld.js - 写node.js的内容:
console.log('hello nodejs') - 打开命令窗口
cmd- shift + 右键打开命令窗口,输入
node 文件名.js回车即可 - 给vscode安装
terminal插件,直接在vscode中执行
- shift + 右键打开命令窗口,输入
- 执行命令:
node helloworld.js
注意:在nodejs中是无法使用DOM和BOM的内容的,因此document, window等内容是无法使用的。
3 node基础语法
fs模块
fs模块是nodejs中最常用的一个模块,因此掌握fs模块非常的有必要,fs模块的方法非常多,用到了哪个查哪个即可。
文档地址:http://nodejs.cn/api/fs.html
在nodejs中,提供了fs模块,这是node的核心模块
注意:
- 除了global模块中的内容可以直接使用,其他模块都是需要加载的。
- **fs模块不是全局的,不能直接使用。**因此需要导入才能使用。
const fs = require("fs");
读取文件
语法:fs.readFile(path[, options], callback)
方式一:不传编码参数
//参数1: 文件的名字
//参数2: 读取文件的回调函数
//参数1:错误对象,如果读取失败,err是一个错误对象,包含错误信息,如果文件读取成功,err是null
//参数2:读取成功后的数据(是一个Buffer对象)成功则是读取到的数据 失败则是undefined
fs.readFile("data.txt", (err, data)={
console.log(err);
// console.log(data);
console.log(data.toString()); //将Buffer对象容器中的数据转换成字符串
});
方式二:传编码参数
//参数1: 文件的路径
//参数2: 编码,如果设置了,返回一个字符串,如果没有设置,会返回一个buffer对象
//参数3: 回调函数,有两个参数err data
fs.readFile("data.txt", "utf-8",(err, data)=>{
console.log(err);
console.log(err.message) //message是error对象的一个属性 存储错误信息
console.log(data);
});
关于Buffer对象:
1. Buffer对象是Nodejs用于处理二进制数据的。
2. 其实任意的数据在计算机底层都是二进制数据,因为计算机只认识二进制。
3. 所以读取任意的文件,返回的结果都是二进制数据,即Buffer对象
4. Buffer对象可以调用toString()方法转换成字符串。
fs模块之写入数据
语法:fs.writeFile(file, data[, options], callback)
//参数1:写入的文件名(如果文件不存在,会自动创建)
//参数2:写入的文件内容 字符串(注意:写入的内容会覆盖以前的内容)
//参数3:数据编码格式 默认是utf-8
//参数4:写文件后的回调函数
fs.writeFile("2.txt", "hello world, 我是一个中国人", err=>{
if(err) return console.log("写入文件失败", err);
console.log("写入文件成功");
});
注意:写文件的时候,会把原来的内容给覆盖掉,追加数据到文件中
追加数据到文件中
语法:fs.appendFile(path, data[, options], callback)
//参数1:追加的文件名(如果文件不存在,会自动创建)
//参数2:追加的文件内容(注意:写入的内容会覆盖以前的内容)
//参数3:追加文件后的回调函数
fs.appendFile("2.txt", "我是追加的内容",(err)=>{
if(err) return console.log("追加文件内容失败");
console.log("追加文件内容成功");
})
**注意:**只会追加新的数据,不会覆盖原来的数据
同步与异步的说明
fs中所有的文件操作,都提供了异步和同步两种方式
异步方式:不按顺序执行,各自执行各的,不会阻塞代码的执行
//异步方式
var fs = require("fs");
console.log(111);
fs.readFile("2.txt", "utf8",(err, data)=>{
if(err) return console.log("读取文件失败", err);
console.log(data);
});
console.log("222");
同步方式:按顺序执行,当前的没有执行完毕,后面的不会执行,会阻塞代码的执行
//同步方式
console.log(111);
var result = fs.readFileSync("2.txt", "utf-8");
console.log(result);
console.log(222);
总结:同步操作使用虽然简单,但是会影响性能,因此尽量使用异步方法,尤其是在工作过程中。
其它API(了解)
方法有很多,但是用起来都非常的简单,学会查文档
文档:http://nodejs.cn/api/fs.html
| 方法名 | 描述 |
|---|---|
fs.readFile(path, callback) |
读取文件内容(异步) |
fs.readFileSync(path) |
读取文件内容(同步) |
fs.writeFile(path, data, callback) |
写入文件内容(异步) |
fs.writeFileSync(path, data) |
写入文件内容(同步) |
fs.appendFile(path, data, callback) |
追加文件内容(异步) |
fs.appendFileSync(path, data) |
追加文件内容(同步) |
fs.rename(oldPath, newPath, callback) |
