CIFAR-10 分类 pytorch
前言
上一篇博客挖了个坑,准备使用cifar-10来进行演示。
再加上加载预训练模型ResNet, 其实Pytorch的torchvision.models没有参数可以设置不要模型最后的分类头,个人感觉有点不方便, 之前用keras写是有的。
代码
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import models
# 设置超参数
batch_size_train = 64
batch_size_test = 64
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 1
torch.manual_seed(random_seed)
如果发现GPU可用则用GPU加速。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
数据准备
transform = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
print('len(trainset): ', len(trainset))
print('len(testset): ', len(testset))

import pickle
filename = '/content/data/cifar-10-batches-py/batches.meta'
with open(filename,'rb') as f:
info_dict = pickle.load(f, encoding='bytes')
print(info_dict)
获取类别下标对应的类别的字符串。如 0 -> airplane, 1 -> automobile…
labels_str_lt = [str(i, encoding="utf-8") for i in info_dict[b'label_names']]
print(labels_str_lt)
# ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size_train,shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(testset, batch_size=batch_size_test, shuffle=False, num_workers=2)
print('len(train_loader): ', len(train_loader))
print('len(test_loader): ', len(test_loader))

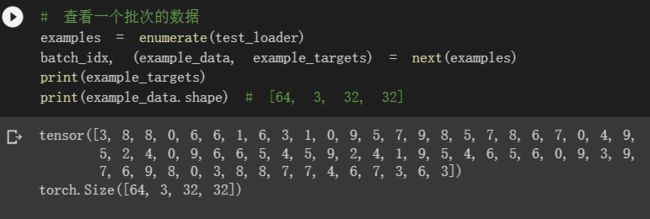
# 查看一个批次的数据
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets)
print(example_data.shape) # [64, 3, 32, 32]
其实不one-hot也没关系,因为nn.crossEntropyLoss有两种用法,详见 torch.nn.CrossEntropyLoss用法
# one hot编码一下
target_onehot = F.one_hot(example_targets)
print(example_targets)
print(target_onehot[:8])
print(target_onehot[:8].argmax(dim=-1))
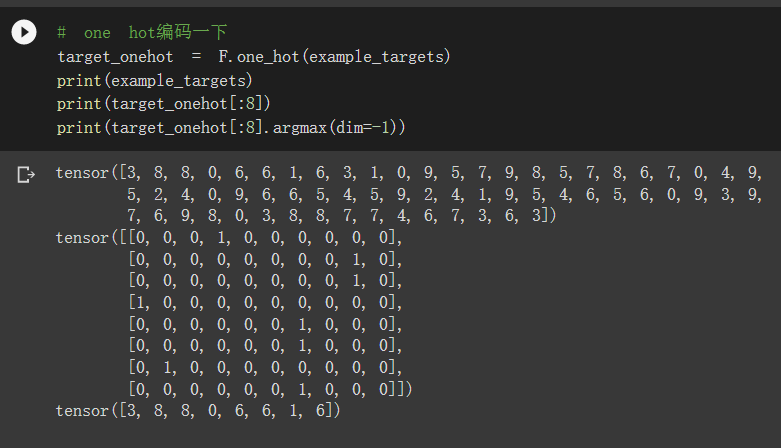
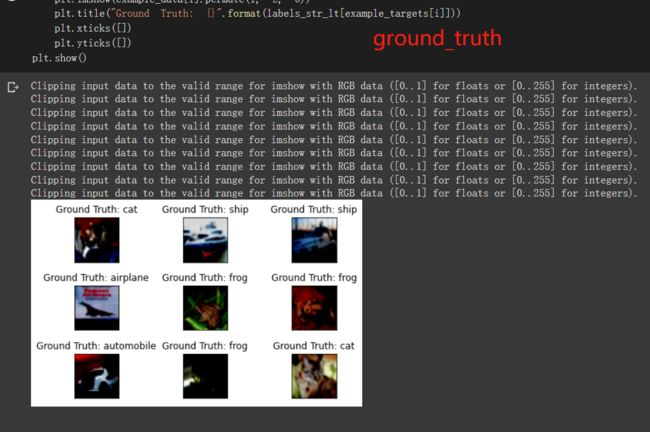
fig = plt.figure()
for i in range(9):
plt.subplot(3, 3,i+1)
plt.tight_layout()
# [3, 32, 32] -> [32, 32, 3]
plt.imshow(example_data[i].permute(1, 2, 0))
plt.title("Ground Truth: {}".format(labels_str_lt[example_targets[i]]))
plt.xticks([])
plt.yticks([])
plt.show()
模型定义
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# resnet18, resnet34, resnet50, resnet101, resnet152
# 更多可查看 https://pytorch.org/vision/stable/models.html
self.backbone = models.resnet50(pretrained=True)
#self.model.load_state_dict(torch.load('./model/resnet50-19c8e357.pth'))
self.fc1 = nn.Linear(2048, 512)
self.fc2 = nn.Linear(512, 10)
self.relu = nn.ReLU()
def forward(self, x):
"""
ResNet50 https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
"""
# x = self.backbone(x) # [batch_size, 1000]因为最后是imagenet 1000个类别
x = self.backbone.conv1(x) # [batch_size, 64, 16, 16]
x = self.backbone.bn1(x) # [batch_size, 64, 16, 16]
x = self.backbone.relu(x) # [batch_size, 64, 16, 16]
x = self.backbone.maxpool(x) # [batch_size, 64, 8, 8]
x = self.backbone.layer1(x) # [batch_size, 256, 8, 8]
x = self.backbone.layer2(x) # [batch_size, 512, 4, 4]
x = self.backbone.layer3(x) # [batch_size, 1024, 2, 2]
x = self.backbone.layer4(x) # [batch_size, 2048, 1, 1]
x = self.backbone.avgpool(x) # [batch_size, 2048, 1, 1]
x = torch.flatten(x, 1) # [batch_size, 2048]
x = self.fc1(x) # [batch_size, 512]
x = self.relu(x) # [batch_size, 512]
x = self.fc2(x) # [batch_size, 10]
return x
model = Net()
# output = model(example_data)
# print(output.shape)

