【k8s】2、k8s安装、kubeSphere安装与使用
本文主要内容:
- 介绍k8s的kubeadmin和二进制部署方式
- 提供配置文件(仅供参考):https://gitee.com/HanFerm/java-config-files/blob/master/k8s相关文件
一、k8s集群搭建
本章节主要介绍如何搭建kubernetes的集群环境
2.1 环境规划
集群类型
kubernetes集群大体上分为两类:一主多从和多主多从。
- 一主多从:一台Master节点和多台Node节点,搭建简单,但是有单机故障风险,适合用于测试环境
- 多主多从:多台Master节点和多台Node节点,搭建麻烦,安全性高,适合用于生产环境

说明:为了测试简单,本次搭建的是 一主两从 类型的集群
主机规划
| 作用 | IP地址 | 操作系统 | 配置 |
|---|---|---|---|
| Master | 192.168.56.100 | Centos7.5 基础设施服务器 | 2颗CPU 2G内存 50G硬盘 |
| Node1 | 192.168.56.101 | Centos7.5 基础设施服务器 | 2颗CPU 2G内存 50G硬盘 |
| Node2 | 192.168.56.102 | Centos7.5 基础设施服务器 | 2颗CPU 2G内存 50G硬盘 |
安装方式
kubernetes有多种部署方式,目前主流的方式有kubeadm、minikube、二进制包
- minikube:一个用于快速搭建单节点kubernetes的工具
- kubeadm:一个用于快速搭建kubernetes集群的工具(本文选取),提供kubeadm init 和 kubeadm join,用于快速部署Kubernetes集群
- 创建一个Master 节点kubeadm init
- 将Node 节点加入到当前集群中$ kubeadm join
- 二进制包 :从官网下载每个组件(master和node有多个组件)的二进制包,依次去安装,此方式对于理解kubernetes组件更加有效
- 还跟证书有关
2.2 k8s环境准备
本次环境搭建需要安装三台Centos服务器(一主二从),然后在每台服务器中分别安装docker(18.06.3),kubeadm(1.17.4)、kubelet(1.17.4)、kubectl(1.17.4)程序。
2.2.1 主机安装
安装虚拟机过程中注意下面选项的设置:
-
操作系统环境:CPU(2C) 内存(2G) 硬盘(50G)
-
软件选择:基础设施服务器
-
分区选择:自动分区
-
网络配置:按照下面配置网路地址信息
网络地址:192.168.56.100 (每台主机都不一样 分别为100、101、102) 子网掩码:255.255.255.0 默认网关:192.168.56.2 DNS: 223.5.5.5 -
主机名设置:按照下面信息设置主机名
master节点: k8s-node1 node节点: k8s-node2 node节点: k8s-node3
为什么不以 master node1 node2这样的方式命名? 因为在生产中机器不一定作用永远不变
2.2.2 环境初始化
1) 检查操作系统的版本
# 此方式下安装kubernetes集群要求Centos版本要在7.5或之上
[root@master ~]# cat /etc/redhat-release
CentOS Linux release 7.5.1804 (Core)
2) 主机名解析
为了方便后面集群节点间的直接调用,在这配置一下主机名解析,企业中推荐使用内部DNS服务器
# 编辑三台服务器的/etc/hosts文件
cat >> /etc/hosts << EOF
192.168.56.100 k8s-node1
192.168.56.101 k8s-node2
192.168.56.102 k8s-node3
EOF
# 设置主机名 # 如果是vagrant启动的,那其实在vagrantFile中已经配置过了,在这里无需重复配置
hostnamectl set-hostname <hostname>
3) 时间同步
kubernetes要求集群中的节点时间必须精确一致,这里直接使用chronyd服务从网络同步时间。
企业中建议配置内部的时间同步服务器
# 启动chronyd服务
systemctl start chronyd
# 设置chronyd服务开机自启
systemctl enable chronyd
# chronyd服务启动稍等几秒钟,就可以使用date命令验证时间了
date
4) 禁用iptables和firewalld服务
kubernetes和docker在运行中会产生大量的iptables规则,为了不让系统规则跟它们混淆,直接关闭系统的规则
# 1 关闭firewalld服务
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
# 2 关闭iptables服务
[root@master ~]# systemctl stop iptables
[root@master ~]# systemctl disable iptables
5) 禁用selinux
selinux是linux系统下的一个安全服务,如果不关闭它,在安装集群中会产生各种各样的奇葩问题
# 编辑 /etc/selinux/config 文件,修改SELINUX的值为disabled
# 注意修改完毕之后需要重启linux服务
SELINUX=disabled
# sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
# setenforce 0 # 临时
6) 禁用swap分区
swap分区指的是虚拟内存分区,它的作用是在物理内存使用完之后,将磁盘空间虚拟成内存来使用
启用swap设备会对系统的性能产生非常负面的影响,因此kubernetes要求每个节点都要禁用swap设备
但是如果因为某些原因确实不能关闭swap分区,就需要在集群安装过程中通过明确的参数进行配置说明
# vim /etc/fstab 分区配置文件,注释掉swap分区一行
# 注意修改完毕之后需要重启linux服务
UUID=455cc753-7a60-4c17-a424-7741728c44a1 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
# /dev/mapper/centos-swap swap swap defaults 0 0
# 关闭swap
swapoff -a # 临时
# sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
7)修改linux的内核参数
# 修改linux的内核参数,添加网桥过滤和地址转发功能
# 编辑/etc/sysctl.d/kubernetes.conf文件,添加如下配置:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
# 重新加载配置
[root@master ~]# sysctl -p
# 加载网桥过滤模块
[root@master ~]# modprobe br_netfilter
# 查看网桥过滤模块是否加载成功
[root@master ~]# lsmod | grep br_netfilter
8)配置ipvs功能
在kubernetes中service有两种代理模型,
- 基于
iptables: - 是基于
ipvs:ipvs的性能明显要高一些,但是如果要使用它,需要手动载入ipvs模块
# 1 安装ipset和ipvsadm
[root@master ~]# yum install ipset ipvsadmin -y
# 2 添加需要加载的模块写入脚本文件
[root@master ~]# cat < /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
# 3 为脚本文件添加执行权限
[root@master ~]# chmod +x /etc/sysconfig/modules/ipvs.modules
# 4 执行脚本文件
[root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules
# 5 查看对应的模块是否加载成功
[root@master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
也有配置iptables的
将桥接的 IPv4 流量传递到 iptables 的链:
$ cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF $ sysctl --system # 生效