重命名文件(异步)移动文件 |
fs.renameSync(oldPath, newPath) |
重命名文件(同步) |
fs.unlink(path, callback) |
删除文件(异步) |
fs.unlinkSync(path) |
删除文件(同步) |
fs.mkdir(path, mode, callback) |
创建文件夹(异步) |
fs.mkdirSync(path, mode) |
创建文件夹(同步) |
fs.rmdir(path, callback) |
删除文件夹(异步) |
fs.rmdirSync(path) |
删除文件夹(同步) |
fs.readdir(path, option, callback) |
读取文件夹内容(异步) |
fs.readdirSync(path, option) |
读取文件夹内容(同步) |
fs.stat(path, callback) |
查看文件状态(异步) |
fs.statSync(path) |
查看文件状态(同步) |
path模块
路径操作的问题
在读写文件的时候,文件路径可以写相对路径或者绝对路径
readFile这个方法在读取文件的时候,如果是用的相对路径,是以执行node命令时所在的文件夹为当前文件夹来查找文件。
//data.txt是相对路径,读取当前目录下的data.txt, 相对路径相对的是指向node命令的路径
//如果node命令不是在当前目录下执行就会报错, 在当前执行node命令的目录下查找data.txt,找不到
fs.readFile("data.txt", "utf8", function(err, data) {
if(err) {
console.log("读取文件失败", err);
}
console.log(data);
});
相对路径:相对于执行node命令的路径
绝对路径:__dirname: 当前文件所在的目录,不包括自己文件名,__filename: 当前文件的目录,包括自己文件名。
path模块的常用方法
关于路径,在linux系统中,路径分隔符使用的是
/,但是在windows系统中,路径使用的\
在我们拼写路径的时候会带来很多的麻烦,经常会出现windows下写的代码,在linux操作系统下执行不了
path模块就是为了解决这个问题而存在的。
示例如下:
path.join();//拼接路径
//windows系统下
> path.join("abc","def","gg", "index.html")
"abc\def\gg\a.html"
//linux系统下
> path.join("abc","def","gg", "index.html")
'abc/def/gg/index.html'
path.basename(path[, ext]) 返回文件的最后一部分
path.dirname(path) 返回路径的目录名
path.extname(path) 获取路径的扩展名
var path = require("path");
var temp = "abc\\def\\gg\\a.html";
console.log(path.basename(temp));//a.html
console.log(path.dirname(temp));//abc\def\gg
console.log(path.extname(temp));//.html
const fs = require('fs');
const path = require('path');
fs.readFile(path.join(__dirname, './data.txt'), 'utf-8', (err, data) => {
if (err) return console.log('读取失败');
console.log('读取成功');
});
path模块的其它API(了解)
| 方法名 | 描述 |
|---|---|
path.basename(path[, ext]) |
返回文件的最后一部分 |
path.dirname(path) |
返回路径的目录名 |
path.extname(path) |
获取路径的扩展名 |
path.isAbsolute(path) |
判断目录是否是绝对路径 |
path.join([...paths]) |
将所有的path片段拼接成一个规范的路径 |
path.normalize(path) |
规范化路径 |
path.parse(path) |
将一个路径解析成一个path对象 |
path.format(pathObj) |
讲一个path对象解析成一个规范的路径 |
http模块
http模块可以用来创建服务器
基本步骤及代码:
// 1. 引入http模块
const http = require('http')
// 2. 创建服务器对象
const server = http.createServer()
// 3. 监听端口并开启服务器
server.listen(3000,()=>{
console.log('server is running at http://127.0.0.1:3000');
})
// 4.注册事件 监听请求
server.on('request',(req,res)=>{
// req request的缩写是一个请求对象 所有的请求相关的内容都在这个req对象当中
// res response的缩写是一个响应对象 所有的响应相关的内容都在这个res对象当中
// res.write('hello'); // 表示向浏览器响应数据
// res.write('world'); // 可以响应多次
// res.end() // 表示所有的数据都响应完毕了
// res.end('hello world123') // 相当于是res.write('hello world123') + res.end()
// res.end('这是一个段落标签...
