【JavaWeb从入门到实战】MySQL筑基&初探SQL
一个人走得远了,就会忘记自己为了什么而出发,希望你可以不忘初心,不要随波逐流,一直走下去
欢迎关注点赞收藏留言
本文由 程序喵正在路上 原创,CSDN首发!
系列专栏:JavaWeb从入门到实战
首发时间:2022年8月18日
✅ 如果觉得博主的文章还不错的话,希望小伙伴们三连支持一下哦
阅读指南
- 一、JavaWeb介绍
- 二、数据库相关概念
- 三、MySQL数据库
-
- MySQL安装
- MySQL配置
- MySQL登录、退出
- MySQL卸载
- MySQL数据模型
- 四、SQL概述
-
- SQL简介
- SQL通用语法
- SQL分类
- 五、DDL -- 数据定义语言
-
- DDL -- 操作数据库
- DDL -- 操作表
- 六、navicat
-
- navicat概述
- navicat安装
- navicat使用
- 七、DML -- 数据操作语言
-
- 添加数据
- 修改数据
- 删除数据
- 八、DQL -- 数据查询语言
-
- 基础查询
-
- 1 - 语法
- 2 - 练习
- 条件查询
-
- 1 - 语法
- 2 - 条件查询练习
- 3 - 模糊查询练习
- 排序查询
-
- 1 - 语法
- 2 - 练习
- 聚合函数
-
- 1 - 概念
- 2 - 聚合函数分类
- 3 - 聚合函数语法
- 4 - 练习
- 分组查询
-
- 1 - 语法
- 2 - 练习
- 分页查询
-
- 1 - 语法
- 2 - 练习
一、JavaWeb介绍
-
Web:全球广域网,也称为万维网(www),能够通过浏览器访问的网站
-
JavaWeb:是用 Java 技术来解决相关 web 互联网领域的技术栈
-
通俗地说,JavaWeb 就是用 Java 语言来做网站的
那我们的网站是怎么呈现出来的呢?
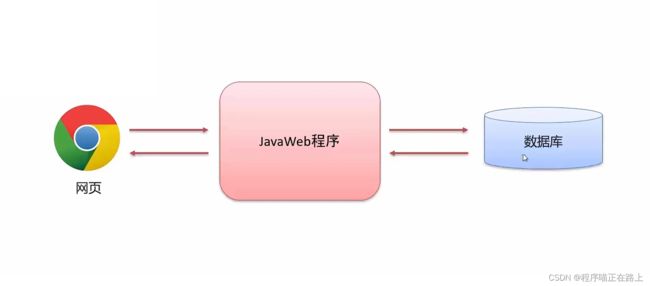
- 网页:用来展现数据
- 数据库:存储和管理数据
- JavaWeb 程序:逻辑处理
二、数据库相关概念
数据库
- 存储数据的仓库,数据是有组织地进行存储
- 英文:DataBase,简称 DB
数据库管理系统
- 管理数据库的大型软件,例如 MySQL
- 英文:DataBase Management System,简称 DBMS
SQL
- 英文:Structured Query Language,简称 SQL,结构化查询语言
- 操作关系型数据库的编程语言
- 定义操作所有关系型数据库的统一标准

常见的关系型数据库管理系统
- Oracle:收费的大型数据库,Oracle 公司的产品
- MySQL:开源免费的中小型数据库,后来 Sun 公司收购了 MySQL,而 Sun 公司又被 Oracle 收购
- SQL Server:MicroSoft 公司收费的中型数据库。C#、.net 等语言常使用
- PostgreSQL:开源免费的中小型数据库
- DB2:IBM 公司的大型收费数据库产品
- SQLite:嵌入式的微型数据库,如:作为 Android 内置数据库
- MariaDB:开源免费的中小型数据库
三、MySQL数据库
MySQL安装
点击此处进入MySQL官网,你会看到下面这个界面
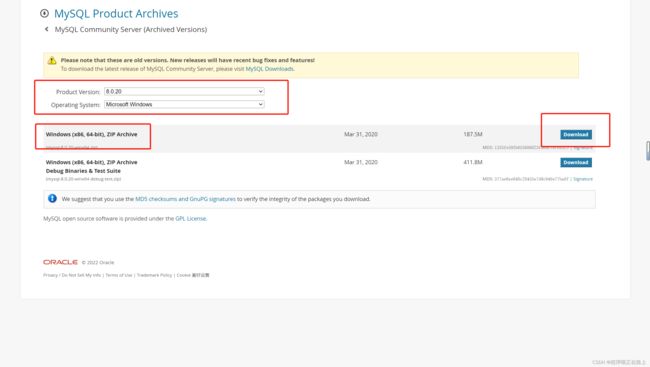
选择要下载的 MySQL 版本和你电脑对应的操作系统,个人建议是不要下载最新版本的,可能会不太稳定,接着选择显示出来的下载链接第一个,点击 DownLoad 进行下载

