python3之Requests模块
requests模块
- requests介绍
-
- 一:requests模块入门
-
- 1.url参数问题
- 2.响应内容
-
- 响应状态码
- 响应头
- 3.cookie问题
-
- 概念:
- 基本原理:
- cookie在request模块中的应用:
- 4.解码编码问题
requests介绍
request模块用于构造模拟http消息的交互,自动化构造模拟http报文交互
笔者建议阅读python中文手册中的request模块,可以对这一模块有更为清晰的认知
request中文手册
一:requests模块入门
模拟发送不同形式的HTTP请求:
requests.get(‘https://github.com/timeline.json’) #GET请求
requests.post(“http://httpbin.org/post”) #POST请求
requests.put(“http://httpbin.org/put”) #PUT请求
requests.delete(“http://httpbin.org/delete”) #DELETE请求
requests.head(“http://httpbin.org/get”) #HEAD请求
requests.options(“http://httpbin.org/get”) #OPTIONS请求
常用方法:
r.status_code #响应状态码
r.raw #返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read() 读取
r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
r.text #字符串方式的响应体,会自动根据响应头部的字符编码进行解码
r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
#特殊方法#
r.json() #Requests中内置的JSON解码器
r.raise_for_status() #失败请求(非200响应)抛出异常
1.url参数问题
当所构造的url要进行传参时,若为手工构建 URL,那么数据会以键/值对的形式置于 URL 中,跟在一个问号的后面例如:https://www.baidu.com/s?wd=value1&pn=value2
requests模块允许使用params进行传参,
import requests
keyword={'wd':'kali','pn':'10'}
r=requests.get('https://www.baidu.com/s',params=keyword)
print(r.url)
>>>>https://www.baidu.com/s?wd=kali&pn=10
2.响应内容
Requests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。
请求发出后,Requests会根据http头部对响应的编码进行判断,r.text会根据所判断的编码方式对响应体进行解码
r.encoding会显示request模块所使用的编码方式,并且可以用此方法更改响应体的解码方式
import requests
r = requests.get('https://api.github.com/events')
print(r.text)
print(r.encoding)
print(r.content)
r.content 为字节流编码显示响应体
r.encoding返回requests模块所用的编码方式
响应状态码
r.status_code 返回响应体的状态码
import requests
r = requests.get('https://api.github.com/events')
print(r.status_code)
>>>200
当发送错误请求时,可以使用Response.raise_for_status() 来抛出异常
>>> bad_r = requests.get('http://httpbin.org/status/404')
>>> bad_r.status_code
404
>>> bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
响应头
headers在HTTP消息中为字典型数据结构,可以调用requests.headers.get(‘key’)对响应头进行查询
>>> r.headers['Content-Type']
'application/json'
>>> r.headers.get('content-type')
'application/json'
3.cookie问题
概念:
cookie,一种口令机制,用于维持浏览器访问服务器状态的口令机制
服务器可以利用这种机制识别同一用户,并记录该用户产生窗口的状态
从而可以实现会话跟踪,并记录用户的行为。
基本原理:
1.当一个浏览器访问某web服务器时,web服务器会在响应头中添加一个名叫Set-Cookie的响应字段用于将Cookie返回给浏览器,当浏览器第二次访问该web服务器时会自动的将该cookie回传给服务器,来实现用户状态跟踪。(http协议本身为静态协议,不能实现状态跟踪功能)
2.cookie的domain和path属性定义了cookie的作用范围,即访问哪些网站或url时,会自动的带着该cookie。
domain即域名,默认是当前主机(不包括子域名)
path默认是*(所有路径),即域名后面的的路径。大部分情况下我们都是使用默认的设置即可。
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
print(r.text)
print(r.url)
此处的domain为httpbin.org域名(此域名为GitHub上一开源项目,用于测试HTTP实验)path设为/cookies(/elsewhere)
cookie在request模块中的应用:
1.当请求响应中存在有cookie时,可以调用
url = 'http://www.baidu.com'
r = requests.get(url)
print(r.cookies)
》》》<RequestsCookieJar[<Cookie ###### for .baidu.com/>]>
来查看响应中的cookie值
2.若要发送cookie至目标服务器,则可以使用r.requests.get(url=url,cookie=cookie)参数来进行发送
url = 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url, cookies=cookies)
r.text
'{"cookies": {"cookies_are": "working"}}'
cookie返回的对象为RequestCookiejar
使用RequestCookiejar可以利用更多的接口,适合跨域名跨路径使用
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
print(r.text)
print(r.url)
》》》{
"cookies": {
"tasty_cookie": "yum"
}
}
http://httpbin.org/cookies
若想对cookie进行详细了解,请移步笔者另一博文
cookie,session,token三剑客
4.解码编码问题
r.text:返回字符串形式的响应体
r.content:返回字节形式的响应体
import requests
r = requests.get(url='http://www.baidu.com') # 最基本的GET请求
print(r.status_code) # 获取返回状态
r = requests.get(url='http://www.baidu.com/s', params={'wd': 'python'}) # 带参数的GET请求
print(r.url)
print(r.text) # 打印响应体
》》》
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>百度安å
¨éªŒè¯</title> #发现打印出来为乱码
因为网站的网页为gzip压缩过的数据,不可以直接打印,要先进行解压缩
r.content()方法可以对响应体进行gzip/deflate解压操作,
print(r.content)
#打印出未解码的响应体
print(r.content.decode('utf-8'))
#打印解码之后的响应体
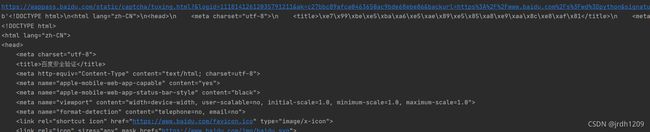
e>\xe7\x99\xbe\xe5\xba\xa6\xe5\xae\x89\xe5\x85\xa8\xe9\xaa\x8c\xe8\xaf\x81</title>\n
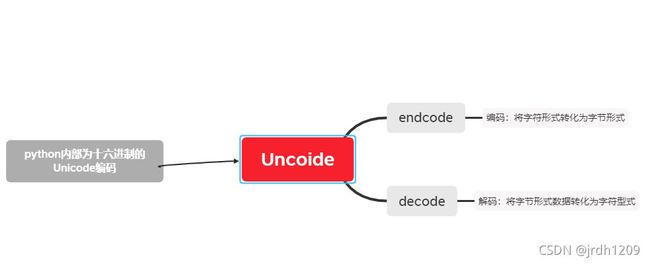
这些都为十六进制文本,是python内部编码uncoide的编码格式。即:响应体通过content()解压缩之后,在python内部为uncoide编码,可以对其进行utf-8解码操作,得到字符响应体
decode(‘utf-8’)的意思就是将当前的unicode编码转换成utf-8编码
编码解码问题: