Scala | SparkSQL | 创建DataSet | 序列化问题 | UDF与UDAF | 开窗函数
文章目录
-
- 一、SparkSQL
-
- 1.SparkSQL介绍
- 2.Dataset 与 DataFrame概念解析
- 3.SparkSQL 的数据源
- 4.SparkSQL 底层架构
- 5.谓词下推(predicate Pushdown)
- 二、创建DataSet的几种方式
-
- 1.读取 json 格式的文件创建 Dataset
- 2.通过 json 格式的 RDD 创建 Dataset
- 3.非 json 格式的 RDD 创建 Dataset
-
- 3.1 反射
- 3.2 动态创建 Schema
- 4.读取 parquet 文件创建 Dataset
- 5.读取 JDBC 中的数据创建 Dataset(MySql 为例)
- 6.读取 Hive 中的数据加载成 Dataset
- 三、序列化问题
- 四、自定义函数 UDF 和 UDAF
-
- 1.自定义函数 UDF
- 2.自定义函数 UDAF
- 5.开窗函数
- 课程地址:spark讲解
- Scala | Spark基础入门 | IDEA配置 | 集群搭建与测试
- Scala | Spark核心编程 | SparkCore | 算子
- Scala | 宽窄依赖 | 资源调度与任务调度 | 共享变量 | SparkShuffle | 内存管理
- Scala | SparkSQL | 创建DataSet | 序列化问题 | UDF与UDAF | 开窗函数
一、SparkSQL
1.SparkSQL介绍
Hive 是 Shark 的前身,Shark 是 SparkSQL 的前身,SparkSQL 产生的根本原因是其完全脱离了 Hive 的限制。
SparkSQL支持查询原生的RDD。RDD是Spark平台的核心概念, 是Spark能够高效的处理大数据的各种场景的基础。- 能够在
scala、Java中写SQL语句。支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
Spark on Hive:Hive只作为储存角色,Spark负责sql解析优化,执行。Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。两者数据源均为
Hive表,底层人物均为Spark人物,关键区别在于一个是Hive去解析,一个是Spark去解析。
| name | 存数据的位置 | 解析引擎 | 执行引擎 |
|---|---|---|---|
| hive on spark | hive表 | hive | spark |
| spark on hive | hive表 | spark | spark |
2.Dataset 与 DataFrame概念解析
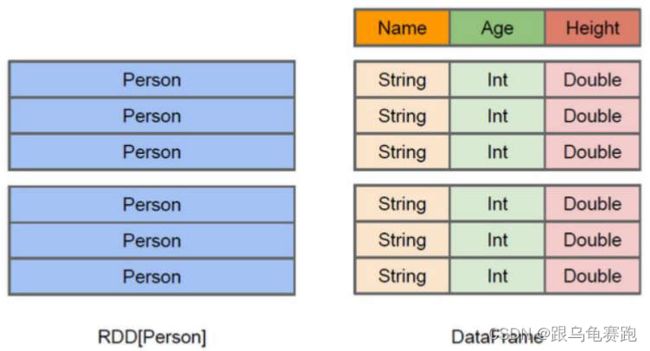
Dataset 也是一个分布式数据容器。与 RDD 类似,然而 Dataset 更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息(元数据),即schema。同时,与 Hive 类似,Dataset 也支持嵌套数据类型(struct、array 和 map)。从 API 易用性的角度上 看, Dataset API 提供的是一套高层的关系操作,比函数式的 RDD API 要更加友好,门槛更低。Dataset 的底层封装的是 RDD,当 RDD 的泛型是 Row 类型的时候,我们也可以称它为 DataFrame。
Dataset<Row> = DataFrame
3.SparkSQL 的数据源
SparkSQL 的数据源可以是 JSON 类型的字符串,JDBC,Parquent,Hive,HDFS 等。

可以将不同源中的数据进行join,这就是SparkSQL中的异构数据源的操作。
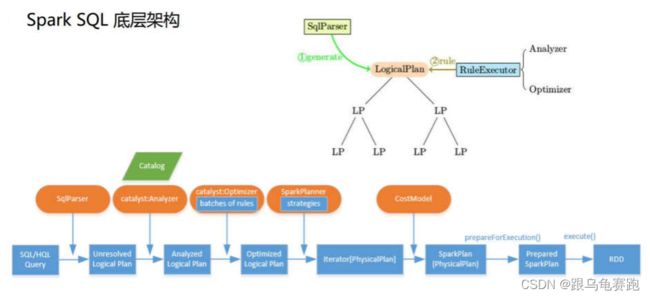
4.SparkSQL 底层架构
首先拿到 sql 后解析一批未被解决的逻辑计划,再经过分析得到分析后的逻辑计划,再经过一批优化规则转换成一批最佳优化的逻辑计划,再经过 SparkPlanner 的策略转化成一批物理计划,随后经过消费模型转换成一个个的 Spark 任务执行。
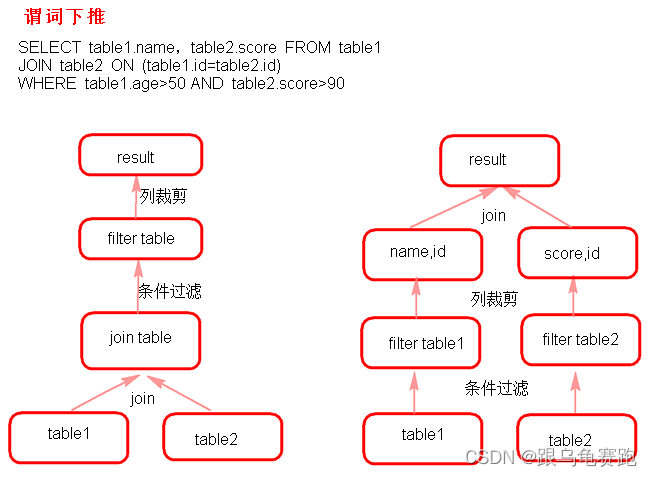
5.谓词下推(predicate Pushdown)
二、创建DataSet的几种方式
1.读取 json 格式的文件创建 Dataset
读取 json 格式的文件有两种方式:
- 一种是
spark.read.json(文件路径) - 另一种是
spark.read.format("json").load(文件路径)
注意:
json文件中的json数据不能嵌套json格式数据。Dataset是一个一个Row类型的RDD,ds.rdd()/ds.javaRdd()。df.show()默认显示前 20 行数据。json文件自带元数据,默认排序时字段名按照字典序排序,然后类型自动推断。- 注册成临时表时,表中的列默认按
ascii顺序显示列。
package com.shsxt.scala_Test.sql.dataset
import org.apache.spark.sql.{DataFrame, SQLContext, SparkSession}
object CreateDFFromJsonFile {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("jsonRDD")
.getOrCreate()
val jsonDS: DataFrame = spark.read.json("./data/json")
jsonDS.show();
jsonDS.createOrReplaceTempView("jsonTable")
val result: DataFrame = spark.sql("select * from jsonTable where age is not NULL")
result.show()
spark.stop()
}
}
+----+--------+
| age| name|
+----+--------+
| 18|zhangsan|
|null| lisi|
| 18| wangwu|
| 28| laoliu|
| 20|zhangsan|
|null| lisi|
| 18| wangwu|
| 28| laoliu|
| 28|zhangsan|
|null| lisi|
| 18| wangwu|
+----+--------+
+---+--------+
|age| name|
+---+--------+
| 18|zhangsan|
| 18| wangwu|
| 28| laoliu|
| 20|zhangsan|
| 18| wangwu|
| 28| laoliu|
| 28|zhangsan|
| 18| wangwu|
+---+--------+
2.通过 json 格式的 RDD 创建 Dataset