下载完是一个压缩包,点击解压即可,然后你可以把这个文件夹放到你想放的地方

MySQL配置
✓ 添加环境变量
环境变量里面有很多选项,这里我们只需要用到 Path 这个参数
为什么我们在初始化的开始要添加环境变量呢?
在黑框 (即CMD) 中输入一个可执行程序的名字,Windows 会先在环境变量中的 Path 所指的路径中寻找一遍,如果找到了就直接执行,没找到就在当前工作目录找,如果还没找到,就报错。我们添加环境变量的目的就是能够在任意一个黑框直接调用 MySQL 中的相关程序而不用总是修改工作目录,大大简化了操作
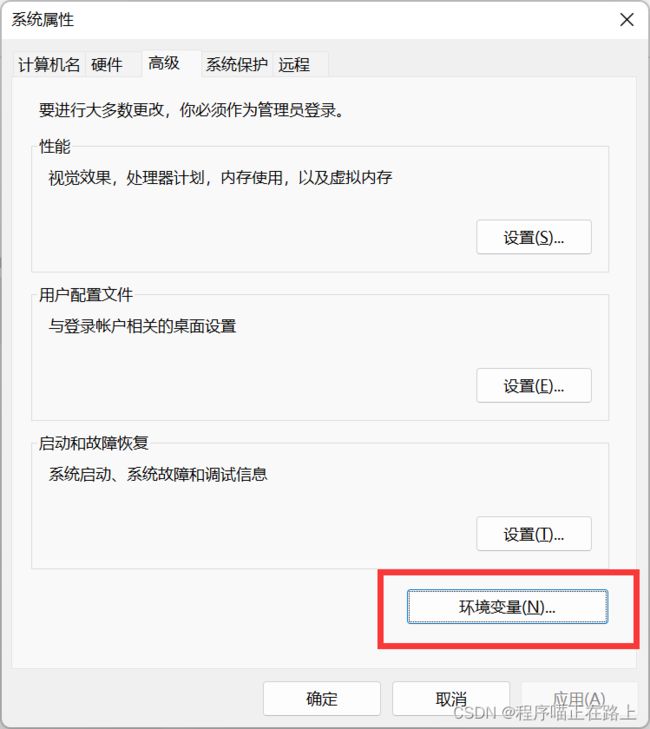
① 找到 此电脑 ,右键选择 属性 ,找到 高级系统设置 ,如下

② 找到 环境变量 ,如下
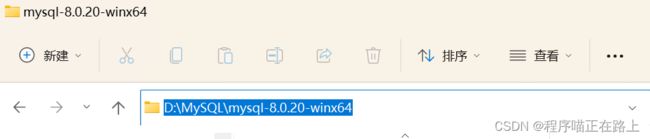
③ 接着把你刚刚 安装 MySQL 的目录 先 复制 一份,如下
④ 找到 系统变量,点击 新建
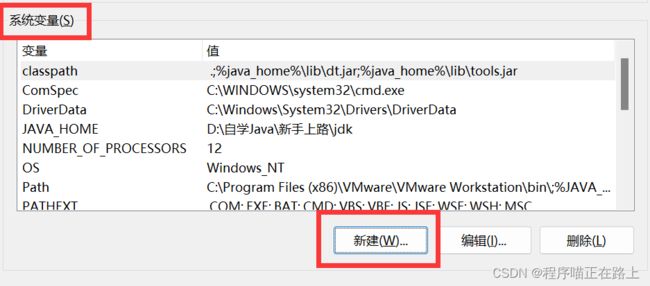
⑤ 填写变量名 MYSQL_HOME,将前面复制的路径粘贴到变量值处,然后点击确定
MYSQL_HOME
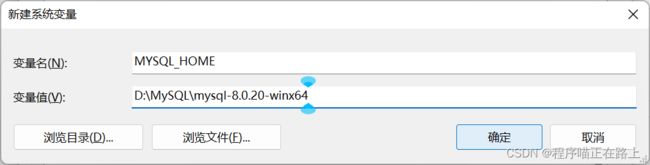
⑥ 找到 Path,点击 编辑

⑦ 点击 新建,输入 %MYSQL_HOME%\bin,然后点击 确定
%MYSQL_HOME%\bin
如何验证是否添加成功?
右键开始菜单,选择 命令提示符(管理员),打开黑框,敲入mysql,回车
如果提示 Can't connect to MySQL server on 'localhost' (如下图)则证明添加成功

如果提示 mysql不是内部或外部命令,也不是可运行的程序或批处理文件 则表示添加添加失败,请重新检查步骤并重试
✓ 新建配置文件
新建一个文本文件,内容如下,注意文件路径要改成你自己的路径
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录 ----------是你的文件路径-------------
basedir=E:\mysql\mysql
# 设置mysql数据库的数据的存放目录 ---------是你的文件路径data文件夹自行创建
datadir=E:\mysql\mysql\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。
max_connect_errors=10
# 服务端使用的字符集默认为utf8mb4
character-set-server=utf8mb4
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
#mysql_native_password
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8mb4
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8mb4
把上面的文本文件另存为,在保存类型里选 所有文件 (*.*),文件名叫 my.ini,存放的路径为 MySQL 的 根目录,也就是刚刚安装 MySQL 的目录
上面代码的意思是配置数据库的默认编码集为 utf-8 和默认存储引擎为 INNODB
✓ 初始化MySQL
在刚才的黑框中敲入mysqld --initialize-insecure,回车,稍微等待一会,如果出现没有出现报错信息 (如下图) 则证明 data 目录初始化没有问题,此时再查看 MySQL 目录下已经有 data 目录生成
mysqld --initialize-insecure
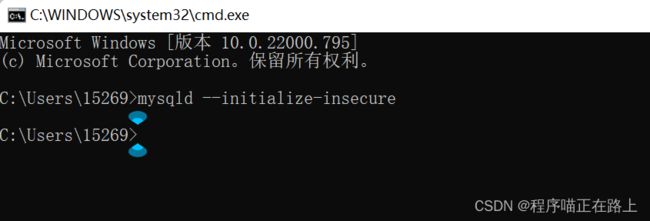

✓ 注册MySQL服务
以管理员身份运行 cmd,在里面敲入 mysqld -install,然后回车
mysqld -install
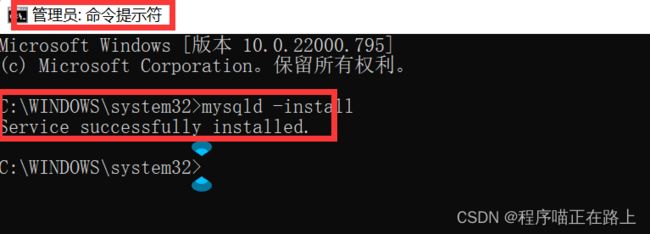
现在你的计算机上已经安装好了 MySQL 服务了
MySQL登录、退出
✓ 启动MySQL服务
在黑框里敲入 net start mysql,然后回车
net start mysql // 启动mysql服务
net stop mysql // 停止mysql服务

