PySpark | RDD持久化 | 共享变量 | Spark内核调度
文章目录
-
- 一、RDD持久化
-
- 1.RDD的数据是过程数据
- 2.RDD缓存
-
- 2.1 RDD缓存的特点
- 2.2 cache()与unpersist()实战
- 3.RDD CheckPoint
-
- 3.1 CheckPoint和缓存的对比
- 3.2 CheckPoint算子实战
- 4.总结
- 二、Spark案例练习
-
- 1.搜索引擎日志分析
- 2.提交到集群运行
- 三、共享变量
-
- 1. 广播变量
-
- 1.1 使用方式
- 1.2 广播变量实战
- 2. 累加器
-
- 2.1 使用方式
- 2.2 累加器实战
- 2.3 累加器的注意事项
- 3. 综合案例
- 4. 总结
- 四、Spark内核调度(重点理解)
-
- 1. DAG
-
- 1.1 Job和DAG的关系
- 1.2 DAG和分区的关系
- 2. DAG的宽窄依赖和阶段划分
- 3. 内存迭代计算
- 4. Spark并行度
-
- 4.1 如何设置全局并行度
- 4.2 针对RDD的并行度设置
- 4.3 集群中如何规划并行度?
- 5. Spark任务调度
-
- 5.1 DAG的两个组件
- 6. 拓展 - Spark概念名词大全
-
- 6.1 Spark运行层级关系梳理
- 7. 总结
传送门:
- 视频地址:黑马程序员Spark全套视频教程
- 1.PySpark基础入门(一)
- 2.PySpark基础入门(二)
- 3.PySpark核心编程(一)
- 4.PySpark核心编程(二)
- 5.PySaprk——SparkSQL学习(一)
- 6.PySaprk——SparkSQL学习(二)
- 7.Spark综合案例——零售业务统计分析
- 8. Spark3新特性及核心概念(背)
一、RDD持久化
1.RDD的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失。RDD的数据是过程数据,只在处理的过程中存在。一旦处理完成,就不见了。
这个特性可以最大化的利用资源,老旧RDD没用了就从内存中清理,给后续的计算腾出内存空间。

如上图,rdd3被2次使用,第一次使用之后,其实RDD3就不存在了
第2次用的时候,只能基于RDD的血缘关系,从RDD1重新执行,构建出RDD3,供RDD5使用
2.RDD缓存
上述的场景肯定要执行优化,优化就是:RDD3如果不消失,那么RDD1→RDD2→RDD3,这个链条就不会执行2次,或者更多次。此时,用到了RDD的缓存技术。RDD的缓存技术: Spark提供了缓存API,可以让我们通过调用API,将指定的RDD数据保留在内存或者硬盘上。
缓存API:

2.1 RDD缓存的特点
-
缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上(分散存储——保存在多个服务器的内存空间与硬盘空间中)


-
但是,这个保存在设定上是认为不安全的。
缓存的数据在设计上是认为有丢失风险的。所以,一旦缓存丢失,可以基于RDD的血缘关系记录,重新计算这个RDD数据。缓存必须保留被缓存RDD的前置"血缘关系"。
缓存如何丢失:
➊在内存中的缓存是不安全的, 比如断电\计算任务内存不足,把缓存清理给计算让路
➊硬盘中因为硬盘损坏也是可能丢失的.
2.2 cache()与unpersist()实战
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
import time
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
rdd1 = sc.textFile('../data/input/words.txt')
rdd2 = rdd1.flatMap(lambda x: x.split(' '))
rdd3 = rdd2.map(lambda x: (x, 1))
# 缓存到内存中
rdd3.cache()
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
# 主动清理缓存
rdd3.unpersist()
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]

3.RDD CheckPoint
CheckPoint技术,也是将RDD的数据保存起来。但是,它仅支持硬盘存储。并且:
- 被设计认为是安全的
- 不保留血缘关系
这个RDD数据将被CheckPoint到HDFS中