') // 直接向浏览器端响应数据
res.end('900') // 响应的数据只能是二进制或字符串
})
// ctrl + c 停止服务器
详细说明:
- http是一个内置模块对象,可以通过
createServer()方法来创建服务对象 - listen是一个方法,此方法有三个参数
- 第1个参数表示要监听的端口
- 第2个参数表示服务器的地址,如果不写默认是:
127.0.0.1 - 第3个参数是一个箭头函数,表示端口监听时要进行的操作
- on事件有两个参数 第一个参数是request 名字必须这么写 表示监听浏览器端(客户端)的请求 第二个参数是回调函数
- 给服务器注册request事件,只要服务器接收到了客户端的请求,就会触发request事件
- request事件有两个参数:
- req: request的缩写 表示请求对象,可以获取所有与请求相关的信息,
- res: response的缩写 表示响应对象,可以获取所有与响应相关的信息。
- 服务器监听的端口范围为:1-65535之间,推荐使用3000以上的端口,因为3000以下的端口一般留给系统使用
- 前后端数据交互的格式只有两种
- 二进制
- 字符串
网络知识:
IP地址:就是用来标识网络中的终端设备 电脑 手机 智能家居 家电
域名:其实就是一个IP地址的别名
任何人的电脑中的私有地址IP地址就是:127.0.0.1
request对象详解
文档地址:http://nodejs.cn/api/http.html#http_message_headers
常见属性:
headers: 所有的请求头信息
method: 请求的方式 GET/POST URL地址栏中的请求一定是GET
url: 请求的地址 获取的是地址中端口号后面的所有的数据
代码如下:
// - 4.注册事件,监听请求
let num = 0;
app.on('request', (req, res) => {
// 只要是浏览器端向127.0.0.1:3000这个目标地址发送的请求,都会进到这个回调函数当中
// req request的缩写是一个请求对象 所有的请求相关的内容都在这个req对象当中
// res response的缩写是一个响应对象 所有的响应相关的内容都在这个res对象当中
// res.write('aaaaa') // 表示向浏览器响应内容
// res.write('bbbbbbbbb')
// res.end('aaaaaaaaaabbbbbbbbbb')
// num++
// res.setHeader('content-Type', 'text/plain;charset=utf-8')
// res.end('来了,老弟儿' + num)
// console.log(req)
console.log(req.url) // 获取的是端口号后面的所有的数据
console.log(req.method) // 请求的方式 GET/POST
console.log(req.headers) // 请求头信息 数据比较多
res.end('OK')
})
注意:在发送请求的时候,可能会出现两次请求的情况,这是因为谷歌浏览器会自动增加一个
favicon.ico的请求。
小结:
- request对象中,常用的就是method和url两个参数
response对象详解
文档地址:http://nodejs.cn/api/http.html#http_class_http_serverresponse
常见的属性和方法:
res.write(data): 给浏览器发送请求体,可以调用多次,从而提供连续的请求体
res.end(); 通知服务器,所有响应头和响应主体都已被发送,即服务器将其视为已完成。
res.end(data); 结束请求,并且响应一段内容,相当于: res.write(data) + res.end()
res.statusCode: 响应的的状态码 200 404 500 403表示禁止
res.statusMessage: 响应的状态信息, OK Not Found ,会根据statusCode自动设置。
res.setHeader(name, value); 设置响应头信息, 比如content-type
//res.setHeader('Content-Type','text/html;charset=utf-8')
res.writeHead(statusCode[, statusMessage], options); 设置响应头,同时可以设置状态码和状态信息。
//res.writeHead(200,{
'Content-Type':'text/html;charset=utf-8';
})
Response Headers 是服务器用来告诉浏览器有关服务器端的一些信息 还包括 告诉浏览器如何解析我响应给你的数据,如果服务器没有告诉浏览器如何解析响应过去的数据,则浏览器会用自己默认的方式去处理,浏览器默认的处理编码是GBK 而浏览器的默认编码是‘utf-8’
示例代码:
let num = 0
app.on('request', (req, res) => {
// 只要是浏览器端向127.0.0.1:3000这个目标地址发送的请求,都会进到这个回调函数当中
let url = req.url;
console.log(url);
let method = req.method;
if (method == 'GET' && url == '/index.html') {
fs.readFile(path.join(__dirname, './index.html'), (err, data) => {
if (err) return console.log('读取失败...')