✓ 修改默认账户密码
在黑框里敲入 mysqladmin -u root password 1234,这里的 1234 就是指默认管理员 (即 root 账户) 的密码,可以自行修改成你喜欢的
mysqladmin -u root password 1234

到这里,MySQL 解压版就安装完成了!
✓ 登录MySQL
右键开始菜单,选择 命令提示符,打开黑框,在黑框中输入,mysql -uroot -p1234,回车,出现下图且左下角为 mysql>,则登录成功
mysql -uroot -p1234
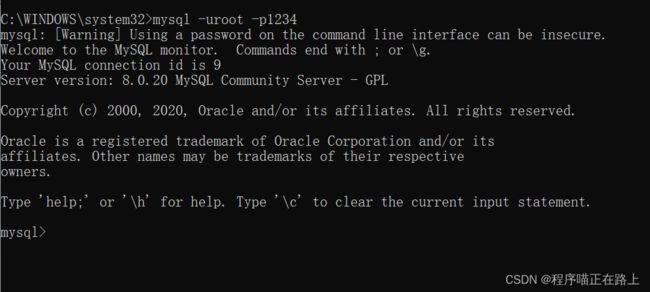
到这里你就可以开始你的MySQL之旅了!
退出 mysql 的命令:
exit
或者
quit

登录参数:
mysql -u用户名 -p密码 -h要连接的mysql服务器的ip地址(默认127.0.0.1) -P端口号(默认3306)
MySQL卸载
如果你想删库跑路,也很简单
右键开始菜单,选择 命令提示符(管理员),打开黑框
- 敲入
net stop mysql,回车
net stop mysql

2. 再敲入mysqld -remove mysql,回车
mysqld -remove mysql
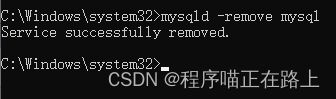
3. 最后删除 MySQL 目录及相关的环境变量即可
MySQL数据模型
关系型数据库
关系型数据库是建立在关系模型基础上的数据库,简单说,关系型数据库是由多张能互相连接的 二维表 组成的数据库
✅优点
- 都是使用表结构,格式一致,易于维护
- 使用通用的 SQL 语言操作,使用方便,可用于复杂查询
- 数据存储在磁盘中,安全
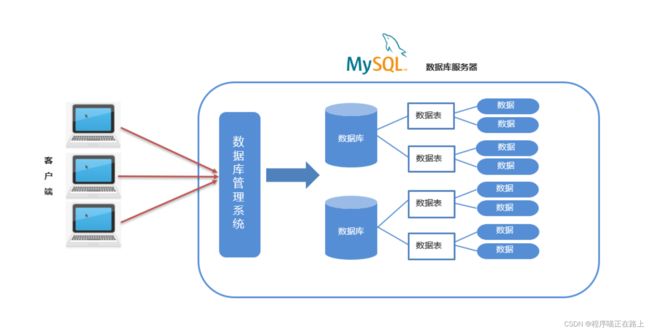
- MySQL 中可以创建多个数据库,每个数据库对应到磁盘上的一个文件夹
- 在每个数据库中可以创建多个表,每张都对应到磁盘上一个 frm 文件
- 每张表可以存储多条数据,数据会被存储到磁盘中 MYD 文件中
四、SQL概述
了解了数据模型后,接下来我们就学习 SQL 语句,通过 SQL 语句对数据库、表、数据进行增删改查操作
SQL简介
- 英文:Structured Query Language,简称 SQL
- 结构化查询语言,一门操作关系型数据库的编程语言
- 定义操作所有关系型数据库的统一标准
- 对于同一个需求,每一种数据库操作的方式可能会存在一些不一样的地方,我们称为 “方言”
SQL通用语法
SQL 语句可以单行或多行书写,以分号结尾
MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写
注释
- 单行注释:-- 注释内容 或 #注释内容 (后者为 MySQL 特有)
- 多行注释:/* 注释 */
➳ 单行注释

➳ 多行注释

SQL分类
-
DDL(Data Definition Language) : 数据定义语言,用来定义数据库对象:数据库,表,列等
DDL简单理解就是用来操作数据库,表等
-
DML(Data Manipulation Language):数据操作语言,用来对数据库中表的数据进行增删改
DML简单理解就对表中数据进行增删改
-
DQL(Data Query Language):数据查询语言,用来查询数据库中表的记录(数据)
DQL简单理解就是对数据进行查询操作,从数据库表中查询到我们想要的数据。
-
DCL(Data Control Language):数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户
DML简单理解就是对数据库进行权限控制。比如我让某一个数据库表只能让某一个用户进行操作等。

五、DDL – 数据定义语言
DDL – 操作数据库
我们先来学习 DDL 操作数据库,而操作数据库主要就是对数据库的增删查操作
✓ 查询
查询所有的数据库
SHOW DATABASES;
效果如下:

上述查询到的是的这些数据库是 mysql 安装好自带的数据库,我们以后不要操作这些数据库
✓ 创建数据库
- 创建数据库:
CREATE DATABASE 数据库名称;
效果如下:

