【机器学习】聚类【Ⅱ】原型聚类经典算法
主要来自周志华《机器学习》一书,数学推导主要来自简书博主“形式运算”的原创博客,包含自己的理解。
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
由于字数限制,分成五篇博客。
【机器学习】聚类【Ⅰ】基础知识与距离度量
【机器学习】聚类【Ⅱ】原型聚类经典算法
【机器学习】聚类【Ⅲ】高斯混合模型讲解
【机器学习】聚类【Ⅳ】高斯混合模型数学推导
【机器学习】聚类【Ⅴ】密度聚类与层次聚类
4 原型聚类
原型聚类亦称“基于原型的聚类”(prototype-based clustering),“原型”是指样本空间中具有代表性的点,此类算法假设聚类结构能通过一组原型刻画,在现实聚类任务中极为常用。通常情形下,算法先对原型进行初始化,然后对原型进行迭代更新求解。采用不同的原型表示、不同的求解方式,将产生不同的算法。
原型聚类强调两点,“原型”和“迭代”。“原型”思想是指用具有代表性的点表示簇,“迭代”思想是指在原型聚类中往往很难找到最优解,所以会通过迭代的方式找到最佳近似解。
4.1 k k k 均值算法
给定样本集 D = { x 1 , x 2 , ⋅ ⋅ ⋅ , x m } D =\{\pmb x_1, \pmb x_2,··· , \pmb x_m\} D={xx1,xx2,⋅⋅⋅,xxm},“ k k k 均值”(k-means)算法针对聚类所得簇划分 C = { C 1 , C 2 , ⋅ ⋅ ⋅ , C k } \mathcal{C}= \{C_1,C_2,··· ,C_k\} C={C1,C2,⋅⋅⋅,Ck} 最小化平方误差
E = ∑ i = 1 k ∑ x ∈ C i ∥ x − μ i ∥ 2 2 (27) E=\sum_{i=1}^k\sum_{\pmb x∈C_i}\Vert \pmb x-\pmb \mu_i \Vert_2^2 \tag{27} E=i=1∑kxx∈Ci∑∥xx−μμi∥22(27)
其中 μ i = 1 ∣ C i ∣ ∑ ∈ C i \pmb {\mu}_i=\frac{1}{|C_i|}\sum_{\pmb ∈C_i} μμi=∣Ci∣1∑∈∈Ci 是簇 C i C_i Ci 的均值向量。直观来看,式 ( 27 ) (27) (27) 在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度, E E E 值越小则簇内样本相似度越高。
最小化式 ( 27 ) (27) (27) 并不容易,找到它的最优解需考察样本集 D D D 所有可能的簇划分,这是一个 NP 难问题,也就是说最小化式 ( 27 ) (27) (27) 只是无法达成的理想目标。因此, k k k 均值算法采用了贪心策略,通过迭代优化来近似求解式 ( 27 ) (27) (27) 。算法流程如算法 1 1 1 所示,其中第 1 1 1 行对均值向量进行初始化,在第 4 4 4 - 8 8 8 行与第 9 9 9 - 16 16 16 行依次对当前簇划分及均值向量迭代更新,若迭代更新后聚类结果保持不变,则在第 18 18 18 行将当前簇划分结果返回。
输入: 样本集 D = { x 1 , x 2 , ⋅ ⋅ ⋅ , x m } ; 聚类簇数 k . 过程: \begin{array}{ll} \textbf{输入:}&\space样本集\space D = \{\pmb x_1,\pmb x_2,···,\pmb x_m\}\space ;&&&&&&&&&&&&&&&&&&\\ &\space 聚类簇数\space k\space.\\ \textbf{过程:} \end{array} 输入:过程: 样本集 D={xx1,xx2,⋅⋅⋅,xxm} ; 聚类簇数 k .