对比缓存,CheckPoint的RDD数据保存是集中收集存储。如图,CheckPoint存储RDD数据,是集中收集各个分区数据进行存储,而缓存是分散存储。
注意:
- CheckPoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,我们采用CheckPoint比较合适。或者数据量很大,用CheckPoint比较合适。如果数据量小,或者RDD重新计算是非常快,用CheckPoint没啥必要,直接缓存即可。
- Cache和CheckPoint两个API都不是Action类型。所以,想要它俩工作,必须在后面接上Action。接上Action的目的,是让RDD有数据,而不是为了让checkPoint和cache工作。
3.1 CheckPoint和缓存的对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行, HDFS是高可靠存储,CheckPoint被认为是安全的。
- CheckPoint不支持内存,缓存可以,缓存如果写内存性能比CheckPoint要好一些
- CheckPoint因为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留血缘关系
3.2 CheckPoint算子实战

#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2.告知Spark,开启Checkpoint功能
sc.setCheckpointDir('hdfs://node1:8020/test/output/ckp')
rdd1 = sc.textFile('../data/input/words.txt')
rdd2 = rdd1.flatMap(lambda x: x.split(' '))
rdd3 = rdd2.map(lambda x: (x, 1))
# 调用Checkpoint API;保存数据即可
rdd3.checkpoint()
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print(rdd4.collect())
rdd5 = rdd3.groupByKey()
rdd6 = rdd5.mapValues(lambda x : sum(x))
print(rdd6.collect())
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]
[('hadoop', 1), ('hello', 3), ('spark', 1), ('flink', 1)]

4.总结
-
Cache和Checkpoint区别
- Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)
- CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)
-
Cache和CheckPoint的性能对比?
Cache性能更好,因为是分散存储,各个Executor并行执行,效率高,可以保存到内存中(占内存),更快。
- CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储到HDFS上更加安全(多副本)
二、Spark案例练习
1.搜索引擎日志分析
使用搜狗实验室提供【用户查询日志(SogouQ)】数据,使用Spark框架,将数据封装到RDD中进行业务数据处理分析。
数据格式:下载地址

每一列分别为访问时间、用户ID、查询词、该URL在返回结果中的排名、用户点击的顺序号、用户点击的URL
案例需求:三个需求。
- 用户搜索的关键词分析
- 用户和关键词组合分析
- 热门搜索时间段分析