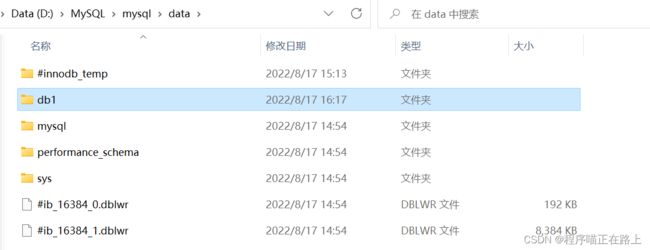
而在创建数据库的时候,有可能已经有重名的数据库存在,当我们直接再次创建名为 db1 的数据库时就会出现错误
为了避免这个错误,在创建数据库的时候我们需要先做判断,如果数据库不存在再创建
- 创建数据库(有判断,如果不存在则创建):
CREATE DATABASE IF NOT EXISTS 数据库名称;
✓ 删除数据库
- 删除数据库
DROP DATABASE 数据库名称;
- 删除数据库(判断,如果存在则删除)
DROP DATABASE IF EXISTS 数据库名称;
✓ 使用数据库
数据库创建好了,要在数据库中创建表,得先明确在哪个数据库中操作,此时就需要使用数据库
- 使用数据库
USE 数据库名称;
- 查看当前使用的数据库
SELECT DATABASE();
DDL – 操作表
操作表也就是对表进行增(Create)删(Delete)改(Update)查(Retrieve)
✓ 查询表
- 查询当前数据库下所有表名称
SHOW TABLES;
我们创建的数据库中没有任何表,因此我们进入 mysql 自带的 mysql 数据库,执行上述语句查看

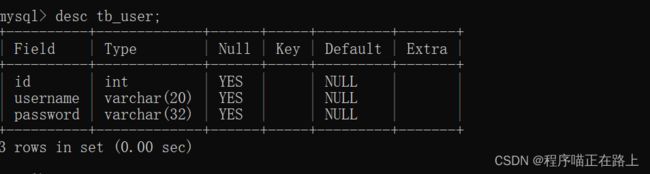
- 查询表结构
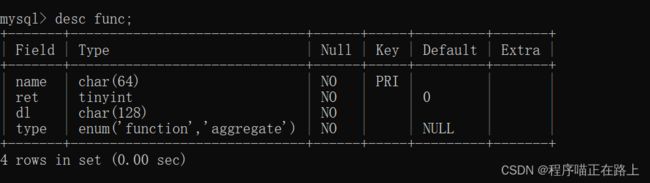
DESC 表名称;
查看 mysql 数据库中 func 表的结构,运行语句如下:
✓ 创建表
- 创建表
CREATE TABLE 表名 (
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);
注意:最后一行末尾,不能加逗号
知道了创建表的语句,我们创建如下结构的表

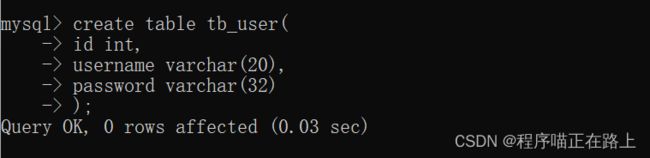
create table tb_user (
id int,
username varchar(20),
password varchar(32)
);
运行语句如下:
✓ 数据类型
MySQL 支持多种类型,可以分为三类:
-
数值
tinyint : 小整数类型,占一个字节 int : 大整数类型,占四个字节 eg : age int double : 浮点类型 使用格式: 字段名 double(总长度,小数点后保留的位数) eg : score double(5,2) -
日期
date : 日期值,只包含年月日 eg :birthday date : datetime : 混合日期和时间值。包含年月日时分秒 -
字符串
char : 定长字符串 优点:存储性能高 缺点:浪费空间 eg : name char(10) 如果存储的数据字符个数不足10个,也会占10个的空间 varchar : 变长字符串 优点:节约空间 缺点:存储性能底 eg : name varchar(10) 如果存储的数据字符个数不足10个,那就数据字符个数是几就占几个的空间

小案例:
需求:设计一张学生表,请注重数据类型、长度的合理性
1. 编号
2. 姓名,姓名最长不超过10个汉字
3. 性别,因为取值只有两种可能,因此最多一个汉字
4. 生日,取值为年月日
5. 入学成绩,小数点后保留两位
6. 邮件地址,最大长度不超过 64
7. 家庭联系电话,不一定是手机号码,可能会出现 - 等字符
8. 学生状态(用数字表示,正常、休学、毕业...)
语句设计如下:
create table student (
id int,
name varchar(10),
gender char(1),
birthday date,
score double(5,2),
email varchar(15),
tel varchar(15),
status tinyint
);
✓ 删除表
- 删除表
DROP TABLE 表名;
- 删除表时判断表是否存在
DROP TABLE IF EXISTS 表名;
✓ 修改表
- 修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
-- 将表名student修改为stu
alter table student rename to stu;
- 添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
-- 给stu表添加一列address,该字段类型是varchar(50)
alter table stu add address varchar(50);
- 修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
-- 将stu表中的address字段的类型改为 char(50)
alter table stu modify address char(50);
- 修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
-- 将stu表中的address字段名改为 addr,类型改为varchar(50)
alter table stu change address addr varchar(50);
- 删除列
ALTER TABLE 表名 DROP 列名;
-- 将stu表中的addr字段 删除
alter table stu drop addr;
六、navicat
通过前面的学习,我们不难发现,在命令行中写 sql 语句特别不方便,尤其是编写创建表的语句,我们只能在记事本上写好后直接复制到命令行进行执行
于是,navicat 出现了
navicat概述
- Navicat for MySQL 是管理和开发 MySQL 或 MariaDB 的理想解决方案
- 这套全面的前端工具为数据库管理、开发和维护提供了一款直观而强大的图形界面
- 官网: http://www.navicat.com.cn
navicat安装
点此下载相关资源
首先,双击navicat111_mysql_cs_x86.exe ,然后一路下一步,最后安装成功

