图像超分综述:超长文一网打尽图像超分的前世今生 (附核心代码)
文章目录
-
- 一、目的
- 二、研究背景
- 三、存在的问题
- 四、研究现状
- 五、各算法创新点及核心代码总结
-
- SRCNN
- ESPCN
- VDSR
- DRCN
- DRRN
- EDSR
- SRGAN
- ESRGAN
- RDN
- WDSR
- LapSRN
- RCAN
- SAN
- IGNN
- SwinIR
- 六、结语与讨论 (个人理解)
-
- 图像超分的困境
- 图像超分的未来
- 其他
声明:
(1) 本文由博主 Minnie_Vautrin 原创整理,经本人大修后上传。
(2) 本文参考文献与资源众多,由于部分已经无法溯源,若有侵权请联系删改。
一、目的
- 提高图像的分辨率;
- 丰富图像的细节纹理。
二、研究背景
- 智能显示领域:普通摄像头拍摄的图像分辨率一般偏低,不能满足高分辨率的视觉要求。目前 4K 高清显示逐渐走向普及,但很多成像设备拍摄的图片以及老电影的像素分辨率远不及 4K。
- 医学成像领域:医学仪器采集得到的图像分辨率通常偏低,高分辨率医学影像有利于发现微小的病灶。
- 遥感成像领域:遥感成像时卫星或飞机与成像对象之间的距离较远,且受限于传感器技术以及成像设备成本等,采集的图片分辨率低,从而导致目标模糊不清,不利于对图像进行分析。
- 城市视频监控领域:公共监控系统的摄像头受限于成本等因素往往是低分辨率的,而低分辨率的图片或视频不利于后续的人脸识别、车牌识别和目标结构化特征识别等任务 。
- 图像压缩传输领域:为了降低海量数据对传输带宽的压力,图像或视频数据在传输时会进行压缩处理,比如降低图像的分辨率。但是人们对这些图像或视频的清晰度要求是很高的,因此在接收端就需要使用图像超分辨率技术来提升分辨率,尽可能重建出原有的高清图像或视频。
三、存在的问题
- 退化模型的估计:实际解决图像超分辨率重建问题的最大挑战是对退化模型的精确估计。估计退化模型就是在对图像进行超分辨率重建的同时从低分辨率图像中估计出图像的运动信息、模糊信息及噪声信息。现实中由于缺少数据,仅仅从低分辨率图像估计退化模型是很困难的。之前大部分学者都将研究重点放在如何设计准确的图像先验上, 而忽视了退化模型对结果的影响。虽然许多做法都己经取得了很好的重建结果,但是在自然图像上的表现却差强人意,这是由于自然图像的退化模型与算法中假定的模型不相符导致的,这也是为什么现有成熟的算法无法得到推广的主要原因。
- 计算复杂度和稳定性:制约图像超分辨率重建算法不能得到广泛应用的因素还有算法的计算复杂度和稳定性。现有的算法基本是通过牺牲计算代价来提高重建结果的质量, 尤其当放大倍数较大时,计算量平方倍的增加,这导致图像超分处理非常耗时, 因而缺少实际应用的价值。最近,出现一些学者集中于研究如何又快又好地实现图像超分辨率重建。虽然,现有的做法能够重建出质量较高的图像,但是当输入图像不满足算法假定的模型时,就会产生错误的细节。尤其是当学习数据集不完备时,基于学习的方法由于缺乏知识,仅依靠学习模型的泛化能力去预测丢失的高频细节,错误细节的引入是不可避免的。所以,到目前为止现有的图像超分辨率重建算法不具备很强的稳定性。
- 压缩退化和量化误差:在现有的图像超分辨率重建算法中,往往忽略的是图像的压缩降质。事实上,消费级的相机在最后一步输出图像时要图像进行压缩的。另外,受传输条件和存储空间的限制,互联网中出现的图像也都是经过压缩的。图像压缩给超分辨率重建问题带来的影响就是改变了图像的退化模型,而图像的退化模型在超分辨率重建中起到非常重要的作用。例如噪声,当图像被压缩时,降质图像中 的噪声不仅有加性噪声,还有与图像内容有关的乘性噪声。另外,大部分超分辨率重建的工作基于的成像模型都是连续的,并没有考虑数字量化的因素,然而实际处理的图像都是数字的,在量化的过程中不可避免地引入量化误差,而这个误差又会影响到图像的退化模型。
- 客观评价指标:目前,评价超分辨率重建最常用的客观评价指标有峰值信噪比 (Peak Signal Noise Ratio, PSNR)、均方误差 (Mean Square Error, MSE) 和结构相似性 (Structural SIMilarity, SSIM)。这些指标需要用到真实的髙分辨率图像作为参考,评价重建后的图像与真实图像之间的相似度,相似度越髙则认为重建结果越好,反之就越差。然而,这些评价指标并不能充分地反映重建效果的好坏。在做实验比较时,会经常遇到重建图像的主观评价较高而客观评价较低的情况。另外,在对自然图像进行超分辨率重建时,真实的参考图像是很难获取到的,面对此类情况时这些评价指标就失去了作用。因而,研究一项无需参考图像的、与主观评价相一致的图像客观评价指标还是很有意义的。
四、研究现状
- 基于插值:常见的插值方法有最近邻插值、双线性插值、双三次插值。这些方法虽然简单有效,但是都假设图像具有连续性,并没有引入更多有效的信息,往往重建结果的边缘和轮廓较为模糊,纹理恢复效果不佳,性能十分有限。
- 基于重建:该类方法将图像超分辨率重建视为是一个优化重建误差的问题,通过引入先验知识来得到局部最优解。常见的基于重建的算法有凸集投影法 (Projection onto Convex Set, POCS)、 最大后验概率法 (Maximum A Posterior estimation, MAP)、贝叶斯分析方法 (Bayesian Analysis, BA)、迭代反投影法 (Iterative Back Projection, IBP) 等。虽然这类方法通过引入先验信息为图像超分辨率重建过程增加约束条件,进而获得了良好的重建效果。但是这些算法存在明显的收敛不理想等问题。
- 基于学习:卷积神经网络 (Convolutional Neural Network, CNN) 由于其优秀的细节表征能力已经广泛应用于图像超分辨率重建研究,同时 Transformer 也在图像超分辨率领域取得成功。能够隐式地学习图像的先验知识,并利用学习到的先验知识生成效果更好的超分辨率图像。 该类方法中经典的包括 SRCNN、ESPCN、VDSR、DRCN、DRRN、EDSR、SRGAN、ESRGAN、RDN、WDSR、LapSRN、RCAN、SAN、IGNN、SwinIR等。基于学习的图像超分辨率重建算法在重建结果上取得了远超传统算法的优势,但由于对硬件设备和处理时间的高要求导致这些算法中被实际应用的寥寥无几。
五、各算法创新点及核心代码总结
SRCNN
论文:https://arxiv.org/abs/1501.00092
代码:
MatLab http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
TensorFlow https://github.com/tegg89/SRCNN-Tensorflow
Pytorch https://github.com/fuyongXu/SRCNN_Pytorch_1.0
Keras https://github.com/jiantenggei/SRCNN-Keras

- 创新点:基于深度学习的图像超分辨率重建开山之作。对于一张低分辨率图像,首先采用双三次插值 (bicubic) 的方法将其变换到真实高分辨率图像的大小尺寸。将插值后的图像作为卷积神经网络的输入,最后得到重建的高分辨率图像。
- 主观效果:相比传统方法,SRCNN 重建后的图像质量更高。
- 不足:(1) 依赖于图像区域信息;(2) 训练收敛速度太慢;(3) 网络只适用于单一尺度输入。
- 核心代码:
import torch.nn as nn
class SRCNN(nn.Module):
def __init__(self, inputChannel, outputChannel):
super(SRCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(inputChannel, 64, kernel_size=9, padding=9 // 2),
nn.ReLU(inplace=True),
nn.Conv2d(64, 32, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, outputChannel, kernel_size=5, padding=5 // 2),
)
def forward(self, x):
out = self.conv(x)
return out
ESPCN
论文:https://arxiv.org/abs/1609.05158
代码:
MatLab https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
TensorFlow https://github.com/drakelevy/ESPCN-TensorFlow
Pytorch https://github.com/leftthomas/ESPCN

- 创新点:在末端直接使用亚像素卷积的方式来进行上采样。
- 好处:(1) 只在模型末端进行上采样,可以使得在低分辨率空间保留更多的纹理区域,在视频超分中也可以做到实时。(2) 模块末端直接使用亚像素卷积的方式来进行上采样,相比于显示的将低分插值到高分,这种上采样方式可以获得更好的重建效果。
- 不足:只考虑上采样的问题,对于如何学习更加丰富的特征信息和利用没有太多研究。
- 其他:亚像素卷积实际上并不涉及到卷积运算,是一种高效、快速、无参 的像素重排列的上采样方式。由于处理速度很快,其直接用在视频超分中也可以做到实时。因此这种上采样的方式很多时候都成为上采样的首选,经常用在低级计算机视觉领域。
- 核心代码:
import math
import torch
from torch import nn
class ESPCN(nn.Module):
def __init__(self, scale_factor, num_channels=1):
super(ESPCN, self).__init__()
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=5, padding=5//2),
nn.Tanh(),
nn.Conv2d(64, 32, kernel_size=3, padding=3//2),
nn.Tanh(),
)