9) 重启服务器
上面步骤完成之后,需要重新启动linux系统
[root@master ~]# reboot
2.2.3 安装docker
Kubernetes 默认 CRI( 容器运行时) 为 Docker, 因此先安装 Docker
# 1 切换镜像源
[root@master ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 2 查看当前镜像源中支持的docker版本
[root@master ~]# yum list docker-ce --showduplicates
# 3 安装特定版本的docker-ce
# 必须指定--setopt=obsoletes=0,否则yum会自动安装更高版本
[root@master ~]# yum install --setopt=obsoletes=0 docker-ce-18.06.3.ce-3.el7 -y
# 4 添加一个配置文件yum
# Docker在默认情况下使用的Cgroup Driver为cgroupfs,而kubernetes推荐使用systemd来代替cgroupfs
[root@master ~]# mkdir /etc/docker
# 配置仓库地址
[root@master ~]# cat < /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://kn0t2bca.mirror.aliyuncs.com"]
}
EOF
# 5 启动docker
[root@master ~]# systemctl start docker
[root@master ~]# systemctl enable docker
# 6 检查docker状态和版本
[root@master ~]# docker version
2.3 kubeadmin方式搭建
2.3.1 安装K8S组件
# 由于kubernetes的镜像源在国外,速度比较慢,这里切换成国内的镜像源
# vim /etc/yum.repos.d/kubernetes.repo,添加下面的配置
cat >/etc/yum.repos.d/kubernetes.repo <安装kubeadm、kubelet和kubectl
# 安装kubeadm、kubelet和kubectl
[root@master ~]# yum install --setopt=obsoletes=0 kubeadm-1.17.17-0 kubelet-1.17.17-0 kubectl-1.17.17-0 -y
# 配置kubelet的cgroup
# 编辑/etc/sysconfig/kubelet,添加下面的配置
KUBELET_CGROUP_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
# 4 设置kubelet开机自启
[root@master ~]# systemctl enable kubelet
2.3.2 准备集群镜像
在安装kubernetes集群之前,必须要提前准备好集群需要的镜像,所需镜像可以通过下面命令查看
# 在安装kubernetes集群之前,必须要提前准备好集群需要的镜像,所需镜像可以通过下面命令查看
[root@master ~]# kubeadm config images list
创建脚本,执行下面的脚本,下面脚本的目的是拉取国内的镜像,然后tag打标签为k8s的镜像,这样创建集群的时候就不需要拉取k8s的镜像了
目前只需在master上执行,至于worker结点需要执行什么我们后文讲
# 下载镜像
# 此镜像在kubernetes的仓库中,由于网络原因,无法连接,下面提供了一种替代方案
images=(
kube-apiserver:v1.17.17
kube-controller-manager:v1.17.17
kube-scheduler:v1.17.17
kube-proxy:v1.17.17
pause:3.1
etcd:3.4.3-0
coredns:1.6.5
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
2.3.3 集群初始化
下面开始对集群进行初始化,并将node节点加入到集群中
kubeadm init
下面的操作只需要在
master节点上执行即可
使用kubeadm init命令在master上初始化kubeadm
# 创建集群 # 只在master结点运行
[root@master ~]# kubeadm init \
--kubernetes-version=v1.17.17 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--apiserver-advertise-address=192.168.56.100
# 只需要改最后一个地址
# 加上这个反倒拖慢了速度
# --image-repository registry.aliyuncs.com/google_containers \
* --apiserver-advertise-address=192.168.56.100 :这里的IP地址是master主机的地址,为上面的eth0网卡的地址;
* pod-network-cidr:pod之间的访问
# ===================输出信息========================
Your Kubernetes control-plane has initialized successfully! # 控制面板就是master
To start using your cluster, you need to run the following as a regular user:
然后他告诉你如果想要使用集群,需要把配置文件放到家目录下
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
你可以使用k8s集群了 但是你应该安装网络插件
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
# 如果你想要添加工作结点,可以在node结点上以root身份执行下面的话
kubeadm join 192.168.56.100:6443 --token 15ckqi.et50udit3pqdn180 \
--discovery-token-ca-cert-hash sha256:a23f2c32749a128d653712e33c4045e5932339ddd96e61251348b203cfdba4bb
# ===================根据输出信息做一些操作========================
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubeadm join
下面的操作只需要在
node节点上执行即可
# 将node节点加入集群 # 自己输入自己命令行输出的,不要全部复制
[root@master ~]# kubeadm join 192.168.56.100:6443 --token 8507uc.o0knircuri8etnw2 --discovery-token-ca-cert-hash sha256:acc37967fb5b0acf39d7598f8a439cc7dc88f439a3f4d0c9cae88e7901b9d3f
# 查看集群状态 状态均为NotReady,因为还没有配置网络插件
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady master 6m43s v1.17.4
node1 NotReady 22s v1.17.4
node2 NotReady 19s v1.17.4
2.3.4 安装网络插件
注意上面都是NotReady,因为没有为k8s集群安装网络
kubernetes支持多种网络插件,比如flannel、calico、canal等等,任选一种使用即可,本次选择flannel
下面操作依旧只在
master节点执行即可,插件使用的是DaemonSet的控制器,它会在每个节点上都运行
# 获取fannel的配置文件
[root@master ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 修改文件中quay.io仓库为quay-mirror.qiniu.com
# 也可以拷贝我的镜像
# wget https://gitee.com/HanFerm/java-config-files/blob/master/k8s相关文件/尚硅谷YAML文件/kube-flannel.yaml
# 使用配置文件启动flannel
[root@master ~]# kubectl apply -f kube-flannel.yml
# 稍等片刻,再次查看集群节点的状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 15m v1.17.4
node1 Ready 8m53s v1.17.4
node2 Ready 8m50s v1.17.4
工作结点notReady?
我遇到过安装完flannel后master ready了,工作结点却notReady
# 看pod发现是工作结点的proxy和flannel pod没启动起来,显示ContainerCreating
kubectl get pod -n kube-system
# 看看出错原因
kubectl describe pod kube-proxy-dm925 --namespace=kube-system
该proxy日志:
该pod被分配到node3
Normal Scheduled 12m default-scheduler Successfully assigned kube-system/kube-proxy-dm925 to k8s-node3
to create pod sandbox: rpc error: code = Unknown desc = failed pulling image “k8s.gcr.io/pause:3.1”: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning FailedCreatePodSandBox 41s kubelet, k8s-node3 Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image “k8s.gcr.io/pause:3.1”: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
创建kubelet pod出错,原来是因为pause这个容器出错,而且是因为拉取镜像出错,我们知道了,之前的脚本是在master上执行的,并没有给worker结点拉取国内镜像,现在我们知道了应该给他拉一下pause镜像
Warning FailedCreatePodSandBox 4m24s (x10 over 11m) kubelet, k8s-node3 Failed
# 分别在两个worker node执行
# 不怕硬盘不够的话可以直接执行master那个下载镜像脚本,省得报错
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.17.17
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.17.17 k8s.gcr.io/kube-proxy:v1.17.17
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
稍等一会,可以看pod状态,也可以看node状态,正常了
kubectl get pod -n kube-system
# 改为你的pod
kubectl describe pod kube-proxy-dm925 --namespace=kube-system
# master上执行
kubectl get nodes
[root@k8s-node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready master 21m v1.17.17
k8s-node2 Ready 20m v1.17.17
k8s-node3 Ready 20m v1.17.17
至此,kubernetes的集群环境搭建完成
内存不够可以rmi不需要的镜像
卸载k8s?
如果你打算不写k8s,要提桶run了,卸载方式为:
# 每个结点上执行
kubectl delete -f kube-flannel.yml
kubeadm reset
rm -rf $HOME/.kube
rm -rf /etc/cni/net.d
2.4 二进制方式搭建k8s
同样需要先进行一些准备工作,这里不再赘述,2.2.4之前的都是初始化配置
可以参考:https://blog.csdn.net/givenchy_yzl/article/details/118556798
Master:
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- flannel:提供集群间网络
Node:
- kubelet:部署容器,监控容器
- kube-proxy:提供容器间的网络
高可用:
api-server先写入etcd再处理
192.168.15.51 k8s-m-01 m1 etcd-01
192.168.15.52 k8s-m-02 m2 etcd-02
192.168.15.53 k8s-m-03 m3 etcd-03
192.168.15.54 k8s-n-01 n1
192.168.15.55 k8s-n-02 n2
# 虚拟VIP
192.168.15.56 k8s-m-vip vip
顺序:集群规划、创建证书(生成其他普通证书需要CA证书生成,对称秘钥)、编写配置文件、部署各个组件
主要步骤:
-
修改网卡
vim /etc/systemconfig/network,修改IP和gateway后重启systemctl restart network。ip a显示192和172 -
修改主机名 hostnamectl set-hostname k8s-m-01
-
安装虚拟机和操作系统,对操作系统进行初始化操作
-
生成cfssl 自签证书
- 私钥
ca-key.pem、公钥ca.pem server-key.pem、server.pem
- 私钥
-
部署Etcd集群
- 部署的本质,就是把etcd集群交给 systemd 管理
- 把生成的证书复制过来,启动,设置开机启动
-
为apiserver自签证书,生成过程和etcd类似
-
部署master组件,主要包含以下组件
- apiserver
- controller-manager
- scheduler
- 交给systemd管理,并设置开机启动
- 如果要安装最新的1.19版本,下载二进制文件进行安装
-
部署node组件
- docker
- kubelet
- kube-proxy【需要批准kubelet证书申请加入集群】
- 交给systemd管理组件- 组件启动,设置开机启动
-
批准kubelet证书申请 并加入集群
-
部署CNI网络插件
-
测试Kubernets集群【安装nginx测试】
证书类型
- client certificate: 客户端使用,用于服务端认证客户端,例如etcdctl、etcd proxy、fleetctl、docker客户端
- server certificate: 服务端使用,客户端以此验证服务端身份,例如docker服务端、kube-apiserver
- peer certificate: 双向证书,用于etcd集群成员间通信
0)基础
证书学习:https://blog.csdn.net/dihunman8809/article/details/101624740
核心概念理解
- 认证证书=公钥。 公钥和私钥都可以存储为pem格式
- 证书前面请求CSR(Certificate Signing Request):发送CSR请求后得到CRT文件(证书)
1)cfssl自签证书
cfssl 是一个开源的证书管理工具, 使用 json 文件生成证书, 相比 openssl 更方便使用。
找任意一台服务器操作, 这里用 Master 节点。
步骤:
- 把cfssl工具的3个文件先下下来
- 创建 ~TLS/{etcd,k8s}两个文件夹,分别用于存放etcd和k8s的证书
- 创建CA
- 创建证书:得到公钥私钥
- 适用刚才得到的公钥私钥 创建etcd证书
需要证书的插件:
- etcd
- api-server
- controller-manager
- kube-scheduler
- kubelet
- kube-proxy
- 集群管理员
- TLS BootStrapping证书
- flannel(主要和etcd连)
1)安装cfssl
# 下载几个文件到服务器上,然后放到/usr下
# cfssl
curl -s -L -o /usr/bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
# cfssljson
curl -s -L -o /usr/bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