接着,双击PatchNavicat.exe,在弹出来的界面中刚才选择安装目录中的 navicat.exe
默认安装目录是:
C:\Program Files (x86)\PremiumSoft\Navicat for MySQL
如果你没改路径,可以复制上面的路径直接查找
最后,激活完成
navicat使用
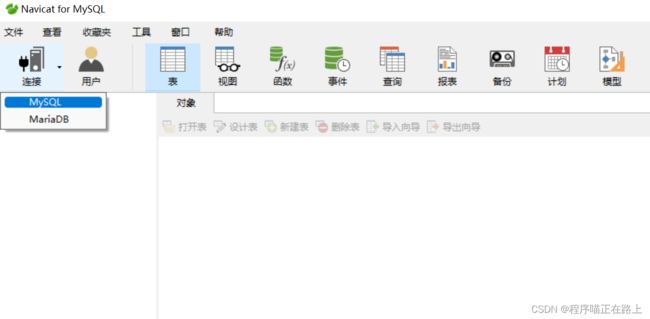
✓ 建立和mysql服务的连接
第一步: 点击连接,选择 MySQL
第二步:填写连接数据库必要的信息
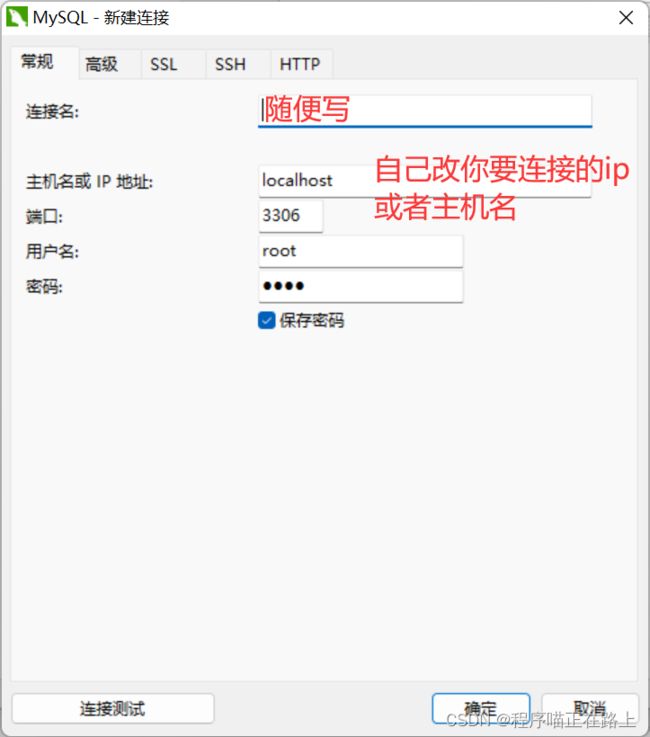
第三步,点击连接测试,连接成功即可

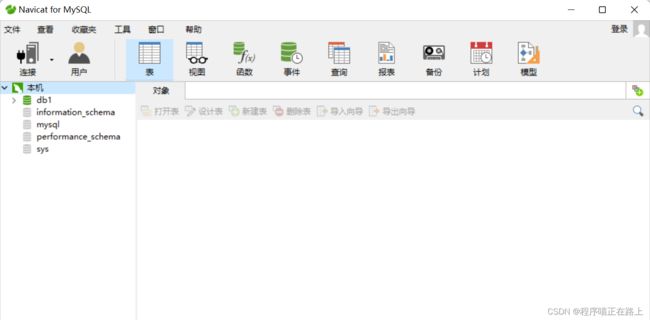
✓ 操作
连接成功后就能看到如下界面:
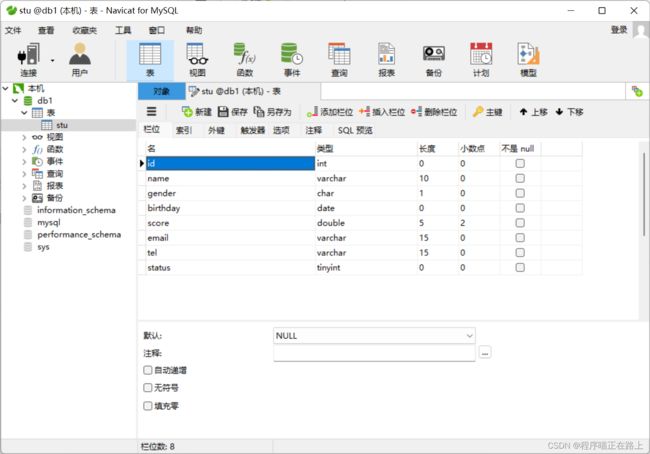
- 修改表结构
通过下图操作修改表结构:

点击了设计表后即出现如下图所示界面,在图中红框中直接修改字段名,类型等信息:
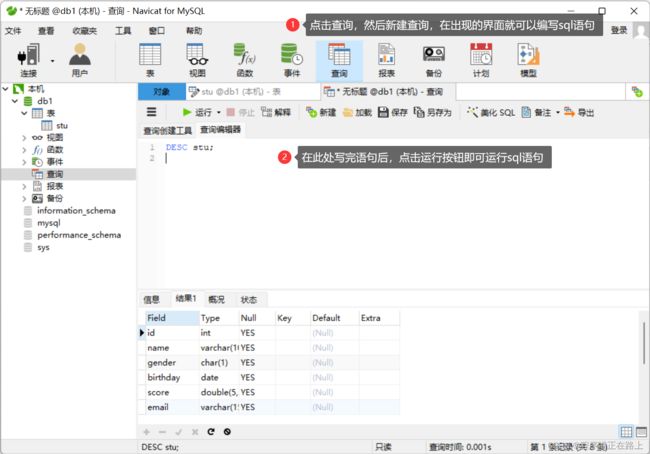
- 编写SQL语句并执行
按照如下图所示进行操作即可书写并执行 sql 语句
七、DML – 数据操作语言
DML 主要是对数据进行增(insert)删(delete)改(update)操作。
添加数据
- 给指定列添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);
- 给全部列添加数据
INSERT INTO 表名 VALUES(值1,值2,…);
- 批量添加数据
INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
INSERT INTO 表名 VALUES(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
- 练习