1 : 从 D 中随机选择 k 个样本作为初始均值向量 { μ 1 , μ 2 , ⋅ ⋅ ⋅ , μ k } 2 : repeat 3 : 令 C i = ∅ ( 1 ≤ i ≤ k ) 4 : for j = 1 , 2 , ⋅ ⋅ ⋅ , m do 5 : 计算样本 x j 与各均值向量 μ i ( 1 ≤ i ≤ k ) 的距离 : d j i = ∥ x j − μ i ∥ 2 ; 6 : 根据距离最近的均值向量确定 x j 的簇标记 : λ j = a r g m a x i ∈ { 1 , 2 , ⋅ ⋅ ⋅ , k } d j i ; 7 : 将样本 x j 划入相应的簇 : C λ j = C λ j ⋃ { x j } ; 8 : end for 9 : for i = 1 , 2 , ⋅ ⋅ ⋅ , k do 10 : 计算新均值向量 : μ i ′ = 1 ∣ C i ∣ ∑ x ∈ C i x ; 11 : if μ i ′ ≠ μ i then 12 : 将当前均值向量 μ i 更新为 μ i ′ 13 : else 14 : 保持当前均值向量不变 15 : end if 16 : end for 17 : until 当前均值向量均未更新 \begin{array}{rl} 1:&从\space D\space 中随机选择\space k\space个样本作为初始均值向量\space \{\pmb \mu_1,\pmb \mu_2,···,\pmb \mu_k\}\\ % 2:&\textbf{repeat}\\ % 3:&\space\space\space\space 令\space C_i=\varnothing\space(1\le i\le k)\\ % 4:&\space\space\space\space \textbf{for}\space j=1,2,···,m \space \textbf{do}\\ % 5:&\space\space\space\space\space\space\space\space 计算样本\space\pmb x_j \space与各均值向量 \space \pmb \mu_i\space(1\le i\le k)\space的距离:d_{ji}=\Vert \pmb x_j-\pmb\mu_i \Vert_2\space;\\ % 6:&\space\space \space\space\space\space \space\space 根据距离最近的均值向量确定\space\pmb x_j\space 的簇标记:\lambda_j={\rm arg}\space {\rm max}_{i∈\{1,2,···,k\}}d_{ji} \space;\\ % 7:&\space\space \space\space\space\space \space\space 将样本\space\pmb x_j\space 划入相应的簇:C_{\lambda_j}=C_{\lambda_j}\bigcup \{\pmb x_j\} \space; \\ % 8:&\space\space \space\space \textbf{end}\space \textbf{for}\\ % 9:&\space\space\space\space \textbf{for}\space i=1,2,···,k \space \textbf{do}\\ % 10:&\space\space \space\space\space\space \space\space 计算新均值向量:\pmb \mu_i'=\frac{1}{|C_i|}\sum_{\pmb x∈C_i} \pmb x \space;\\ % 11:&\space\space\space\space\space\space \space\space \textbf{if}\space \pmb \mu_i'\ne\pmb \mu_i\space \textbf{then}\\ % 12:&\space\space\space\space\space\space\space\space\space\space\space\space 将当前均值向量\space\pmb\mu_i\space更新为\space \pmb \mu_i'\\ % 13:&\space\space\space\space\space\space\space\space\textbf{else} \\ % 14:&\space\space\space\space\space\space\space\space\space\space\space\space保持当前均值向量不变 \\ % 15:&\space\space\space\space\space\space\space\space \textbf{end}\space \textbf{if}\\ % 16:&\space\space\space\space\textbf{end}\space \textbf{for}\\ % 17:& \textbf{until}\space 当前均值向量均未更新\\ \end{array} 1:2:3:4:5:6:7:8:9:10:11:12:13:14:15:16:17:从 D 中随机选择 k 个样本作为初始均值向量 {μμ1,μμ2,⋅⋅⋅,μμk}repeat 令 Ci=∅ (1≤i≤k) for j=1,2,⋅⋅⋅,m do 计算样本 xxj 与各均值向量 μμi (1≤i≤k) 的距离:dji=∥xxj−μμi∥2 ; 根据距离最近的均值向量确定 xxj 的簇标记:λj=arg maxi∈{1,2,⋅⋅⋅,k}dji ; 将样本 xxj 划入相应的簇:Cλj=Cλj⋃{xxj} ; end for for i=1,2,⋅⋅⋅,k do 计算新均值向量:μμi′=∣Ci∣1∑xx∈Cixx ; if μμi′=μμi then 将当前均值向量 μμi 更新为 μμi′ else 保持当前均值向量不变 end if end foruntil 当前均值向量均未更新