# cfssl-certinfo
curl -s -L -o /usr/bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x /usr/bin/cfssl*
配置
- ca-config.json:用于生成CA证书
- ca-csr.json:
创建生成CA证书的JSON配置文件
ca-config.json
7-200 ~]# mkdir /opt/certs
7-200 ~]# vim /opt/certs/ca-config.json
{
"signing": { # 表示该证书可用于签名其它证书;生成的ca.pem 证书中CA=TRUE;
"default": {
"expiry": "175200h"
},
"profiles": {
"server": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"server auth" # 表示client 可以用该CA 对server 提供的证书进行校验
]
},
"client": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"client auth" # 表示server 可以用该CA 对client 提供的证书进行验证。
]
},
"peer": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
证书类型
- client certificate: 客户端使用,用于服务端认证客户端,例如etcdctl、etcd proxy、fleetctl、docker客户端
- server certificate: 服务端使用,客户端以此验证服务端身份,例如docker服务端、kube-apiserver
- peer certificate: 双向证书,用于etcd集群成员间通信
ca-csr.json
创建生成CA证书签名请求(csr)的JSON配置文件
/opt/certs/ca-csr.json
{
"CN": "kubernetes-ca",
"hosts": [
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "shanghai",
"L": "shanghai",
"O": "phc-dow",
"OU": "kjdow"
}
],
"ca": {
"expiry": "175200h"
}
}
CN: Common Name,浏览器使用该字段验证网站是否合法,一般写的是域名。非常重要。浏览器使用该字段验证网站是否合法
C: Country, 国家
ST: State,州,省
L: Locality,地区,城市
O: Organization Name,组织名称,公司名称
OU: Organization Unit Name,组织单位名称,公司部门
生成CA证书和私钥
根证书
7-200 ~]# cd /opt/certs
7-200 certs]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca
2019/01/18 09:31:19 [INFO] generating a new CA key and certificate from CSR
2019/01/18 09:31:19 [INFO] generate received request
2019/01/18 09:31:19 [INFO] received CSR
2019/01/18 09:31:19 [INFO] generating key: rsa-2048
2019/01/18 09:31:19 [INFO] encoded CSR
2019/01/18 09:31:19 [INFO] signed certificate with serial number 345276964513449660162382535043012874724976422200
7-200 certs]# ls -l
-rw-r--r-- 1 root root 836 Jan 16 11:04 ca-config.json
-rw-r--r-- 1 root root 332 Jan 16 11:10 ca-csr.json
-rw-r--r-- 1 root root 1001 Jan 16 11:17 ca.csr
-rw------- 1 root root 1675 Jan 16 11:17 ca-key.pem
-rw-r--r-- 1 root root 1354 Jan 16 11:17 ca.pem
生成ca.pem、ca.csr、ca-key.pem(CA私钥,需妥善保管)
2)etcd集群
下载地址: https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
因为很多教程教安装了,但很多新手都会选择kubeadmin的安装方式,所以再次我就不详述二进制安装了,只说主要步骤,java开发搞得流程即可,详细配置可以去gitee中查看。
部署步骤:
- 在opt/etcd/下创建3个文件夹:bin cfg ssl 分别放置执行文件、配置、证书
- 把下载到的文件夹里面的etcd服务器和客户端ctl放到bin下
- 创建etcd.conf文件指定配置信息
- systemd管理etcd:/usr/lib/systemd/system/etcd.service写入内容
- 把证书放到ssl下:
cp ~/TLS/etcd/ca*pem ~/TLS/etcd/server*pem /opt/etcd/ssl/ - 设置开启自启
- 将etcd+system文件夹下内容拷贝到结点2和结点3。然后修改conf下的ETCD_NAME为2和3;修改所有IP为该结点的IP。
二进制和配置文件都放到gitee中了,不赘述
3)Master插件部署
3.1)kube-apiserver
- 生成公钥私钥
- 生成证书
- 下载api-server二进制文件
- 创建几个文件夹 /opt/kubernetes/{bin,cfg,ssl,logs}
- 拷贝几个插件到bin下:kube-apiserverkube-schedulerkube-controller-manager
- 拷贝ctl到/usr/bin/kubectl
- 拷贝证书
- 让ststemd管理api-server、controller-manager、scheduler
4)Worker Node部署
- 配置文件
- 证书
- 让ststemd管理
5)CNI
-
mkdir /opt/cni/bin
-
部署flannel
-
让flannel接管docker网络,修改docker启动文件
-
先启动flannel再启动docker,发现docker0的IP编程10.241.248.1/21
11110001。每台机器还有个flannel.1网络,ip 10.242{241,242}.248{88,40}.0/32-
flannel的配置文件里指定了endpoints是3台主机eth0的IP,还有
Network:10.244.0.0/1211110100 -
# 网关Network:10.244.0.0/12 244=`1111`0100 flannel.1 docker0 # 机器1 10.241.248.0/32 10.241.248.1/21 # 机器2 10.241. 88.0/32 # 机器3 10.241. 40.0/32 互相ping flannel.1 都成功
-
-
coreDNS
- 在kube-proxy-config.yml中配置过clusterCIDR 10.96.0.0/16
- 在kubelet-config.yaml中配置了clusterDNS:-
10.96.0.2 - 在部署DNS时与上面保持一直是
10.96.0.2
2.5 测试
接下来在kubernetes集群中部署一个nginx程序,测试下集群是否在正常工作。
# 部署nginx
[root@master ~]# kubectl create deployment nginx --image=nginx:1.14-alpine
# 暴露端口
[root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
# 查看服务状态
[root@master ~]# kubectl get pods,service
NAME READY STATUS RESTARTS AGE
pod/nginx-86c57db685-fdc2k 1/1 Running 0 18m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 443/TCP 82m
