Spark SQL
- 一 Spark SQL架构
- 二 运行原理之Catalyst优化器
-
- 1、运行逻辑
- 2、逻辑计划
- 3、优化
- 4、物理计划
- 三 Spark SQL API
-
- 1、SparkSession
- 2、Dataset
- 3、使用Case Class创建Dataset
- 4、RDD->Dataset
- 5、DataFrame
-
- 什么是DataFrame
- DataFrame API常用操作
- RDD -> DataFrame
- Seq/List ->DataFrame
- DataFrame -> RDD
- DataFrame -> DataSet
- 四 Spark SQL操作外部数据源
-
- Spark SQL支持的外部数据源
- Parquet文件
- Spark对Hive表的数据插入和读取
-
- Linux虚拟机spark-shell环境
- IDEA中开发环境
- 操作Mysql中的表
-
- 五 Spark SQL函数
-
- 六 Spark UDF&UDAF&UDTF
-
- 七 Spark SQL CLI
- 八 Spark性能优化
-
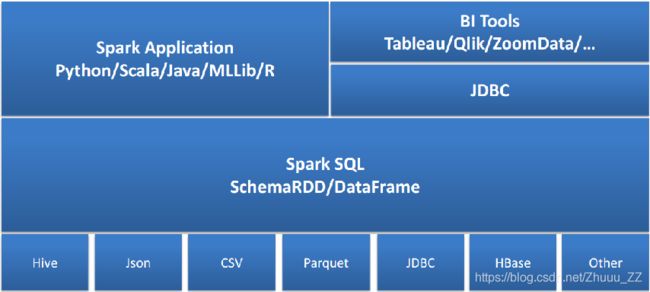
一 Spark SQL架构
- Spark SQL是Spark的核心组件之一(Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX)
- 能够直接访问现存的Hive数据
- 提供JDBC/ODBC接口供第三方工具借助Spark进行数据处理
- 提供了更高层级的接口方便地处理数据
- 支持多种操作方式:SQL、API编程
- 支持多种外部数据源:Parquet、JSON、RDBMS等
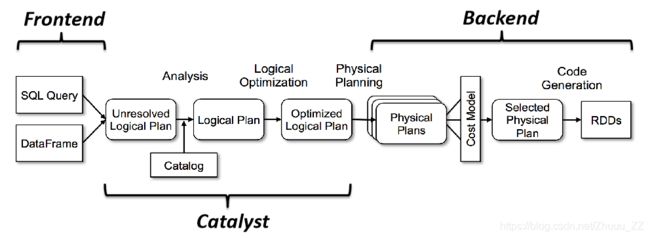
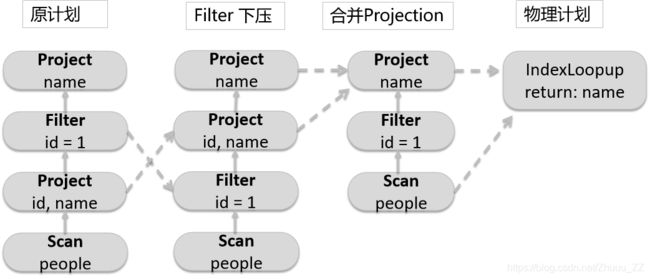
二 运行原理之Catalyst优化器
1、运行逻辑
- Catalyst优化器是Spark SQL的核心
- 将逻辑计划转为物理计划
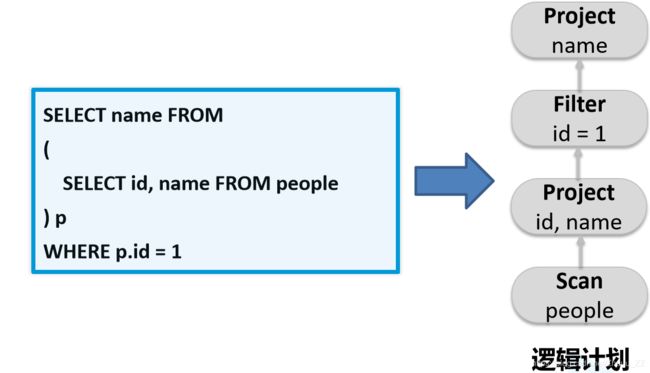
2、逻辑计划
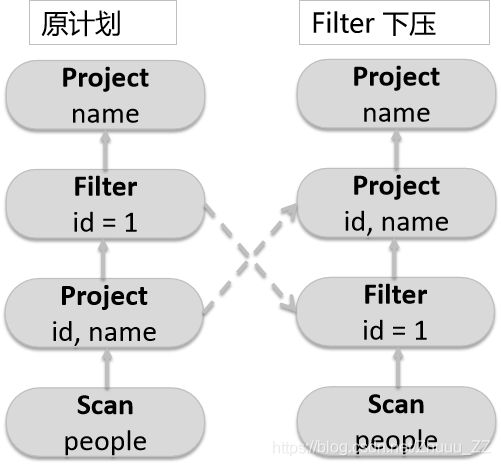
3、优化
- 在投影上面查询过滤器
- 检查过滤器是否可下压
4、物理计划
三 Spark SQL API
1、SparkSession
- SparkContext
- SQLContext
- HiveContext
- SparkSession(Spark 2.x推荐)
- SparkSession:合并了SQLContext与HiveContext
- 提供与Spark功能交互单一入口点,并允许使用DataFrame和Dataset API对Spark进行编程
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val spark = SparkSession.builder
.master("master")
.appName("appName")
.getOrCreate()
val spark=SparkSession.builder.config(conf).getOrCreate()
2、Dataset
scala> spark.createDataset(1 to 3).show
scala> spark.createDataset(List(("a",1),("b",2),("c",3))).show
scala> spark.createDataset(sc.parallelize(List(("a",1,1),("b",2,2)))).show
- createDataset()的参数可以是:Seq、Array、RDD
- 上面三行代码生成的Dataset分别是:Dataset[Int]、Dataset[(String,Int)]、Dataset[(String,Int,Int)]
- Dataset=RDD+Schema,所以Dataset与RDD有大部共同的函数,如map、filter等
3、使用Case Class创建Dataset
- Scala中在class关键字前加上case关键字 这个类就成为了样例类,样例类和普通类区别:
- (1)不需要new可以直接生成对象
- (2)默认实现序列化接口
- (3)默认自动覆盖 toString()、equals()、hashCode()
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
val points=Seq(Point("bar",3.0,5.6),Point("foo",-1.0,3.0)).toDS
val categories=Seq(Category(1,"foo"), Category(2,"bar")).toDS
points.join(categories,points("label")===categories("name")).show
4、RDD->Dataset
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
val pointsRDD=sc.parallelize(List(("bar",3.0,5.6),("foo",-1.0,3.0)))
val categoriesRDD=sc.parallelize(List((1,"foo"),(2,"bar")))
val points=pointsRDD.map(line=>Point(line._1,line._2,line._3)).toDS
val categories=categoriesRDD.map(line=>Category(line._1,line._2)).toDS
points.join(categories,points("label")===categories("name")).show
5、DataFrame
什么是DataFrame