点击美化 SQL 可以优化代码格式
-- 查询所有语句,最后单独执行,才能看到添加的效果
SELECT
*
FROM
stu;
-- 给指定列添加数据 INSERT INTO 表名(列名1,列名2,…) VALUES(值1,值2,…);
INSERT INTO stu (id, NAME)
VALUES
(1, '张三');
-- 给所有列添加数据 INSERT INTO 表名 VALUES(值1,值2,…);
INSERT INTO stu (
id,
NAME,
gender,
birthday,
score,
email,
tel,
STATUS
)
VALUES
(
2,
'李四',
'男',
'1999-1-1',
66.6,
'[email protected]',
'1234567890',
1
);
-- 列名可省略不写,但不建议省略
-- 批量添加数据
INSERT INTO stu
VALUES
(
2,
'李四',
'男',
'1999-1-1',
66.6,
'[email protected]',
'1234567890',
1
),
(
2,
'李四',
'男',
'1999-1-1',
66.6,
'[email protected]',
'1234567890',
1
),
(
2,
'李四',
'男',
'1999-1-1',
66.6,
'[email protected]',
'1234567890',
1
);
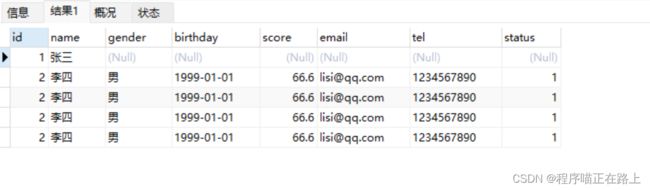
修改数据
- 修改表数据
UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件] ;
注意:
- 修改语句中如果不加条件,则将所有数据都修改!
- 像上面的语句中的中括号,表示在写sql语句中可以省略这部分
-
练习
-
将张三的性别改为女
update stu set sex = '女' where name = '张三'; -
将张三的生日改为 1999-12-12,分数改为 99.99
update stu set birthday = '1999-12-12', score = 99.99 where name = '张三';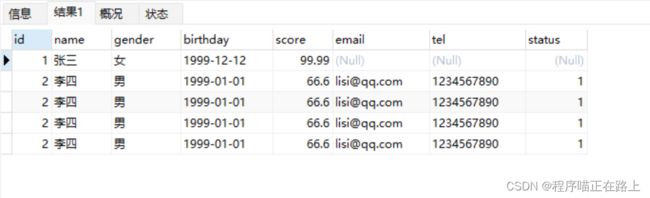
-
注意:如果 update 语句没有加 where 条件,则会将表中所有数据全部修改!
update stu set sex = '女';
-
完整代码:
SELECT
*
FROM
stu;
-- 修改数据 UPDATE 表名 SET 列名1=值1,列名2=值2,… [WHERE 条件] ;
-- 将张三的性别改为女
UPDATE stu
SET gender = '女'
WHERE
NAME = '张三';
-- 将张三的生日改为 1999-12-12,分数改为 99.99
UPDATE stu
SET birthday = '1999-12-12',
score = 99.99
WHERE
NAME = '张三';
-- 注意:如果 **update** 语句没有加 **where** 条件,则会将表中所有数据全部修改!
UPDATE stu
SET gender = '女';
删除数据
- 删除数据
DELETE FROM 表名 [WHERE 条件] ;
- 练习
-- 删除张三记录
delete from stu where name = '张三';
-- 删除stu表中所有的数据
delete from stu;

八、DQL – 数据查询语言
数据库查询操作是最常用的操作,也是最重要的操作,所以这部分需要重点掌握
接下来我们先介绍查询的完整语法:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组后条件
ORDER BY
排序字段
LIMIT
分页限定
- 基础查询
- 条件查询(WHERE)
- 分组查询(GROUP BY)
- 排序查询(ORDER BY)
- 分页查询(LIMIT)
为了演示查询的语句,我们需要先准备表及一些数据:
-- 删除stu表
drop table if exists stu;
-- 创建stu表
CREATE TABLE stu (
id int, -- 编号
name varchar(20), -- 姓名
age int, -- 年龄
sex varchar(5), -- 性别
address varchar(100), -- 地址
math double(5,2), -- 数学成绩
english double(5,2), -- 英语成绩
hire_date date -- 入学时间
);
-- 添加数据
INSERT INTO stu(id,NAME,age,sex,address,math,english,hire_date)
VALUES
(1,'马运',55,'男','杭州',66,78,'1995-09-01'),
(2,'马花疼',45,'女','深圳',98,87,'1998-09-01'),
(3,'马斯克',55,'男','香港',56,77,'1999-09-02'),
(4,'柳白',20,'女','湖南',76,65,'1997-09-05'),
(5,'柳青',20,'男','湖南',86,NULL,'1998-09-01'),
(6,'刘德花',57,'男','香港',99,99,'1998-09-01'),
(7,'张学右',22,'女','香港',99,99,'1998-09-01'),
(8,'德玛西亚',18,'男','南京',56,65,'1994-09-02');
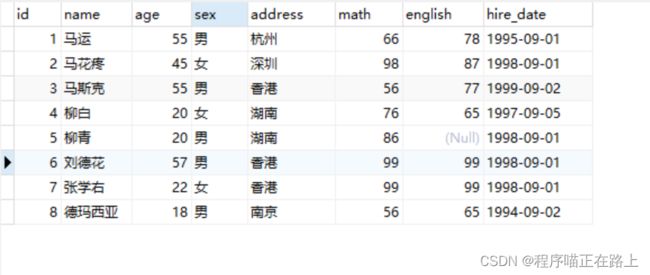
基础查询
1 - 语法
- 查询多个字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名; -- 查询所有数据
- 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
- 起别名
AS: AS 也可以省略
2 - 练习
-
查询 name、age 两列
select name,age from stu;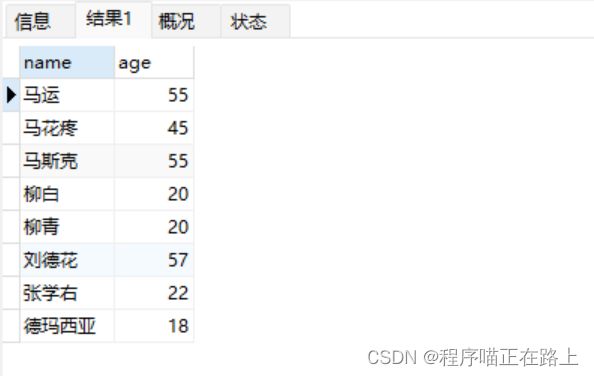
-
查询所有列的数据,列名的列表可以使用 * 替代
select * from stu;上面语句中的 * 不建议大家使用,因为在这写 * 不方便我们阅读 sql 语句。我们写字段列表的话,可以添加注释对每一个字段进行说明