需求一:用户搜索的关键词分析,代码解析:
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
搜索引擎日志分析
- 用户搜索的关键词分析
- 用户和关键词的组合分析
- 热门搜索时间段分析
"""
import jieba
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
from utils import context_jieba, filter_words, transfer_words
if __name__ == '__main__':
# 0.构建SparkContext对象
conf = SparkConf().setAppName(' ').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 1.读取数据文件
file_rdd = sc.textFile('../../data/input/SogouQ.txt')
# 2.对数据按照“\t”进行切分
split_rdd = file_rdd.map(lambda x: x.split('\t'))
# 3.split_rdd作为基础rdd,要多次使用,因此保存在硬盘中
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求1:用户搜索的关键词分析——主要分析热点词
# 将搜索内容取出来
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索内容进行分词,得到分词后的结果
words_rdd = context_rdd.flatMap(content_jieba)
# 对分词后的异常内容进行处理——先将不要的过滤掉,再将剩余内容替换成完成的内容
# 将关键词中的谷、帮、客进行过滤掉
filter_rdd = words_rdd.filter(filter_words)
# 将关键词进行替换
final_word_rdd = filter_rdd.map(transfer_words)
# 对单词进行分组、聚合、降序排序,找出前五个热点词
result1 = final_word_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(5)
print("需求1的结果:", result1)
需求1的结果: [('scala', 2310), ('hadoop', 2268), ('博学谷', 2002), ('传智汇', 1918), ('itheima', 1680)]
需求二:用户和关键词组合分析,代码解析:
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
搜索引擎日志分析
- 用户搜索的关键词分析
- 用户和关键词的组合分析
- 热门搜索时间段分析
"""
import jieba
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
from utils import content_jieba, filter_words, transfer_words, extract_userid_and_word
if __name__ == '__main__':
# 0.构建SparkContext对象
conf = SparkConf().setAppName(' ').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 1.读取数据文件
file_rdd = sc.textFile('../../data/input/SogouQ.txt')
# 2.对数据按照“\t”进行切分
split_rdd = file_rdd.map(lambda x: x.split('\t'))
# 3.split_rdd作为基础rdd,要多次使用,因此保存在硬盘中
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求2:用户和关键词组合分析——每个用户的搜索热点词
# 抽取用户和关键词
user_content_rdd = split_rdd.map(lambda x: (x[1], x[2]))
# 对用户的搜索内容进行分词,分词后与用户ID再次组合
user_word_rdd = user_content_rdd.flatMap(extract_userid_and_word)
# 对内容进行分组、聚合、排序,求前5
result2 = user_word_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(5)
print("需求2的结果:", result2)
需求2的结果: [('6185822016522959_scala', 2016), ('41641664258866384_博学谷', 1372), ('44801909258572364_hadoop', 1260), ('7044693659960919_数据', 1120), ('7044693659960919_仓库', 1120)]
需求三:热门搜索时间段分析,代码解析:
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
搜索引擎日志分析
- 用户搜索的关键词分析
- 用户和关键词的组合分析
- 热门搜索时间段分析
"""
import jieba
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
from utils import content_jieba, filter_words, transfer_words, extract_userid_and_word
if __name__ == '__main__':
# 0.构建SparkContext对象
conf = SparkConf().setAppName(' ').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 1.读取数据文件
file_rdd = sc.textFile('../../data/input/SogouQ.txt')
# 2.对数据按照“\t”进行切分
split_rdd = file_rdd.map(lambda x: x.split('\t'))
# 3.split_rdd作为基础rdd,要多次使用,因此保存在硬盘中
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求3:热门搜索时间段分析
# 取出所有的时间
time_rdd = split_rdd.map(lambda x: x[0])
# 对时间进行处理,只保留小时精度即可
hour_with_one_rdd = time_rdd.map(lambda x: (x.split(':')[0], 1))
# 分组、聚合、排序、求前5
# lambda a, b: a + b ==> from operator import add
result3 = hour_with_one_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(5)
print("需求3的结果:", result3)
需求3的结果: [('20', 3479), ('23', 3087), ('21', 2989), ('22', 2499), ('01', 1365)]
2.提交到集群运行
本地模式与集群模式相比,需要修改如下部分:
- master部分删除
- 读取的文件路径改为hdfs才可以
main.py:
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
搜索引擎日志分析
- 用户搜索的关键词分析
- 用户和关键词的组合分析
- 热门搜索时间段分析
"""
import jieba
from pyspark import SparkContext, SparkConf
from pyspark.storagelevel import StorageLevel
from utils import content_jieba, filter_words, transfer_words, extract_userid_and_word
if __name__ == '__main__':
# 0.构建SparkContext对象
conf = SparkConf().setAppName('test')
sc = SparkContext(conf=conf)
# 1.读取hdfs文件
file_rdd = sc.textFile('hdfs://node1:8020/test/input/SogouQ.txt')
# 2.对数据按照“\t”进行切分
split_rdd = file_rdd.map(lambda x: x.split('\t'))
# 3.split_rdd作为基础rdd,要多次使用,因此保存在硬盘中
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求1:用户搜索的关键词分析——主要分析热点词
# 将搜索内容取出来
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索内容进行分词,得到分词后的结果
words_rdd = context_rdd.flatMap(content_jieba)
