吴恩达深度学习笔记-布置机器学习项目(第4课)
布置机器学习项目
- 一、训练集/验证集/测试集
- 二、偏差与方差
- 三、机器学习基础
- 四、正则化
- 五、为什么正则化可以减少过拟合?
- 六、Dropout正则化
- 七、理解Dropout
- 八、其他正则化方法
- 九、归一化输入
- 十、梯度消失与梯度爆炸
- 十一、神经网络的权重初始化
- 十二、梯度的数值逼近
- 十三、梯度检验
- 十四、关于梯度检验实现的注意事项
一、训练集/验证集/测试集
-
划分数据为训练集、验证集和测试集可以减少确定超参数的迭代过程。
在有100~10000个数据样本时,可将数据分成7:3=训练集:验证集或60:20:20=训练集:验证集:测试集
但在大数据时代,样本数量可能高达上百万条,那么验证集和测试集占数据总量的比例会趋向于变的更小。【验证集是为了选出最优的模型,测试集是为了评估模型,也许少量的数据样本就足够了】 -
假设正在开发一个识别图片是否包含猫的网站,测试集是从网上下载的小猫图片,测试集和验证集是用户上传的图片。
网上的图片都经过后期加工,十分的精美;而用户上传的图片都是随手拍的。从而训练集和测试集的数据有所不同(不是同一分布)。
针对这种情况,要确保验证集和测试集的数据来自于同一分布,同一分布下机器学习会学的更快。 -
可以不存在测试集,测试集只是对模型的一种无偏估计。可以通过训练集和验证集迭代的选择合适的参数,选出适用的模型。
二、偏差与方差
第一种情况:
使用逻辑回归去划分下图的数据,很明显效果并不是很好;存在欠拟合问题,即高偏差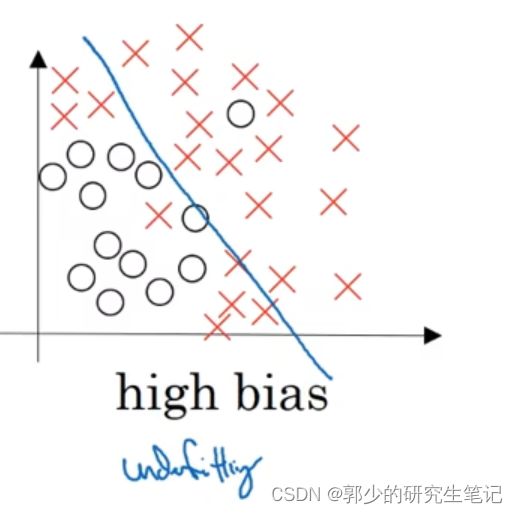
第二种情况:
使用相当复杂的模型去描述这个分类问题,如下图;每个样本都被完美分隔开,寻找过拟合问题,高方差。
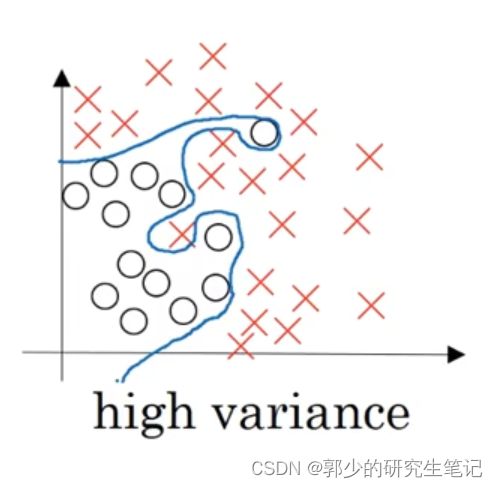
高偏差(high bias):
距离最优模型的距离,越小越好
.