-
查询地址信息
select address from stu;执行上面语句结果如下:
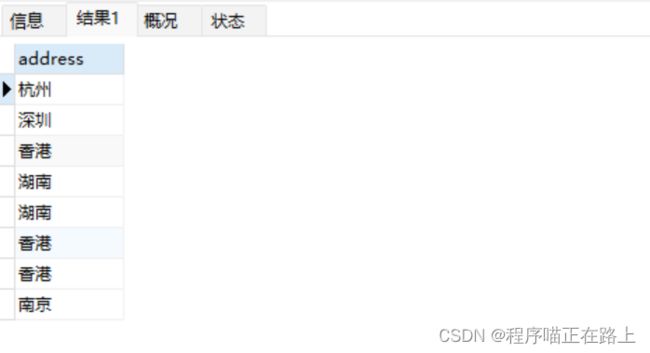
从上面的结果我们可以看到有重复的数据,我们可以使用
distinct关键字去重 -
去除重复记录
select distinct address from stu;
-
查询姓名、数学成绩、英语成绩。并通过 as 给 math 和 english 起别名(as 关键字可以省略)
select name,math as 数学成绩,english as 英文成绩 from stu; select name,math 数学成绩,english 英文成绩 from stu; ```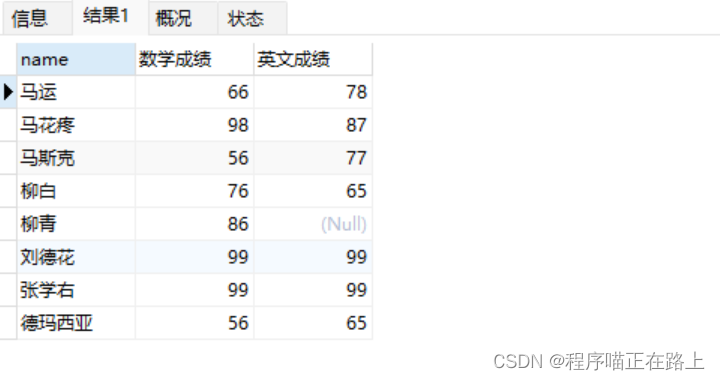
条件查询
1 - 语法
SELECT 字段列表 FROM 表名 WHERE 条件列表;
- 条件
条件列表可以使用以下运算符
| 符号 | 功能 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN…AND… | 在某个范围之内(都包含) |
| IN(…) | 多选一 |
| LIKE 占位符 | 模糊查询 _单个任意字符 %多个任意字符 |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| AND 或 && | 并且 |
| OR 或 | | | 或者 |
| NOT 或 ! | 非,不是 |
2 - 条件查询练习
-
查询年龄大于 20 岁的学员信息
select * from stu where age > 20;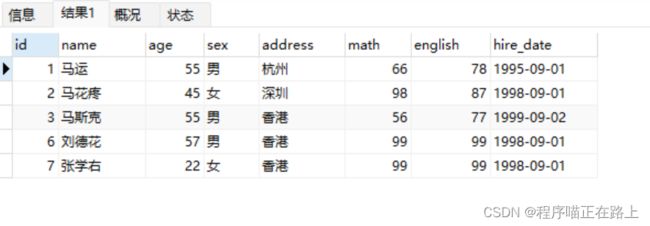
-
查询年龄大于等于 20 岁,并且年龄小于等于 30 岁 的学员信息
select * from stu where age >= 20 && age <= 30; select * from stu where age >= 20 and age <= 30;上面语句中 && 和 and 都表示并且的意思。建议使用 and
也可以使用 between … and 来实现上面需求select * from stu where age BETWEEN 20 and 30;
-
查询入学日期在 ‘1998-09-01’ 到 ‘1999-09-01’ 之间的学员信息
select * from stu where hire_date BETWEEN '1998-09-01' and '1999-09-01';
-
查询年龄不等于 18 岁的学员信息
select * from stu where age != 18; select * from stu where age <> 18;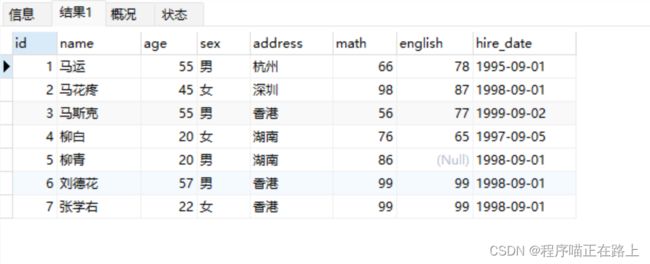
-
查询年龄等于 18 岁或者年龄等于 20 岁 或者年龄等于 22 岁的学员信息
select * from stu where age = 18 or age = 20 or age = 22; select * from stu where age in (18,20,22);
-
查询英语成绩为 null 的学员信息
null 值的比较不能使用 = 或者 != ,需要使用 is 或者 is not
select * from stu where english is null; select * from stu where english is not null;
3 - 模糊查询练习
模糊查询使用 like 关键字,可以使用通配符进行占位:
(1)_ : 代表单个任意字符
(2)% : 代表任意个数字符
-
查询姓 ‘马’ 的学员信息
select * from stu where name like '马%';
-
查询第二个字是 ‘花’ 的学员信息
select * from stu where name like '_花%';
-
查询名字中包含 ‘德’ 的学员信息
select * from stu where name like '%德%';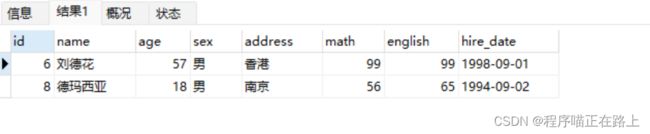
排序查询
1 - 语法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
上述语句中的排序方式有两种,分别是:
- ASC : 升序排列 (默认值)
- DESC : 降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
2 - 练习
-
查询学生信息,按照年龄升序排列
select * from stu order by age;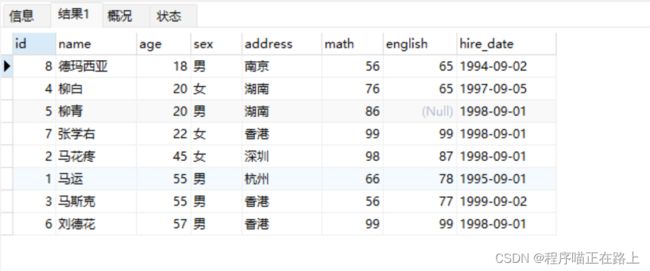
-
查询学生信息,按照数学成绩降序排列
select * from stu order by math desc;
-
查询学生信息,按照数学成绩降序排列,如果数学成绩一样,再按照英语成绩升序排列
select * from stu order by math desc, english asc;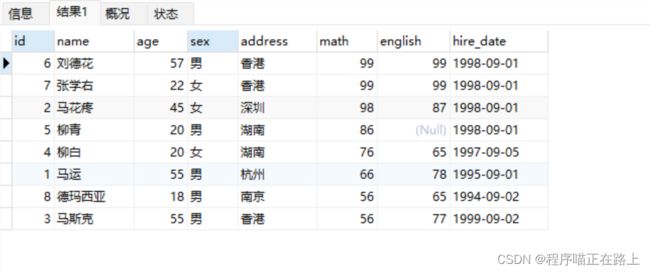
聚合函数
1 - 概念
将一列数据作为一个整体,进行纵向计算
我知道你可能云里雾里,假设有下表