self.last_part = nn.Sequential(
nn.Conv2d(32, num_channels * (scale_factor ** 2), kernel_size=3, padding=3 // 2),
nn.PixelShuffle(scale_factor)
)
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m.in_channels == 32:
nn.init.normal_(m.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(m.bias.data)
else:
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.last_part(x)
return x
VDSR
论文:https://arxiv.org/abs/1511.04587
代码:
MatLab (1) https://cv.snu.ac.kr/research/VDSR/ (2) https://github.com/huangzehao/caffe-vdsr
TensorFlow https://github.com/Jongchan/tensorflow-vdsr
Pytorch https://github.com/twtygqyy/pytorch-vdsr

- 创新点:(1) 使用足够深的神经网络; (2) 引入残差学习; (3) 更高的学习率; (4) 提出多尺度超分模型。
- 好处:(1) VDSR 加深网络深度使得网络感受野更大, 更好地利用了更大区域的上下文信息。(2) 残差学习加速网络收敛,同时进行高低级别特征信息的融合;(3) 更高的学习率可以加速网络的收敛;(4) VDSR 通过让参数在所有预定义的尺度因子中共享,经济地解决了不同放大尺度的问题。
- 不足:过大的学习率可能造成梯度的爆炸,所以提出梯度裁减的方法来避免。
- 核心代码:
import torch
import torch.nn as nn
from math import sqrt
class Conv_ReLU_Block(nn.Module):
def __init__(self):
super(Conv_ReLU_Block, self).__init__()
self.conv = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.conv(x))
class VDSR(nn.Module):
def __init__(self):
super(VDSR, self).__init__()
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
self.input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
residual = x
out = self.relu(self.input(x))
out = self.residual_layer(out)
out = self.output(out)
out = torch.add(out, residual)
return out
DRCN
论文:https://arxiv.org/pdf/1511.04491.pdf
代码:
MatLab https://cv.snu.ac.kr/research/DRCN/
TensorFlow (1) https://github.com/nullhty/DRCN_Tensorflow (2) https://github.com/jiny2001/deeply-recursive-cnn-tf
Pytorch https://github.com/fungtion/DRCN
Keras https://github.com/ghif/drcn


- 创新点:(1) 提出了深度递归卷积网络,用相同的循环层来替代不同的卷积层;(2) 提出循环监督和使用跳跃连接。
- 好处:(1) 增大网络的感受野;(2) 避免深度网络的梯度消失 / 爆炸问题。
- 核心代码:
import torch.nn as nn
class DRCN(nn.Module):
def __init__(self, n_class):
super(DRCN, self).__init__()
# convolutional encoder
self.enc_feat = nn.Sequential()
self.enc_feat.add_module('conv1', nn.Conv2d(in_channels=1, out_channels=100, kernel_size=5,
padding=2))
self.enc_feat.add_module('relu1', nn.ReLU(True))
self.enc_feat.add_module('pool1', nn.MaxPool2d(kernel_size=2, stride=2))
self.enc_feat.add_module('conv2', nn.Conv2d(in_channels=100, out_channels=150, kernel_size=5,
padding=2))
self.enc_feat.add_module('relu2', nn.ReLU(True))
self.enc_feat.add_module('pool2', nn.MaxPool2d(kernel_size=2, stride=2))
self.enc_feat.add_module('conv3', nn.Conv2d(in_channels=150, out_channels=200, kernel_size=3,
padding=1))
self.enc_feat.add_module('relu3', nn.ReLU(True))
self.enc_dense = nn.Sequential()
self.enc_dense.add_module('fc4', nn.Linear(in_features=200 * 8 * 8, out_features=1024))
self.enc_dense.add_module('relu4', nn.ReLU(True))
self.enc_dense.add_module('drop4', nn.Dropout2d())
self.enc_dense.add_module('fc5', nn.Linear(in_features=1024, out_features=1024))
self.enc_dense.add_module('relu5', nn.ReLU(True))
# label predict layer
self.pred = nn.Sequential()
self.pred.add_module('dropout6', nn.Dropout2d())
self.pred.add_module('predict6', nn.Linear(in_features=1024, out_features=n_class))
# convolutional decoder
self.rec_dense = nn.Sequential()
self.rec_dense.add_module('fc5_', nn.Linear(in_features=1024, out_features=1024))
self.rec_dense.add_module('relu5_', nn.ReLU(True))
self.rec_dense.add_module('fc4_', nn.Linear(in_features=1024, out_features=200 * 8 * 8))
self.rec_dense.add_module('relu4_', nn.ReLU(True))
self.rec_feat = nn.Sequential()
self.rec_feat.add_module('conv3_', nn.Conv2d(in_channels=200, out_channels=150,
kernel_size=3, padding=1))
self.rec_feat.add_module('relu3_', nn.ReLU(True))
self.rec_feat.add_module('pool3_', nn.Upsample(scale_factor=2))
self.rec_feat.add_module('conv2_', nn.Conv2d(in_channels=150, out_channels=100,
kernel_size=5, padding=2))
self.rec_feat.add_module('relu2_', nn.ReLU(True))
self.rec_feat.add_module('pool2_', nn.Upsample(scale_factor=2))
self.rec_feat.add_module('conv1_', nn.Conv2d(in_channels=100, out_channels=1,
kernel_size=5, padding=2))
def forward(self, input_data):
feat = self.enc_feat(input_data)
feat = feat.view(-1, 200 * 8 * 8)
feat_code = self.enc_dense(feat)
pred_label = self.pred(feat_code)
feat_encode = self.rec_dense(feat_code)
feat_encode = feat_encode.view(-1, 200, 8, 8)
img_rec = self.rec_feat(feat_encode)
return pred_label, img_rec
DRRN
论文:https://openaccess.thecvf.com/content_cvpr_2017/html/Tai_Image_Super-Resolution_via_CVPR_2017_paper.html