高方差(high variance):
模型泛化能力,越小越好
例如猫的分类问题,当图片中存在猫则输出y=1,否则y=0。

-
当训练集误差为1%,验证集误差为11%;可以看出训练集的效果比较好,而验证集效果较差。问题是我们可能过度的拟合了训练集,称之为高方差(high variance),即泛化能力差。
-
当训练集误差为15%,验证集误差为16%;可以看出训练集和验证集效果较差。可能存在模型欠拟合问题,没有很好的拟合训练集数据,称之为高偏差(high bias)。
-
当训练集误差为15%,验证集误差为30%;验证集比训练集误差要高很多,这种情况会认为是算法偏差高,因为在训练集上不理想,验证集上也不理想。
-
当训练集误差为0.5%,验证集误差为1%;在验证集和测试集上的效果都很好,模型偏差和方差都很低。
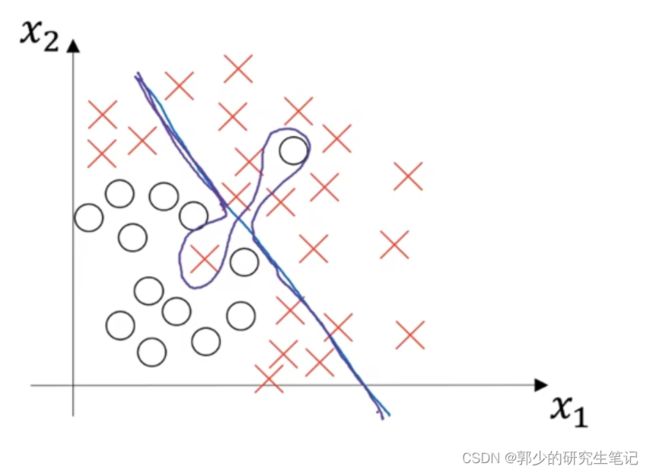
例如下图紫色的分界线,高偏差是因为它几乎是一条线性分类器,并未拟合数据;高方差是因为过度拟合了部分样本。
三、机器学习基础
- 对于高偏差,可以使用一个更大的神经网络,或者花费更多时间训练算法,或者尝试更先进的优化算法,或者尝试找到更合适的神经网络框架。反复尝试,以解决欠拟合的问题。
- 对于高方差,可以获取更多的数据,或者正则化,或者尝试找到更合适的神经网络框架。
- 高偏差和高方差是两种不同的情况,因此应该通过训练验证机来确定情况,从而对症下药。
四、正则化
高方差问题最先想到的方法可能是正则化;另一个解决方法是准备更多数据,这也是一个非常可靠的方法,但可能无法准备足够多的数据或获取更多数据的成本很高,那么正则化是一个很好的选择。
- logistic regression中的正则化:
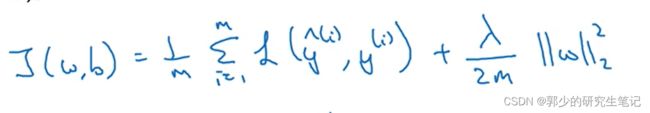
通常不对b进行正则化。上图采用的是L2范式,此外也可以采用其他范式:
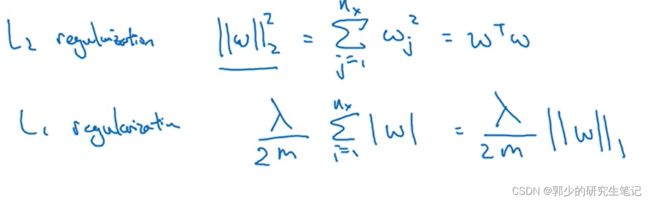
当使用L1范式的时候,w会是稀疏的,即W向量中会有很多0。有人说L1会帮助压缩存储(稀疏矩阵的存储),但正则化的目的并非是压缩存储。在模型正则化中会更倾向于L2正则化。
图中的λ是正则化参数,通常使用验证集或交叉验证来配置这个参数。
python中lambda是关键字,一般使用lambd代替
- 神经网络中的正则化:
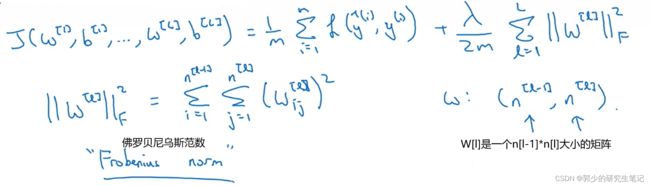 对于反向传播过程的修改:
对于反向传播过程的修改:
dw添加正则项的导数:
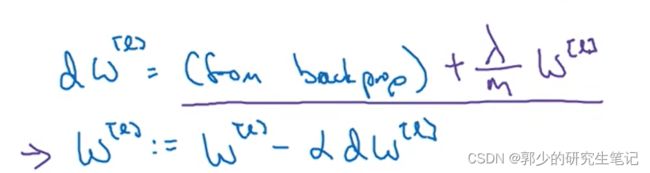
W[l]的更新如下图所示,红框部分会希望W[l]总是小一点,因此L2范数正则化也被称为“权重衰减”。

五、为什么正则化可以减少过拟合?
