Flink部署
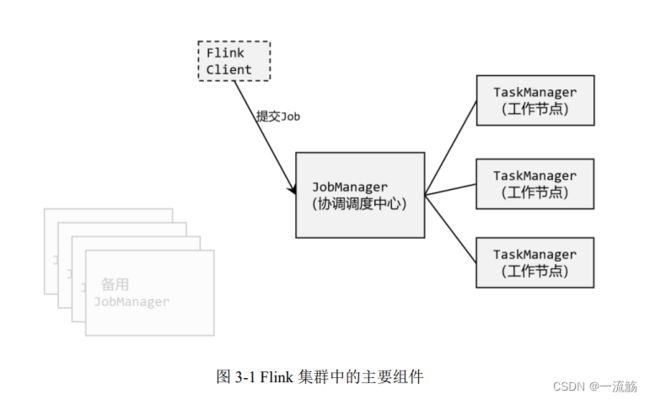
Flink 中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任 务 管 理 器 ( TaskManager)。 我 们 的 代 码 , 实 际 上 是 由 客 户 端 获 取 并 做 转 换 , 之 后 提 交 给JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager。这里的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,这里如图所示:
1、快速搭建
准备一个flink包,这里用的是flink-1.13.2-bin-scala_2.11.tgz
解压
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
启动
进入解压后的目录,执行启动命令,并查看进程。
$ cd flink-1.13.0/
$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
$ jps
10369 StandaloneSessionClusterEntrypoint
10680 TaskManagerRunner
10717 Jps
启动成功以后,访问http:hadoop102:8081
搭建flink集群
Flink 是 典 型 的 Master-Slave 架 构 的 分 布 式 数 据 处 理 框 架 , 其 中 Master 角 色 对 应 着
JobManager,Slave 角色则对应 TaskManager。
进入conf目录下,修改flink-conf.yaml文件,设置 jobmanager.rpc.address 参数为Hadoop102
cd conf/
vim flink-conf.yaml
JobManager 节点地址.
jobmanager.rpc.address: hadoop102
(2)修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点,
具体修改如下:
$ vim workers
hadoop103
hadoop104
这样就指定了 hadoop103 和 hadoop104 为 TaskManager 节点。
(3)另外,在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件
进行优化配置,主要配置项如下:
⚫ jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置,
包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
⚫ taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,
包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
⚫ taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置,
默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓
Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
⚫ parallelism.default:Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配
置和任务提交时使用参数指定的并行度数量。
分发到其他目录机器就行。
提交作业的方式
将程序进行打包上传到
1、基于页面提交
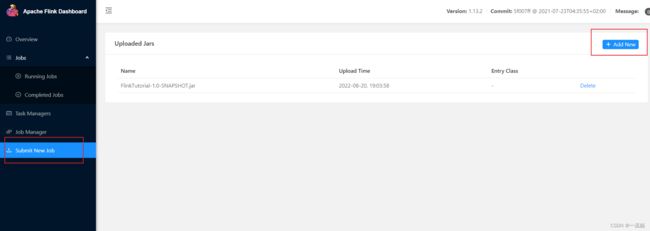
(1)任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包,如图 3-4 所示。
(2)点击该 JAR 包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如图 3-6 所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况。
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行。
2、命令提交作业
除了通过 WEB UI 界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便
起见,我们可以先把 jar 包直接上传到目录 flink-1.13.0 下
(1)首先需要启动集群。
$ bin/start-cluster.sh
(2)在 hadoop102 中执行以下命令启动 netcat。
$ nc -lk 7777
(3)进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业。
bin/flin run -m hadoop102:8081 -c com.atguigu.wc.BatchWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
部署模式
Flink 为各种场景提供了不同的部署模式,主要有以下三种:
⚫ 会话模式(Session Mode)
⚫ 单作业模式(Per-Job Mode)
⚫ 应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底在哪里执行——客户端(Client)还是 JobManager。
会话模式:会话模式其实最符合常规思维。需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。会话模式比较适合于单个规模小、执行时间短的大量作业。
单作业模式:客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
应用模式:直接把应用提交到 JobManger 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了。Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管
理框架来启动集群,比如 YARN、Kubernetes。
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群。
总结一下,
在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。
单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。
最后,应用模式为每个应用程序创建一个会话集群,JobManager 上直接调用应用程序的 main()方法。