索引是什么
索引是帮助MySQL高效获取数据的排好序的数据结构
最重要的点是有序的,我们用索引就是为了快速的查找数据,如果一堆数据是无序的,程序只能挨个遍历每个元素,对比值,才能找到某个元素,最坏的情况要比对N次, N 是这一堆数据的长度。如果数据是有序的,我们就可以使用二分查找算法,他的时间复杂度是 O(long N),效率比直接挨个查找快的多。
二分查找算法关键步骤就是找到区间的中间值,然后确定要查找的值落在左区间还是右区间,一直重复这个步骤直到找到该值。于是就可以将这种查询方法映射成一种数据结构——树。我们规定一种树,有左节点,右节点,和当前节点。并且左节点 < 当前节点 < 右节点 .
如下图所示:
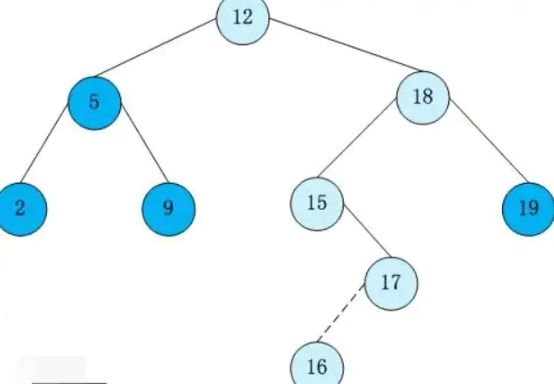
由于树具有方便快速查找的特性,我们一般都会使用树结构去存储索引,并对简单的查找二叉树做了很多优化,比如 红黑树,平衡二叉树, B 树 B+树
树的构建,删除, 查找都有一定的算法,这里不详细描述,只需知道树有一个通用的特性:树的高度越低,查找效率越高
所以索引的构建 , 本质上是控制树的高度
索引数据结构
二叉树:
- 红黑树
- Hash 表
- B Tree
树形索引
表中的数据与索引结构映射关系可以理解如下图:

加入要找到 col2 = 23 的记录,如果不使用索引,我们需要对整张表扫描,从 34 -> 77 -> 5 -> 91 -> 22 -> 89 -> 23, 需要对比7次才能找到
使用索引时, 查找路径时是 34 -> 22 -> 23 只需对比3次就行。在表中数据量极大时,差别更明显
树的动画
推荐一个在线工具,它以动画的形式描述了每种树的构建与查找方法
为什么不是简单的二叉树?
我们知道MySQL索引采用的是 B+树,那么为什么不是其他的树呢?
因为在顺序插入下,树的高度会一直增加,等同于链表。无法控制树的高度,如下图:

如果需要查找6,仍然需要查找6次
为什么不是红黑树?
红黑树(平衡二叉树): 虽然会自动平衡节点位置,但仍然高度不可控。表比较大时会导致树的高度很高。增加查找次数
为什么最终选择B+树 而不是B树
要解决这个疑问,我们需要知道这两种树的构造,如下图:
B Tree:
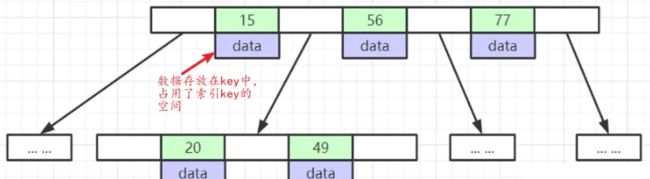
B + Tree:

水平方向可以存放更多的索引key
B+树将数据全部放到叶子节点,留下更多的空间放 key, key 越多,宽度越宽,同样的数据量,宽度越大,高度越小。查找次数就越小。
为什么需要 扩展树的宽度而不是树的深度呢?