代码:
MatLab https://github.com/tyshiwo/DRRN_CVPR17
TensorFlow https://github.com/LoSealL/VideoSuperResolution
Pytorch https://github.com/Major357/DRRN-pytorch

- 创新点:(1) 比 VDSR 更深的网络;(2) 递归学习; (3) 残差学习。
- 好处:(1) 越深的网络一般可以得到更好的重建效果;(2) 相当于增加网络深度,权重共享来减少参数量;(3) 避免发生梯度消失 / 爆炸问题。
- 核心代码:
import torch
import torch.nn as nn
from math import sqrt
class DRRN(nn.Module):
def __init__(self):
super(DRRN, self).__init__()
self.input = nn.Conv2d(in_channels=1, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.conv1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=128, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def forward(self, x):
residual = x
inputs = self.input(self.relu(x))
out = inputs
for _ in range(25):
out = self.conv2(self.relu(self.conv1(self.relu(out))))
out = torch.add(out, inputs)
out = self.output(self.relu(out))
out = torch.add(out, residual)
return out
EDSR
论文:https://arxiv.org/abs/1707.02921
代码:
TensorFlow https://github.com/jmiller656/EDSR-Tensorflow
Pytorch (1) https://github.com/sanghyun-son/EDSR-PyTorch (2) https://github.com/thstkdgus35/EDSR-PyTorch

- 创新点:(1) 移除 BatchNorm 层;(2) 提出带有单一主分支的的多尺度木块,先训练低倍超分模型,再在其基础上训练高倍超分模型。
- 好处:(1) 模型更加轻量,也能更好地表达图像特征;(2) 权值共享,减少高倍超分模型训练时间,同时重建效果更好。
- 移除 BN 层的原因:
BatchNorm 是深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,防止网络过拟合,因此 BatchNorm 在 CNN 中被大量使用。但在图像超分辨率和图像生成与恢复方面,BatchNorm 的表现并不好,它反而使得网络训练速度缓慢,不稳定,甚至最后发散。
BatchNorm 会忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只考虑相对差异,所以在不需要绝对差异的任务中(比如分类),有锦上添花的效果。而对于图像超分辨率这种需要利用绝对差异的任务,BatchNorm 并不适用。此外,由于 BatchNorm 消耗与它前面的卷积层相同大小的内存,去掉后在相同的计算资源下,EDSR 可以堆叠更多的网络层或者使每层提取更多的特征,从而获得更好的表现。
参考:https://blog.csdn.net/sinat_36197913/article/details/104845599 - 核心代码:
class EDSR(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(EDSR, self).__init__()
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
scale = args.scale[0]
act = nn.ReLU(True)
self.sub_mean = common.MeanShift(args.rgb_range)
self.add_mean = common.MeanShift(args.rgb_range, sign=1)
# define head module
m_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
m_body = [
common.ResBlock(
conv, n_feats, kernel_size, act=act, res_scale=args.res_scale
) for _ in range(n_resblocks)
]
m_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
m_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)
]
self.head = nn.Sequential(*m_head)
self.body = nn.Sequential(*m_body)
self.tail = nn.Sequential(*m_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
SRGAN
论文:http://arxiv.org/abs/1609.04802
代码:
MatLab https://github.com/ShenghaiRong/caffe_srgan
TensorFlow (1) https://github.com/brade31919/SRGAN-tensorflow (2) https://github.com/zsdonghao/SRGAN (3) https://github.com/buriburisuri/SRGAN
Pytorch (1) https://github.com/zzbdr/DL/tree/main/Super-resolution/SRGAN (2) https://github.com/aitorzip/PyTorch-SRGAN
Keras (1) https://github.com/jiantenggei/srgan (2) https://github.com/jiantenggei/Srgan_ (3) https://github.com/titu1994/Super-Resolution-using-Generative-Adversarial-Networks

- 创新点:(1) 使用 GAN 进行超分重建;(2) 根据 VGG 网络提取的特征图间的欧氏距离提出一种新的感知损失替换基于 MSE 内容丢失;(3) 提出一种新的图像质量评价指标 Mean Opinion Score (MOS)。
- 好处:(1) GAN网络可以产生具有高感知质量的图像,从而得到让人肉眼感官更加舒适的高分图像;(2) 更高层的图像特征会产生更多的图像细节,在特征图计算损失使其可以重建出视觉上更好的高分图像;(3) 对于重建图像的评价更加符合人眼视觉效果。
- MSE 损失函数的局限性:虽然直接优化 MSE 可以产生较高的 PSNR / SSIM,但是在放大倍数较大的情况下,MSE 损失引导的学习无法使得重建图像捕获细节信息。
- 为什么不用 PSNR / SSIM 评价图像质量:众所周知,PSNR 值的大小并不能绝对真实地反应图像的质量,SSIM 相比 PSNR 对图像质量的评价更接近人眼的视觉效果。但在本文中,作者认为这两个指标都不够准确,因此提出平均意见得分 MOS。
- 核心代码:
import torch.nn as nn
class Block(nn.Module):
def __init__(self, input_channel=64, output_channel=64, kernel_size=3, stride=1, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel),
nn.PReLU(),
nn.Conv2d(output_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel)
)
def forward(self, x0):
x1 = self.layer(x0)
return x0 + x1
class Generator(nn.Module):
def __init__(self, scale=2):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 9, stride=1, padding=4),
nn.PReLU()
)
self.residual_block = nn.Sequential(
Block(),
Block(),
Block(),
Block(),
Block(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
)
self.conv4 = nn.Conv2d(64, 3, 9, stride=1, padding=4)
def forward(self, x):
x0 = self.conv1(x)
x = self.residual_block(x0)
x = self.conv2(x)
x = self.conv3(x + x0)
x = self.conv4(x)
return x
class DownSalmpe(nn.Module):
def __init__(self, input_channel, output_channel, stride, kernel_size=3, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding),
