Domain Generalization by Solving Jigsaw Puzzles----论文翻译
目录
Abstract
Introduction
The JiGen Approach
Extension to Unsupervised Domain Adaptation
Implementation Details
Experiments
Patch-Based Convolutional Models for Jigsaw Puzzles
Multi-Source Domain Generalization
Conclusions
-
Abstract
人的适应能力主要依赖于通过有监督和无监督学习方法来学习和融合知识的能力:父母指出一些重要的概念,孩子们自己填补空白。这是非常有效的,因为有监督的学习永远不会是详尽无遗的,因此自主学习可以发现有助于归纳的不变性和规律性。在本文中,我们建议对跨域的对象识别任务应用类似的方法:我们的模型以监督的方式学习语义标签,并通过学习自监督的信号如何在相同的图像上解决拼图游戏来拓宽其对数据的理解。这一次要任务有助于网络学习空间相关性的概念,同时充当分类任务的正则化器。在PACS,VLCS,Office-Home和数字数据集上进行的多次实验证实了我们的直觉,并表明这种简单的方法优于以前的域泛化和域适应的解决方案。消融学习进一步说明了我们的方法的内部运作过程.
-
Introduction
在当前对人工智能系统的淘金热中,越来越明显的是,如果没有转换知识,在任务,领域和类别之间有泛化性,那么智能就很有限[11]。计算机视觉研究的很大一部分专门用于有监督方法,这些方法在明确定义的环境中使用卷积神经网络获得显着的结果,但是在尝试这些类型的泛化时仍然很困难。针对跨域泛化的能力,社区迄今为止主要通过有监督学习过程来攻克这个问题,该过程搜索能够捕获基本数据知识的语义空间,而不管输入图像的具体外观如何。现有方法包括将图像样式与共享对象内容[3]分离,将不同域的数据拉到一起并施加对抗条件[28,29],直至生成新样本以更好地覆盖任何未来目标所涵盖的空间[40 ,47]。为了获得通用特征嵌入的类似目的,研究者最近在无监督学习领域中寻求另一种研究方向。主要技术基于定义:对学习通过补丁[36,10,38]的空间共址,计数基元[37],图像着色[50],视频帧排序[33,48]和其他自监督的信号捕获的视觉不变性和规律性有用的任务。
由于未标记的数据在很大程度上是可用的,并且它们本质上不太容易产生偏差(没有标记偏差问题[45]),因此它们似乎是提供独立于特定领域样式的视觉信息的完美候选者。 尽管它们具有巨大的潜力,但现有的无监督方法通常伴随着特定的架构,这些架构需要专门的微调策略来重新设计所获得的知识,并使其可用作标准监督训练过程的输入[38]。 此外,这种知识通常应用于真实世界的照片,并且没有挑战过与具有其他性质的图像比如绘画或者草图的非常大的域间隙.
从图像学习内在规律和跨域的稳健分类之间的这种明显分离与生物系统的视觉学习策略,尤其是人类视觉系统的视觉学习策略形成对比。事实上,许多研究都强调婴儿和幼儿同时学习对物体和相关规律进行分类[2]。例如,婴幼儿的流行玩具通过将它们装入形状分类器来教授识别不同的类别;在12-18个月大的时间里,动物或车辆的拼图游戏鼓励学习对象部分的空间关系。这种类型的联合学习无疑是人类在幼年时期达到复杂视觉概括能力的关键因素[16]。
受此启发,我们提出了第一个端到端架构,该架构同时学习如何跨域泛化以及图像部分的空间共址(图1,2)。在这项工作中,我们专注于从其打乱的部分恢复原始图像的无监督任务,也称为解决拼图游戏。我们展示了如何将这种流行的游戏重新作为一个侧面目标,与不同源域上的对象分类共同优化,并通过简单的多任务流程提高泛化能力[7]。我们将基于Jigsaw puzzle的泛化方法命名为JiGen。与之前处理单独图像补丁并在学习过程结束时重新组合其特征的方法不同[36,10,38],我们在图像级别移动补丁重新组装,并将拼图任务形式化为面对尺寸相同的重组图像与原始图像的分类任务。通过这种方式,对象识别和补丁重新排序可以共享相同的网络主干,并且我们可以无缝地利用任何卷积学习结构以及几个预训练模型,而无需进行特定的体系结构更改。