输出: 簇划分 C = { C 1 , C 2 , ⋅ ⋅ ⋅ , C k } \begin{array}{l} \textbf{输出:}\space 簇划分\space \mathcal{C}=\{C_1,C_2,···,C_k\} &&&&&&&&&&&&&&&&&&&& \end{array} 输出: 簇划分 C={C1,C2,⋅⋅⋅,Ck}
算法 1 k 均值算法
为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若达到最大轮数或调整幅度小于阈值,则停止运行。
算法基本思路为,将每个样本分到距离最近的均值向量所代表的簇中,用簇内全部样本的均值作为新的均值向量不断迭代,直到向量均值不再改变或满足算法停止的其他条件。
注意:原型并不一定是均值向量,均值向量只是原型的一种表示方式,也就是说,我们可以选择用均值向量作为簇的原型,也可以选择其他方式。
下面以表 1 1 1 的西瓜数据集为例来演示 k k k 均值算法的学习过程。为方便叙述,我们将编号为 i i i 的样本称为 x i \pmb x_i xxi,这是一个包含“密度”与“含糖率”两个属性值的二维向量。
| 编号 | 密度 | 含糖率 | 编号 | 密度 | 含糖率 | 编号 | 密度 | 含糖率 |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.697 | 0.460 | 11 | 0.245 | 0.057 | 21 | 0.748 | 0.232 |
| 2 | 0.774 | 0.376 | 12 | 0.343 | 0.099 | 22 | 0.714 | 0.346 |
| 3 | 0.634 | 0.264 | 13 | 0.639 | 0.161 | 23 | 0.483 | 0.312 |
| 4 | 0.608 | 0.318 | 14 | 0.657 | 0.198 | 24 | 0.478 | 0.437 |
| 5 | 0.556 | 0.215 | 15 | 0.360 | 0.370 | 25 | 0.525 | 0.369 |
| 6 | 0.403 | 0.237 | 16 | 0.593 | 0.042 | 26 | 0.751 | 0.489 |
| 7 | 0.481 | 0.149 | 17 | 0.719 | 0.103 | 27 | 0.532 | 0.472 |
| 8 | 0.437 | 0.211 | 18 | 0.359 | 0.188 | 28 | 0.473 | 0.376 |
| 9 | 0.666 | 0.091 | 19 | 0.339 | 0.241 | 29 | 0.725 | 0.445 |
| 10 | 0.243 | 0.267 | 20 | 0.282 | 0.257 | 30 | 0.446 | 0.459 |
表 1 西瓜数据集
假定聚类簇数 k = 3 k =3 k=3,算法开始时随机选取三个样本 x 6 , x 12 , x 27 \pmb x_6,\pmb x_{12},\pmb x_{27} xx6,xx12,xx27 作为初始均值向量,即
μ 1 = ( 0.403 ; 0.237 ) , μ 2 = ( 0.343 ; 0.099 ) , μ 3 = ( 0.532 ; 0.472 ) \pmb \mu_1=(0.403;0.237),\space \pmb \mu_2=(0.343;0.099),\space\pmb \mu_3=(0.532;0.472) μμ1=(0.403;0.237), μμ2=(0.343;0.099), μμ3=(0.532;0.472)
考察样本 x 1 = ( 0.697 ; 0.460 ) \pmb x_1= (0.697;0.460) xx1=(0.697;0.460),它与当前均值向量 μ 1 , μ 2 , μ 3 \pmb\mu_1, \pmb \mu_2, \pmb \mu_3 μμ1,μμ2,μμ3 的距离分别为 0.369 , 0.506 , 0.166 0.369,0.506,0.166 0.369,0.506,0.166,因此 x 1 x_1 x1 将被划入簇 C 3 C_3 C3 中。类似的,对数据集中的所有样本考察一遍后,可得当前簇划分为
C 1 = { x 5 , x 6 , x 7 , x 8 , x 9 , x 10 , x 13 , x 14 , x 15 , x 17 , x 18 , x 19 , x 20 , x 23 } C 2 = { x 11 , x 12 , x 16 } C 3 = { x 1 , x 2 , x 3 , x 4 , x 21 , x 22 , x 24 , x 25 , x 26 , x 27 , x 28 , x 29 , x 30 } \begin{align} C_1&=\{ x_{5},x_{6},x_{7},x_{8},x_{9},x_{10},x_{13},x_{14},x_{15},x_{17},x_{18},x_{19},x_{20},x_{23} \} \notag{} \\ C_2&=\{ x_{11},x_{12},x_{16} \} \notag{} \\ C_3&=\{x_{1},x_{2},x_{3},x_{4},x_{21},x_{22},x_{24},x_{25},x_{26},x_{27},x_{28},x_{29},x_{30} \} \notag{} \\ \end{align} C1C2C3={x5,x6,x7,x8,x9,x10,x13,x14,x15,x17,x18,x19,x20,x23}={x11,x12,x16}={x1,x2,x3,x4,x21,x22,x24,x25,x26,x27,x28,x29,x30}
