概览文章中提到了k8s的鉴权模式,简单回顾下:
- RBAC: Role-based access control 是基于角色的访问控制
- ABAC: Atrribute-based access control 是基于属性的访问控制
- Node Authorization: 节点鉴权,专门用于kubelet发出的api请求进行鉴权
- Webhook Authorization: webhook是一种http回调,kube-apiserver配置webhook时, 会设置回调webhook的规则,这些规则中包含了调用的api
group、version、operation、scope等信息。
有细心的小伙伴指出,RBAC的角色可以作为ABAC的属性来配置。 感谢小伙伴指正,ABAC可以更细粒度的控制权限,相应配置起来也更复杂。
kubernetes 鉴权
选定RBAC模式后,关于角色,有Role和ClusterRole,对应对象的绑定分别为: RoleBinding 和 ClusterRoleBinding。
Role创建后归属于特定的namespace,一般与特定namespace的权限绑定,而ClusterRole 不属于任何namespace,通常与一组权限绑定。
ClusterRole通常用于
- 定义指定namespace资源的访问权限,并在某个namespace范围内授予访问权限;
- 定义指定namespace资源的访问权限,并在跨namespace范围内授予访问权限;
- 定义集群范围内的资源访问权限。
官方文档推荐,如果在单个namespace内定义角色则使用Role,如果是定义集群范围的角色,则使用ClusterRole。
要监控kubernetes组件和集群范围内业务以及为了通用性,所以我们选择ClusterRole 和 ClusterRoleBinding。
权限盘点
我们来盘点需要监控的对象。
- 组件监控,访问组件metrics接口,需要非资源对象的
get/list权限。访问/api/v1/xxx /apis/都属于非资源对象请求。/ /xxx - node、pod对象的资源监控, 需要访问kubelet metrics接口,权限同上。
- serverless场景下,如果不能直接访问kubelet,还需要
node/proxy的get权限。 - node、pod对象的数量监控, 需要资源对象的
get/list权限。 - 自动发现, 需要service、endpoint的
get/list+watch权限。 - 如果要从metrics server 拿数据,还需要metrics.k8s.io 的访问权限。
不论需要多少权限, 一个原则就是按需申请,最小化申请。 指标采集都是读权限,基本都是get、list。自动发现要达到发现及时,需要watch endpoints变化。
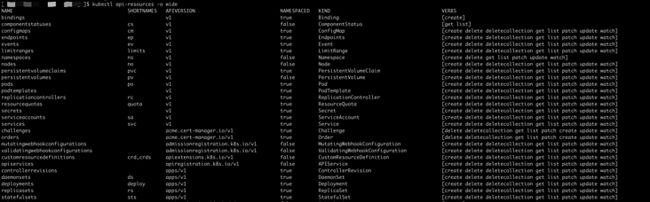
如何确定资源对象的api groups和version呢? 可以使用 kubectl api-resources -o wide 来查看。 新版本的APIVERSION包含了api groups和version信息。
权限配置
基本的权限配置如下
- apiGroups: [""]
resources:
- pods
- nodes
- nodes/stats
- nodes/metrics
- nodes/proxy
- services
- endpoints
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]将权限填充到ClusterRole中
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations: {}
labels:
app: n9e
component: categraf
name: categraf-role
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/stats
- nodes/metrics
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]有了ClusterRole, 创建ClusterRoleBinding之前,还需要一个ServiceAccount,用于存储api的访问凭据,这个凭据可以以token形式挂载到Pod内。
也可以直接解析用于Pod外部使用。
apiVersion: v1
kind: ServiceAccount
metadata:
annotations: {}
labels:
app: n9e
component: categraf
name: categraf-serviceaccount
namespace: ${NAMESPACE}注意,ServiceAccount需要指定namespace,需要跟categraf即将部署的namespace保持一致。
利用ClusterRoleBinding 将ClusterRole和ServiceAccount关联起来
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations: {}
labels:
app: n9e
component: categraf
name: categraf-rolebinding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: categraf-role
subjects:
- kind: ServiceAccount
name: categraf-serviceaccount
namespace: ${NAMESPACE}现在ClusterRoleBinding 已经将权限和票据关联起来了。
备注:创建完成后,ServiceAccount会自动创建一个secret,这个secret 会自动挂载到后续创建的categraf pod内。
可以通过 kubectl get secrets -n monitoring categraf-serviceaccount-token-frqc5 -o jsonpath={.data.token} | base64 -d
获得token内容,这样通过curl -s -k -H "Authorization: Bearer $TOKEN" 即可访问apiserver,用来调试。
kubernetes 组件的服务发现
1. 监控对象部署在pod内
当创建service(带选择符)时,k8s会自动为pod创建endpoint,这样service和pod就关联起来了。利用这个特性,我们可以及时发现pod的变化。
如果组件是部署在pod内,我们就可以直接利用这个特性进行采集。比如kubeadm部署的集群,apiserver 本身就已经创建了对应的service。
...
- job_name: "apiserver"
metrics_path: "/metrics"
kubernetes_sd_configs:
- role: endpoints # 看这里
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
...2. 监控对象部署在物理机 (文件服务发现)
如果组件是以二进制方式部署在物理机,又没有其他服务发现的手段。那可以利用prometheus类似的文件服务发现,当组件有变更时,直接在目录中添加删除包含目标信息的文件就好了。
这里多提一点,之前有小伙伴提出,categraf提供一个注册接口,服务向categraf注册,然后categraf去拉注册目标指标。categraf本身的定位是一个采集器,没有服务发现的功能。
提一个最简单的问题,如果categraf挂了重启,但是采集目标没有发现,这里就会有很多数据不能被采集了。再有就是集中式拉取方式,提供push接口,会把业务和采集器耦合更深了。
这种方式 并不可取。
....
- job_name: 'coredns'
file_sd_configs:
- files:
- /home/work/prometheus/file_sd_config/*.json
...在file_sd_config目录下放一个json文件,如下:
[
{
"labels": {
"job": "coredns"
},
"targets": [
"172.16.6.160:9153"
]
}
]等增加新的coredns后,只需要再增加一份json配置(这里只是为了举例说明,直接修改coredns.json效果一样)。不需要再做任何其他操作
[
{
"labels": {
"job": "coredns"
},
"targets": [
"172.16.0.85:9153"
]
}
]3. 其他服务发现方式
采集器categraf集成了prometheus的agent mode模式, 如果你使用了其他服务发现方式, 例如consul,则可以和categraf无缝对接了。
除此之外,还支持docker_swarm_sd_configs,docker_sd_config, dns_sd_configs, http_sd_configs等prometheus所支持的服务发现方式。
本次主要介绍kubernete权限和服务自动发现。感谢大家持续关注,欢迎各位批评指正, 欢迎各位点赞 转发和收藏。
关于作者
本文作者是孔飞,来自快猫星云( https://flashcat.cloud )是Kubernetes和Prometheus专家,快猫团队致力于让监控更简单,为企业提供稳定性保障的产品,也提供夜莺监控的技术支持服务,性价比极高,有兴趣的小伙伴欢迎联系我们
关于夜莺监控
夜莺监控是一款开源云原生监控分析系统,姑且可以看做是 Prometheus 的企业级版本。Kubernetes 监控系列文章都是基于夜莺监控来梳理,欢迎关注
更多文章
更多云原生监控相关文章、教程,欢迎关注我们:

本文由mdnice多平台发布