package com.shsxt.scala_Test.sql.dataset
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SQLContext, SparkSession}
case class Person(id: String, name: String, age: Integer)
object CreateDFFromRDDWithReflect {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("jsonRDD")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
val nameRDD: RDD[String] = sc.parallelize(Array(
"{'name':'zhangsan','age':\"18\"}",
"{\"name\":\"lisi\",\"age\":\"19\"}",
"{\"name\":\"wangwu\",\"age\":\"20\"}"))
val scoreRDD: RDD[String] = sc.parallelize(Array(
"{\"name\":\"zhangsan\",\"score\":\"100\"}",
"{\"name\":\"lisi\",\"score\":\"200\"}",
"{\"name\":\"wangwu\",\"score\":\"300\"}"
))
val name: DataFrame = spark.read.json(nameRDD)
val score: DataFrame = spark.read.json(scoreRDD)
//注册成临时表使用
name.createOrReplaceTempView("nameTable");
score.createOrReplaceTempView("scoreTable");
val result: DataFrame = spark.sql(
"""
|select nameTable.name,nameTable.age,scoreTable.score
|from nameTable join scoreTable
|on nameTable.name = scoreTable.name
|""".stripMargin)
result.show()
spark.stop()
}
}
+--------+---+-----+
| name|age|score|
+--------+---+-----+
| wangwu| 20| 300|
|zhangsan| 18| 100|
| lisi| 19| 200|
+--------+---+-----+
3.非 json 格式的 RDD 创建 Dataset
3.1 反射
通过反射的方式将非 json 格式的 RDD 转换成 Dataset。实际上就是先将数据转换成自定义类对象,变成RDD,在底层通过反射的方式解析Person.class获得Person的所有schema信息(field),结合RDD本身,就生成了Dataset。
- 自定义类要可序列化
- 自定义类的访问级别是
Public RDD转成Dataset后会根据映射将字段按Assci码排序- 将
Dataset转换成RDD时获取字段两种方式,一种是ds.getInt(0)下标获取(不推荐使用),另一种是ds.getAs(“列名”)获取(推荐使用)
package com.shsxt.scala_Test.sql.dataset
import org.apache.spark.sql.{DataFrame, Dataset, SQLContext, SparkSession}
case class Person(id: String, name: String, age: Integer)
object CreateDFFromRDDWithReflect {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("jsonRDD")
.getOrCreate()
import spark.implicits._
//将非json格式RDD隐式转换成Dataset
val ds: Dataset[Person] = spark.read.textFile("data/person.txt").map { x =>
Person(x.split(",")(0), x.split(",")(1), Integer.valueOf(x.split(",")(2)))
}
ds.createOrReplaceTempView("person")
val result: DataFrame = spark.sql("select name ,id from person ")
result.show()
spark.stop()
}
}
+--------+---+
| name| id|
+--------+---+
|zhangsan| 1|
| lisi| 2|
| wangwu| 3|
+--------+---+
3.2 动态创建 Schema
动态创建 Schema 将非 json 格式的 RDD 转换成 Dataset。
package com.shsxt.scala_Test.sql.dataset
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Row, RowFactory, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object CreateDFFromRDDWithStruct {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("schema")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
val lineRDD: RDD[String] = sc.textFile("data/person.txt")
val rowRDD: RDD[Row] = lineRDD.map { x => {
val split: Array[String] = x.split(",")
RowFactory.create(split(0), split(1), Integer.valueOf(split(2)))
}
}
val schema: StructType = StructType(List(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
val df: DataFrame = spark.createDataFrame(rowRDD, schema)
df.show()
df.printSchema()
sc.stop()
}
}
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 18|
| 2| lisi| 19|
| 3| wangwu| 20|