-
最直观的理解,当神经节点数量过多,神经网络会太过复杂,从而过于拟合训练集样本,导致过拟合。当我们加入正则项后,
当λ设置的足够大,权重矩阵W被设置为接近于0的值,从而使神经网络中的部分节点失效,降低模型复杂度减少过拟合。但当λ过大,可能会将模型变得过于简单,导致高偏差(欠拟合)的状态。
正则化中部分节点失效的不是使其消失,而是通过降低w使其影响变小。 -
若我们使用的激活函数是tanh:
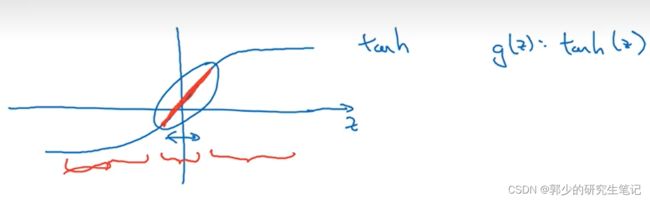 当λ过大,w[l]就变的很小,而z[l] = w[l]a[l-1]+b[l],从而z就会变得很小,那么激活函数使用的范围会压缩到上图红色的部分,这一部分类似一个线性函数;而当我们的神经节点激活函数使用线性函数时,那么整个网络就是一个线性函数,最终我们只能计算线性函数,因此不会发生过拟合的情况。
当λ过大,w[l]就变的很小,而z[l] = w[l]a[l-1]+b[l],从而z就会变得很小,那么激活函数使用的范围会压缩到上图红色的部分,这一部分类似一个线性函数;而当我们的神经节点激活函数使用线性函数时,那么整个网络就是一个线性函数,最终我们只能计算线性函数,因此不会发生过拟合的情况。
六、Dropout正则化
-
假设我们在训练下面的神经网络,且存在过拟合的问题。
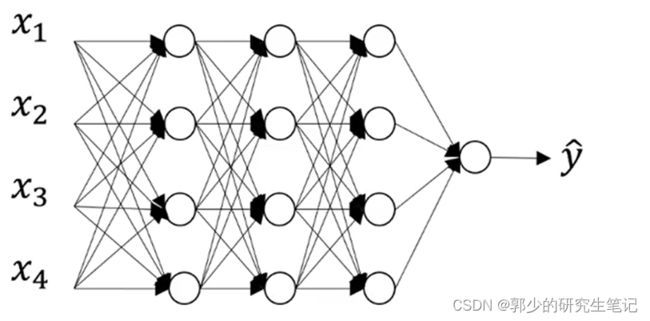
dropout会遍历网络的每一层,并设置消除神经网络中节点的概率。
例如对于网络中的每一层的每个节点都以抛硬币的方式设置概率,每个节点得以保留和消除的概率都是0.5。
最后我们会消除部分节点,然后删掉该节点进出的连线,最后得到一个节点更少,规模更小的网络。
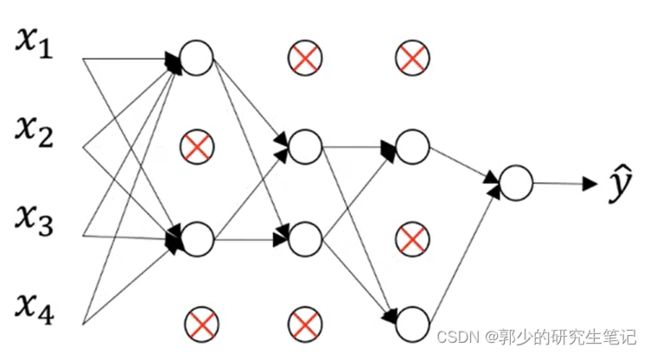
-
实施dropout:
以一个3层神经网络为例,首先先定义d3表示第三层的dropout向量,如下图:
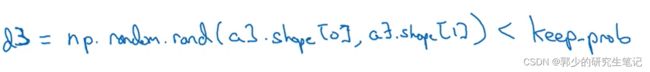 keepprob是一个具体的数字,代表保留某个隐藏单元的概率。上一个例子中它就是0.5,本例子中设置为0.8,上图的d3矩阵赋值为一个逻辑表达式,矩阵中随机数小于0.8为1,否则为0;使d3矩阵中的1的分布为80%。
keepprob是一个具体的数字,代表保留某个隐藏单元的概率。上一个例子中它就是0.5,本例子中设置为0.8,上图的d3矩阵赋值为一个逻辑表达式,矩阵中随机数小于0.8为1,否则为0;使d3矩阵中的1的分布为80%。
最后a3的输出为a3=a3*d3,点乘的作用就是过滤调d3中所有等于0的元素。
接下来可以将a3除于keepdrob,为啥呢?