nn.BatchNorm2d(output_channel),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
x = self.layer(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1),
nn.LeakyReLU(inplace=True),
)
self.down = nn.Sequential(
DownSalmpe(64, 64, stride=2, padding=1),
DownSalmpe(64, 128, stride=1, padding=1),
DownSalmpe(128, 128, stride=2, padding=1),
DownSalmpe(128, 256, stride=1, padding=1),
DownSalmpe(256, 256, stride=2, padding=1),
DownSalmpe(256, 512, stride=1, padding=1),
DownSalmpe(512, 512, stride=2, padding=1),
)
self.dense = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
x = self.down(x)
x = self.dense(x)
return x
ESRGAN
论文:https://arxiv.org/abs/1809.00219
代码:
Pytorch https://github.com/xinntao/ESRGAN


- 创新点:(1) 提出 Residual-in-Residual Dense Block (RRDB) 结构,并去掉去掉 BatchNorm 层; (2) 借鉴 Relativistic GAN 的想法,让判别器预测图像的真实性而不是图像“是否是 fake 图像”;(3) 使用激活前的特征计算感知损失。
- 好处:(1) 密集连接可以更好地融合特征和加速训练,更加提升恢复得到的纹理(因为深度模型具有强大的表示能力来捕获语义信息),而且可以去除噪声,同时去掉 BatchNorm 可以获得更好的效果;(2) 让重建的图像更加接近真实图像;(3) 激活前的特征会提供更尖锐的边缘和更符合视觉的结果。
- 核心代码:
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
def make_layer(block, n_layers):
layers = []
for _ in range(n_layers):
layers.append(block())
return nn.Sequential(*layers)
class ResidualDenseBlock_5C(nn.Module):
def __init__(self, nf=64, gc=32, bias=True):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = nn.Conv2d(nf, gc, 3, 1, 1, bias=bias)
self.conv2 = nn.Conv2d(nf + gc, gc, 3, 1, 1, bias=bias)
self.conv3 = nn.Conv2d(nf + 2 * gc, gc, 3, 1, 1, bias=bias)
self.conv4 = nn.Conv2d(nf + 3 * gc, gc, 3, 1, 1, bias=bias)
self.conv5 = nn.Conv2d(nf + 4 * gc, nf, 3, 1, 1, bias=bias)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
# initialization
# mutil.initialize_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5 * 0.2 + x
class RRDB(nn.Module):
'''Residual in Residual Dense Block'''
def __init__(self, nf, gc=32):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nf, gc)
self.RDB2 = ResidualDenseBlock_5C(nf, gc)
self.RDB3 = ResidualDenseBlock_5C(nf, gc)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out * 0.2 + x
class RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32):
super(RRDBNet, self).__init__()
RRDB_block_f = functools.partial(RRDB, nf=nf, gc=gc)
self.conv_first = nn.Conv2d(in_nc, nf, 3, 1, 1, bias=True)
self.RRDB_trunk = make_layer(RRDB_block_f, nb)
self.trunk_conv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
#### upsampling
self.upconv1 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.upconv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.HRconv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.conv_last = nn.Conv2d(nf, out_nc, 3, 1, 1, bias=True)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
def forward(self, x):
fea = self.conv_first(x)
trunk = self.trunk_conv(self.RRDB_trunk(fea))
fea = fea + trunk
fea = self.lrelu(self.upconv1(F.interpolate(fea, scale_factor=2, mode='nearest')))
fea = self.lrelu(self.upconv2(F.interpolate(fea, scale_factor=2, mode='nearest')))
out = self.conv_last(self.lrelu(self.HRconv(fea)))
return out
RDN
论文:https://arxiv.org/abs/1802.08797
代码:
TensorFlow https://github.com/hengchuan/RDN-TensorFlow
Pytorch https://github.com/lizhengwei1992/ResidualDenseNetwork-Pytorch

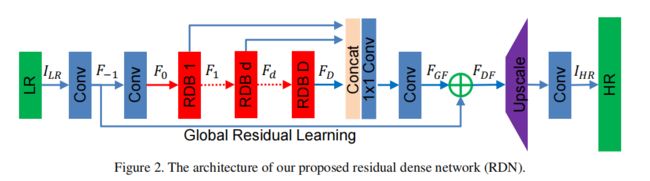
- 创新点:提出Residual Dense Block (RDB) 结构;
- 好处:残差学习和密集连接有效缓解网络深度增加引发的梯度消失的现象,其中密集连接加强特征传播, 鼓励特征复用。
- 核心代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class sub_pixel(nn.Module):
def __init__(self, scale, act=False):
super(sub_pixel, self).__init__()
modules = []
modules.append(nn.PixelShuffle(scale))
self.body = nn.Sequential(*modules)
def forward(self, x):
x = self.body(x)
return x
class make_dense(nn.Module):
def __init__(self, nChannels, growthRate, kernel_size=3):
super(make_dense, self).__init__()
self.conv = nn.Conv2d(nChannels, growthRate, kernel_size=kernel_size, padding=(kernel_size-1)//2, bias=False)
def forward(self, x):
out = F.relu(self.conv(x))
out = torch.cat((x, out), 1)
return out
# Residual dense block (RDB) architecture
class RDB(nn.Module):
def __init__(self, nChannels, nDenselayer, growthRate):
super(RDB, self).__init__()
nChannels_ = nChannels
modules = []
for i in range(nDenselayer):
modules.append(make_dense(nChannels_, growthRate))
nChannels_ += growthRate
self.dense_layers = nn.Sequential(*modules)
self.conv_1x1 = nn.Conv2d(nChannels_, nChannels, kernel_size=1, padding=0, bias=False)
def forward(self, x):
out = self.dense_layers(x)
out = self.conv_1x1(out)