- DataFrame=Dataset[Row],即DataFrame是Dataset的子类型
- 类似传统数据的二维表格
- 在RDD基础上加入了Schema(数据结构信息)
- DataFrame Schema支持嵌套数据类型
- 提供更多类似SQL操作的API
DataFrame API常用操作
val df = spark.read.json("file:///software/wordcount/users.json")
df.show
- 使用printSchema方法输出DataFrame的Schema信息
df.printSchema()
df.select("name").show()
- 使用select方法选择我们所需要的字段,并未age字段加1
df.select(df("name"), df("age") + 1).show()
df.select(df.col("name"), df.col("age") + 1).show()
df.filter(df("age") > 21).show()
df.groupBy("age").count().show()
df.registerTempTable("people")
spark.sql("SELECT * FROM people").show
RDD -> DataFrame
- 通过反射RDD内的Schema
- 凡是涉及到其它类型到DF转换都需要导入隐式包
import spark.implicits._
case class People(name:String,age:Int)
object rddToDF {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
val df: DataFrame = sc.textFile("in/people.txt").map(x=>x.split(",")).map(x=>People(x(0),x(1).toInt)).toDF()
df.printSchema()
df.show()
}
}
case class Person(name String,age Int)
val people: RDD[String] =sc.textFile("file:///home/hadoop/data/people.txt")
val schemaString = "name age"
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
val schema: StructType = StructType(schemaString.split(" ").map(fieldName=>{
if(fieldName.equals("name"))
StructField(fieldName,StringType,true)
else
StructField(fieldName,IntegerType,true)
}))
val rowRDD: RDD[Row]= people.map(_.split(",")).map(p => Row(p(0), p(1).toInt))
val peopleDataFrame: DataFrame = spark.createDataFrame(rowRDD, schema)
peopleDataFrame.registerTempTable("people")
val results = spark.sql("SELECT name FROM people")
results.show
Seq/List ->DataFrame
case class Student(id:Int,name:String,sex:String,age:Int)
val stuDF: DataFrame = Seq(
Student(1001, "zhangsan", "F", 20),
Student(1002, "lisi", "M", 16),
Student(1003, "wangwu", "M", 21),
Student(1004, "zhaoliu", "F", 21),
Student(1005, "zhouqi", "M", 22),
Student(1006, "qianba", "M", 22),
Student(1007, "liuliu", "F", 23)
).toDF()
val df: DataFrame = List((1,20),(3,40)).toDF("id","age")
df.show()
DataFrame -> RDD
val rdd: RDD[Row] = peopleDataFrame.rdd
DataFrame -> DataSet
val frame: DataFrame= sqlContext.sql("select name,count(cn) from tbwordcount group by name")
val DS1: Dataset[(String, Long)] = frame.map(row => {
val name: String = row.getAs[String]("name")
val cn: Long = row.getAs[Long]("cn")
(name, cn)
})
val DS2: Dataset[(String, Long)] = frame.as[(String,Long)]
四 Spark SQL操作外部数据源
Spark SQL支持的外部数据源

Parquet文件
- 是一种流行的列式存储格式,以二进制存储,文件中包含数据与元数据
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.types._
object ParDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("ParquetDemo").getOrCreate()
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val list = List(