# 对分词后的异常内容进行处理——先将不要的过滤掉,再将剩余内容替换成完成的内容
# 将关键词中的谷、帮、客进行过滤掉
filter_rdd = words_rdd.filter(filter_words)
# 将关键词进行替换
final_word_rdd = filter_rdd.map(transfer_words)
# 对单词进行分组、聚合、降序排序,找出前五个热点词
result1 = final_word_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(5)
print("需求1的结果:", result1)
# TODO:需求2:用户和关键词组合分析——每个用户的搜索热点词
# 抽取用户和关键词
user_content_rdd = split_rdd.map(lambda x: (x[1], x[2]))
# 对用户的搜索内容进行分词,分词后与用户ID再次组合
user_word_rdd = user_content_rdd.flatMap(extract_userid_and_word)
# 对内容进行分组、聚合、排序,求前5
result2 = user_word_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(5)
print("需求2的结果:", result2)
# TODO:需求3:热门搜索时间段分析
# 取出所有的时间
time_rdd = split_rdd.map(lambda x: x[0])
# 对时间进行处理,只保留小时精度即可
hour_with_one_rdd = time_rdd.map(lambda x: (x.split(':')[0], 1))
# 分组、聚合、排序、求前5
# lambda a, b: a + b ==> from operator import add
result3 = hour_with_one_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1).take(5)
print("需求3的结果:", result3)
utils.py:
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
工具函数
"""
import jieba
def content_jieba(data):
"""通过jieba分词工具进行分词操作"""
seg = jieba.cut_for_search(data)
l = list()
for word in seg:
l.append(word)
return l
def filter_words(data):
"""过滤不要的内容,比如:谷、帮、客等"""
return data not in ['谷', '帮', '客']
def transfer_words(data):
"""修订某些关键词内容"""
if data == "传智播": data = "传智播客"
if data == "院校": data = "院校帮"
if data == "博学": data = "博学谷"
return (data, 1)
def extract_userid_and_word(data):
"""
将搜索内容进行分词,分词后与用户ID进行组合
:param data: 传入内容是(用户ID,搜索内容)
:return:
"""
user_id = data[0]
user_content = data[1]
# 对搜索内容进行分词
words = content_jieba(user_content)
# 对单词进行过滤与替换,并拼接
result_list = list()
for word in words:
if filter_words(word):
result_list.append((user_id + '_' + transfer_words(word)[0], 1))
return result_list
默认参数的集群提交:
[root@node1 example]# cd /tmp/pycharm_project_189/01_RDD/example/
[root@node1 example]# /export/server/spark/bin/spark-submit --master yarn --py-files utils.py main.py
22/06/24 16:33:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
需求1的结果: [('scala', 2310), ('hadoop', 2268), ('博学谷', 2002), ('传智汇', 1918), ('itheima', 1680)]
需求2的结果: [('6185822016522959_scala', 2016), ('41641664258866384_博学谷', 1372), ('44801909258572364_hadoop', 1260), ('7044693659960919_数据', 1120), ('7044693659960919_仓库', 1120)]
需求3的结果: [('20', 3479), ('23', 3087), ('21', 2989), ('22', 2499), ('01', 1365)]
榨干集群性能提交:
先查看集群资源有多少:
-
查看CPU有几核
(pyspark_env) [root@node1 example]# cat /proc/cpuinfo | grep processor | wc -l -
查看内存有多大
(pyspark_env) [root@node1 example]# free -g
通过命令,计算得知,当前我集群3台服务器总共提供: 16G物理内存+6核心CPU的计算资源。
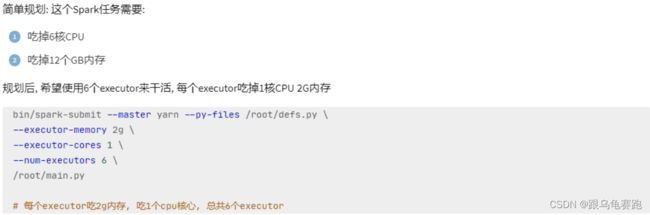
- 如何尽量提高任务计算的资源?
计算CPU核心和内存量,通过–executor-memory 指定executor内存,通过–executor-cores 指定executor的核心数,通过–num-executors 指定总executor数量
基于自身虚拟机所做的操作:
(pyspark_env) [root@node1 example]# /export/server/spark/bin/spark-submit --master yarn --py-files utils.py --executor-memory 1g --executor-cores 1 --num-executors 3 main.py
22/06/24 17:02:03 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
需求1的结果: [('scala', 2310), ('hadoop', 2268), ('博学谷', 2002), ('传智汇', 1918), ('itheima', 1680)]
需求2的结果: [('6185822016522959_scala', 2016), ('41641664258866384_博学谷', 1372), ('44801909258572364_hadoop', 1260), ('7044693659960919_数据', 1120), ('7044693659960919_仓库', 1120)]
需求3的结果: [('20', 3479), ('23', 3087), ('21', 2989), ('22', 2499), ('01', 1365)]
三、共享变量
1. 广播变量
问题引出:有如下代码
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 本地list对象
stu_info_list = [(1, '张大仙', 11),
(2, '王晓晓', 13),
(3, '张甜甜', 11),
(4, '王大力', 11)]
score_info_rdd = sc.parallelize([
(1, '语文', 99),
(2, '数学', 99),
(3, '英语', 99),
(4, '编程', 99),
(1, '语文', 99),
(2, '编程', 99),
(3, '语文', 99),
(4, '英语', 99),
(1, '语文', 99),
(3, '英语', 99),
(2, '编程', 99)
])
def map_func(data):
id = data[0]
name = ''
# 匹配list对象与分布式rdd中的ID,来获得当前学生的姓名
for i in stu_info_list:
if id == i[0]:
name = i[1]
return (name, data[1], data[2])
# 4.完成用户id到用户名的映射
print(score_info_rdd.map(map_func).collect())
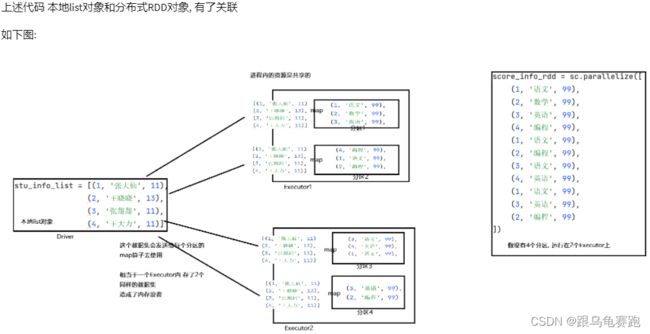
本地list对象(在Driver进程中),被发送到每个分区的处理线程上使用,也就是一个executor内,其实存放了2份一样的数据。executor是进程,进程内资源共享,这2份数据没有必要,造成了内存与网络IO的浪费。
解决方案:广播变量。如果将本地list对象标记为广播变量对象,那么当上述场景出现的时候,Spark只会给每个Executor来一份数据,而不是像原本那样,每一个分区的处理线程都来一份,节省内存。