out = out + x
return out
# Residual Dense Network
class RDN(nn.Module):
def __init__(self, args):
super(RDN, self).__init__()
nChannel = args.nChannel
nDenselayer = args.nDenselayer
nFeat = args.nFeat
scale = args.scale
growthRate = args.growthRate
self.args = args
# F-1
self.conv1 = nn.Conv2d(nChannel, nFeat, kernel_size=3, padding=1, bias=True)
# F0
self.conv2 = nn.Conv2d(nFeat, nFeat, kernel_size=3, padding=1, bias=True)
# RDBs 3
self.RDB1 = RDB(nFeat, nDenselayer, growthRate)
self.RDB2 = RDB(nFeat, nDenselayer, growthRate)
self.RDB3 = RDB(nFeat, nDenselayer, growthRate)
# global feature fusion (GFF)
self.GFF_1x1 = nn.Conv2d(nFeat*3, nFeat, kernel_size=1, padding=0, bias=True)
self.GFF_3x3 = nn.Conv2d(nFeat, nFeat, kernel_size=3, padding=1, bias=True)
# Upsampler
self.conv_up = nn.Conv2d(nFeat, nFeat*scale*scale, kernel_size=3, padding=1, bias=True)
self.upsample = sub_pixel(scale)
# conv
self.conv3 = nn.Conv2d(nFeat, nChannel, kernel_size=3, padding=1, bias=True)
def forward(self, x):
F_ = self.conv1(x)
F_0 = self.conv2(F_)
F_1 = self.RDB1(F_0)
F_2 = self.RDB2(F_1)
F_3 = self.RDB3(F_2)
FF = torch.cat((F_1, F_2, F_3), 1)
FdLF = self.GFF_1x1(FF)
FGF = self.GFF_3x3(FdLF)
FDF = FGF + F_
us = self.conv_up(FDF)
us = self.upsample(us)
output = self.conv3(us)
return output
WDSR
论文:https://arxiv.org/abs/1808.08718
代码:
TensorFlow https://github.com/ychfan/tf_estimator_barebone
Pytorch https://github.com/JiahuiYu/wdsr_ntire2018
Keras https://github.com/krasserm/super-resolution


- 创新点:(1) 增多激活函数前的特征图通道数,即宽泛特征图;(2) Weight Normalization;(3) 两个分支进行相同的上采样操作,直接相加得到高分图像。
- 好处:(1) 激活函数会阻止信息流的传递,通过增加特征图通道数可以降低激活函数对信息流的影响;(2) 网络的训练速度和性能都有提升,同时也使得训练可以使用较大的学习率;(3) 大卷积核拆分成两个小卷积核,可以节省参数。
- 核心代码:
import torch
import torch.nn as nn
class Block(nn.Module):
def __init__(
self, n_feats, kernel_size, wn, act=nn.ReLU(True), res_scale=1):
super(Block, self).__init__()
self.res_scale = res_scale
body = []
expand = 6
linear = 0.8
body.append(
wn(nn.Conv2d(n_feats, n_feats*expand, 1, padding=1//2)))
body.append(act)
body.append(
wn(nn.Conv2d(n_feats*expand, int(n_feats*linear), 1, padding=1//2)))
body.append(
wn(nn.Conv2d(int(n_feats*linear), n_feats, kernel_size, padding=kernel_size//2)))
self.body = nn.Sequential(*body)
def forward(self, x):
res = self.body(x) * self.res_scale
res += x
return res
class MODEL(nn.Module):
def __init__(self, args):
super(MODEL, self).__init__()
# hyper-params
self.args = args
scale = args.scale[0]
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
act = nn.ReLU(True)
# wn = lambda x: x
wn = lambda x: torch.nn.utils.weight_norm(x)
self.rgb_mean = torch.autograd.Variable(torch.FloatTensor(
[args.r_mean, args.g_mean, args.b_mean])).view([1, 3, 1, 1])
# define head module
head = []
head.append(
wn(nn.Conv2d(args.n_colors, n_feats, 3, padding=3//2)))
# define body module
body = []
for i in range(n_resblocks):
body.append(
Block(n_feats, kernel_size, act=act, res_scale=args.res_scale, wn=wn))
# define tail module
tail = []
out_feats = scale*scale*args.n_colors
tail.append(
wn(nn.Conv2d(n_feats, out_feats, 3, padding=3//2)))
tail.append(nn.PixelShuffle(scale))
skip = []
skip.append(
wn(nn.Conv2d(args.n_colors, out_feats, 5, padding=5//2))
)
skip.append(nn.PixelShuffle(scale))
# make object members
self.head = nn.Sequential(*head)
self.body = nn.Sequential(*body)
self.tail = nn.Sequential(*tail)
self.skip = nn.Sequential(*skip)
def forward(self, x):
x = (x - self.rgb_mean.cuda()*255)/127.5
s = self.skip(x)
x = self.head(x)
x = self.body(x)
x = self.tail(x)
x += s
x = x*127.5 + self.rgb_mean.cuda()*255
return x
LapSRN
论文:https://arxiv.org/abs/1704.03915
代码:
MatLab https://github.com/phoenix104104/LapSRN
TensorFlow https://github.com/zjuela/LapSRN-tensorflow
Pytorch https://github.com/twtygqyy/pytorch-LapSRN

- 创新点:(1) 提出一种级联的金字塔结构;(2) 提出一种新的损失函数。
- 好处:(1) 降低计算复杂度,同时低级特征与高级特征来增加网络的非线性,从而更好地学习和映射细节特征。此外,金字塔结构也使得该算法可以一次就完成多个尺度;(2) MSE 损失会导致重建的高分图像细节模糊和平滑,新的损失函数可以改善这一点。
- 拉普拉斯图像金字塔:https://www.jianshu.com/p/e3570a9216a6
- 核心代码:
import torch
import torch.nn as nn
import numpy as np
import math
def get_upsample_filter(size):
"""Make a 2D bilinear kernel suitable for upsampling"""
factor = (size + 1) // 2
if size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:size, :size]
filter = (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
return torch.from_numpy(filter).float()
class _Conv_Block(nn.Module):
def __init__(self):
super(_Conv_Block, self).__init__()