+---+--------+---+
root
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
4.读取 parquet 文件创建 Dataset
读取与保存二进制格式–parquet 文件。
-
可以将
Dataset存储成parquet文件。保存成parquet文件的方式有两种:df.write().mode(SaveMode.Overwrite).format("parquet").save("./sparksql/parquet") df.write().mode(SaveMode.Overwrite).parquet("./sparksql/parquet") -
读取
parquet文件的方式有两种:spark.read.parquet("./sparksql/parquet") spark.read.format("parquet").load("./sparksql/parquet")
SaveMode 指定文件保存时的模式:
Overwrite:覆盖Append:追加ErrorIfExists:如果存在就报错Ignore:如果存在就忽略
package com.shsxt.scala_Test.sql.dataset
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFFromParquet {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("jsonRDD")
.getOrCreate()
val df: DataFrame = spark.read.json("./data/json")
df.write.mode(saveMode="Overwrite").format("parquet").save("./data/parquet")
// df.write.mode(saveMode="Overwrite").parquet("./data/parquet")
val result: DataFrame = spark.read.parquet("./data/parquet")
result.show()
spark.stop()
}
}
+----+--------+
| age| name|
+----+--------+
| 18|zhangsan|
|null| lisi|
| 18| wangwu|
| 28| laoliu|
| 20|zhangsan|
|null| lisi|
| 18| wangwu|
| 28| laoliu|
| 28|zhangsan|
|null| lisi|
| 18| wangwu|
+----+--------+
5.读取 JDBC 中的数据创建 Dataset(MySql 为例)
从MYSQL中读取创建 Dataset与写入。读取JDBC所需参数及书写案例
- 第一种方式读取
MySql数据库表,加载为DataFrame - 第二种方式读取
MySql数据表加载为Dataset
package com.shsxt.scala_Test.sql.dataset
import java.util.{HashMap, Properties}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, DataFrameReader, SQLContext, SaveMode, SparkSession}
import java.util
object CreateDFFromMysql {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("jsonRDD")
.getOrCreate()
/**
* 第一种方式:读取Mysql数据库表创建DS
*/
val options: util.HashMap[String, String] = new HashMap[String, String]();
options.put("url", "jdbc:mysql://localhost:3306/spark")
options.put("driver", "com.mysql.jdbc.Driver")
options.put("user", "root")
options.put("password", "root")
options.put("dbtable", "person")
val person: DataFrame = spark.read.format("jdbc").options(options).load()
person.show()
person.createOrReplaceTempView("person")
/**
* 第二种方式:读取Mysql数据库表创建DS
*/
val reader: DataFrameReader = spark.read.format("jdbc")
reader.option("url", "jdbc:mysql://localhost:3306/spark")
reader.option("driver", "com.mysql.jdbc.Driver")
reader.option("user", "root")
reader.option("password", "root")
reader.option("dbtable", "score")
val score: DataFrame = reader.load()
score.show()
score.createOrReplaceTempView("score")
val result: DataFrame = spark.sql(
"""
|select person.id,person.name,person.age,score.score
|from person,score
|where person.name = score.name and score.score> 82"
|""".stripMargin);
result.show()
/**
* 将数据写入到Mysql表中
*/
val properties: Properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "root")
result.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/spark", "result", properties)
spark.stop()
}
}
6.读取 Hive 中的数据加载成 Dataset
package com.shsxt.java_Test.sql.dataset;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
public class CreateDSFromHive {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession
.builder()
.appName("hvie")