于是,可从 C 1 C_1 C1、 C 2 C_2 C2、 C 3 C_3 C3 分别求出新的均值向量
μ 1 ′ = ( 0.473 ; 0.214 ) , μ 2 ′ ( 0.394 ; 0.066 ) , μ 3 ′ = ( 0.623 ; 0.388 ) \pmb \mu_1'=(0.473;0.214),\space \pmb \mu_2'(0.394;0.066),\space \pmb \mu_3'=(0.623;0.388) μμ1′=(0.473;0.214), μμ2′(0.394;0.066), μμ3′=(0.623;0.388)
更新当前均值向量后,不断重复上述过程,如图 2 2 2 所示,第五轮迭代产生的结果与第四轮迭代相同,于是算法停止,得到最终的簇划分。

图 2 西瓜数据集上 k 均值算法(k=3)在各轮迭代后的结果。样本点与均值向量分别用“●”与“+”表示,红色虚线显示出簇划分。
优点:
- 解决聚类问题的一种经典算法,简单、快速;
- 对处理大数据集,该算法是相对可伸缩和高效率的;
- 当结果簇密集时效果较好。
缺点:
- 必须事先给出 k k k(要生成的簇数),而且对初值敏感,对于不同的初始值,可能会导致不同结果;
- 不适合于发现非凸面形状的簇或者大小差别很大的簇。而且,它对于“噪声”和孤立点数据是敏感的。
4.2 k k k-modes 算法
k k k-means 算法是一种简单且实用的聚类算法,但是传统的 k k k-means 算法只适用于数值型属性的数据集,而对于类别型属性的数据集,计算簇的均值以及点之间的欧式距离就变得不合适了。 k k k-modes 作为 k k k-means 的一种扩展,适用于类别型属性的数据集。
数值型属性和类别型属性分别是前面提到的有序属性和无序属性。
由于 k k k-modes 算法与 k k k-means 算法流程一致,唯一的不同在于 k k k-modes 算法使用类别型样本距离的度量方法和更新原型的方法。算法采用”汉明距离“(hamming distance)度量样本距离,汉明距离常用于数据传输差错控制编码中,这里拓展其概念和用途。类别型样本间的汉明距离定义为
d i s t h m ( x i , x j ) = ∑ u = 1 n δ ( x i u , x j u ) (28) {\rm dist_{hm}}(\pmb x_i,\pmb x_j)=\sum_{u=1}^n\delta (x_{iu}, x_{ju})\tag{28} disthm(xxi,xxj)=u=1∑nδ(xiu,xju)(28)
其中, δ ( a , b ) \delta(a,b) δ(a,b) 定义为
δ ( a , b ) = { 1 , a = b 0 , a ≠ b (29) \delta(a,b)= \left\{ \begin{array}{ll} 1,&a=b\\ 0,&a\ne b \end{array} \right. \tag{29} δ(a,b)={1,0,a=ba=b(29)
观察上式可知,两个样本的汉明距离可以理解为,对应属性不同取值的个数和。
在更新原型时,选择每个族中每个属性出现频率最大的属性作为簇的代表属性。
4.3 k k k-prototype 算法
k k k-prototype 算法是处理混合属性聚类的典型算法。继承 k k k-means 算法和 k k k-modes 算法的思想,并且加入了描述数据簇的原型和混合属性数据之间的相异度计算公式。混合属性是指既包括数值型属性又包括类别型属性。
给定样本集 D = { x 1 , x 2 , ⋅ ⋅ ⋅ , x m } D =\{\pmb x_1, \pmb x_2,··· , \pmb x_m\} D={xx1,xx2,⋅⋅⋅,xxm},样本 x i = { x i 1 , ⋅ ⋅ ⋅ , x i n } \pmb x_i=\{x_{i1},···,x_{in}\} xxi={xi1,⋅⋅⋅,xin},第 i i i 个簇 C i C_i Ci 的原型 p i = { p i 1 , ⋅ ⋅ ⋅ , p i m } \pmb p_i=\{p_{i1},···,p_{im}\} ppi={pi1,⋅⋅⋅,pim}, k k k-prototype的理想优化目标是最小化误差,误差度量也即损失函数为
E = ∑ l = 1 k ∑ i = 1 m y i l d ( x i , p l ) (30) E=\sum_{l=1}^k\sum_{i=1}^m \space y_{il}\space d(\pmb x_i,\pmb p_l)\tag{30} E=l=1∑ki=1∑m yil d(xxi,ppl)(30)
其中, y i l y_{il} yil 表示样本 x i \pmb x_i xxi 是否在簇 C l C_l Cl 中,如果在簇中,则 y i l = 1 y_{il}=1 yil=1 否则 y i l = 0 y_{il}=0 yil=0 。 d ( x i , p l ) d(\pmb x_i,\pmb p_l) d(xxi,ppl) 度量样本 x i \pmb x_i xxi 与簇 C l C_l Cl 的原型 p l \pmb p_l ppl 的距离, k k k-prototype 算法考虑到一个样本具有数值型和类别型两类属性,因此对于数值型属性的距离采用欧拉距离的平方进行度量,对于类别型属性的距离采用汉明距离与某个系数的乘积进行度量。假定有 n c n_c nc 个数值型属性、 n − n c n - n_c n−nc 个类别型属性,不失一般性,令数值型属性排列在类别型属性之前,则