self.cov_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(in_channels=64, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
)
def forward(self, x):
output = self.cov_block(x)
return output
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv_input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.LeakyReLU(0.2, inplace=True)
self.convt_I1 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=4, stride=2, padding=1, bias=False)
self.convt_R1 = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.convt_F1 = self.make_layer(_Conv_Block)
self.convt_I2 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=4, stride=2, padding=1, bias=False)
self.convt_R2 = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.convt_F2 = self.make_layer(_Conv_Block)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
if isinstance(m, nn.ConvTranspose2d):
c1, c2, h, w = m.weight.data.size()
weight = get_upsample_filter(h)
m.weight.data = weight.view(1, 1, h, w).repeat(c1, c2, 1, 1)
if m.bias is not None:
m.bias.data.zero_()
def make_layer(self, block):
layers = []
layers.append(block())
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.conv_input(x))
convt_F1 = self.convt_F1(out)
convt_I1 = self.convt_I1(x)
convt_R1 = self.convt_R1(convt_F1)
HR_2x = convt_I1 + convt_R1
convt_F2 = self.convt_F2(convt_F1)
convt_I2 = self.convt_I2(HR_2x)
convt_R2 = self.convt_R2(convt_F2)
HR_4x = convt_I2 + convt_R2
return HR_2x, HR_4x
RCAN
论文:https://arxiv.org/abs/1807.02758
代码:
TensorFlow (1) https://github.com/dongheehand/RCAN-tf (2) https://github.com/keerthan2/Residual-Channel-Attention-Network
Pytorch https://github.com/yulunzhang/RCAN


- 创新点:(1) 使用通道注意力来加强特征学习;(2) 提出 Residual In Residual (RIR) 结构;
- 好处:(1) 通过特征不同通道的特征来重新调整每一通道的权重;(2) 多个残差组和长跳跃连接构建粗粒度的残差学习,在残差组内部再堆叠多个简化的残差块并采用短跳跃连接 (大的残差内部嵌入小残差),使得高低频充分融合,同时加速网络训练和稳定性。
- 核心代码:
from model import common
import torch.nn as nn
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=16):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
## Residual Channel Attention Block (RCAB)
class RCAB(nn.Module):
def __init__(
self, conv, n_feat, kernel_size, reduction,
bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(RCAB, self).__init__()
modules_body = []
for i in range(2):
modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias))
if bn: modules_body.append(nn.BatchNorm2d(n_feat))
if i == 0: modules_body.append(act)
modules_body.append(CALayer(n_feat, reduction))
self.body = nn.Sequential(*modules_body)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x)
res += x
return res
## Residual Group (RG)
class ResidualGroup(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(ResidualGroup, self).__init__()
modules_body = []
modules_body = [
RCAB(
conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True), res_scale=1) \
for _ in range(n_resblocks)]
modules_body.append(conv(n_feat, n_feat, kernel_size))
self.body = nn.Sequential(*modules_body)
def forward(self, x):
res = self.body(x)
res += x
return res
## Residual Channel Attention Network (RCAN)
class RCAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(RCAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
modules_body = [
ResidualGroup(
conv, n_feats, kernel_size, reduction, act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) \
for _ in range(n_resgroups)]
modules_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.head = nn.Sequential(*modules_head)
self.body = nn.Sequential(*modules_body)
self.tail = nn.Sequential(*modules_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
SAN
论文:https://csjcai.github.io/papers/SAN.pdf
代码:
Pytorch https://github.com/daitao/SAN

- 创新点:(1) 提出二阶注意力机制 Second-order Channel Attention (SOCA);(2) 提出非局部增强残差组 Non-Locally Enhanced Residual Group (NLRG) 结构。
- 好处:(1) 通过二阶特征的分布自适应学习特征的内部依赖关系,使得网络能够专注于更有益的信息且能够提高判别学习的能力;(2) 非局部操作可以聚合上下文信息,同时利用残差结构来训练深度网络,加速和稳定网络训练过程。
- 核心代码:
from model import common
import torch
import torch.nn as nn
import torch.nn.functional as F
from model.MPNCOV.python import MPNCOV
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, mode='embedded_gaussian', sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, mode=mode,
sub_sample=sub_sample,
bn_layer=bn_layer)
## Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel, reduction=8):
super(CALayer, self).__init__()
# global average pooling: feature --> point
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
)
def forward(self, x):
_,_,h,w = x.shape
y_ave = self.avg_pool(x)
y_ave = self.conv_du(y_ave)