如下图,我们的期望是a[3]减少20%,也就是说a[3]中有20%的元素被归零;为了不影响z[4]的期望值,我们需要用w[4]a[3]除于0.8,它会修正我们所需的那20%。

理解除于dropout:(弹幕中的原话,感觉不错)
即削弱某些单元的同时又加强其他单元的影响
dropout中的不同训练样本对于不同的dropout矩阵,即不同的训练样本消除的隐藏单元不同。例如,第三层的有50个units,那么d3的大小会是50*m
- 测试阶段:
在测试阶段我们给出了x或是想预测的变量,在测试阶段不使用dropout函数,因为在测试阶段,不希望输出结果是随机的。
如果测试阶段使用dropout函数,预测会受到干扰;理论上只需要多从预测处理过程,每一次不同的隐藏单元会被随机归0,但是预测的效率低且得出的结果也几乎相同。
之前那一步除于keepdrop的操作,目的是确保在测试阶段不执行dropout来调整数值范围,激活函数的预期结果也不会发生改变。
七、理解Dropout
- 对dropout的第一个直观认知:使用dropout函数,每次迭代之后神经网络都会变得比以前更小,因此采用一个较小的神经网络好像和使用正则化的效果是一样的。
- 第二个直观的认知:对于某个神经节点来说,它的输入会随机被清除;因此不愿意把所有赌注都放在一个节点上,
不愿意给任何一个输入加上太多的权重,因为它可能会被随机清除,该节点将通过这种方式传播权重并为输入增加一点权重。并通过传播所有权重,dropout将产生收缩权重的L2范式的效果【dropout的功能类似于L2正则化】
在实施dropout的过程中,每一层的keepprob可以不一样;若担心某一层会较大程度的出现过拟合,可以将keepprob设置的低一些;若不考虑过拟合问题,可以设置keepprob为1。对于输入层,keepprob=1是常用的输入值,或者使用一个较大的值0.9。
八、其他正则化方法
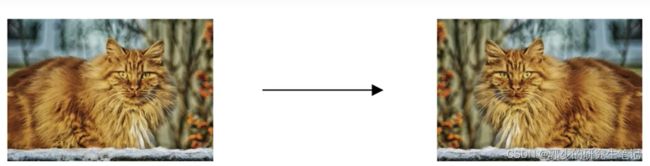
- 假设你正在拟合猫咪图片分类器,想要通过增加训练数据来解决过拟合,但扩增数据代价很大或者无法扩增数据。我们可以翻转图片来扩充训练集,这虽然不如额外收集一组新图片那么好,但这样做节省了获取更多猫咪图片的花费。除了水平翻转外,可以通过裁剪图片、放大、旋转等方式扩增数据。
虽然这些额外的“假”数据无法提供那么多信息,但我们这么做基本没有花费,代价基本为0.