res.end(data);
});
} else {
// 如果路径不对的话,就到了这个else当中了,则返回404的信息 并且最好返回一个404的状态码
// 一般来说,我们不会主动的去设置状态码和状态信息 服务器会自动的根据状态码来设置一个合适的状态信息
// res.statusCode = 404
// res.statusMessage = 'the file is not found'
// res.end('404')
// res.setHeader('content-type', 'text/plain;charset=utf-8')
res.writeHead(404, {
'content-type': 'text/plain;charset=utf-8',
'aaaa': 'bbbbbbbbb'
})
res.end('你找的文件不存在...') // res.end执行了之后,后面的代码不再执行了
console.log('111111111111111'); // 不再执行了
}
})
注意:必须先设置响应头,才能设置响应。
实现静态WEB服务器
服务器响应首页
- 注意:浏览器中输入的URL地址,仅仅是一个标识,不与服务器中的目录一致。
- 也就是说:返回什么内容是由服务端的逻辑决定.
// 1. 引入模块
const http = require('http');
const path = require('path');
const fs = require('fs');
// 2. 创建服务器实例对象
const app = http.createServer();
// 3. 监听端口并开启服务器
app.listen(3000, () => {
console.log('server is running at 127.0.0.1:3000')
})
// 4. 注册事件,并响应数据
app.on('request', (req, res) => {
// 读取静态文件中的数据,响应给浏览器
fs.readFile(path.join(__dirname,'./views/index.html'),(err,data)=>{
// 读取失败要报错
if(err) return console.log(err.message);
// 将读取到的数据响应给浏览器
res.end(data);
})
})
根据不同的路径,响应不同的页面
思考:如果有如下的需求怎么办?
- 1.如果浏览器端输入的是
http://127.0.0.1:3000/index.html,则要显示index.html页面内容 - 2.如果浏览器端输入的是
http://127.0.0.1:3000/movie.html,则要显示movie.html页面内容 - 3.如果浏览器端输入的是
http://127.0.0.1:3000/detail.html,则要显示detail.html页面内容
思路:
- 1.使用
req.url获取浏览器端发送过来的请求路径 请求路径是端口号后面的内容 - 2.使用
req.method获取请求方式 - 3.根据路径和请求方式来判断,然后响应不同的页面源代码
- 4.如果文件不存在,那么会读取失败,响应404页面
// 1. 引入模块
const http = require('http');
const path = require('path');
const fs = require('fs');
// 2. 创建服务器实例对象
const app = http.createServer();
// 3. 监听端口并开启服务器
app.listen(3000, () => {
console.log('server is running at 127.0.0.1:3000')
})
// 4. 注册事件,处理请求
app.on('request', (req, res) => {
// 4.1 获取请求的路径
let url = req.url;
// 4.2 获取请求的方式
let method = req.method;
// 4.3 根据不同的请求路径和方式响应不同的页面
if (method == 'GET' && (url == '/' || url == '/index.html')) {
fs.readFile(path.join(__dirname, './views/index.html'), (err, data) => {
if (err) return console.log(err.message);
res.end(data);
})
} else if (method == 'GET' && url == '/movie.html') {
fs.readFile(path.join(__dirname, './views/movie.html'), (err, data) => {
if (err) return console.log(err.message);
res.end(data);
})
} else if (method == 'GET' && url == '/detail.html') {
fs.readFile(path.join(__dirname, './views/detail.html'), (err, data) => {
if (err) return console.log(err.message);
res.end(data);
})
} else {
res.statusCode = 404;
res.end('404,file not found...');
}
})
延伸:
- 如果有css样式,图片及js文件会如何呢?