//开启hive的支持,接下来就可以操作hive表了
// 前提需要是需要开启hive metastore 服务
.enableHiveSupport()
.getOrCreate();
sparkSession.sql("USE spark");
sparkSession.sql("DROP TABLE IF EXISTS student_infos");
//在hive中创建student_infos表
sparkSession.sql("CREATE TABLE IF NOT EXISTS student_infos (name STRING,age INT) row format delimited fields terminated by '\t' ");
sparkSession.sql("load data local inpath '/root/student_infos' into table student_infos");
//注意:此种方式,程序需要能读取到数据(如/root/student_infos),同时也要能读取到 metastore服务的配置信息。
sparkSession.sql("DROP TABLE IF EXISTS student_scores");
sparkSession.sql("CREATE TABLE IF NOT EXISTS student_scores (name STRING, score INT) row format delimited fields terminated by '\t'");
sparkSession.sql("LOAD DATA "
+ "LOCAL INPATH '/root/student_scores'"
+ "INTO TABLE student_scores");
// Dataset df = hiveContext.table("student_infos");//读取Hive表加载Dataset方式
/**
* 查询表生成Dataset
*/
Dataset<Row> goodStudentsDF = sparkSession.sql("SELECT si.name, si.age, ss.score "
+ "FROM student_infos si "
+ "JOIN student_scores ss "
+ "ON si.name=ss.name "
+ "WHERE ss.score>=80");
goodStudentsDF.registerTempTable("goodstudent");
Dataset<Row> result = sparkSession.sql("select * from goodstudent");
result.show();
/**
* 将结果保存到hive表 good_student_infos
*/
sparkSession.sql("DROP TABLE IF EXISTS good_student_infos");
goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos");
sparkSession.stop();
}
}
三、序列化问题
序列化是生成对象的一种方式。
- 反序列化时
serializable版本号不一致时会导致不能反序列化。
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的, 可以进行反序列化,否则就会出现序列化版本不一致的异常。当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID。如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,未作更改的类,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。 - 子类中实现了
serializable接口,父类中没有实现,父类中的变量是不能被序列化,序列化后父类中的变量会得到null。
一个子类实现了Serializable接口,它的父类都没有实现Serializable接口,序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,该变量数值与序列化时的数值不同。(需要在父类中是实现默认的构造方法,否则会报异常:no validconstructor)在父类没有实现Serializable接口时,虚拟机是不会序列化父对象的,而一个Java对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。如果你考虑到这种序列化的情况,在父类无参构造函数中对变量进行初始化,否则的话,父类变量值都是默认声明的值,如 int 型的默认是 0,string 型的默认是 null。- 注意:父类实现
serializable接口,子类没有实现serializable接口时,子类可以正常序列化(应用:将一些不需要序列化的属性值抽取出来放到父类(未实现序列化接口),子类实现序列化接口)
- 注意:父类实现
- 被关键字
transient修饰的变量不能被序列化。 - 静态变量不能被序列化,属于类,不属于方法和对象,所以不能被序列化。
- 静态变量的值是在jvm中,能获取到不是因为反序列化。
四、自定义函数 UDF 和 UDAF
1.自定义函数 UDF
package com.shsxt.scala_Test.sql.udf_udaf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object UDF {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("udaf")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
// 构造模拟数据
val names: Array[String] = Array("Leo", "Marry", "Jack", "Tom")
val namesRDD: RDD[String] = sc.parallelize(names, 5)
val namesRowRDD: RDD[Row] = namesRDD.map { name => Row(name) }
val structType: StructType = StructType(Array(StructField("name", StringType, true)))
val namesDF: DataFrame = spark.createDataFrame(namesRowRDD, structType)
// 注册一张names表
namesDF.createOrReplaceTempView("names")
// 定义和注册自定义函数
// 定义函数:自己写匿名函数
// 注册函数:SQLContext.udf.register()
spark.udf.register("strLen", (str: String) => str.length())
// 使用自定义函数