service/nginx NodePort 10.104.121.45 80:30073/TCP 17m
# 上面的ip不是nginx的ip
# 4 最后在电脑上访问下部署的nginx服务
192.168.56.101:30073
二、安装KubeSphere
可以参考https://www.cnblogs.com/hujinzhong/p/14229728.html
- 安装helm
- 安装tiller
安装helm
# 去下载 https://gitee.com/HanFerm/java-config-files/blob/master/k8s相关文件/尚硅谷YAML文件/脚本/get_helm.sh
sh get_helm.sh
# 还是可能下载失败,可以去里面改改内容
# github打不开可以去gitee搜搜,一般软件都有人克隆过
# 可以去这里下载压缩包 https://github.com/helm/helm/releases/tag/v2.17.0
# helm--linux-amd64.tar.gz
ll helm-v2.17.0-linux-amd64.tar.gz
tar xf helm-v2.17.0-linux-amd64.tar.gz
cp linux-amd64/helm /usr/local/bin
cp linux-amd64/tiller /usr/local/bin
helm version
# Client: &version.Version{SemVer:"v2.17.0"}
# Error: could not find tiller
# 其他脚本和yaml在我上面gitee里都有,以后就不贴地址了
kubectl apply -f helm-rbac.yaml
helm init --service-account tiller --upgrade \
-i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.17.0 \
--stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
# To prevent this, run `helm init` with the --tiller-tls-verify flag.
kubectl get pods --all-namespaces
# 看大tiller pod # 检查下
tiller
# 输出[main] 2021/10/08 14:38:38 Starting Tiller v2.17.0 (tls=false)
helm version
安装 OpenEBS
它是k8s的存储类型StorageClass,因为集群里没有StorageClass,所以我们安装OpenEBS作为StorageClass,且必须手动指定默认是它
安装可以参考https://v2-1.docs.kubesphere.io/docs/zh-CN/appendix/install-openebs/
仅需要在master执行,因为他是存储
# 去掉污点,污点会影响OpenEBS安装
kubectl describe node k8s-1 | grep Taint
# 如果上面有输出就去掉指定的内容
# 比如输出了 Taints: node-role.kubernetes.io/master:NoSchedule
kubectl taint nodes k8s-1 node-role.kubernetes.io/master:NoSchedule-
kubectl describe node k8s-1 | grep Taint
# 输出为none
kubectl create ns openebs
# 我记得这个版本会影响kubeSphere的版本,自己注意下就行,这个文件我那放了
kubectl apply -f openebs-operator-1.7.0.yaml
# 又安装了一堆pod
#查看storageclass
kubectl get sc
# 显示false和Delete正常
# 设置默认storageclass
kubectl patch storageclass openebs-hostpath -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
# 验证
kubectl get pod -n openebs
kubectl get sc
注意:此时不要给master加上污点,否者导致后面的pods安装不上(openldap,redis),待kubesphere安装完成后加上污点
安装kubesphere
kubesphere简写为ks(快手?)
文档:https://kubesphere.io/zh/docs/installing-on-kubernetes/introduction/overview/
kubectl apply -f kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
# 可以编辑devops为true
监控ks安装进度、是否正常
#使用如下命令监控
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
正确输出内容为:
Start installing monitoring
Start installing multicluster
Start installing openpitrix
Start installing network
Start installing devops
**************************************************
Waiting for all tasks to be completed ...
task multicluster status is successful (1/5)
task network status is successful (2/5)
task openpitrix status is successful (3/5)
task devops status is successful (4/5) # 我自己开启了devops
task monitoring status is successful (5/5)
**************************************************
Collecting installation results ...
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://192.168.56.100:30880
Account: admin
Password: P@88w0rd
NOTES:
1. After you log into the console, please check the
monitoring status of service components in
"Cluster Management". If any service is not
ready, please wait patiently until all components
are up and running.
2. Please change the default password after login.
#####################################################
https://kubesphere.io 2021-10-09 05:30:34
#####################################################
使用 kubectl get pod --all-namespaces,查看所有 Pod 在 KubeSphere 相关的命名空间运行是否正常。如果是,请通过以下命令检查控制台的端口(默认为 30880),安全组需放行该端口
账号admin 密码 P@88w0rd
卸载kubeSphere
比较麻烦,去官网搜索一下,需要使用脚本卸载
只要上面没有出现成功页面,都要通过该脚本删除,别的方式删不干净,会使得ks安装不成功,以及后续使用有地方service有差异
定制kubeSphere插件
https://kubesphere.com.cn/docs/quick-start/enable-pluggable-components/
官网也说了,如果要安装后定义插件,可以在kubeSphere中
集群管理-自定义资源 CRD-搜索clusterconfiguration点击- ks-installer点击最右侧-即可编辑配置