("zhangsan", "red", Array(3, 4, 5)),
("lisi", "blue", Array(7, 8, 9)),
("wangwu", "black", Array(12, 15, 19)),
("zhaoliu", "orange", Array(7, 9, 6))
)
val rdd1: RDD[(String, String, Array[Int])] = sc.parallelize(list)
val schema = StructType(
Array(
StructField("name", StringType),
StructField("color", StringType),
StructField("numbers", ArrayType(IntegerType))
)
)
val rowRDD: RDD[Row] = rdd1.map(x=>Row(x._1,x._2,x._3))
val df: DataFrame = spark.createDataFrame(rowRDD,schema)
df.show()
df.write.parquet("out/color")
val frame: DataFrame = spark.read.parquet("out/color")
frame.printSchema()
frame.show()
}
}
Spark对Hive表的数据插入和读取
Linux虚拟机spark-shell环境
- 复制hive中的hive-site.xml至spark安装目录下的conf下(ln -s /opt/hive/conf/hive-site.xml /opt/spark/conf/hive-site.xml)
- 将mysql驱动拷贝至spark的jars目录下(cp /opt/hive/lib/mysql-connector-java-5.1.38.jar /opt/spark/jars/)
- 启动元数据服务:nohup hive --service metastore &
- spark-shell
- 然后直接在spark.sql("....")里面写sql语句就可以了(scala> spark.sql("select * from stu").show())
- 同样,也不能够在spark-shell中创建hive数据库。
IDEA中开发环境
- linux虚拟机输入下述命令会开启jps的RunJar就ok了
nohup hive --service metastore &
- IDEA中创建HIve数据库会产生权限问题:
-chgrp: 'LAPTOP-F4OELHQ8\86187' does not match expected pattern for groupUsage: hadoop fs [generic options] -chgrp [-R] GROUP PATH...。会导致表能够创建成功,但是数据会存到IDEA目录下,不会上传到HDFS上,并且创建的数据库仅仅是个文件夹没有.db后缀。暂时未找到解决方案。建议:数据库提前用虚拟机创建好,然后使用即可。
- IDEA添加依赖
<!-- spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<!-- spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<!-- mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparksqlOnHiveDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("sparkHive")
.master("local[*]")
.config("hive.metastore.uris","thrift://192.168.198.201:9083")
.enableHiveSupport().getOrCreate()
spark.sql("show databases").collect().foreach(println)
val df: DataFrame = spark.sql("select * from toronto")
df.printSchema()
df.show()
val df2: Dataset[Row] = df.where(df("ssn").startsWith("158"))
val df3: Dataset[Row] = df.filter(df("ssn").startsWith("158"))
}
}
操作Mysql中的表
- 虚拟机中请将
mysql-connector-java-5.1.38.jar复制到spark安装目录的jars下
- IDEA中请添加以下依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
从mysql读数据
spark.read.format("jdbc")
.option("url", "jdbc:mysql://192.168.198.201:3306/hive")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "ok")
.option("dbtable", "TBLS")
.load().show
spark.read.format("jdbc")
.options(Map("url"->"jdbc:mysql://192.168.198.201:3306/hive?user=root&password=ok",
"dbtable"->"TBLS","driver"->"com.mysql.jdbc.Driver")).load().show
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparksqlOnMysqlDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]")