d ( x i , p l ) = ∑ u = 1 n c ( x i u − p l u ) 2 + γ l ∑ u = n c + 1 n δ ( x i u , p l u ) (30) d(\pmb x_i,\pmb p_l)=\sum_{u=1}^{n_c} (x_{iu}-p_{lu})^2+\space\gamma_l\sum_{u=n_c+1}^n \delta(x_{iu},p_{lu})\tag{30} d(xxi,ppl)=u=1∑nc(xiu−plu)2+ γlu=nc+1∑nδ(xiu,plu)(30)
其中, γ l \gamma_l γl 为度量簇 C l C_l Cl 中样本与原型的类别型属性距离时的权重,即上文中提到的”系数“。
在更新原型的方式上,对于数值型属性计算均值,对于类别型属性以频率最大的属性作为代表,相当于融合了 k k k-means 算法和 k k k-modes 算法,其算法流程依然与 k k k-means 一致。
为了与前文的符号统一,这里定义的符号与参考论文有些不同。这部分仅挑选了论文中有关思想及算法的部分进行了讲解。
4.4 k k k-medoids 算法
不去详细区分”mediods“和”medoids“,网上对于两个单词的用法区分度不高。
k k k-means 算法对离群点敏感,当离群点分配到一个簇时,它们可能严重地扭曲簇的均值,这不经意间影响了其他样本的分配。 k k k-medoids 算法应运而生,围绕中心点划分(Partitioning Around Medoids,简称 PAM)算法是 k k k-medoids 聚类的一种实现方式。
k k k-medoids 算法流程相较于 k k k-means 算法有一些区别。首先需要明确,在 k k k-medoids 算法中,簇的原型一定是样本,这与前面讲到的聚类算法不同。
算法流程大致描述如下:
- 随机选取 k k k 个样本作为原型
- 计算每个非原型样本到原型样本的距离,把每个非原型样本分配到距离它最近的原型所代表的簇中
- 尝试用全部非原型样本去替换每个原型样本作为新的原型,对于全部替换方式,计算替换前后的目标函数值变化量(后减前)
- 如果存在变化量小于零的替换方式,则选择变化量最小的对应的替换方式,用新样本替换原型样本作为新原型,迭代第二步到第四步;反之,如果不存在则不替换,算法结束
给定样本集 D = { x 1 , x 2 , ⋅ ⋅ ⋅ , x m } D =\{\pmb x_1, \pmb x_2,··· , \pmb x_m\} D={xx1,xx2,⋅⋅⋅,xxm}, k k k 个簇的原型样本为 p = { p 1 , ⋅ ⋅ ⋅ , p k } \pmb p=\{\pmb p_1,···,\pmb p_k\} pp={pp1,⋅⋅⋅,ppk} 且 p i ∈ D \pmb p_i ∈D ppi∈D, k k k-medoids 算法的目标函数
E = ∑ i = 1 k ∑ x ∈ C i d i s t ( x , p i ) E=\sum_{i=1}^k\sum_{\pmb x∈C_i} {\rm dist}(\pmb x, \pmb p_i) E=i=1∑kxx∈Ci∑dist(xx,ppi)
我们认为样本自己间的距离为 0 0 0,所以上式不再特意区分簇中的样本是原型还是非原型。可以根据需要选择不同的距离度量方式。
举个简单的例子,假定忽略距离度量方法,表 2 2 2 直接以邻接矩阵的形式给出 5 5 5 个样本两两之间的距离。
| 样本点 | A | B | C | D | E |
|---|---|---|---|---|---|
| A | 0 | 1 | 2 | 2 | 3 |
| B | 1 | 0 | 2 | 4 | 3 |
| C | 2 | 2 | 0 | 1 | 5 |
| D | 2 | 4 | 1 | 0 | 3 |
| E | 3 | 3 | 5 | 3 | 0 |
表 2 距离邻接矩阵
假定从 5 5 5 个样本中随机抽取的 2 2 2 个原型为 { A , B } \{A,B\} {A,B},则样本被划分为 { A , C , D } \{A,C,D\} {A,C,D} 和 { B , E } \{B,E\} {B,E} ,如图 3 3 3 所示。此时的目标函数值为 2 + 2 + 3 = 7 2+2+3=7 2+2+3=7。

图 3 初始划分
尝试用每个非原型样本替换原型样本作为簇的原型,对于这个示例而言,总共有 3 × 2 = 6 3×2=6 3×2=6 种替换方式,如图 4 4 4 所示。分别计算出六种替换方式的目标函数值变化量:用样本 C C C 替换原型样本 A A A 得到变化量为 Δ A C = ( 1 + 1 + 3 ) − 7 = − 2 \Delta_{AC}=(1+1+3)-7=-2 ΔAC=(1+1+3)−7=−2,其他五个类似, Δ A D = − 2 \Delta_{AD}=-2 ΔAD=−2, Δ A E = − 1 \Delta_{AE}=-1 ΔAE=−1, Δ B C = − 2 \Delta_{BC}=-2 ΔBC=−2, Δ B D = − 2 \Delta_{BD}=-2 ΔBD=−2, Δ B E = − 2 \Delta_{BE}=-2 ΔBE=−2。计算完毕后,要选取一个最小的代价,显然有多种替换可以选择,选择 C C C 替换 A A A,根据图 4 4 4 左上角子图所示,样本被划分为 { B , A , E } \{ B,A,E\} {B,A,E} 和 { C , D } \{C,D\} {C,D} 两个簇。
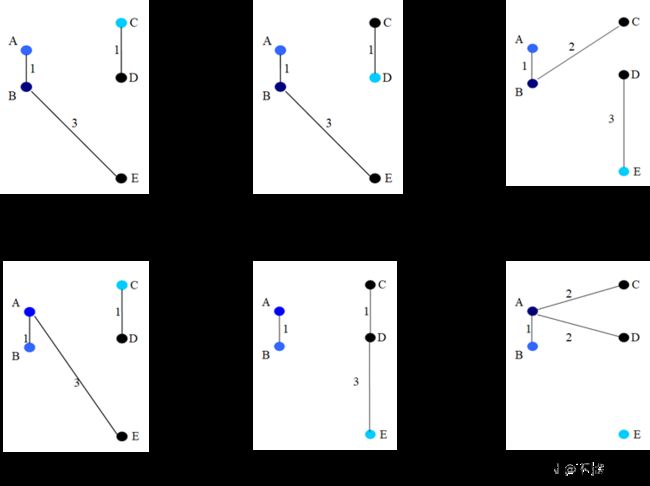
图 4 六种替换方式