如图,使用广播变量后,每个Executor只会收到一份数据集,内部的各个线程(分区)共享这一份数据集。
使用场景:本地集合对象和分布式集合对象rdd进行关联的时候,需要将本地集合对象封装为广播变量。这个通常用在本地集合对象占用内存不大的情况下。如果占用内存过大,需要分布式rdd与分布式rdd进行JOIN算子的关联。
可以节省:
- 网络IO的次数
- Executor的内存占用
1.1 使用方式

1.2 广播变量实战
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2.将本地list对象标记为广播变量
# 本地list对象
stu_info_list = [(1, '张大仙', 11),
(2, '王晓晓', 13),
(3, '张甜甜', 11),
(4, '王大力', 11)]
broadcast = sc.broadcast(stu_info_list)
score_info_rdd = sc.parallelize([
(1, '语文', 99),
(2, '数学', 99),
(3, '英语', 99),
(4, '编程', 99),
(1, '语文', 99),
(2, '编程', 99),
(3, '语文', 99),
(4, '英语', 99),
(1, '语文', 99),
(3, '英语', 99),
(2, '编程', 99)
])
def map_func(data):
id = data[0]
name = ''
# 3. 使用广播变量,从broadcast对象中取出本地list对象即可
value = broadcast.value
# 匹配广播变量与分布式rdd中的ID,来获得当前学生的姓名
for i in value:
if id == i[0]:
name = i[1]
return (name, data[1], data[2])
# 4.完成用户id到用户名的映射
print(score_info_rdd.map(map_func).collect())
[('张大仙', '语文', 99), ('王晓晓', '数学', 99), ('张甜甜', '英语', 99), ('王大力', '编程', 99), ('张大仙', '语文', 99), ('王晓晓', '编程', 99), ('张甜甜', '语文', 99), ('王大力', '英语', 99), ('张大仙', '语文', 99), ('张甜甜', '英语', 99), ('王晓晓', '编程', 99)]
2. 累加器
想要对map算子计算中的数据,进行计数累加。得到全部数据计算完后的累加结果。问题引出:代码如下
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2)
count = 0
def map_func(data):
global count
count += 1
print(count)
rdd.map(map_func).collect()
print(count)
1
2
3
4
5
1
2
3
4
5
0
两个分区,分别打印1到5。代码最后结果打印为0(由Driver进程打印)。