重点小结
1. 创建服务器的四个步骤:
- 导入http模块
- 创建服务器
createServer - 启动服务器,监听一个端口,0-65535之间
- 给服务器注册
request事件,有两个参数,req代表请求,res代表响应
2. req对象中常用的属性
- req.url: 获取用户请求的地址
- req.method :获取用户的请求方式
- req.headers:获取所有的请求头
3. res对象中常用的属性和方法
- res.write() : 发送一段响应体,可以多次调用
- res.end(): 结束响应,每个请求,都必须调用end()
- res.setHeader(): 设置响应头的,需要设置
content-type - res.statusCode: 设置状态码 200 404 500
- res.writeHead() : 可以同时设置状态码和响应头
4.path模块
1.可以非常方便的用来拼接路径,无论是Linux,还是Windows
2.常用方法:path.join()
5.__dirname
1.获取当前文件的绝对路径,是从盘符开始的
2.常用于读写文件时的路径拼接
6.fs模块
1.此模块是用于读写文件用的
2.常用方法: fs.readFile() fs.writeFile() fs.appendFile()
4.nodemon工具
由于每次修改了js代码之后,都需要使用node命令重新启动服务器,这样不是太方便
我们可以通过nodemon这个小工具,来实现自动帮助我们重启
nodemon的安装
npm install nodemon -g // 使用全局的方式进行安装 -g表示全局安装
npm i nodemon -g
会将这个第三方插件安装到:C:\Users\用户名\AppData\Roaming\npm
nodemon的使用
nodemon app.js // 启动服务器
5.NPM-Node包管理工具
npm的基本概念
- node package manager
- npm官网
- npm中文文档
1. npm 是node的包管理工具,
2. 它是世界上最大的软件注册表,每星期大约有 30 亿次的下载量,包含超过 600000 个 包(package) (即,代码模块)。
3. 来自各大洲的开源软件开发者使用 npm 互相分享和借鉴。包的结构使您能够轻松跟踪依赖项和版本。
- 作用:通过
npm来快速安装开发中使用的包 - npm不需要安装,只要安装了node,就自带了
npm
配置下载源
原始的npm包是从https://www.npmjs.com/下载的,这是一个外国的网站,可能会导致下载速度比较慢
为了有一个更快的下载速度,淘宝将npm官方网站的那些模块或包同步到了国内的淘宝提供的服务器上
查看镜像源
npm config list
因此可以镜像源切换到国内淘宝提供的服务器
npm config set registry https://registry.npm.taobao.org --global
npm config set disturl https://npm.taobao.org/dist --global
nrm的使用
nrm:npm registry manager(npm仓库地址管理工具)
如果在国内开发的话,可以使用淘宝服务器提供的镜像
如果是在国外开发的话,可以使用国外的官方镜像源
因此,我们可以使用nrm来方便的切换镜像源
安装nrm
npm i -g nrm // -g 就是--global的缩写 i是install的缩写
查看当前镜像源
nrm ls // 带*表示当前正在使用的地址 ls就是list的缩写
切换镜像源地址
nrm use taobao // 切换到淘宝提供的镜像源 以后下载的包都是从淘宝镜像源服务器来下载
npm基本使用
初始化包
npm init; //这个命令用于初始化一个包,创建一个package.json文件,我们的项目都应该先执行npm init
npm init -y; //快速的初始化一个包, 不能是一个中文名
安装包
npm install 包名; //安装指定的包名的最新版本到项目中
npm install 包名@版本号; //安装指定包的指定版本
npm i 包名; //简写
卸载包
npm uninstall 包名; //卸载已经安装的包
清除缓存
npm cache clean -f // 如果npm安装失败了,可以用这个命令来清除缓存
快速下载项目中所有的依赖项:
npm i // 这个命令会根据package.json文件中的依赖项去下载对应的第三方库或包
package.json文件
package.json文件,包(项目)描述文件,用来管理组织一个包(项目),它是一个纯JSON格式的。
-
作用:描述当前项目(包)的信息,描述当前包(项目)的依赖项
-