- Early stopping:
在训练迭代过程中,可以绘制验证集和测试集的代价函数图,如下图所示;验证集在一开始的下降之后就开始上升了,我们可以在合适的位置停止训练。
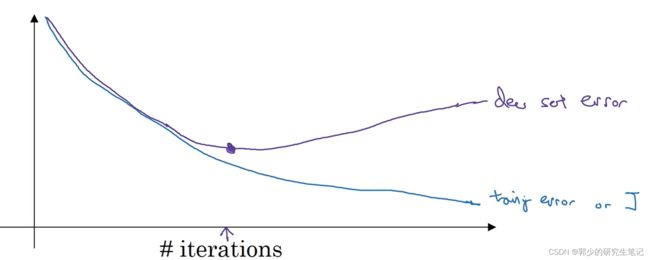
在一开始,w是一个接近于0的较小的随机数,在训练过程中w会逐渐增大,也许在迭代后期参数w就会变得很大了;所有early stopping要做的事在中间点停止迭代过程,得到一个中等范式的佛罗贝尼乌斯范数(w矩阵的平方和,即||w||2F),与L2正则化相似,选择参数w范数比较小的神经网络。
early stopping的缺点:在训练过程中,我们希望代价函数能够尽可能的小,又希望防止过拟合;early stopping为了防止过拟合就停止了代价函数的下降过程,即对代价函数的下降和防止过拟合没有采取不同的策略,而是一棒子解决这两个问题。
与L2正则化相比,early stopping不用尝试寻找λ参数,只需要运行一次坡度下降即可。
九、归一化输入
训练神经网络过程中一个加速训练的方法就是归一化输入。
归一化方式:(输入-均值)/标准差
s:标准差
s2:方差
归一化的目的是让各feature的范围相差不大,以二维的数据为例子,如下图:
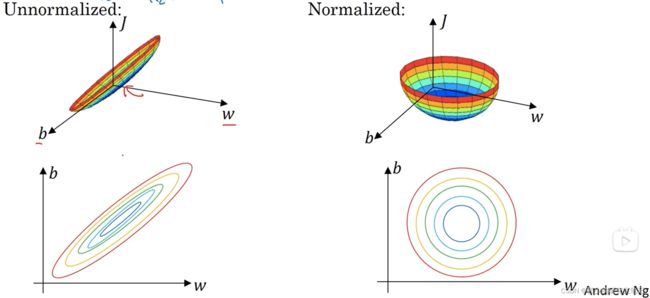
左边是未标准化的,数据分布范围相差很大,把递归下降想象成小球下落,这个狭长的山谷小球是不是的下滑好一段时间。右边是标准化的,数据分布均匀,就像一个半圆,小球无论从哪开始下落都会很快的到达谷底。
十、梯度消失与梯度爆炸
假设我们在训练下图的神经网络,为了简化,将激活函数都设置为线性激活函数,b都设置为0。

最后y=W[l]W[l-1]W[l-2]……W[2]W[1]X
- 假设W[1]~W[l-1] = 1.5*E (1.5倍的单位矩阵)
最后y = W[l](1.5)(l-1)X,y呈数型增长 - 假设W[1]~W[l-1] = 0.5*E (0.5倍的单位矩阵)
最后y = W[l](0.5)(l-1)X,y呈指数型减小
结论:权重W只比1略大一些,深度神经网络的激活函数将爆炸式增长;权重W只比1略小一些,深度神经网络的激活函数将指数级递减。
十一、神经网络的权重初始化
以逻辑回归为例子,为了简化讨论忽略b。
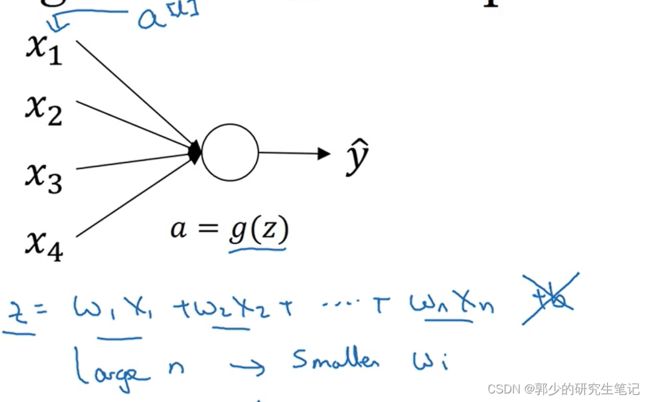
为了避免z过大或者过小,当n特别大的时候希望wi能够小,需要将wi设置的不比1大很多,也不能比1小很多。
Xaviar初始化:将wi的方差设置为1/n(n表示前一层神经节点的个数),神经结点是tanh激活函数可以使用这个方法;大致代码如下:
w[l] = np.random().randn(n[l],n[l-1])*np.sqrt(1/n[l-1])
np.random().randn()随机出来的数服从标准正态分布,即期望等于0,方差等于1。