.appName("sparksqlOnmysql")
.getOrCreate()
val url="jdbc:mysql://192.168.198.201:3306/hive"
val user="root"
val pwd="ok"
val driver="com.mysql.jdbc.Driver"
val prop=new java.util.Properties()
prop.setProperty("user",user)
prop.setProperty("password",pwd)
prop.setProperty("driver",driver)
val df: DataFrame = spark.read.jdbc(url,"TBLS",prop)
df.show()
df.where(df("CREATE_TIME").startsWith("159")).show()
val frame: DataFrame = df.groupBy(df("DB_ID")).count()
frame.printSchema()
frame.orderBy(frame("count").desc).show()
}
}
向Mysql写数据
object SparkSQL03_Datasource {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val rdd: RDD[(String, Int)] = spark.sparkContext.parallelize(List(("zs",21),("ls",23),("ww",26)))
val df: DataFrame = rdd.toDF("name","age")
df.write
.format("jdbc")
.option("url", "jdbc:mysql://192.168.198.201:3306/test")
.option("user", "root")
.option("password", "ok")
.option("dbtable", "users")
.mode(SaveMode.Append)
.save()
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "ok")
df.write.mode(SaveMode.Append).jdbc("jdbc:mysql://192.168.198.201:3306/test", "users", props)
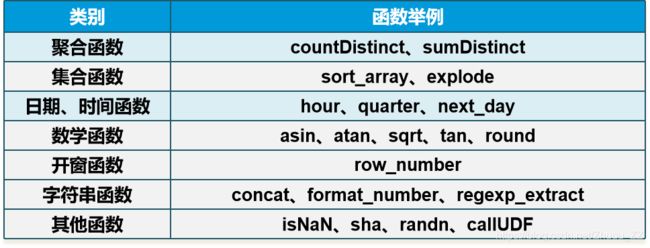
五 Spark SQL函数
内置函数
package sparkSQL
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession, types}
object InnerFunctionDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("innerfunction").master("local[*]").getOrCreate()
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val accessLog = Array(
"2016-12-27,001",
"2016-12-27,001",
"2016-12-27,002",
"2016-12-28,003",
"2016-12-28,004",
"2016-12-28,002",
"2016-12-28,002",
"2016-12-28,001"
)
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
val rdd1: RDD[Row] = sc.parallelize(accessLog).map(x=>x.split(",")).map(x=>Row(x(0),x(1).toInt))
val structType= StructType(Array(
StructField("day", StringType, true),
StructField("user_id", IntegerType, true)
))
val frame: DataFrame = spark.createDataFrame(rdd1,structType)
frame.groupBy("day").agg(countDistinct("user_id").as("pv")).select("day","pv")
.collect().foreach(println)
}
}
case class
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, SparkSession}
object caseClass {
case class Student(id:Int,name:String,sex:String,age:Int)
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("case").getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
val stuDF: DataFrame = Seq(
Student(1001, "zhangsan", "F", 20),
Student(1002, "lisi", "M", 16),
Student(1003, "wangwu", "M", 21),
Student(1004, "zhaoliu", "F", 21),
Student(1005, "zhouqi", "M", 22),
Student(1006, "qianba", "M", 22),
Student(1007, "liuliu", "F", 23)
).toDF()
import org.apache.spark.sql.functions._
stuDF.groupBy(stuDF("sex")).agg(count(stuDF("age")).as("num")).show()