如果按照上面的说法,我们拓宽了树的宽度,减少了树的高度,但是比较次数并没有发生改变,只不过是减少了纵向的比较,增加了横向的比较
这个疑问的前提是所有的数据都在内存中,直接在内存中进行比较大小。 但是事实并非如此,不可能把表中的所有数据都加到内存中,必须先从磁盘中加在一部分数据到内存,然后在内存中比较大小,内存中运算的速度远远大于从磁盘加载数据的速度。磁盘加载数据是机械运动,需要电机带动磁针转圈扫描磁道。内存运算则是电子运动,不可同日而语。
数据从磁盘加载到内存中,是有最小单位的,这个单位是 页, 不是 字节或者 位, 页是固定字节数据,由操作系统决定,这样可以减少加载磁盘的次数。
由于B Tree 的每一层都已经是有序的,我们把树中水平方向的数据放在磁盘相邻的地方,每次从磁盘加载一页数据时,便可以得到部分或全部的水平方向的结点,不用再次排序。
在水平方向在内存中使用二分查找的效率远远大于从磁盘中加载一页数据, 所以我们希望树越宽越好,这样一次性加载的数据就越多,而不是越高越好
对于B+ 树,我们假设要查找50这个数据,先从根节点即(15 56 77) 这些数据中找到50所处的范围,因为 (15 56 77) 已经是有序的,可以根据二分查找算法找到 50 处于 15--56之间, 然后加载 15 所指向的下一页数据 (15 20 49),再次根据二分查找算法,找到50处于 49之后,再从磁盘加载49所指向的数据页,找到50
数据量估算
MySQL 自己也有一个逻辑 页,一般是操作系统中 页 的整数倍,这个逻辑页的数据可以通过配置修改,但是不建议,MySQL 是经过大量的测试,为我们定义了一个合理的默认值 16Kb
可以通过下面语句查询:
show global status like 'Innodb_page_size'
假设上图中表示的是主键索引,类型是 bigint, 占 8 个字节。指向下一页的指针占 6 个字节, 那么这一页可以存放 16 * 1024 / (8 + 6) = 1170 个key, 同理第二页即 (15 20 49 ....) 也可以放 1170 个key , 对于第三页,也就是叶子节点,包含了主键和对应整行的数据。就按照一行数据放1KB 吧(已经比较大了) 能放 16 行,那么只有一页根节点的话, 这个索引索引树能放 1170 * 1170 * 16 =21,902,400 行数据。 这棵树的高度只有3,就已经能支持上千万的数据量了。也就是只需加载3次磁盘就可以查找到数据了。并且MySQL 存放根节点的页还有优化,可能会把这个页常驻内存。
叶子节点包含所有的索引字段
如上图所示,在主键索引中,叶子节点包含了表中的所有字段,对于一些全表扫描的查询来说,直接扫描叶子节点便可以得到数据,不用再从索引树上挨个查找
叶子节点直接包含双向指针,范围查找效率高
对于一些范围查询比如 id > 20 and id < 50, 在索引树上定位到 20 之后直接使用右向指针定位到下一个比20大的数据,依次往下,直到 50,便可以检出该区间的数据,如果没有这个指针,(B Tree)则需要再次回到索引树中去查找 , 极大的提高了范围查找的性能
Hash 索引
hash 索引原理如下:
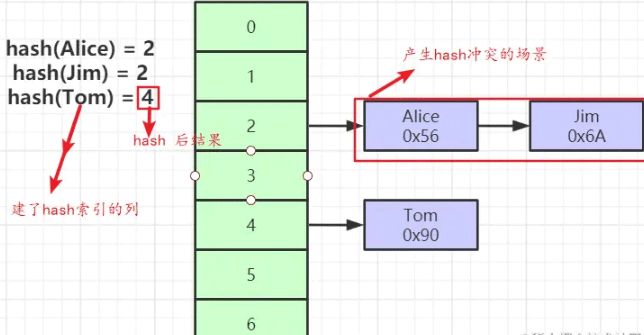
更快
大多情况下 Hash 索引比B+ Tree 索引更快,Hash 计算的效率非常高,且仅需一次查找就可以定位到数据(无hash冲突的情况)
不支持范围查询
图中有些歧义,Hash 后的值是没有顺序的,也不是整数,所以无法进行高效的范围查询查询
hash 冲突问题
如果在某列上有很多相同的行,比如 name 字段,叫 张三的人非常多。会产生很多次hash冲突,只能退化成列表搜索了
表引擎