方差为σ2的数组乘于a,数组方差变为a2*σ2,所以上面代码乘的是开根号的
- 当激活函数为非线性函数relu,将
wi的方差设置为2/n,代码如下
w[l] = np.random().randn(n[l],n[l-1])*np.sqrt(2/n[l-1])
- 对于线性激活函数tanh,也可以将
方差设置为2/(n[l-1]+n[l]),代码如下
w[l] = np.random().randn(n[l],n[l-1])*np.sqrt(2/(n[l-1]+n[l]))
十二、梯度的数值逼近
在神经网络中进行反向传播时,为了确保反向传播的梯度的正确性,会进行梯度检验以确保反向传播细节的正确性。
梯度数值逼近的方式:
- 单边误差的方法:f’(θ) = [f(θ+ε)-f(θ)]/ε

- 双边误差的方法:f’(θ) = [f(θ+ε)-f(θ-ε)]/2ε

双边的精度会比单变的精度高,更接近真实值结果更准确。因此在执行梯度检验时,使用更加准确的双边误差。
十三、梯度检验
梯度检验用于检验backdrop(反向传播)的实施是否正确
-
首先将参数组合成一个大的参数θ和dθ:
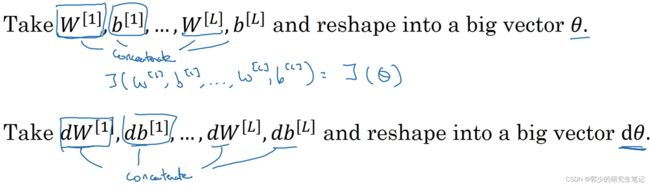
接下来需要讨论的问题就是:dθ和代价函数J的坡度有什么关系 -
梯度检测:
对于每个参数θi进行遍历计算梯度得到dθapprox,看dθapprox是否约等于dθ
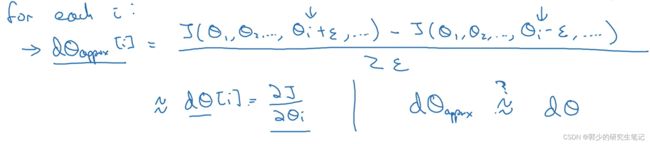
如何定义两个向量是否接近?一般做下列运算:
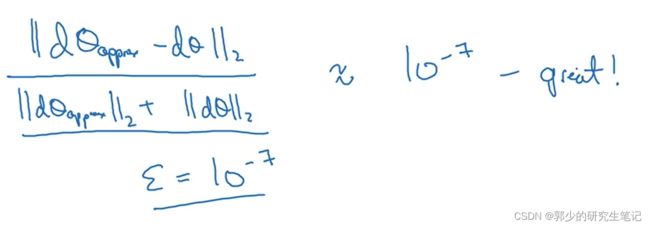
上图的||x||2为欧式距离。ε的值可能为10-7,当执行上图的运算时,运算结果的值为10-7或者更小,这就很好,意味着导数逼近很有可能是正确的。
若它的值在10-5范围内,那就得小心了,也许这个值没有问题,但应该检查这个向量的所有项,确保没有一项误差过大,有一项误差过大的话那么这里可能会有bug。
十四、关于梯度检验实现的注意事项
- 不要使用在训练过程中,仅在调试中使用。因为检验过程计算量很大。
- 如果算法的梯度检验失败,要检查所有项;检查每一项并试着找出bug。即如果dθapprox[i]和dθ[i]的值相差很大,需要做的是查找不同的i值,看是哪个导致了误差。
- 在实施梯度检验时,如果使用正则化,请注意正则项。即代价函数记得是带正则项的那个
- 梯度检验和dropout不能同时使用。
大不随机化dropout或者按一定的模式dropout,就可以检查梯度了,但吴老师不会这么做
- 当w和b接近0时,梯度下降的实施是正确的,但是在运行梯度下降时,w和b变得更大。可能只有在w和b接近0时,backprop的实施才是正确的。但是当w和b变大时,它会变得越来越不准确。我们可以在随机初始化过程中运行梯度检验,然后再训练网络,反复训练网络之后,再重新运行梯度检验。