如何生成:
npm init或者npm init -y -
作用
- 作为一个标准的包,必须要有
package.json文件进行描述 - 一个项目的node_modules目录通常都会很大,不用拷贝node_modules目录,
- 可以通过package.json文件配合
npm install直接安装项目所有的依赖项
- 作为一个标准的包,必须要有
-
描述内容
{ "name": "03-npm", //描述了包的名字,不能有中文 "version": "1.0.0", //描述了包的的版本信息, x.y.z 如果只是修复bug,需要更新Z位。如果是新增了功能,但是向下兼容,需要更新Y位。如果有大变动,向下不兼容,需要更新X位。 "description": "", //包的描述信息 "main": "index.js", //入口文件(模块化加载规则的时候详细的讲) "scripts": { //配置一些脚本,在vue的时候会用到,现在体会不到 "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [], //关键字(方便搜索) "author": "", //作者的信息 "license": "ISC", //许可证,开源协议 "dependencies": { //重要,项目的依赖, 方便代码的共享 通过 npm install可以直接安装所有的依赖项 "bootstrap": "^3.3.7", "jquery": "^3.3.1" } }注意:一个合法的package.json,必须要有name和version两个属性
安装依赖
依赖分两种
- 一个是部署依赖,即:在开发和部署上线都需要使用的包
- 使用命令:
npm install 包名 --save其中:--save可以简单写成-S
- 使用命令:
- 一个是开发依赖,即:只在项目开发阶段需要用到的包,比如某些打包工具,格式化工具等…
- 命令:
npm install 包名 --save-dev其中:--save-dev可以简写成-D
- 命令:
6. MIME
MIME的说明
MIME 类型
- 1.MIME(Multipurpose Internet Mail Extensions)多用途Internet邮件扩展类型 是一种表示文档性质和格式的标准化方式
- 2.浏览器通常使用MIME类型(而不是文件扩展名)来确定如何处理文档;
- 3.常见的mime类型
- 4.因此服务器将正确的MIME类型附加到响应对象的头部是非常重要的
- 5.通过响应头的
content-type可以设置mime类型 - 6.如果没有给浏览器设置正确的mime类型,浏览器会根据响应的内容猜测对应的mime类型。
- 7.但是不能保证所以浏览器能够得到一致的效果。
-
- 对于服务器开发,需要给每一个响应都设置一个正确的mime类型
mime模块的使用
nodejs核心并没有提供用于处理mime的模块。但是我们可以在npm上下载开发中遇到的第三方包。
安装:
npm i mime
使用:
// 引入mime模块
const mime = require('mine')
// 获取路径对应的MIME类型
console.log(mime.getType('.css'))
console.log(mime.getType('.html'))
console.log(mime.getType('.gif'))
...
// 也可以根据路径来生成指定的mime类型
console.log(mime.getType('http://127.0.0.1:3000/views/index.html'))
console.log(mime.getType('http://127.0.0.1:3000/views/index.css'))
console.log(mime.getType('http://127.0.0.1:3000/views/index.js'))
console.log(mime.getType('http://127.0.0.1:3000/images/aa.jpg'))
console.log(mime.getType('http://127.0.0.1:3000/images/aa.gif'))
7 . 静态网站与动态网站
静态网站:
- 页面中的数据是不会发生变化的
- 每次打开与之前都是一样的
动态网站:
- 页面中的数据是会发生变化的,甚至是时时发生变化的
- 网站上的数据来源于服务器端
- 有可能是前端渲染出来的数据
- 也有可能是服务器端渲染出来的数据
8. 在node当中使用art-template
[文档][https://aui.github.io/art-template/zh-cn/docs/]
作用:
- 1.将数据快速高效的替换到html页面中需要的位置