现有一需求:让我们求表中所有数据的数学成绩的总和,这就是对 math 字段进行纵向求和
2 - 聚合函数分类
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为 null 的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
3 - 聚合函数语法
SELECT 聚合函数名(列名) FROM 表;
注意:null 值不参与所有聚合函数运算
4 - 练习
-
统计班级一共有多少个学生
select count(id) from stu; select count(english) from stu;上面语句根据某个字段进行统计,如果该字段某一行的值为 null 的话,将不会被统计,所以可以用 count(*) 来实现。* 表示所有字段数据,一行中也不可能所有的数据都为 null,所以建议使用 count(*)
select count(*) from stu;
-
查询数学成绩的最高分
select max(math) from stu;
-
查询数学成绩的总分
select sum(math) from stu;
-
查询数学成绩的平均分
select avg(math) from stu;
分组查询
1 - 语法
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
2 - 练习
-
查询男同学和女同学各自的数学平均分
select sex, avg(math) from stu group by sex;
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
select name, sex, avg(math) from stu group by sex; -- 这里查询name字段就没有任何意义 -
查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math),count(*) from stu group by sex;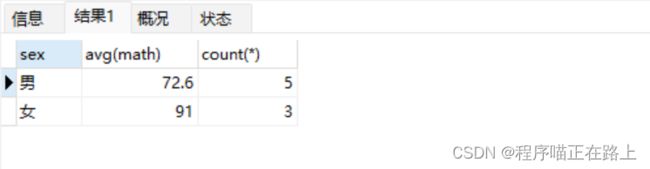
-
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于 70 分的不参与分组
select sex, avg(math), count(*) from stu where math > 70 group by sex;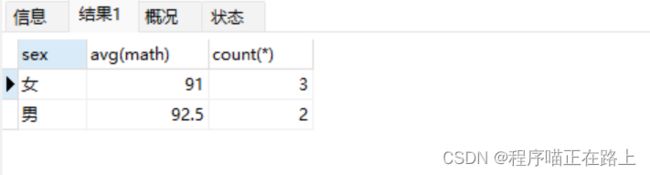
-
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于 70 分的不参与分组,分组之后人数大于 2 个的
select sex, avg(math), count(*) from stu where math > 70 group by sex having count(*) > 2;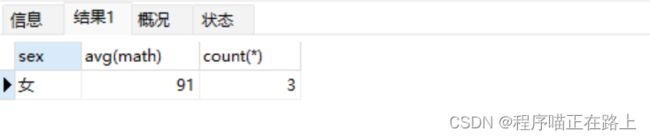
where 和 having 区别: -
执行时机不一样:where 是分组之前进行限定,不满足 where 条件,则不参与分组,而 having 是分组之后对结果进行过滤
-
可判断的条件不一样:where 不能对聚合函数进行判断,having 可以
分页查询
如下图所示,大家在很多网站都见过类似的效果,如京东、百度、淘宝等。分页查询是将数据一页一页的展示给用户看,用户也可以通过点击查看下一页的数据

接下来我们先说分页查询的语法
1 - 语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询条目数;
注意: 上述语句中的起始索引是从 0 开始
2 - 练习
-
从 0 开始查询,查询 3 条数据
select * from stu limit 0, 3;
-
每页显示 3 条数据,查询第 1 页数据
select * from stu limit 0, 3; -
每页显示 3 条数据,查询第 2 页数据
select * from stu limit 3, 3;
-
每页显示 3 条数据,查询第 3 页数据
select * from stu limit 6, 3;
从上面的练习推导出起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数
这次的分享就到这里啦,继续加油哦^^
我是程序喵,陪你一点点进步
有出错的地方欢迎在评论区指出来,共同进步,谢谢啦