持久内存BTT实现及优化(一)
Intel IOG/PRC Optane CoE
Wu, Dennis ([email protected])
一般提示及法律声明:
本主题主要涉及Linux内核BTT的优化,该优化将遵循开源的原则,所有的代码将公开。实际测试的性能受使用情况、配置和其他因素的差异影响。更多信息请见www.Intel.com/PerformanceIndex
目录
1、介绍
2、数据布局[ii]
信息块
数据块
BTT Map
BTT Flog
3、原有算法
通道lane的概念
通道上的LBA操作
不同通道上写相同的LBA
不同通道上读写相同的物理块
数据恢复
错误处理
4、算法优化
构建空闲列表
通道上的LBA操作
兼容性的考量
5、性能状况
测试环境
Kernel BTT sector 模式下FIO性能
6、后续的计划
1、介绍
传统SSD通常提供扇区级(512 bytes sector)的保护。为了防止硬件中的扇区数据损坏,通常通过使用电容中存储的能量完成执行中的块写入。持久性内存的存储按照字节的粒度来执行IO,且和内存一样只能保证8字节对齐的8字节的原子性[i][WZ1] [WD2] 。如果写入正在进行,并且我们遇到电源故障,那么数据将可能包含新旧数据的混合。我们希望将持久内存存储也可以转变为传统的块设备, 持久内存的块驱动程序正是这样做的。

Figure 1 SNIA编程模型中的storage编程模型依赖BTT
块转换表(BTT - Block Translation Table)为持久性内存设备提供了像传统SSD一样的扇区级原子更新的原语语义,利用BTT可以让PMem在应用中呈现为Sector的设备, 实现和SSD相同的编程模型(如图Figure 1所示)。
BTT会将持久内存显示为一个堆叠的块设备,并为其元数据保留一部分存储。它的核心是一个间接表,用于重新映射卷上的所有块, BTT可以被认为是一个非常简单的文件系统[WZ3] [WD4] ,提供扇区级原子更新。所谓的原子性这里是指一下三个方面:
- 从应用上同时写一个LBA(Logic Block Address)不会引起数据的脏写。
- 不会出现读一个正在写的物理扇区。
- 断电的时候一个正在写的扇区,如果没有返回,所有的数据还是原始数据,不会出现新旧数据混合的脏数据;一旦返回,数据更新为最新的数据。
2、数据布局[ii]
静态数据布局有利于持久内存上数据的访问以及元数据的设计。由于持久内存的容量较大,我们可以将整个持久内存的空间分成多个“Arena”,每一个“Arena”上的元数据遵循相同的布局,“Arena”上的元数据都是指向内部的数据或数据结构(除下一个“Arena” 的偏移除外)。现有的BTT按照空间分割成512GB的区间,可以由30 bit表示512字节扇区的范围。持久内存的数据布局如Figure 2所示。
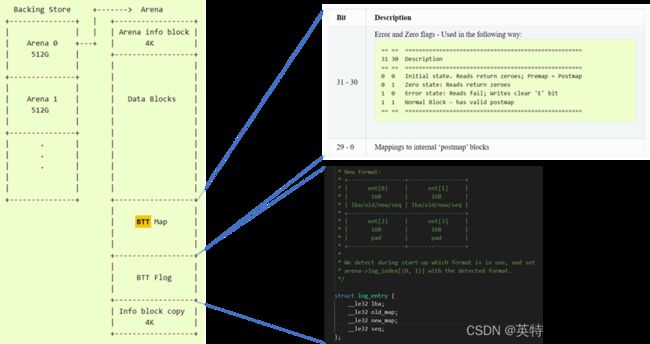
Figure 2 持久内存的静态数据布局
-
信息块
从数据布局中可见,每一个Arena的第一个4K字节和最后一个4k空间用来存储相同的Arena信息块(Info Block),我们也可以称之为这个Arena的超级块(Super Block)。信息块的数据关系到整个数据的布局,其中包含了数据块(data blocks)的位置,BTT map的位置,BTT Flog的位置,以及下一个Arena的位置等等信息,一旦损坏将无法恢复用户存储的数据。所以这个超级块中会利用checksum来检查整个超级块数据的完整性同时增加一个备份以备出现最坏的情况,这样的保险机制能够保证客户信息块中数据的安全。
-
数据块
数据块中存储用户的数据,按照扇区的大小将其按顺序并称之为数据地址(ABA-Arena Block Address),如果扇区的大小是512字节,那第一个512字节的数据块的ABA就等于0。 一个Arena去除掉所有的元数据之后就是数据区的大小,这个大小在数据布局的时候就已经确定。
-
BTT Map
逻辑块地址(LBA-Logic Block Address)是上层应用可以操作的地址,其最终需要映射到一个具体的数据块ABA。而BTT Map是一个简单的查找/间接表,用于将外部的LBA映射到内部数据块ABA。外部的LBA顺序对应到每一个BTT Map的一个映射条目,[SX5] 映射到这个Arena的第一个LBA对应BTT Map的第一个4字节的映射条目。