方法2:kubectl edit cm -n kubesphere-system ks-installer
定制的内容
- devops
- notification
- alerting
登录报错
登录时遇到了一个这个问题
request to http://ks-apiserver.kubesphere-system.svc/oauth/token failed, reason: connect ECONNREFUSED 10.111.99.93:80
这个IP是eth0的IP,不是eth1的IP,但我机器外是访问不到10IP的啊

10的IP,再结合上面我的日志居然是让登录10.0.2.15,而不是我想要的eth1 192.168.56.100,所以可能是IP/host引起的问题。
又重新部署了一下k8s,让api-server是192的IP
三、使用KubeSphere
1、基本页面



2、用户管理
官方写的都比较全,我这里就简单贴贴图,让手懒或配置不够的同学熟悉一下
| 内置角色 | 描述 |
|---|---|
workspaces-manager |
企业空间管理员,管理平台所有企业空间。 |
users-manager |
用户管理员,管理平台所有用户。 |
platform-regular |
平台普通用户,在被邀请加入企业空间或集群之前没有任何资源操作权限。 |
platform-admin |
平台管理员,可以管理平台内的所有资源。 |
RBAC:
- 角色users-manager(3.1中默认有该角色)
- 账号 ali-hr

登出admin后重新登录ali-hr
- 可以创建账户
- ws-manager 角色 workerspaces-manager
- ws-admin 角色 cluster-regular
- project-admin 角色cluter-regular
- project-regular 角色 cluster-regular
去登录ws-manager,

ws-admin登录之前要使用ws-manager分配给他

登录ws-admin,邀请project-regular(ws-viewer只读命名空间)、project-admin(ws-regular角色)不贴图了
3、创建项目
登录project-admin创建项目,邀请project-regular来开发