我们常说的 MyISAM 引擎 或者 InnoDB 引擎是基于表的,是表的一个属性, 可不是基于数据库的, 同一个数据库中可以有不同引擎的表
MyISAM 和 InnoDB 引擎
不同引擎的表在磁盘中产生的文件也不一样,数据库文件位置默认在安装目录/data 下
MyISAM 引擎
- frm: 表结构相关, frame(框架) 缩写`
- MYD: MyISAM Data 表数据
- MYI: MyISAM Index 表索引

索引结构中的叶子节点的 data 存放的是 数据行的位置,及这一行在 MYD 文件的位置, 而不是直接放的真实数据
InnoDB
- frm 表结构信息
- ibd 表数据加索引
表数据组织形式
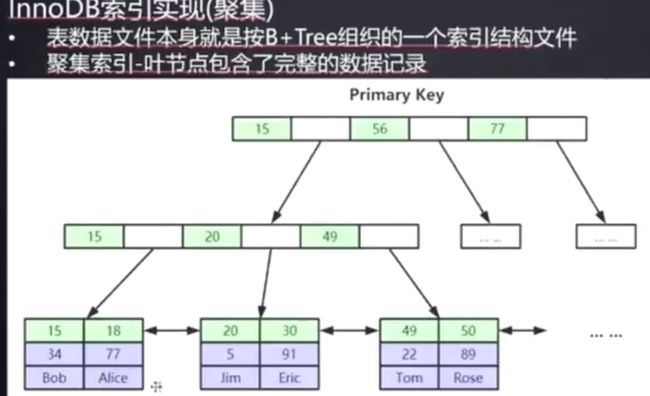
表结构本身就是按照 B+ Tree 结构存储, 叶子节点放的是出索引列其他列的数据
聚集与非聚集索引
聚集索引 (InnoDB 主键索引)
叶子节点直接包含整行数据
非聚集索引 (MyISAM 索引, InnoDB 非主键索引)
叶子节点不包含整行数据,包含的是对应行所在的位置,或者主键Id
单从索引结构的来看,聚集索引的查找速度高于非聚集索引
InnoDB 只有一个聚集索引,默认是主键索引, 非主键索引的叶子节点存放的是主键的值,如下图:
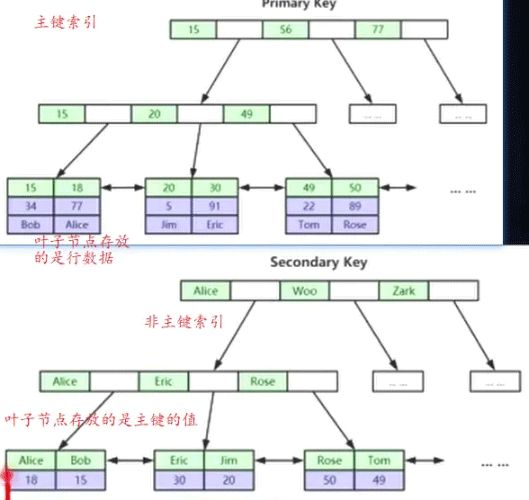
这样做的目的有两个:
- 节约空间,避免将整行的数据存放多份
- 保证数据的一致性,否则每增加一行,对应的每个索引都要维护一份行数据。必须要等到每个索引都更新完,数据才能插入成功
★★★ 为什么建议InnoDB 表必须有主键,并且是整型自增的?
InnoDB 整个表的数据就是用B+ 树组织的,如果存在主键,就用主键为索引,叶子节点存储行数据
如果没有主键,InnoDB 就会找到一个每行数据都不相同的列作为索引来组织整个表的数据
如果没有找到这种列,就会建一个隐藏的列,自动维护值,用这个隐藏的列来组织数据,所以我们要主动做这种工作减少数据库的负担
为什么是整型
因为在查找数据的过程中,需要多次比较大小,整型的比较运算速度大于字符串, 并且占用空间小
为什么是自增
这一点涉及到B+ 树的构建,我们知道索引一个最重要的特性就是排好序 的。如果我们不是顺序插入的,那么树就要自己额外做排序,调整树结构,浪费了性能
- 避免叶子节点的分裂
- 避免B+ 树做平衡调整
联合索引
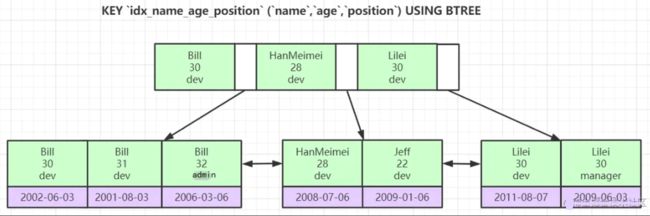
联合索引和单索引差不多,只不过是先按第一个字段排序,再按第二个字段排序,然后再按第三个字段排序。
这种排序规则表明了只有在第一个字段相等的情况下,第二字段才是有序的。第二字段相等的情况下,第三个字段才是有序的。
所以 name = 'Bill' and age = 20 and position = 'dev' 可以用到全部索引, 因为 name 确定了,age 是有序的,age 可以走索引, age 确定后 position 可以走索引。这个联合索引可以全部用到
如果是 name = 'Bill and age > 30 and position = 'dev'' , 首先name 可以走索引,name 确定后 age 是有序的,age 也可以走索引,但是 age > 30 导致 age 查出来的数据有多个(31 32), 31 和 32 下的 position (dev admin ) 不是有序的,便无法利用二分算法进行查找。所以无法利用 position 这个索引,这也就是左前缀法则的原理和联合索引失效的原理
到此这篇关于MySQL索引原理详解的文章就介绍到这了,更多相关MySQL索引内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!