我们证明JiGen允许更好地捕获多个源域的共享知识,并充当单个源域的正则化工具。 在目标数据的未标记样本在训练时可用的情况下,在它们上运行无监督拼图任务有助于特征适应过程并且显现出对于现有技术的无监督域自适应方法有竞争力的结果。
-
The JiGen Approach
从多个源域的样本开始,我们希望学习一种能够在覆盖同一类别的任何新目标数据集上表现良好的模型。我们假设保留 个域,其中第
个域,其中第 个域包含
个域包含 个带标签的样本对
个带标签的样本对![]() ,其中
,其中![]() 表示第j个图像,
表示第j个图像,![]() 是它的类标签。 JiGen的第一个基本目标是最小化损失
是它的类标签。 JiGen的第一个基本目标是最小化损失![]() ,其计算真实标签y和由深度模型函数h预测的标签之间的误差,由
,其计算真实标签y和由深度模型函数h预测的标签之间的误差,由![]() 和
和 参数化。这些参数定义特征嵌入空间和最终的分类器,相对的是网络的卷积和全连接部分。与此目标一起,我们要求网络满足解决拼图游戏的第二个条件。我们首先使用常规的n×n补丁网格分解源图像,然后将其打乱并重组到
参数化。这些参数定义特征嵌入空间和最终的分类器,相对的是网络的卷积和全连接部分。与此目标一起,我们要求网络满足解决拼图游戏的第二个条件。我们首先使用常规的n×n补丁网格分解源图像,然后将其打乱并重组到 个网格位置之一。跳出
个网格位置之一。跳出![]() 可能的排列我们通过遵循[36]中基于Hamming距离的算法选择一组
可能的排列我们通过遵循[36]中基于Hamming距离的算法选择一组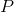 元素,并为每个条目分配一个索引。通过这种方式,我们定义了第二个分类任务,基于
元素,并为每个条目分配一个索引。通过这种方式,我们定义了第二个分类任务,基于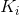 个带标签的实例
个带标签的实例![]() ,其中
,其中![]() 表示重组样本,
表示重组样本,![]() 表示相关的置换指数,我们需要最小化拼图损失
表示相关的置换指数,我们需要最小化拼图损失![]() 。这里深度模型函数h具有与物体分类任务相同的结构,并共享参数
。这里深度模型函数h具有与物体分类任务相同的结构,并共享参数![]() 。专用于置换识别的最终全连接层由
。专用于置换识别的最终全连接层由![]() 参数化。总的来说,我们通过以下loss函数训练网络以获得最佳模型:
参数化。总的来说,我们通过以下loss函数训练网络以获得最佳模型:

其中 和
和 都是标准的交叉熵损失。我们强调拼图损失也是在计算排序的图像。实际上,正确的补丁排序对应于可能的排列之一,并且我们总是将其包括在所考虑的子集
都是标准的交叉熵损失。我们强调拼图损失也是在计算排序的图像。实际上,正确的补丁排序对应于可能的排列之一,并且我们总是将其包括在所考虑的子集![]() 中。反过来,分类loss不受乱序图像的影响,因为这会使对象识别更加困难。在测试时,我们仅使用对象分类器来预测新的目标图像。
中。反过来,分类loss不受乱序图像的影响,因为这会使对象识别更加困难。在测试时,我们仅使用对象分类器来预测新的目标图像。
Extension to Unsupervised Domain Adaptation
无监督域适应的扩展由于拼图游戏任务的无监督性质,我们总是可以在训练时将JiGen扩展到目标域的未标记样本。 这允许我们利用拼图任务进行无监督的域自适应。 在此设置中,对于目标有序图像,我们通过经验熵损失![]() 来最小化分类器预测不确定性,而对于乱序目标图像,我们持续优化拼图