代码的问题在于:count来自driver对象,当在分布式的map算子中需要count对象的时候,driver会将count对象发送给每一个executor一份(复制发送),每个executor各自收到一个,在最后执行print(count)的时候,这个被打印的count依旧是driver中的那个,所以不管executor中累加到多少,都和driver这个count无关。
2.1 使用方式
sc.accumulator(初始值)
累加器对象唯一和前面提到的count不同的是,这个对象可以从各个Executor中收集它们的执行结果,作用回自己身上。
2.2 累加器实战
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2)
# TODO:accumulator算子,构建累加器对象,这个对象可以从各个Executor中收集它们的执行结果
acmlt = sc.accumulator(0)
def map_func(data):
global acmlt
acmlt += 1
print(acmlt)
rdd.map(map_func).collect()
print(acmlt)
1
2
3
4
5
1
2
3
4
5
10
2.3 累加器的注意事项
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2)
# TODO:accumulator算子,构建累加器对象,这个对象可以从各个Executor中收集它们的执行结果
acmlt = sc.accumulator(0)
def map_func(data):
global acmlt
acmlt += 1
# print(acmlt)
rdd2 = rdd.map(map_func)
rdd2.collect()
rdd3 = rdd2.map(lambda x: x)
rdd3.collect()
print(acmlt)
20
如上代码,第一次rdd2被action后,累加器值是10,然后rdd2就没有了。当rdd3构建出来的时候,是依赖rdd2的,rdd2没数据,那么rdd2就要重新生成。重新生成就导致累加器累加数据的代码再次被执行。所以代码的结果是20。
如何解决:加缓存或者checkPoint即可。
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 1.构建SparkContext对象
conf = SparkConf().setAppName('creat rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 2)
# TODO:accumulator算子,构建累加器对象,这个对象可以从各个Executor中收集它们的执行结果
acmlt = sc.accumulator(0)
def map_func(data):
global acmlt
acmlt += 1
# print(acmlt)
rdd2 = rdd.map(map_func)
# 添加缓存
rdd2.cache()
rdd2.collect()
rdd3 = rdd2.map(lambda x: x)
rdd3.collect()
print(acmlt)
10
3. 综合案例
-
数据