例如,在添加BTT后,我们将对外暴露出1024G的磁盘。我们得到的外部LBA访问768G处。这属于第二个Arena,在这个Arena贡献的512G的数据中,这个位置是256G。因此对应的BTT Map的条目为256G处的BTT Map映射条目,如果我们扇区大小配置为4K,那么就可以从256G/4K= 64M位置(Premap ABA)的BTT Map条目找到其真正的物理块ABA(postmap ABA)为64。
每个映射条目为32位。其中最高的两位是特殊标志,其余组成内部ABA块号。其中的两位特殊标记包括了:
- 初始状态(0 0):LBA没有映射任何物理块
- 零状态(0 1):映射的数据块里的数据为零,所以读数据访问到此标志时,直接返回0,无需读物理块。
- 错误状态(1 0):表示物理块有错误。读此数据时直接返回错误,可以写覆盖。
- 正常状态(1 1): 表示物理块正常。
从上面这些描述,我们总结一下几个重要的概念:
| 外部逻辑块地址(LBA) |
上层应用可以操作的地址 |
| Arena数据地址(ABA) |
数据区里数据地址 |
| Premap ABA |
外部LBA对应的BTT map的位置 |
| Postmap ABA |
在BTT map的4字节条目中对应的ABA地址 |
-
BTT Flog
BTT通过让每次写入都成为“分配写入”,即每次写入都进入“空闲”块,从而提供扇区原子性。以BTT flog的形式维护空闲块的运行列表。”“Flog”是“free list”和“log”的组合。flog包含“nfree”条目,条目包含:
| LBA |
外部LBA对应的BTT map的位置即premap ABA |
| old_map |
老的BTT map中对应的ABA数据地址,一旦写完成,这个数据地址就变为空闲 |
| new_map |
新分配的数据地址btt map会更新以反映新的映射关系 |
| seq |
序列号,用于标记此flog条目的两个部分中的哪一部分有效/最新。正常运行时,它在01->10->11->01(二进制)之间循环,00表示未初始化状态。 |
| LBA’ |
备用lba条目 |
| old_map’ |
备用 old_map条目 |
| new_map’ |
备用new_map条目 |
| seq’ |
备用seq条目 |
上述每个字段都是32位的,其中一个条目为32字节。条目也被填充到64字节,以避免缓存线共享。Flog更新的执行方式是:
- 根据序号覆盖条目中的“旧”部分
- 写入“新”部分,以便最后写入序号。
3、原有算法
BTT的算法和逻辑都是围绕上述的数据分布来进行的。其中的核心点BTT map的映射关系比较直接,但是flog却是比较难以理解的。所以我们首先从flog这个算法开始。
-
通道lane的概念
在BTT算法中,“nlanes”表示BTT设备作为一个整体可以处理的IO数,而“nfree”表示在任何情况下需要保留的物理块的多少。 我们一般将通道的数目设置为:
nlanes =min(nfree, num_cpus)
通道号在任何IO开始时获得,并用于在IO期间索引到所有磁盘上和内存中的数据结构。如果CPU数量超过可用通道的最大数量,通道上的IO受锁保护,只有等到锁可用,这些IO才能执行。我们一般将通道数nlane和nfree设置成一样,表示每一个通道在任何情况下都至少有一个空闲的物理块。
每一个通道都会有一个通道锁,所以通道上接受的外部LBA都是顺序的,而各个通道是可以并发的。如Figure 2 BTT 通道概念以及操作流程所示,通道lane0,依次接受了lba0,lba1,lba2的访问,而lane1依次接受了lba3,lba4,lba5的访问。
-
通道上的LBA操作
我们设定了nfree和nlane大小相同,同时假定用户还没有对该Arena存储过任何数据,也就是所有的内部ABA都是空闲的。下面是通道lane0写操作的过程:
- 需要写lba0数据时,首先从最后的nfree个空闲块里取出lane0对应的空闲块,然后将数据写入该空闲块。然后将lba0对应的Premap ABA作为该通道的下一个空闲的ABA。当写完成后,更新lba0对应的btt map条目。
- 需要写lba1数据时,数据将写入通道lane0的空闲数据块(lba0对应的Premap ABA), 然后将lba1对应的premap ABA作为该通道的下一个空闲的ABA。写完成后,更新lba1对应的btt map条目。