通过上述计算,已经完成了 PAM 算法的第一次迭代。在下一迭代中,将用其他的非原型样本 { A , D , E } \{A,D,E\} {A,D,E} 替换原型 { B , C } \{B,C\} {B,C},找出具有最小变化量的替换。一直重复上述过程,直到目标函数不再减小为止。
4.5 学习向量量化
”学习向量量化“属于监督学习的算法,也就是说存在训练与预测两部分,而无监督学习没有训练与预测之说,可以直接进行分类。但是无监督也可能存在参数要学习,比如上面的 k k k-means 算法等都是采用 EM 算法进行参数学习,上述聚类算法中的参数为簇原型。
之所以将这部分放在”聚类“部分讲解,是因为其训练算法与 k k k-means 算法流程基本一致。
与k均值算法类似,“学习向量量化”(Learning Vector Quantization,简称 LVQ)也是试图找到一组原型向量来刻画聚类结构,但与一般聚类算法不同的是,LVQ 假设数据样本带有类别标记,学习过程利用样本的这些监督信息来辅助聚类。
给定样本集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋅ ⋅ ⋅ , ( x m , y m ) } D= \{(\pmb x_1, y_1),(\pmb x_2, y_2),···, (\pmb x_m ,y_m)\} D={(xx1,y1),(xx2,y2),⋅⋅⋅,(xxm,ym)},每个样本 x j \pmb x_j xxj 是由 n n n 个属性描述的特征向量 ( x j 1 ; x j 2 ; ⋅ ⋅ ⋅ ; x j n ) (x_{j1};x_{j2};···; x_{jn}) (xj1;xj2;⋅⋅⋅;xjn), y j ∈ Y y_j ∈ \mathcal Y yj∈Y 是样本 x j \pmb x_j xxj 的类别标记。LVQ 的目标是学得一组 n n n 维原型向量 { p 1 , p 2 , ⋅ ⋅ ⋅ , p q } \{\pmb p_1,\pmb p_2,···, \pmb p_q\} {pp1,pp2,⋅⋅⋅,ppq},每个原型向量代表一个聚类簇,簇标记 t i ∈ Y t_i∈\mathcal Y ti∈Y 。
允许 t i = t j ( i ≠ j ) t_i=t_j\space (i\ne j) ti=tj (i=j) ,这是因为 LVQ 是监督学习。
LVQ 算法描述如算法 2 2 2 所示。算法第 1 1 1 行先对原型向量进行初始化,例如对第 q q q 个簇可从类别标记为 t q t_q tq 的样本中随机选取一个作为原型向量。算法第 2 ∼ 12 2\sim12 2∼12 行对原型向量进行迭代优化。在每一轮迭代中,算法随机选取一个有标记训练样本,找出与其距离最近的原型向量,并根据两者的类别标记是否一致来对原型向量进行相应的更新。在第 12 12 12 行中,若算法的停止条件已满足(例如已达到最大迭代轮数,或原型向量更新很小甚至不再更新),则将当前原型向量作为最终结果返回。
输入: 样本集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋅ ⋅ ⋅ , ( x m , y m ) } ; 原型向量个数 q ,各原型向量预设的类别标记 { t 1 , t 2 , ⋅ ⋅ ⋅ , t q } ; 学习率 η ∈ ( 0 , 1 ) . 过程: \begin{array}{ll} \textbf{输入:}&\space样本集\space D = \{(\pmb x_1,y_1),(\pmb x_2,y_2),···,(\pmb x_m,y_m)\}\space ;&\\ &\space 原型向量个数\space q,各原型向量预设的类别标记\space\{t_1,t_2,··· ,t_q\}\space ;\\ &\space 学习率 \space \eta∈(0,1)\space. \\ \textbf{过程:} \end{array} 输入:过程: 样本集 D={(xx1,y1),(xx2,y2),⋅⋅⋅,(xxm,ym)} ; 原型向量个数 q,各原型向量预设的类别标记 {t1,t2,⋅⋅⋅,tq} ; 学习率 η∈(0,1) .
1 : 初始化一组原型向量 { p 1 , p 2 , ⋅ ⋅ ⋅ , p k } 2 : repeat 3 : 从样本集 D 随机选取样本 ( x j , y j ) ; 4 : 计算样本 x j 与 p i ( 1 ≤ i ≤ q ) 的距离 : d j i = ∥ x j − p i ∥ 2 ; 5 : 找出与 x j 距离最近的原型向量 p i ∗ , i ∗ = a r g m i n i ∈ { 1 , 2 , ⋅ ⋅ ⋅ , q } d j i ; 6 : if y j = t i ∗ then 7 : p ′ = p i ∗ + η ⋅ ( x j − p i ∗ ) 8 : else 9 : p ′ = p i ∗ − η ⋅ ( x j − p i ∗ ) 10 : end if 11 : 将原型向量 p i ∗ 更新为 p ′ 12 : until 满足停止条件 \begin{array}{rl} 1:&初始化一组原型向量\space \{\pmb p_1,\pmb p_2,···,\pmb p_k\}\\ % 2:&\textbf{repeat}\\ % 3:&\space\space\space\space 从样本集 \space D\space 随机选取样本(\pmb x_j,y_j)\space ;\\ % 4:&\space\space\space\space 计算样本\space \pmb x_j\space 与\space \pmb p_i\space (1 \le i\le q)\space 的距离: d_{ji} =\Vert \pmb x_j - \pmb p_i\Vert_2\space ;\\ % 5:&\space\space\space\space 找出与\space\pmb x_j\space 距离最近的原型向量\space \pmb p_{i^*},i^*={\rm arg}\space {\rm min}_{i∈\{1,2,···,q\}} \space d_{ji} \space;\\ % 6:&\space\space \space\space \textbf{if}\space y_j=t_{i^*}\space \textbf{then}\\ % 7:&\space\space \space\space\space\space\space\space \pmb p'=\pmb p_{i^*}+\eta\space·\space (\pmb x_j-\pmb p_{i^*})\\ % 8:&\space\space \space\space \textbf{else}\\ % 9:&\space\space\space\space\space\space\space\space \pmb p'=\pmb p_{i^*}-\eta\space·\space (\pmb x_j-\pmb p_{i^*})\\ % 10:&\space\space \space\space \textbf{end}\space \textbf{if}\\ % 11:&\space\space\space\space将原型向量\space \pmb p_{i^*}\space更新为\space \pmb p'\\ % 12:& \textbf{until}\space 满足停止条件\\ \end{array} 1:2:3:4:5:6:7:8:9:10:11:12:初始化一组原型向量 {pp1,pp2,⋅⋅⋅,ppk}repeat 从样本集 D 随机选取样本(xxj,yj) ; 计算样本 xxj 与 ppi (1≤i≤q) 的距离:dji=∥xxj−ppi∥2 ; 找出与 xxj 距离最近的原型向量 ppi∗,i∗=arg mini∈{1,2,⋅⋅⋅,q} dji ; if yj=ti∗ then pp′=ppi∗+η ⋅ (xxj−ppi∗) else pp′=ppi∗−η ⋅ (xxj−ppi∗) end if 将原型向量 ppi∗ 更新为 pp′until 满足停止条件
输出: 原型向量 { p 1 , p 2 , ⋅ ⋅ ⋅ , p q } \begin{array}{l} \textbf{输出:}\space 原型向量\space \{\pmb p_1,\pmb p_2,···,\pmb p_q\}&&&&&&&&&&&&&&&&& \end{array} 输出: 原型向量 {pp1,pp2,⋅⋅⋅,ppq}
算法 2 学习向量量化算法
显然,LVQ 的关键是第 6 ∼ 10 6\sim10 6∼10 行,即如何更新原型向量。直观上看,对样本 x j \pmb x_j xxj,若最近的原型向量 p i ∗ \pmb p_{i^*} ppi∗ 与 x j \pmb x_j xxj 的类别标记相同,则令 p i ∗ \pmb p_{i^*} ppi∗ 向 x j \pmb x_j xxj 的方向靠拢,如第 7 7 7 行所示,此时新原型向量为
p ′ = p i ∗ + η ⋅ ( x j − p i ∗ ) (31) \pmb p'=\pmb p_{i^*}+\eta\space·\space (\pmb x_j-\pmb p_{i^*})\tag{31} pp′=ppi∗+η ⋅ (xxj−ppi∗)(31)
p ′ \pmb p' pp′ 与 x j \pmb x_j xxj 之间的距离为
∥ p ′ − x j ∥ 2 = ∥ p i ∗ + η ⋅ ( x j − p i ∗ ) − x j ∥ 2 = ( 1 − η ) ⋅ ∥ p i ∗ − x j ∥ 2 \begin{align} \Vert \pmb p'-\pmb x_j\Vert_2 &=\Vert\pmb p_{i^*}+\eta\space·\space (\pmb x_j-\pmb p_{i^*})-\pmb x_j\Vert_2 \notag \\ &=(1-\eta)\space·\space\Vert \pmb p_{i^*}-\pmb x_j \Vert_2 \tag{32} \end{align} ∥pp′−xxj∥2=∥ppi∗+η ⋅ (xxj−ppi∗)−xxj∥2=(1−η) ⋅ ∥ppi∗−xxj∥2(32)
令学习率 η ∈ ( 0 , 1 ) \eta∈ (0,1) η∈(0,1),则原型向量 p i ∗ \pmb p_{i^*} ppi∗ 在更新为 p ′ \pmb p' pp′ 之后将更接近 x j \pmb x_j xxj 。
类似的,若 p i ∗ \pmb p_{i^*} ppi∗ 与 x j \pmb x_j xxj 的类别标记不同,则更新后的原型向量与 x j \pmb x_j xxj 之间的距离将增大为 ( 1 + η ) ⋅ ∥ p i ∗ − x j ∥ 2 (1+\eta)\space ·\space \Vert\pmb p_{i^*}-\pmb x_j\Vert_2 (1+η) ⋅ ∥ppi∗−xxj∥2,从而更远离 x j \pmb x_j xxj 。
之所以式 ( 31 ) (31) (31) 不直接使用 ± η ⋅ x j \pm \space\eta\space·\space\pmb x_j ± η ⋅ xxj ,而使用 ± η ⋅ ( x j − p i ∗ ) \pm \space \eta\space·\space (\pmb x_j-\pmb p_{i^*}) ± η ⋅ (xxj−ppi∗),正是因为要保证计算 p ′ \pmb p' pp′ 与 x j \pmb x_j xxj 之间距离时能方便比较变化前后的距离大小,即得到式 ( 32 ) (32) (32)。总而言之,就是为了更好的解释性。