stuDF.groupBy(stuDF("sex")).agg(max(stuDF("age")).as("max")).show()
stuDF.groupBy(stuDF("sex")).agg(min(stuDF("age")).as("min")).show()
stuDF.groupBy(stuDF("sex")).agg("age"->"max","age"->"min","age"->"avg","id"->"count").show()
stuDF.groupBy("sex","age").count().show()
}
}
六 Spark UDF&UDAF&UDTF
UDF
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkUDFDemo {
case class Hobbies(name:String,hobbies:String)
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("innerfunction").master("local[*]").getOrCreate()
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val rdd: RDD[String] = sc.textFile("in/hobbies.txt")
val df: DataFrame = rdd.map(x=>x.split(" ")).map(x=>Hobbies(x(0),x(1))).toDF()
df.registerTempTable("hobbies")
spark.udf.register("hobby_num",
(v:String)=>v.split(",").size
)
val frame: DataFrame = spark.sql("select name,hobbies,hobby_num(hobbies) as hobnum from hobbies")
frame.show()
}
}
UDAF
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
object SparkUDAFDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("udaf").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
val df: DataFrame = spark.read.json("in/user.json")
println("读取的文件详情")
df.show()
val myUdaf = new MyAgeAvgFunction
spark.udf.register("myAvgAge", myUdaf)
df.createTempView("userinfo")
val resultDF: DataFrame = spark.sql("select sex, myAvgAge(age) from userinfo group by sex")
println("使用udaf后的效果")
resultDF.show()
}
}
class MyAgeAvgFunction extends UserDefinedAggregateFunction{
override def inputSchema: StructType = {
new StructType().add("age",LongType)
}
override def bufferSchema: StructType = {
new StructType().add("sum",LongType).add("count",LongType)
}
override def dataType: DataType = DoubleType
override def deterministic: Boolean =true
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0)=0L
buffer(1)=0L
}
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getLong(0)+input.getLong(0)
buffer(1) = buffer.getLong(1)+1
}
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
override def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble/buffer.getLong(1)
}
}
UDTF
import java.util
import org.apache.hadoop.hive.ql.exec.UDFArgumentException
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory
import org.apache.hadoop.hive.serde2.objectinspector.{ObjectInspector, ObjectInspectorFactory, PrimitiveObjectInspector, StructObjectInspector}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkUDTFDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().appName("udtf").master("local[*]")
.enableHiveSupport()
.getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