所以我们每个通道上的空闲块就构成了一个完整的链条,如果突然断电或重启,要恢复整个链条的关系,我们需要记住每一个通道在断电之前最后一刻的链条关系,这个就是flog。每一个flog条目是16个字节,所以必须分成两个8字节的原子写才能够完成。Flog的更新在btt map更新之前。断电重启可能发生在下列的情况:
- 写完了数据,但是没有完成flog的更新,那么btt map还是原来的对应关系,所以数据没有写成功。如果读,读出以前的数据。
- 第一个8字节的flog更新完成,第二个还没有更新,由于seq number还没有更新,所以还是读原有的bflog,包括之前的map关系。
- flog 16字节完全更新成功,btt map没有更新,在重启后可以再次根据记录的postmap,更新btt map。

Figure 3 BTT 通道概念以及操作流程
读操作比较简单,根据外部的LBA首先找到在arena内部的premap ABA出的btt map条目,读此条目根据状态和ABA信息,返回正确的数据,详见2.2节。
-
不同通道上写相同的LBA
如Figure 2 BTT 通道概念以及操作流程,两个不同的通道可能会写相同的外部LBA,由于每一个通道都有自己的空闲的ABA,所以数据写入并不冲突。但是当写入btt_map时,我们不清楚最终谁会竞争成功。
如Figure 3 在不同的通道上写相同的lba所示,在通道lane0,和lane1上写相同的lba0,其过程如下,可能会出现数据安全的风险:
- lba0此时是premap ABA,使用锁lane_enter()来保持通道只有一个操作。
- 从各自通道中获取空闲的ABA,a1和b1,并分别写各自的数据。
- 更新各自的flog。
- 更新btt map条目,确定lba0->ABA块地址。然后将相应的老的ABA释放为该通道上闲的块。
- 如图中所示,两个通道可能释放出相同的c1,作为该通道上空闲块。
- 下次操作就会出现两个写操作写道同一个ABA上的错误。

Figure 4 在不同的通道上写相同的lba
要解决这样的问题,可以对相同的lba加锁来保证执行的顺序性,从而解决上述可能出现的问题,在BTT的实现中,将所有的lba分成一定的区域,相同的lba肯定处在同一个区域,从而减少锁冲突的风险。Figure 4 为保证写相同lba数据正确性而增加的lba的锁。
static void lock_map(struct arena_info *arena, u32 premap)
__acquires(&arena->map_locks[idx].lock)
{
u32 idx = (premap * MAP_ENT_SIZE / L1_CACHE_BYTES) % arena->nfree;
spin_lock(&arena->map_locks[idx].lock);
}
static void unlock_map(struct arena_info *arena, u32 premap)
__releases(&arena->map_locks[idx].lock)
{
u32 idx = (premap * MAP_ENT_SIZE / L1_CACHE_BYTES) % arena->nfree;
spin_unlock(&arena->map_locks[idx].lock);
}Figure 5 为保证写相同lba数据正确性而增加的lba的锁
-
不同通道上读写相同的物理块
假设我们有两个线程,一个执行读操作,另一个执行写操作。我们可能遇到这样一种情况:写入线程获取一个空闲块来执行新IO,但(速度慢的)读线程仍在从这个块中读取数据。根据Figure 5 读写操作相同的物理块,导致脏读的步骤,我们可以看到步骤3和步骤6可能同时发生。
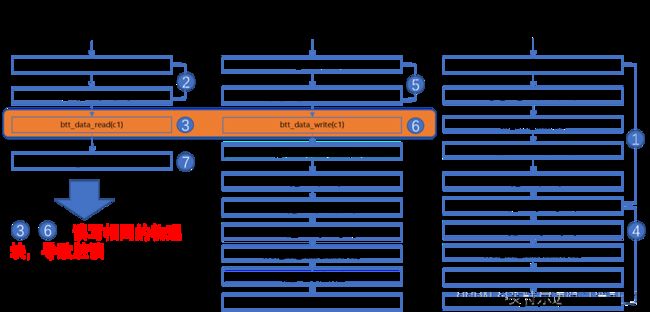
Figure 6 读写操作相同的物理块,导致脏读
为了解决这个问题,BTT引入了Read Tracking Table (RTT)这个内存数据结构,来记录各个通道上读的情况,如果写检测到某个通道上正在读某个相同的ABA,写操作就会等待读完成后再写数据。在上述的步骤中间插入RTT的逻辑如Figure 6 RTT逻辑来避免读写相同的物理块。