邀请开发人员
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NK9LDaLj-1633946056369)(https://gitee.com/HanFerm/image-bed/raw/master/img/20211009223801.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fScerCx3-1633946056370)(C:/Users/HAN/AppData/Roaming/Typora/typora-user-images/image-20211009223828766.png)]
4、创建devops

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0uSy6C0y-1633946056372)(C:/Users/HAN/AppData/Roaming/Typora/typora-user-images/image-20211009224557416.png)]
5、部署应用
参考https://kubesphere.com.cn/docs/quick-start/wordpress-deployment/

动手实验
步骤 1:创建密钥
创建 MySQL 密钥
环境变量 WORDPRESS_DB_PASSWORD 是连接到 WordPress 数据库的密码。在此步骤中,您需要创建一个密钥来保存将在 MySQL Pod 模板中使用的环境变量。
-
使用
project-regular帐户登录 KubeSphere 控制台,访问demo-project的详情页并导航到配置中心。在密钥中,点击右侧的创建。
-
输入基本信息(例如,将其命名为
mysql-secret)并点击下一步。在下一页中,选择类型为 Opaque(默认),然后点击添加数据来添加键值对。输入如下所示的键 (Key)MYSQL_ROOT_PASSWORD和值 (Value)123456,点击右下角 √ 进行确认。完成后,点击创建按钮以继续。
创建 WordPress 密钥
按照以上相同的步骤创建一个名为 wordpress-secret 的 WordPress 密钥,输入键 (Key) WORDPRESS_DB_PASSWORD 和值 (Value) 123456。创建的密钥显示在列表中,如下所示:
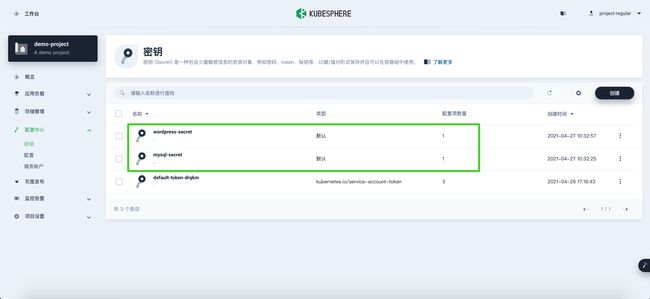
步骤 2:创建存储卷
-
访问存储管理下的存储卷,点击创建。

-
输入卷的基本信息(例如,将其命名为
wordpress-pvc),然后点击下一步。 -
在存储卷设置中,需要选择一个可用的存储类型,并设置访问模式和存储卷容量。您可以直接使用如下所示的默认值,点击下一步继续。

-
对于高级设置,您无需为当前步骤添加额外的配置,点击创建完成即可。
步骤 3:创建应用程序
添加 MySQL 后端组件
-
导航到应用负载下的应用,选择自制应用,再点击构建自制应用。

-
输入基本信息(例如,在应用名称一栏输入
wordpress),然后点击下一步。
-
在服务组件中,点击添加服务以在应用中设置组件。

-
设置组件的服务类型为有状态服务。
-
输入有状态服务的名称(例如 mysql)并点击下一步。

-
在容器镜像中,点击添加容器镜像。

-
在搜索框中输入
mysql:5.6,按下回车键,然后点击使用默认端口。由于配置还未设置完成,请不要点击右下角的 √ 按钮。
备注
在高级设置中,请确保内存限制不小于 1000 Mi,否则 MySQL 可能因内存不足而无法启动。
-
向下滚动到环境变量,点击引用配置文件或密钥。输入名称
MYSQL_ROOT_PASSWORD,然后选择资源mysql-secret和前面步骤中创建的密钥MYSQL_ROOT_PASSWORD,完成后点击 √ 保存配置,最后点击下一步继续。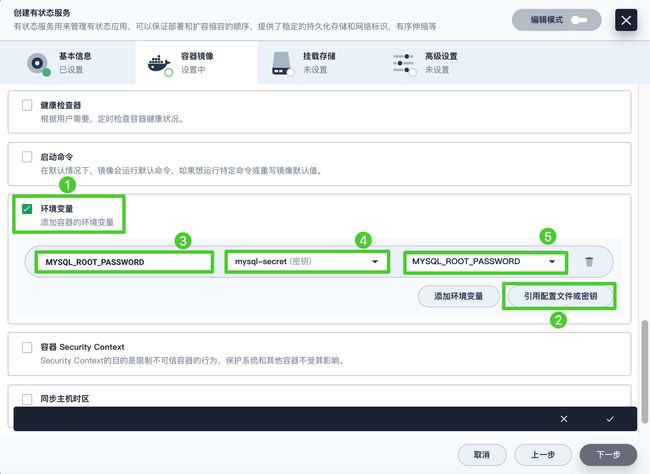
-
选择挂载存储中的添加存储卷模板,输入存储卷名称 (
mysql) 和挂载路径(模式:读写,路径:/var/lib/mysql)的值,如下所示:
完成后,点击 √ 保存设置并点击下一步继续。
-
在高级设置中,可以直接点击添加,也可以按需选择其他选项。