return y_ave
## second-order Channel attention (SOCA)
class SOCA(nn.Module):
def __init__(self, channel, reduction=8):
super(SOCA, self).__init__()
self.max_pool = nn.MaxPool2d(kernel_size=2)
# feature channel downscale and upscale --> channel weight
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
batch_size, C, h, w = x.shape # x: NxCxHxW
N = int(h * w)
min_h = min(h, w)
h1 = 1000
w1 = 1000
if h < h1 and w < w1:
x_sub = x
elif h < h1 and w > w1:
# H = (h - h1) // 2
W = (w - w1) // 2
x_sub = x[:, :, :, W:(W + w1)]
elif w < w1 and h > h1:
H = (h - h1) // 2
# W = (w - w1) // 2
x_sub = x[:, :, H:H + h1, :]
else:
H = (h - h1) // 2
W = (w - w1) // 2
x_sub = x[:, :, H:(H + h1), W:(W + w1)]
## MPN-COV
cov_mat = MPNCOV.CovpoolLayer(x_sub) # Global Covariance pooling layer
cov_mat_sqrt = MPNCOV.SqrtmLayer(cov_mat,5) # Matrix square root layer( including pre-norm,Newton-Schulz iter. and post-com. with 5 iteration)
cov_mat_sum = torch.mean(cov_mat_sqrt,1)
cov_mat_sum = cov_mat_sum.view(batch_size,C,1,1)
y_cov = self.conv_du(cov_mat_sum)
return y_cov*x
## self-attention+ channel attention module
class Nonlocal_CA(nn.Module):
def __init__(self, in_feat=64, inter_feat=32, reduction=8,sub_sample=False, bn_layer=True):
super(Nonlocal_CA, self).__init__()
# second-order channel attention
self.soca=SOCA(in_feat, reduction=reduction)
# nonlocal module
self.non_local = (NONLocalBlock2D(in_channels=in_feat,inter_channels=inter_feat, sub_sample=sub_sample,bn_layer=bn_layer))
self.sigmoid = nn.Sigmoid()
def forward(self,x):
## divide feature map into 4 part
batch_size,C,H,W = x.shape
H1 = int(H / 2)
W1 = int(W / 2)
nonlocal_feat = torch.zeros_like(x)
feat_sub_lu = x[:, :, :H1, :W1]
feat_sub_ld = x[:, :, H1:, :W1]
feat_sub_ru = x[:, :, :H1, W1:]
feat_sub_rd = x[:, :, H1:, W1:]
nonlocal_lu = self.non_local(feat_sub_lu)
nonlocal_ld = self.non_local(feat_sub_ld)
nonlocal_ru = self.non_local(feat_sub_ru)
nonlocal_rd = self.non_local(feat_sub_rd)
nonlocal_feat[:, :, :H1, :W1] = nonlocal_lu
nonlocal_feat[:, :, H1:, :W1] = nonlocal_ld
nonlocal_feat[:, :, :H1, W1:] = nonlocal_ru
nonlocal_feat[:, :, H1:, W1:] = nonlocal_rd
return nonlocal_feat
## Residual Block (RB)
class RB(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(inplace=True), res_scale=1, dilation=2):
super(RB, self).__init__()
modules_body = []
self.gamma1 = 1.0
self.conv_first = nn.Sequential(conv(n_feat, n_feat, kernel_size, bias=bias),
act,
conv(n_feat, n_feat, kernel_size, bias=bias))
self.res_scale = res_scale
def forward(self, x):
y = self.conv_first(x)
y = y + x
return y
## Local-source Residual Attention Group (LSRARG)
class LSRAG(nn.Module):
def __init__(self, conv, n_feat, kernel_size, reduction, act, res_scale, n_resblocks):
super(LSRAG, self).__init__()
##
self.rcab= nn.ModuleList([RB(conv, n_feat, kernel_size, reduction, \
bias=True, bn=False, act=nn.ReLU(inplace=True), res_scale=1) for _ in range(n_resblocks)])
self.soca = (SOCA(n_feat,reduction=reduction))
self.conv_last = (conv(n_feat, n_feat, kernel_size))
self.n_resblocks = n_resblocks
self.gamma = nn.Parameter(torch.zeros(1))
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block)
return nn.ModuleList(layers)
def forward(self, x):
residual = x
for i,l in enumerate(self.rcab):
x = l(x)
x = self.soca(x)
x = self.conv_last(x)
x = x + residual
return x
# Second-order Channel Attention Network (SAN)
class SAN(nn.Module):
def __init__(self, args, conv=common.default_conv):
super(SAN, self).__init__()
n_resgroups = args.n_resgroups
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
reduction = args.reduction
scale = args.scale[0]
act = nn.ReLU(inplace=True)
# RGB mean for DIV2K
rgb_mean = (0.4488, 0.4371, 0.4040)
rgb_std = (1.0, 1.0, 1.0)
self.sub_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std)
# define head module
modules_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
## share-source skip connection
self.gamma = nn.Parameter(torch.zeros(1))
self.n_resgroups = n_resgroups
self.RG = nn.ModuleList([LSRAG(conv, n_feats, kernel_size, reduction, \
act=act, res_scale=args.res_scale, n_resblocks=n_resblocks) for _ in range(n_resgroups)])
self.conv_last = conv(n_feats, n_feats, kernel_size)
# define tail module
modules_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)]
self.add_mean = common.MeanShift(args.rgb_range, rgb_mean, rgb_std, 1)
self.non_local = Nonlocal_CA(in_feat=n_feats, inter_feat=n_feats//8, reduction=8,sub_sample=False, bn_layer=False)