val result: DataFrame = spark.sql("select name,strLen(name) from names")
result.show()
}
}
+-----+----------------+
| name|UDF:strLen(name)|
+-----+----------------+
| Leo| 3|
|Marry| 5|
| Jack| 4|
| Tom| 3|
+-----+----------------+
2.自定义函数 UDAF
实现 UDAF 函数,如果要自定义类,要实现UserDefinedAggregateFunction 类。
package com.shsxt.scala_Test.sql.udf_udaf
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
class MyAverage extends UserDefinedAggregateFunction {
//指定输入数据的字段名称以及类型
def inputSchema: StructType = StructType(StructField("inputColumn", LongType) :: Nil)
// 指定buffer字段的字段名称以及类型
def bufferSchema: StructType = {
StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
}
// UDAF函数返回值的类型
def dataType: DataType = DoubleType
// 相同的输入是否输出相同的结果
def deterministic: Boolean = true
// 初始化buffer中的元素
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// 每个组,有新的值进来的时候,进行分组对应的聚合值的计算(局部更新)
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// 最后merger的时候,在各个节点上的聚合值,要进行merge,也就是合并(全局更新)
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 最后返回一个最终的聚合值
// 要和dataType的类型一一对应
def evaluate(buffer: Row): Double = {
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}
object UDAF {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("udaf")
.getOrCreate()
//注册聚合函数
spark.udf.register("myAverage", new MyAverage())
val df: DataFrame = spark.read.json("data/json")
df.show()
df.createOrReplaceTempView("person")
val result: DataFrame = spark.sql("SELECT myAverage(age) as average_age FROM person")
result.show()
}
}
+---+--------+
|age| name|
+---+--------+
| 18|zhangsan|
| 18| lisi|
| 18| wangwu|
| 28| laoliu|
| 20|zhangsan|
| 18| lisi|
| 18| wangwu|
| 28| laoliu|
| 28|zhangsan|
| 18| lisi|
| 18| wangwu|
+---+--------+
+-----------------+
| average_age|
+-----------------+
|20.90909090909091|
+-----------------+
5.开窗函数
SQL函数
-
row_number(): 开窗函数是按照某个字段分组,然后取另一字段的前几个的值,相当于分组取topN -
开窗函数格式:相当于增加一列唯一的递增的从一开始的序列。
row_number() over (partitin by XXX order by XXX)
package com.shsxt.scala_Test.sql.windowFun
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
//定义Sales样例类
case class Sales(riqi: String, leibie: String, jine: String)
object RowNumberWindowFun {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("window")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
val ds1: Dataset[String] = spark.read.textFile("./data/sales.txt")
val ds2: Dataset[Sales] = ds1.map(x => {
Sales(x.split("\t")(0), x.split("\t")(1), x.split("\t")(2))
})
ds2.createTempView("sales")
/**
* 开窗函数格式:
* 【 rou_number() over (partitin by XXX order by XXX) 】
*/
val result: DataFrame = spark.sql(
"""
|select riqi,leibie,jine
|from (select riqi,leibie,jine,
| row_number() over (partition by leibie order by jine desc) as rank
| from sales) as t
|where t.rank<=3
|""".stripMargin);
result.show();
spark.stop()
}
}
+----+------+----+
|riqi|leibie|jine|
+----+------+----+
| 6| F| 96|
| 9| F| 87|
| 9| F| 84|
| 7| E| 97|
| 4| E| 94|
| 9| E| 90|
| 8| B| 98|
| 9| B| 82|
| 7| B| 67|
| 3| D| 93|
| 1| D| 9|
| 8| D| 79|
| 5| C| 95|
| 9| C| 86|
| 9| C| 81|
| 9| A| 99|
| 2| A| 92|
| 9| A| 88|
| 1| G| 91|
| 9| G| 89|
| 8| G| 75|
+----+------+----+