Figure 7 RTT逻辑来避免读写相同的物理块
在步骤2,3之间,如果步骤6先于步骤3,再次读写btt map, btt map肯定已经更新,读另一个ABA;如果4, 5, 6步骤后于3,btt_map没有更新,RTT肯定被正确的设置。随后可以读数据,读完之后将RTT设置为RTT_INVALID。
而写线程会在步骤5,6之间不停的检查RTT,如果有一个通道正在读相同的ABA,写操作会一直等待直到读完成,检查到相关的通道RTT已经重置,就可以接着写。
-
数据恢复
在BTT启动时,我们分析BTT flog以创建空闲块列表。我们浏览了一个每个通道中间的两个可能的16字节的条目,总是查看最新的一个(基于序号)。重建规则/步骤很简单:
- 读取映射[log_entry.lba]
- 如果log_entry.new 匹配btt map中的ABA条目, 那么log_entry.old 就变为这个车道中的空闲块
- 如果log_entry.new 不匹配btt map中的ABA条目,那么 log_entry.new 就是[WZ6] 这个车道中的空闲块
-
错误处理
如果任何元数据由于错误或介质的错误而导致无法恢复数据,Arena将处于错误状态。以下的4种情况表明Arena存在错误:
- 信息块校验和不匹配(并且从副本恢复也失败)
- 并非所有内部可用块都由映射块和空闲块(来自BTT flog)之和唯一且完全寻址。
- 从flog重建自由列表会显示丢失/重复/不可能的条目
- Btt map条目超出范围
如果遇到上述任何错误情况,将使用超级块中的标志将Arena置于只读状态。
4、算法优化
在上述的算法中,写一个lba需要写入数据,写btt map条目(4个字节),和写flog (16个字节,分两个8字节的写)。持久内存随机写的开销较大,所以写flog极大的增加了整个算法的开销,这个部分时可以优化的。同时bflog的写也增加了另一个错误点的发生。
我们可以只通过原有btt map条目中的信息,来恢复数据的访问,而放弃写入bflog和复杂的bflog的逻辑。
-
构建空闲列表
启动后,首先创建一个内部ABA的比特图(bitmap):扫描整个btt map,如果btt_map中相应的ABA已经被占用(最高两个bit不是00),那该ABA的比特就会被置位。然后扫描整个比特图,就可以创建空闲列表存储表示哪些ABA是空闲的,并知道空闲ABA的数目。如Figure 7 扫描btt map后得出的空闲列表所示,一个数组中间存储着所有的空闲的ABA编号,假定此时空闲的数目是10000。
如果空闲块的数目和nlane一样,表明该Arena已经写满,此时我们可以释放空闲列表。比特图只是一个中间过程,最后可以将比特图的空间释放。
| 0 |
200 |
305 |
502 |
620 |
… |
54250 |
… |
Figure 8 扫描btt map后得出的空闲列表
扫描整个btt map可能会占用一定的时间,但是持久内存的顺序读的性能是非常好的,而且只会在初始化的时候扫描,只会影响初始化的时间。在BTT驱动中,将会增加sector namespace的创建时间。
-
通道上的LBA操作
我们设定了nfree和nlane大小相同,我们将空闲列表的最后nlane个空闲块作为各个通道的初始空闲块lane_free[lane],如Figure 8 扫描btt map生成空闲列表,在通道上的LBA操作:
- 需要写lba0数据时,首先从lane_free[0]中得到空闲块,然后将数据写入该空闲块。然后读lba0的对应的btt map条目,如果条目还是初始状态,就从freelist列表中找出一个空闲块赋值给lane_free[0]作为该通道的下一个空闲的ABA。当写完成后,更新lba0对应的btt map条目。
- 需要写lba1数据时,数据将写入通道lane0的空闲数据块lane_free[0], 如果lba1对应的btt map条目不是初始状态,将该条目中的ABA赋给lane_free[0]作为该通道的下一个空闲的ABA。写完成后,更新lba1对应的btt map条目。
所以我们每个通道上的空闲块就构成了一个完整的链条,如果突然断电或重启,我们只需要从新扫描btt map就可以重构整个空闲块的链条[WZ7] [WD8] 。

Figure 9 扫描btt map生成空闲列表,在通道上的LBA操作