model = model.to(device)
def get_parameter_number(model_analyse):
# 打印模型参数量
total_num = sum(p.numel() for p in model_analyse.parameters())
trainable_num = sum(p.numel() for p in model_analyse.parameters() if p.requires_grad)
return 'Total parameters: {}, Trainable parameters: {}'.format(total_num, trainable_num)
# 查看一下模型总的参数量和可学习参数量
get_parameter_number(model)

训练与预测
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate,
momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
data = data.to(device)
target = target.to(device)
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx * batch_size_train) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(model.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
train(epoch=6)

def test():
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
推测应该是过拟合了,可以多加一下dropout, 或者增加数据增强。
test()
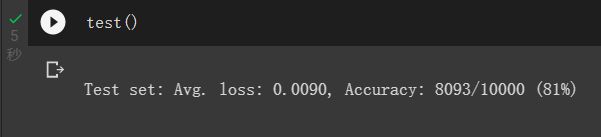
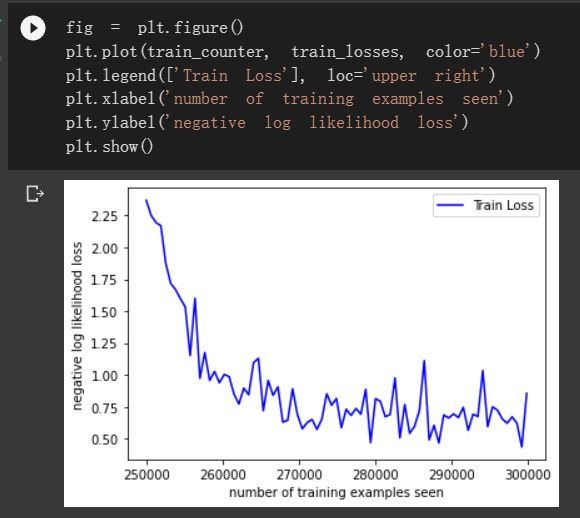
看一下训练过程:
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.legend(['Train Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()
# 看看几个预测输出
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
with torch.no_grad():
example_data = example_data.to(device)
output = model(example_data)
fig = plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i].cpu().permute(1, 2, 0))
plt.title("Prediction: {}".format(
labels_str_lt[output.data.max(1, keepdim=True)[1][i].item()]))
plt.xticks([])
plt.yticks([])
plt.show()