-
需求:
- 正常的单词进行单词计数
- 特殊字符统计出现有多少个
-
代码
#!usr/bin/env python # -*- coding:utf-8 -*- """ 统计: - 正常单词进行单词计数 - 特殊字符统计出现有多少个 """ from pyspark import SparkConf, SparkContext import re if __name__ == '__main__': # 0.构建SparkContext对象 conf = SparkConf().setAppName('creat rdd').setMaster('local[*]') sc = SparkContext(conf=conf) # 1.读取数据文件 file_rdd = sc.textFile('../data/input/accumulator_broadcast_data.txt') # 特殊字符的list定义 abnormal_char = [',', '.', '!', '#', '$', '%'] # 2.特殊字符list,包装成广播变量 broadcast = sc.broadcast(abnormal_char) # 3.对特殊字符出现次数做累加,使用累加器 acmlt = sc.accumulator(0) # 4.数据处理,先处理数据的空行 # 有内容返回True,None返回False lines_rdd = file_rdd.filter(lambda line: line.strip()) # 5.去除前后空格 data_rdd = lines_rdd.map(lambda line: line.strip()) # 6.对数据进行切分,按照正则表达式切分,因为空格分隔符某些单词之间是两个或者多个空格 words_rdd = data_rdd.flatMap(lambda line: re.split('\s+', line)) # 7.当前words_rdd中有正常单词,也有特殊符号 # 过滤数据,保留正常单词用于做单词计数;在过滤的过程中对特殊符号做计数 def filter_func(data): """过滤数据,保留正常单词用于做单词计数;在过滤的过程中对特殊符号做计数""" global acmlt # 取出广播变量 abnormal_chars = broadcast.value if data in abnormal_chars: acmlt += 1 return False else: return True normal_words_rdd = words_rdd.filter(filter_func) # 8.单词计数 result_rdd = normal_words_rdd.map(lambda x: (x, 1)). \ reduceByKey(lambda a, b: a + b) print('正常单词计数结果:', result_rdd.collect()) print('特殊字符计数结果:', acmlt)正常单词计数结果: [('hadoop', 3), ('hive', 6), ('hdfs', 2), ('spark', 11), ('mapreduce', 4), ('sql', 2)] 特殊字符计数结果: 8
4. 总结
- 广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO传输,提高性能。 - 累加器解决了什么问题?
分布式代码执行中,进行全局累加
四、Spark内核调度(重点理解)
这部分内容在面试中经常被问到。
1. DAG
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
以词频统计WordCount程序为例,DAG图为:

Spark官方在4040界面的DAG图为:

1.1 Job和DAG的关系
Action算子的作用是一个触发开关,会将action算子之前的一串rdd依赖链条执行起来。如图,我们前面写的搜索引擎日志分析案例中,三个Job的DAG为:
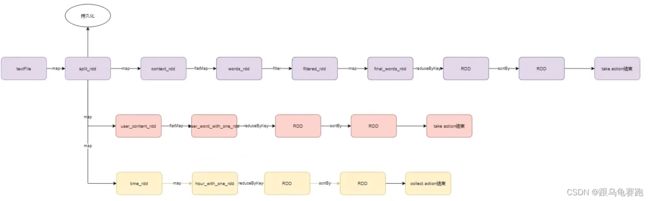
结论:
- 1个Action会产生1个DAG,如果在代码中有3个Action就产生3个DAG。一个Action产生的一个DAG,会在程序运行中产生一个Job。所以: 1个Action = 1个DAG = 1个Job。
- 如果一个代码中,写了3个Action,那么这个代码运行起来产生3个Job,每个Job有自己的DAG。一个代码运行起来,在Spark中称之为: Application。
- 层级关系:1个Application中,可以有多个Job,每一个Job内含一个DAG,同时每一个Job都是由一个Action产生的。
1.2 DAG和分区的关系
DAG是Spark代码的逻辑执行图,这个DAG的最终作用是为了构建物理上的Spark详细执行计划而生。所以,由于Spark是分布式(多分区)的,那么DAG和分区之间也是有关联的。

假设上述代码的全部RDD全部都在三个分区上执行,代码运行时就可以得到带有分区关系的DAG图。
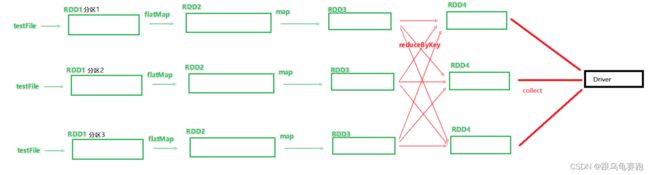
2. DAG的宽窄依赖和阶段划分
Spark RDD前后之间的关系,分为:
- 窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区。

- 宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区。宽依赖还有一个别名:shuffle。

简单的从图中来看:出现分叉就是宽依赖,否则,就是窄依赖。
宽窄依赖涉及到阶段的划分。对于Spark来说,会根据DAG按照宽依赖划分不同的DAG阶段。划分依据:从后向前,遇到宽依赖就划分出一个阶段,称之为stage。