来最小化分类器预测不确定性,而对于乱序目标图像,我们持续优化拼图
损失![]() 。
。
Implementation Details
总体而言,JiGen有两个与我们如何定义拼图任务相关的参数,以及三个与学习过程相关的参数。前两个分别是用于定义图像块的网格大小n×n和补丁置换子集的基数。正如我们将在下一节中详述的那样,JiGen对这些值具有鲁棒性,并且对于我们的所有实验,我们保留它们固定,使用3×3贴片网格并且![]() .其余参数是拼图损失的权重α,并且当包括在用于无监督域自适应的优化过程中时,η被分配给熵损失。最后的第三个参数调节数据输入过程:混洗后的图像与原始有序图像一起进入网络,因此每个图像批次都包含它们。我们定义数据偏差参数β以指定它们的相对比率。例如,
.其余参数是拼图损失的权重α,并且当包括在用于无监督域自适应的优化过程中时,η被分配给熵损失。最后的第三个参数调节数据输入过程:混洗后的图像与原始有序图像一起进入网络,因此每个图像批次都包含它们。我们定义数据偏差参数β以指定它们的相对比率。例如,![]() 意味着对于每个批次,60%的图像被正确排序,而剩余的40%被洗牌。对于每个实验设置,通过对源图像的10%子集的交叉验证来选择这最后三个参数。
意味着对于每个批次,60%的图像被正确排序,而剩余的40%被洗牌。对于每个实验设置,通过对源图像的10%子集的交叉验证来选择这最后三个参数。
我们设计了JiGen网络,使其能够利用许多可能的卷积深度架构。实际上,移除网络的现有最后完全连接层并用新对象和拼图分类层替换它就足够了。 JiGen使用SGD求解器进行训练,30个时期,批量大小128,学习率设置为0.001,并在80%的训练时期后降至0.0001。我们使用简单的数据增强协议,通过随机裁剪图像以保持80-100%和随机应用的水平翻转。沿用[38]我们随机(10%概率)将图像块转换为灰度。的增益。由于[14]没有在VLCS数据集上显示D-SAM的结果,我们使用作者提供的代码来运行这些实验。获得的结果表明,尽管通常能够在PACS和Office-Home中跨越不同样式的图像来关闭大的域间隙,但是当处理来自真实世界图像的域时,聚合模块的使用不支持泛化。
-
Experiments
Patch-Based Convolutional Models for Jigsaw Puzzles
我们通过评估现有拼图相关的基于补丁的卷积体系结构和模型在域泛化任务中的应用来开始我们的实验分析。我们考虑了两个最近的作品,提出了一个拼图解决方案,用于从常规3×3网格分解的图像中的9个混洗补丁。 [36]和[38]都使用具有9个暹罗分支的无上下文网络(CFN),它们从每个图像补丁中分别提取特征,然后在进入最终分类层之前重新组合它们。具体来说,每个CFN分支都是一个Alexnet [24]直到第一个完全连接的层(fc6),并且所有分支共享它们的权重。最后,将分支的输出连接起来并作为输入提供给下面的完全连接层(fc7)。拼图游戏任务被形式化为补丁变换子集的分类问题,并且一旦网络在混合版本f Imagenet [12]上训练,学习的权重可用于初始化标准Alexnet的conv层,而对于新的目标任务,从头开始训练网络的其余部分。实际上,根据原始作品,学习表示能够从图像捕获与语义相关的内容而不管对象标签。我们按照[36]中的说明进行操作,并从作者提供的重新训练的Jigsaw CFN(J-CFN)模型开始,对PACS数据集进行微调分类,并将所有源域样本聚合在一起。在表1的顶部,我们用J-CFN-Finetune用[36]中提出的拼图模型表示该实验的结果,而用J-CFN-Finetune ++表示[38]中提出的高级模型的结果。在这两种情况下,域上的平均分类准确度低于可以使用标准的Alexnet模型获得预先训练过的Imagenet上的对象分类,并对聚合在一起的所有源数据进行微调。我们用Deep All指出这种基线方法,我们可以在表1的以下中心部分中使用相应的值作为参考。我们可以得出结论,尽管它作为无监督的前置任务具有强大的功能,但在解决拼图游戏时完全忽视对象标签会导致语义信息的丢失,这对于跨域的泛化可能是至关重要的。