self.head = nn.Sequential(*modules_head)
self.tail = nn.Sequential(*modules_tail)
def make_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block)
return nn.ModuleList(layers)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
## add nonlocal
xx = self.non_local(x)
# share-source skip connection
residual = xx
# share-source residual gruop
for i,l in enumerate(self.RG):
xx = l(xx) + self.gamma*residual
## add nonlocal
res = self.non_local(xx)
res = res + x
x = self.tail(res)
x = self.add_mean(x)
return x
IGNN
论文:https://proceedings.neurips.cc/paper/2020/file/8b5c8441a8ff8e151b191c53c1842a38-Paper.pdf
代码:
Pytorch https://github.com/sczhou/IGNN
- 创新点:(1) 提出非局部图卷积聚合模块 non-locally Graph convolution Aggregation (GraphAgg) ,进而提出隐式神经网络 Implicit Graph Neural Network (IGNN)。
- 好处:(1) 巧妙地为每个低分图像找到多个高分图像块近邻,再构建出低分到高分的连接图,进而将多个高分图像的纹理信息聚合在低分图像上,从而实现超分重建。
- 核心代码:
from models.submodules import *
from models.VGG19 import VGG19
from config import cfg
class IGNN(nn.Module):
def __init__(self):
super(IGNN, self).__init__()
kernel_size = 3
n_resblocks = cfg.NETWORK.N_RESBLOCK
n_feats = cfg.NETWORK.N_FEATURE
n_neighbors = cfg.NETWORK.N_REIGHBOR
scale = cfg.CONST.SCALE
if cfg.CONST.SCALE == 4:
scale = 2
window = cfg.NETWORK.WINDOW_SIZE
gcn_stride = 2
patch_size = 3
self.sub_mean = MeanShift(rgb_range=cfg.DATA.RANGE, sign=-1)
self.add_mean = MeanShift(rgb_range=cfg.DATA.RANGE, sign=1)
self.vggnet = VGG19([3])
self.graph = Graph(scale, k=n_neighbors, patchsize=patch_size, stride=gcn_stride,
window_size=window, in_channels=256, embedcnn=self.vggnet)
# define head module
self.head = conv(3, n_feats, kernel_size, act=False)
# middle 16
pre_blocks = int(n_resblocks//2)
# define body module
m_body1 = [
ResBlock(
n_feats, kernel_size, res_scale=cfg.NETWORK.RES_SCALE
) for _ in range(pre_blocks)
]
m_body2 = [
ResBlock(
n_feats, kernel_size, res_scale=cfg.NETWORK.RES_SCALE
) for _ in range(n_resblocks-pre_blocks)
]
m_body2.append(conv(n_feats, n_feats, kernel_size, act=False))
fuse_b = [
conv(n_feats*2, n_feats, kernel_size),
conv(n_feats, n_feats, kernel_size, act=False) # act=False important for relu!!!
]
fuse_up = [
conv(n_feats*2, n_feats, kernel_size),
conv(n_feats, n_feats, kernel_size)
]
if cfg.CONST.SCALE == 4:
m_tail = [
upsampler(n_feats, kernel_size, scale, act=False),
conv(n_feats, 3, kernel_size, act=False) # act=False important for relu!!!
]
else:
m_tail = [
conv(n_feats, 3, kernel_size, act=False) # act=False important for relu!!!
]
self.body1 = nn.Sequential(*m_body1)
self.gcn = GCNBlock(n_feats, scale, k=n_neighbors, patchsize=patch_size, stride=gcn_stride)
self.fuse_b = nn.Sequential(*fuse_b)
self.body2 = nn.Sequential(*m_body2)
self.upsample = upsampler(n_feats, kernel_size, scale, act=False)
self.fuse_up = nn.Sequential(*fuse_up)
self.tail = nn.Sequential(*m_tail)
def forward(self, x_son, x):
score_k, idx_k, diff_patch = self.graph(x_son, x)
idx_k = idx_k.detach()
if cfg.NETWORK.WITH_DIFF:
diff_patch = diff_patch.detach()
x = self.sub_mean(x)
x0 = self.head(x)
x1 = self.body1(x0)
x1_lr, x1_hr = self.gcn(x1, idx_k, diff_patch)
x1 = self.fuse_b(torch.cat([x1, x1_lr], dim=1))
x2 = self.body2(x1) + x0
x = self.upsample(x2)
x = self.fuse_up(torch.cat([x, x1_hr], dim=1))
x= self.tail(x)
x = self.add_mean(x)
return x
SwinIR
论文:https://arxiv.org/pdf/2108.10257.pdf
代码:
Pytorch https://github.com/JingyunLiang/SwinIR

- 创新点:(1) 使用 Swin Transformer 进行图像超分、去噪等任务;(2) 将 Transformer 与 CNN 结合使用。
- 好处:(1) Transformer 可以有效捕捉长距离依赖,Swin Transformer 将自注意力计算限制在分割的不重叠窗口内从而降低计算量;(2) 使用 CNN 在 Transformer Layer 后避免原论文中的层级结构,实现即插即用,同时研究表明在 Transformer 中 CNN 可以稳定训练过程与融合特征。
- 代码及注释参考:https://blog.csdn.net/Wenyuanbo/article/details/121264131
六、结语与讨论 (个人理解)
图像超分的困境
- 定量指标的提升越来越困难;
- 大多数算法无法在移动端部署或实际应用;
- 基于纯 CNN 的超分重建算法逐渐不具优势;
- 少有真正基于超分需求建立的网络,多数是通用型架构;
- 通用数据集的训练结果在真实图像或专业领域图像上泛化不佳;
- 常用的客观评价指标与人眼视觉效果间仍存在一定差异;
- 全监督的算法往往需要人工产生低分或高分图像;
- 难以获得真实世界的低分与对应的高分图像来构建真实数据集;
- 现有的多数超分重建算法彻底抛弃传统的一些方法,导致这些算法的可解释性差;
- 尚没有在图像超分领域有足够地位的 baseline。
图像超分的未来
- 主观评价指标上尚有进步空间;
- 视频超分的研究越来越多;
- 超大倍数的超分可能会逐渐引起关注;
- 算法的速度与计算负担将被重点考虑;
- 与传统方法结合的深度学习算法更容易被认可;
- CNN 与 Transformer 结合的算法将在图像超分领域持续,最终可能归于 MLP (Mixer);
- 图像超分与其他方向结合的算法逐渐变多,诸如超分目标检测、超分语义分割、超分图像修复超分图像融合等;
- 旧的数据集由于定量指标难以提高,可能会有一些更难更真实的新数据集出现;
- 无监督或半监督的方向成为主流;
- 图像超分不再关注限制得放大倍数,而是任意尺度;
- 出现许多更加具体场景的超分算法 ;等。
其他
- 对于初学者这里是一个简单易懂的代码实现 (附注释):图像超分 Pytorch 学习代码。
- 随着深度学习框架的发展,从一开始在图像超分领域常见的 Caffe、TensorFlow、Keras 和 Pytorch 等已经基本发展为 Pytorch 一家独大,所以建议直接入手 Pytorch。