在上面的逻辑中,我们不需要构建flog。当空闲列表中的ABA越来越少,空闲块的数目和nlane相同时,我们就可以释放空闲列表,减少对于内存的开销。
-
兼容性的考量
算法的优化可以不改变数据的布局,即原先的bflog的区间仍然保留,但是没有使用任何bflog操作的相关逻辑。这样我们可以通过超级块中的major的信息来知道我们采用什么样的算法。假定我们原有逻辑的major是1,而我们现有逻辑major是2。如果检测到现有的Arena的major是1,保留原有的算法。一旦检测到Arena的major是2,就可以使用最新的算法。
我们可以使用工具通过改变超级块中的major(从1到2),我们可以将原有的算法升级到现有算法,而不会产生任何错误。但是如果从major =2却不能回退到major =1,因为在major =2的算法中,没有任何bflog的操作,从而回退到major =1导致数据的错误。
5、性能状况
Linux内核的NVDIMM BTT驱动可以采用该算法优化,其中kernel的patch可以https://github.com/guoanwu/linux/commits/master或者[PATCH] BTT: Use dram freelist and remove bflog to otpimize perf获得。,重新编译kernel,然后通过创建BTT模式即sector模式,然后测试该块设备的FIO 性能。
-
测试环境
| CPU |
8369B 2.9GHz, 32 cores/socket, 1 socket |
| DRAM |
8 x 32 GB 2666 MHz DDR4 |
| PMEM |
8 * 128GB BPS |
| Kernel Version |
5.17 |
| OS |
CentOS 8.2 |
| Sector Size |
4k (ndctl create-namespace --mode=sector –l 4k) |
| PMem FW |
02.02.00.1553 |
| BIOS Version |
WLYDCRB1.SYS.0020.P93.2103190412 |
| FIO |
https://github.com/axboe/fio |
| FIO命令 |
fio --filename=/dev/pmem0s --direct=1 --iodepth 1 --thread --rw=randwrite --ioengine=psync --bs=4k --time_based --numjobs=$i --runtime=600 --group_reporting --name=mytest --randrepeat=0 --norandommap |
Table 1 测试环境配置
-
Kernel BTT sector 模式下FIO性能
由于读的逻辑基本上没有变化,所以新的算法主要优化了写和读写混合的场景。其中带宽测试使用32个JOB让带宽几乎达到最高值。带宽测试的性能如Figure 10所示:
- 顺序和随机写的带宽提升了41%~55%;
- 读写混合(1R:1W)的带宽提升52%;
- 读写混合(7R:3W)的带宽提升52%。
而延时测试使用1个JOB,让每一个读写请求能够最快的返回。延时测试的性能如图Figure 11所示:
- 顺序或者随机或者混合的写的延时可以降低到原来延时的57%~67%;
- 读的延时基本没有变化,因为我们没有改变读的任何算法逻辑。

Figure 10 BTT带宽优化

Figure 11 BTT 延时优化
6、后续的计划
优化后的算法大大减少了软件的开销,我们可以重新梳理一下相关的存储方案在新的优化上的性能状况。
PMDK中的libpmemblk也使用了BTT相关算法,所以也可以采用该优化。其中优化的代码正在提交审阅https://github.com/pmem/pmdk/pull/5444,相关的测试工作也正在开展。
SPR+CPS可以支持DSA,可以进一步使用DSA来设计和优化BTT。我们也会在后续的工作中测试我们的优化在各代产品的情况。
[i][i] 64-ia-32-architectures-software-developer-manual-325462 Volume 3 Chapter 8
[ii] https://docs.kernel.org/driver-api/nvdimm/btt.html?highlight=btt