- 2.大大提高开发效率
安装
npm i art-template
使用
// 在项目当中引入art-template模板
const template = require('art-template')
// 使用template方法将数据和html标签中的结构进行绑定
// template有两个参数
// 第1个参数表示要替换数据的html页面
// 第2个参数是传一个对象,因为这个对象中保存着要替换的数据,必须是一个对象
// html页面中数据的呈现,与原来浏览器端使用art-template模板一模一样的,该循环的循环,该判断的判断,也是{{}}的形式
let obj={name:'tom',age:20,gender:'男',hobby:['滑雪','游泳','睡觉']};
let htmlStr = template(path.join(__dirname,'./views/index.html'),obj)
<ul>
{{each hobby as value index}}
<li>{{value}}</li>
{{/each}}
</ul>
注意:文件的路径必须是绝对路径
9.JSON
JSON语法规则
即 JavaScript Object Notation,另一种轻量级的文本数据交换格式,独立于语言。
语法规则
1、JSON 中属性名称必须用双引号包裹
2、JSON 中表述字符串必须使用双引号
3、JSON 中不能有单行或多行注释
4、JSON中数据由逗号分隔(最后一个键/值对不能带逗号)
5、JSON中花括号保存对象,方括号保存数组,如果是存储一个数据可以使用 { },如果存储多个数据可以放在[ ]。
6、JSON **没有 undefined **这个值
如果仅仅是在一个js文件中写一个对象或是写一个数组是否遵循JSON格式无所谓
[
{
"id": 1,
"name": "tom",
"age": 18,
"gender": "男",
"zhuanye": "前端",
"address": "松江区"
},
{
"id": 2,
"name": "rose",
"age": 19,
"gender": "女",
"zhuanye": "大数据",
"address": "宝山区"
},
{
"id": 3,
"name": "jerry",
"age": 20,
"gender": "男",
"zhuanye": "python",
"address": "奉贤区"
},
{
"id": 4,
"name": "jodan",
"age": 21,
"gender": "男",
"zhuanye": "java",
"address": "闵行区"
}
]
前后端数据传输的格式只有两种:
1.字符串 一些普通的数据 html css .js....
2.二进制 图片 视频 音乐 大文件...
注:JSON对象中属性值的获取与普通对象一样
相同点:
1.都有{}包裹
2.都是键值对的形式
3.属性值的访问方式都是一样的
不同点:
1.JSON中属性名称必须用双引号包裹
2、JSON中表述字符串必须使用双引号
JSON数据解析
JSON解析
从JSON文件中读取到的数据是字符串’[ ]’ '{ }'
JSON数据在不同语言进行传输时,类型为字符串,不同的语言各自也都对应有解析方法,需要解析完成后才能读取
Javascript 解析方法
let result = JSON.parse(data):是将字符串形式的JSON数据转换成真正的JSON对象(不带引号了)
JSON.stringify(JSON对象):将数组或对象转换为JSON语法形式的字符串 '[{},{},{}]'
语法:
JSON.stringify(value[, replacer [, space]])
参数1:value:将要序列化成 一个 JSON 字符串的值。
参数2:replacer 可选 如果该参数是一个函数,则在序列化过程中,被序列化的值的每个属性都会经过该函数的转换和处理;如果该参数是一个数组,则只有包含在这个数组中的属性名才会被序列化到最终的 JSON 字符串中;如果该参数为 null 或者未提供,则对象所有的属性都会被序列化。
参数3:space 可选 指定缩进用的空白字符串,用于美化输出(pretty-print);如果参数是个数字,它代表有多少的空格;上限为10。该值若小于1,则意味着没有空格;如果该参数为字符串(当字符串长度超过10个字母,取其前10个字母),该字符串将被作为空格;如果该参数没有提供(或者为 null),将没有空格。
总结:JSON体积小、解析方便且高效,在实际开发成为首选。
10.处理GET方式传递的参数
如果使用get方式向服务器发送请求的话,会在URL地址路径后面用?进行连接 参数格式是键=值&键=值&键=值的形式进行拼接
注:input标签中一定要加name属性