如图,可以看到:在DAG中,基于宽依赖将DAG划分成了2个stage,在stage的内部一定都是:窄依赖。
3. 内存迭代计算
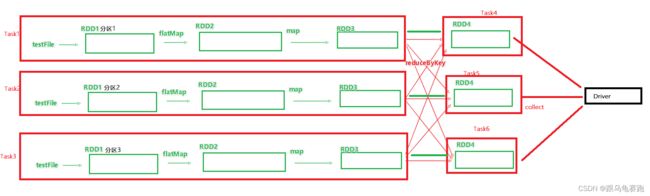
如图,基于带有分区的DAG以及阶段划分,可以从图中得到逻辑上最优的task分配。一个task是由一个线程来具体执行。那么如上图,task1中rdd1、rdd2、rdd3的迭代计算,都是由一个task(线程完成)。如上图,task1、task2、task3,就形成了三个并行的内存计算管道,由三个线程并行工作。
注意:
- Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子都会遵循全局并行度的要求,来规划自己的分区数。
- Spark我们一般推荐只设置全局并行度,除了一些排序算子外,计算算子就让他默认开分区就可以了。如果中途修改分区,必然产生分叉,导致内存迭代管道变短,性能下降。
4. Spark并行度
Spark的并行:在同一时间内,有多少个task在同时运行。比如设置并行度6,其实就是要6个task并行在跑。在有了6个task并行的前提下, rdd的分区就被规划成6个分区了。
4.1 如何设置全局并行度
可以在代码中和配置文件中以及提交程序的客户端参数中设置优先级从高到低:
- 代码中
- 客户端提交参数中
- 配置文件中
- 默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
全局并行度配置的参数:spark.default.parallelism

全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建,或者会产生额外的Shuffle
4.2 针对RDD的并行度设置
- repartition算子
- coalesce算子
- partitionBy算子
4.3 集群中如何规划并行度?
结论:设置为CPU总核心的2~10倍。
比如集群可用CPU核心是100个,我们建议并行度是200~1000。
确保是CPU核心的整数倍即可,最小是2倍,最大一般10倍或更高(适量)均可
- 为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情。所以,在100个核心的情况下,设置100个并行,就能让CPU100%出力。这种设置下,如果task的压力不均衡,某个task先执行完了就导致某个CPU核心空闲。所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待。但是可以确保,某个task运行完了,后续有task补上,不让cpu闲下来,最大程度利用集群的资源。规划并行度,只看集群总CPU核数
5. Spark任务调度
Spark的任务,由Driver进行调度,这个工作包含:
- 逻辑DAG产生
- 分区DAG产生
- Task划分
- 将Task分配给Executor并监控其工作
如图,Spark程序的调度流程如图:
- Driver被构建出来
- 构建SparkContext(执行环境入口对象)
- 基于DAG Scheduler(DAG调度器)构建逻辑Task分配
- 基于TaskScheduler(Task调度器)将逻辑Task分配到各个Executor上干活,并监控它们
- Worker(Executor),被TaskScheduler管理监控,听从它们的指令干活,并定期汇报进度。
1,2,3,4是Driver的工作;5是Worker的工作

5.1 DAG的两个组件
- DAG调度器——DAG Scheduler
工作内容:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分一般,将–num-executor 设置为服务器的数量
因为,一个服务器内的多个executor之间的任务交互,需要走本地回环网络IO。因此,一般一个机器开启一个executor就可以了,从而可以增加内存迭代计算的占比,缩减网络IO。应当关注的是Task任务数量与服务器的CPU数量一样 - Task调度器——Task Scheduler
工作内容:基于DAG Scheduler的产出,来规划这些逻辑的task,应该在哪些物理的executor运行,以及监控管理它们的运行
6. 拓展 - Spark概念名词大全

6.1 Spark运行层级关系梳理

7. 总结
- DAG是什么?有什么用?
DAG有向无环图,用以描述任务执行流程,主要作用是协助DAG调度器构建Task分配用以做任务管理 - 内存迭代\阶段划分?
基于DAG的宽窄依赖划分阶段,阶段内部都是窄依赖可以构建内存迭代的管道 - DAG调度器是什么?
构建Task分配用以做任务管理