为了证明CFN架构的潜力,[36]的作者还使用它来训练Imagenet(C-CFN)上的受监督对象分类模型,并证明它可以产生类似于标准Alexnet的结果。为了进一步测试该网络以了解其特殊的连体结构是否以及有多少可用于提取跨领域的共享知识,我们认为它是JiGen的主要卷积主干。从作者提供的C-CFN模型开始,我们在PACS数据上运行获得的C-CFN-JiGen,以及禁用拼图丢失(α= 0)的普通对象分类版本,我们将其指示为C-CFNDeep所有。从获得的识别精度中我们可以说,将拼图游戏与分类任务相结合可以提供性能的平均改善,这是确认我们直觉的第一个结果。但是,C-CFN-Deep All仍然低于标准Alexnet获得的参考结果。
对于以下所有实验,我们认为JiGen的卷积体系结构使用相同的Alexnet或Resnet主结构构建,始终使用整个图像(有序或混洗),而不是依赖于单独的基于补丁的网络分支。 JCFN-Finetune ++和基于Alexnet的JiGen在具有挑战性的草图领域的每类结果的详细比较显示,对于七个类别中的四个,J-CFN-Finetune ++实际上做得很好,比Deep All更好。 通过JiGen,我们通过在图像级别解决拼图游戏来改进相同类别的Deep All,并且我们保留Deep All的优势以用于其余类别.
Multi-Source Domain Generalization
我们将JiGen的性能与几种最近的域泛化方法进行了比较。 TF是低秩参数化网络,与[27]中的数据集PACS一起呈现。CIDDG是[29]中提出的条件不变深域泛化方法,用于训练具有两个对抗性约束的图像分类:一个在[19]之后最大化整体域混淆,另一个在每个类别中进行相同操作。在DeepC变体中,仅启用了第二个条件。 MLDG [26]是一种元学习方法,它模拟训练期间的训练/测试域转换并利用它们来优化学习模型。 CCSA [34]学习嵌入子空间,其中映射的视觉域在语义上对齐并且最大程度地分离。 MMD-AAE [28]是一种基于对抗性自动编码器的深度方法,通过最大均值差异(MMD)将数据分布与任意先验对齐来学习不变特征表示。 SLRC [13]基于单域不变网络和多个特定域网络,并在它们之间应用低秩约束。 D-SAM [14]是一种基于特定领域聚合模块结合使用以改进模型泛化的方法:它在PACS和Office-Home上提供当前的sota结果。 对于这些方法中的每一种,Deep All基线指示在禁用所有引入的域自适应条件时相应网络的性能。
表1的中部和底部显示了当用作骨干架构Alexnet和Resnet-182时JiGen在数据集PACS上的结果。平均而言,当使用Alexnet时,JiGen产生最佳结果,并且它比Resnet-18的D-SAM参考略差。但请注意,在最后一种情况下,JiGen在四个目标案例中有三个表现优于DSAM,而D-SAM的平均优势仅来自草图上的结果。平均而言,JiGen也优于VLCS和Office-Home数据集上的竞争方法(分别见表2和表3)。特别地,我们注意到VLCS是一个艰难的环境,其中最近的工作相对于相应的Deep All基线(例如TF)仅在准确性方面呈现小
-
Conclusions
在本文中,我们首次展示了通过同时学习分类和内在图像不变性,可以有效地实现跨视觉领域的泛化。我们专注于学习图像部分的空间共置,并提出了一个简单而强大的框架,可以适应各种重新训练的卷积体系结构。我们的方法JiGen可以无缝有效地用于域适应和泛化,如实验结果所示。
我们认为本文为领域适应和概括的新研究主题打开了大门。虽然在这里我们专注于一种特定类型的不变性,但可以学习其他一些规律,从而可能带来更强大的益处。此外,我们的方法的简单性要求测试其在与对象分类不同的应用程序中的有效性,例如语义分段和人员重新识别,其中域移位效应强烈影响野外方法的部署。