val lines: RDD[String] = sc.textFile("in/udtf.txt")
val stuDF: DataFrame = lines.map(_.split("//")).filter(x => x(1).equals("ls"))
.map(x => (x(0), x(1), x(2))).toDF("id", "name", "class")
stuDF.createOrReplaceTempView("student")
spark.sql("CREATE TEMPORARY FUNCTION MyUDTF AS 'sparkSQL.myUDTF' ")
spark.sql("select MyUDTF(class) from student").show()
}
}
class myUDTF extends GenericUDTF{
override def initialize(argOIs: Array[ObjectInspector]): StructObjectInspector = {
if(argOIs.length != 1){
throw new UDFArgumentException("有且只能有一个参数")
}
if(argOIs(0).getCategory!=ObjectInspector.Category.PRIMITIVE){
throw new UDFArgumentException("参数类型不匹配")
}
val fieldNames=new util.ArrayList[String]
val fieldOIs=new util.ArrayList[ObjectInspector]()
fieldNames.add("type")
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector)
ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs)
}
override def process(objects: Array[AnyRef]): Unit ={
val strings: Array[String] = objects(0).toString.split(" ")
println(strings.mkString(","))
for (elem <- strings) {
val tmp = new Array[String](1)
tmp(0)=elem
forward(tmp)
}
}
override def close(): Unit = {}
}
七 Spark SQL CLI
- Spark SQL CLI是在本地模式下使用
Hive元存储服务和执行从命令行所输入查询语句的简便工具
- 注意,Spark SQL CLI无法与thrift JDBC服务器通信
- Spark SQL CLI等同于Hive CLI(old CLI)、Beeline CLI(new CLI)
- 将hive-site.xml、hdfs-site.xml、core-site.xml复制到$SPARK_HOME/conf目录下
- 启动Spark SQL CLI,请在Spark目录中运行以下内容
./bin/spark-sql
$spark-sql
spark-sql> show databases;
default
spark-sql> show tables;
default toronto false
spark-sql> select * from toronto where ssn like '111%';
John S. 111-222-333 123 Yonge Street
spark-sql> create table montreal(full_name string, ssn string, office_address string);
spark-sql> insert into montreal values('Winnie K. ', '111-222-333 ', '62 John Street');
spark-sql> select t.full_name, m.ssn, t.office_address, m.office_address from toronto t inner join montreal m on t.ssn = m.ssn;
John S. 111-222-333 123 Yonge Street 62 John Street
八 Spark性能优化
序列化
- Java序列化,Spark默认方式
- Kryo序列化,比Java序列化快约10倍,但不支持所有可序列化类型
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]));
- 如果没有注册需要序列化的class,Kyro依然可以照常工作,但会存储每个对象的全类名(full class name),这样往往比默认的 Java serialization 更浪费空间
优化点
- 使用对象数组(array数组)、原始类型(基本数据类型)代替Java、Scala集合类(如HashMap)
- 避免嵌套结构
- 尽量使用数字作为Key,而非字符串
- 以较大的RDD使用MEMORY_ONLY_SER
- 加载CSV、JSON时,仅加载所需字段
- 仅在需要时持久化中间结果(RDD/DS/DF)
- 避免不必要的中间结果(RDD/DS/DF)的生成
- DF的执行速度比DS快约3倍(结构简单,只有Row对象)
分区优化
- 自定义RDD分区与spark.default.parallelism
- 将大变量广播出去,而不是直接使用
- 尝试处理本地数据并最小化跨工作节点的数据传输
join操作
- 小表放在join左边,会缓存进内存,右边的大表一一与内存中表关联,效率更快
- 还有一个说法是表中重复键较少的表放在join左边,因为写在关联左侧的表每有1条重复的关联键时底层就会多1次运算处理。两表关联时,即使匹配到一条数据,它还是会继续运行下去,也就是说当一个表关联条件所在字段的某一个值有重复时,会打印多条重复的值