-
现在,MySQL 组件已经添加完成,如下所示:

添加 WordPress 前端组件
-
再次点击添加服务,这一次选择无状态服务。输入名称
wordpress并点击下一步。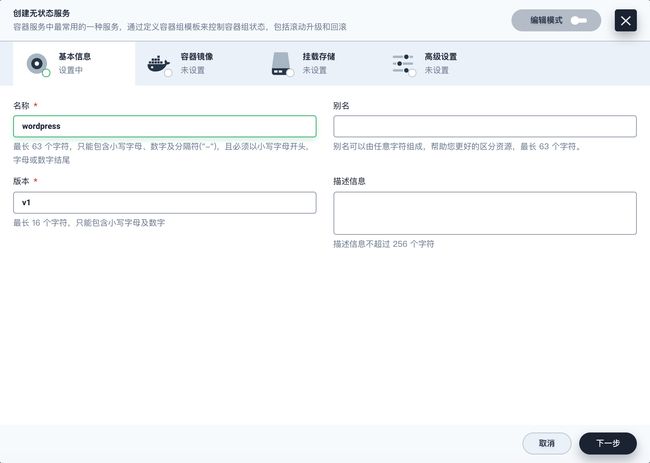
-
与上述步骤类似,点击添加容器镜像,在搜索栏中输入
wordpress:4.8-apache并按下回车键,然后点击使用默认端口。
-
向下滚动到环境变量,点击引用配置文件或密钥。这里需要添加两个环境变量,请根据以下截图输入值:
- 对于
WORDPRESS_DB_PASSWORD,请选择在步骤 1 中创建的wordpress-secret和WORDPRESS_DB_PASSWORD。 - 点击添加环境变量,分别输入
WORDPRESS_DB_HOST和mysql作为键 (Key) 和值 (Value)。
警告
对于此处添加的第二个环境变量,该值必须与步骤 5 中创建 MySQL 有状态服务设置的名称完全相同。否则,WordPress 将无法连接到 MySQL 对应的数据库。

点击 √ 保存配置,再点击下一步继续。
- 对于
-
在挂载存储中,点击添加存储卷,并选择已有存储卷。
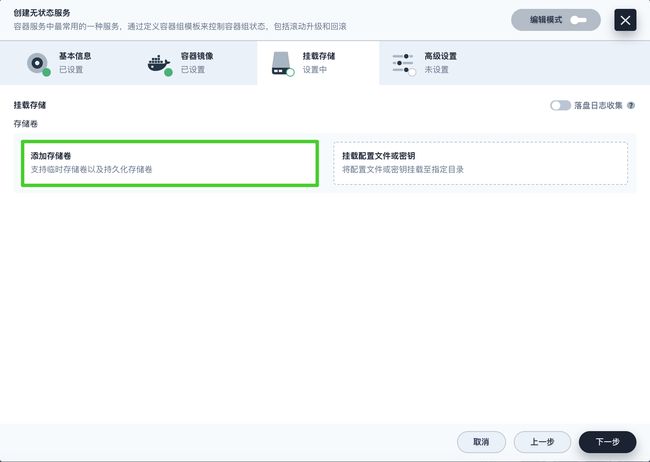

-
选择上一步创建的
wordpress-pvc,将模式设置为读写,并输入挂载路径/var/www/html。点击 √ 保存,再点击下一步继续。
-
在高级设置中,可以直接点击添加创建服务,也可以按需选择其他选项。

-
现在,前端组件也已设置完成。点击下一步继续。

-
您可以在这里设置路由规则(应用路由 Ingress),也可以直接点击创建。

-
创建后,应用将显示在下面的列表中。

步骤 4:验证资源
在工作负载中,分别检查部署和有状态副本集中 wordpress-v1 和 mysql-v1 的状态。如果它们的运行状态如下图所示,就意味着 WordPress 已经成功创建。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bc4Mcs7H-1633946056401)(https://kubesphere.com.cn/images/docs/zh-cn/quickstart/wordpress-deployment/wordpress-deployment1.png)]

步骤 5:通过 NodePort 访问 WordPress
-
若要在集群外访问服务,请首先导航到服务。点击
wordpress右侧的三个点后,选择编辑外网访问。
-
在访问方式中选择
NodePort,然后点击确定。
-
点击服务进入详情页,可以看到暴露的端口。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GDSFuhOk-1633946056405)(https://kubesphere.com.cn/images/docs/zh-cn/quickstart/wordpress-deployment/nodeport-number1.png)]
-
通过
{Node IP}:{NodePort}访问此应用程序,可以看到下图:
备注
在访问服务之前,请确保安全组中的端口已打开。