url模块介绍
- 如果前端浏览器发送过来的请求地址当中,没有参数的话,直接使用req.url来获取路径就可以了
- 因为req.url获取的就是端口号后面的内容 比如:
http://127.0.0.1:3000/views/index.html路径:/views/index.html - 如果请求的路径中带参数了比如:
http://127.0.0.1:3000/add?name=tom&age=20&gender=男再用req.url就不好办了 - 因此要使用一个专门的node中内置的核心模块,
url模块 - 此模块是专门用来url地址的,可以将地址中的
路径和参数非常方便的分开对待
url模块的使用
// 引入url模块
const urlObj = require('url')
// 调用方法中的parse方法,对url地址进行解析
const obj = urlObj.parse(req.url[,true])
-
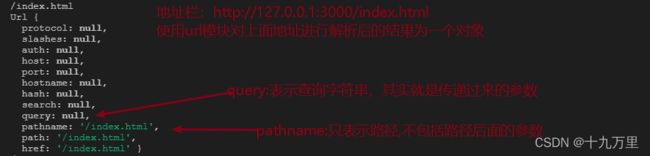
比如当前地址是:http://127.0.0.1:3000/index.html
req.url:
/index.html
const obj = urlObj.parse(req.url)
注意,此时并没有传递第二个参数true
-
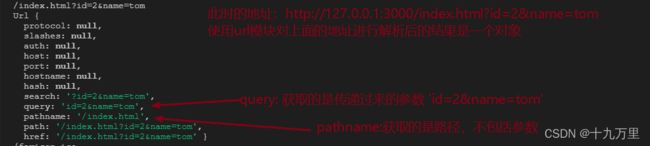
再来看这个地址:http://127.0.0.1:3000/index.html?id=2&name=tom
req.url:/index.html?id=2&name=tom
const obj = urlObj.parse(req.url)注意,此时还是没有传递第二个参数true
-
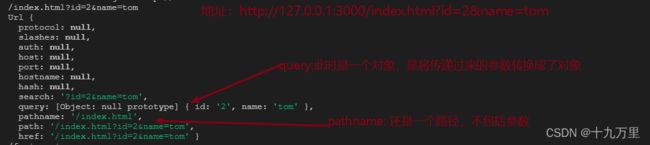
仍然是这个地址:http://127.0.0.1:3000/index.html?id=2&name=tom
req.url:/index.html?id=2&name=tom
const obj = urlObj.parse(req.url,true)注意,此时有传递第二个参数true
小结:如果在写案例或项目的时候,有参数是通过URL拼接传递过来的,则此时在node后端一定要使用url模块来解析。
- 不管请求地址中有没有参数,都要使用:
url.parse(req.url,true)的方式来处理,返回的是一个对象 - 此对象当中有两个常用属性,一个是
pathname,一个是query pathname里面存储的是地址当中的端口号和?之间的路径 比如:/submitquery里面存储的是get方式传递过来的参数,如果没有参数则是null
12.处理POST方式传递的数据
由于POST请求的方式是通过请求体来传递数据,此时在node后端获取数据的方式如下
获取POST请求的数据
// data事件:用来接受客户端发送过来的POST请求数据
// 只要有数据发送过来就会不断的触发data事件
// chunk是块的意思,表示数据是分块来传输的
// 要使用POST的方式来接收浏览器传递过来的数据
// 因为POST方式是以请示体的形式传递的数据 这个数据可以非常大 对数据大小没有要求
// 如果是大量的数据,会分成一块一块的来传递
let str = "";
req.on('data', chunk => {
// 只要有数据以post请示的方式发送过来 就会触发data事件 chunk表示块的意思
str += chunk; // 将接收到的数据拼接起来
})
// 当end事件被 触发的的时候,说明数据传递完毕 str中就存储着最终的数据
req.on('end', ()=> {
cosnole.log(str); // 打印出来的是一个字符串
let obj = querystring.parse(str);
console.log(obj); // 转换成对象之后 就可以进行后续处理
res.end('post');
})
querystring模块
- 用于解析与格式化 字符串数据
- 注意:只在专门处理查询字符串时使用
// 引入模块
const querystring = require('querystring')
// 将字符串转换成对象
let str = 'name=tom&age=20&gender=男'
let obj = querystring.parse(str) // { name: 'tom', age: '20', gender: '男' }
13. 服务器端重定向
-
HTTP 状态码说明
-
服务器端可以通过响应头中的状态码让浏览器中的页面进行重定向(重新跳转)
res.writeHead(302, { 'Location': '/' }) res.end();