在学得一组原型向量 { p 1 , p 2 , ⋅ ⋅ ⋅ , p q } \{\pmb p_1,\pmb p_2,··· ,\pmb p_q\} {pp1,pp2,⋅⋅⋅,ppq} 后,即可实现对样本空间 X \mathcal X X 的簇划分。对任意样本 x \pmb x xx,它将被划入与其距离最近的原型向量所代表的簇中;换言之,每个原型向量 p i \pmb p_i ppi 定义了与之相关的一个区域 R i R_i Ri,该区域中每个样本与 p i \pmb p_i ppi 的距离不大于它与其他原型向量 p i ′ ( i ′ ≠ i ) \pmb p_{i'} \space (i'\ne i) ppi′ (i′=i) 的距离,即
R i = { x ∈ X ∣ ∥ x − p i ∥ 2 ≤ ∥ x − p i ′ ∥ 2 , i ′ ≠ i } (33) R_i=\{\pmb x ∈ \mathcal X\mid \Vert \pmb x-\pmb p_{i} \Vert_2 \le \Vert \pmb x-\pmb p_{i'} \Vert_2,\space i'\ne i \}\tag{33} Ri={xx∈X∣∥xx−ppi∥2≤∥xx−ppi′∥2, i′=i}(33)
由此形成了对样本空间 X \mathcal X X 的簇划分 { R 1 , R 2 , ⋅ ⋅ ⋅ , R q } \{R_1, R_2,··· ,R_q\} {R1,R2,⋅⋅⋅,Rq},该划分通常称为“Voronoi 剖分”(Voronoi tessellation)。
若将 R i R_i Ri 中样本全用原型向量 p i \pmb p_i ppi 表示,则可实现数据的“有损压缩”(lossy compression),这称为“向量量化”(vector quantization);LVQ 由此而得名。
下面我们以表 1 1 1 的西瓜数据集为例来演示 LVQ 的学习(训练)过程。令 9 ∼ 21 9\sim21 9∼21 号样本的类别是“好瓜=否”标记为 C 2 C_2 C2,其他样本的类别是“好瓜=是”标记为 C 1 C_1 C1 。假定 q = 5 q=5 q=5,即学习目标是找到 5 5 5 个原型向量 p 1 , p 2 , p 3 , p 4 , p 5 \pmb p_1,\pmb p_2, \pmb p_3, \pmb p_4, \pmb p_5 pp1,pp2,pp3,pp4,pp5,并假定其对应的类别标记分别为 C 1 , C 2 , C 2 , C 1 , C 1 C_1,C_2,C_2,C_1,C_1 C1,C2,C2,C1,C1,即希望为“好瓜=是”找到 3 3 3 个簇,“好瓜=否”找到 2 2 2 个簇。
算法开始时,根据样本的类别标记和簇的预设类别标记对原型向量进行随机初始化,假定初始化为样本 x 5 , x 12 , x 18 , x 23 , x 29 \pmb x_5,\pmb x_{12},\pmb x_{18},\pmb x_{23},\pmb x_{29} xx5,xx12,xx18,xx23,xx29 。在第一轮迭代中,假定随机选取的样本为 x 1 \pmb x_1 xx1,该样本与当前原型向量 p 1 , p 2 , p 3 , p 4 , p 5 \pmb p_1,\pmb p_2, \pmb p_3, \pmb p_4, \pmb p_5 pp1,pp2,pp3,pp4,pp5 的距离分别为 0.283 , 0.506 , 0.434 , 0.260 , 0.032 0.283,0.506,0.434,0.260,0.032 0.283,0.506,0.434,0.260,0.032 。由于 p 5 \pmb p_5 pp5 与 x 1 \pmb x_1 xx1 距离最近且两者具有相同的类别标记 C 2 C_2 C2,假定学习率 η = 0.1 \eta=0.1 η=0.1,则 LVQ 更新 p 5 \pmb p_5 pp5 得到新原型向量
p ′ = p 5 + η ⋅ ( x 1 − p 5 ) = ( 0.725 ; 0.445 ) + 0.1 ⋅ ( ( 0.697 ; 0.460 ) − ( 0.725 ; 0.445 ) ) = ( 0.722 ; 0.442 ) \begin{align} \pmb p'&=\pmb p_5+\eta\space ·\space (\pmb x_1-\pmb p_5) \notag \\ &=(0.725;0.445)+0.1·\left((0.697;0.460) -(0.725;0.445)\right) \notag\\ &=(0.722;0.442) \end{align} pp′=pp5+η ⋅ (xx1−pp5)=(0.725;0.445)+0.1⋅((0.697;0.460)−(0.725;0.445))=(0.722;0.442)
将 p 5 \pmb p_5 pp5 更新为 p ′ \pmb p' pp′ 后,不断重复上述过程,不同轮数之后的聚类结果如图 5 5 5 所示。
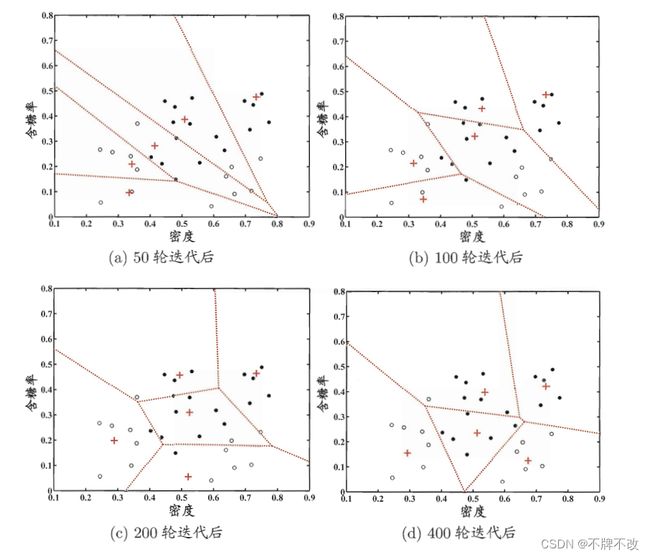
图 5 西瓜数据集上 LVQ 算法(q=5)在不同轮数迭代后的聚类结果。C1, C2类样本点与原型向量分别用“●”,“○”与“+”表示,红色虚线显示出聚类形成的 Voronoi 剖分。
注意,算法 2 2 2 描述过程为模型训练的过程,该算法输出一组原型向量。使用模型进行预测时,我们计算待预测样本与每个簇的原型向量之间的距离,将样本分配到距离最近的簇中,簇的标签即为该样本的预测标签。