新一代分布式实时流处理引擎Flink入门实战操作篇
文章目录
- 安装部署
-
- 安装方式
- Local(Standalone 单机部署)
- Standalone部署
- Standalone HA部署
- Flink On Yarn演示案例
-
- 概述
- 会话(Session)模式
- 单作业(Per-Job)模式
-
- 流程
- 演示
- 应用(Application)模式
安装部署
安装方式
Flink安装支持多种方式,包括Flink Local和Flink Standalone、Flink On Yarn、Flink On Mesos、Flink On K8S等。
- Flink Local基本只用于开发测试
- Flink Standalone为自身提供资源管理,也大部分用于测试
- 目前最佳实践还是得基于专业的任务调度和资源管理框架如yarn、k8s、mesos。
使用前面部署服务器hadoop1、hadoop2、hadoop3,利用前面部署Hadoop环境包括HDFS和YARN,Flink运行在所有类unix环境中如Linux、Mac OS X和Cygwin(用于Windows)可使用安装JDK环境,JDK8也是可以的,但官方上最新写的是Java 11。
Local(Standalone 单机部署)
先下载和解压jdk11,配置JDK11环境
JAVA_HOME=/home/commons/jdk-11
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/jt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME PATH CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
下载最新版本1.15.1 Flink
wget https://dlcdn.apache.org/flink/flink-1.15.1/flink-1.15.1-bin-scala_2.12.tgz
# 解压
tar -xvf flink-1.15.1-bin-scala_2.12.tgz
增加Flink环境变量 vim /etc/profile
# flink环境变量
export FLINK_HOME=/home/commons/flink-1.15.1/
export PATH=$FLINK_HOME/bin:$PATH
保存后更新生效
# 重载环境变量配置
source /etc/profile
# 查看flink执行文件是否生效
which flink
# 进入目录
cd flink-1.15.1
修改flink的配置文件,vim conf/flink-conf.yaml
rest.port: 8081
rest.address: hadoop1
rest.bind-address: hadoop1
classloader.check-leaked-classloader: false
保存启动flink
# 启动flink
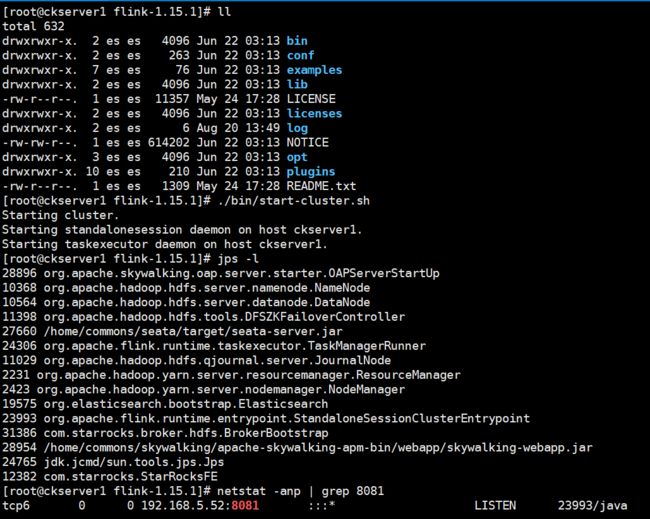
./bin/start-cluster.sh
启动成功后可以有StandaloneSessionClusterEntrypoint和TaskManagerRunner两个进程,Flink控制台 8081端口也已经启动监听,log目录存放的是运行日志,可以查阅standalonesession和flink-root-taskexecutor的运行日志,查日志出问题第一时间首选方式。
# 在windows 上可以配置hosts解析,将出现主机名和IP配置好,比如
192.168.5.52 hadoop1
192.168.5.53 hadoop2
192.168.50.95 hadoop3
192.168.5.52 ckserver1
192.168.5.53 ckserver2
192.168.50.95 k8snode
访问http://hadoop1:8081/ 出现flink 任务管理主页面

使用flink提供的示例程序测试,先在本机上监听5500端口
nc -l 5500
然后运行flink的SocketWindowWordCount基于流式处理统计单词数量
flink run ./examples/streaming/SocketWindowWordCount.jar --port 5500
执行后产生一个JobID

在Socket窗口上输出测试数据

通过上面JobID在控制台页面查看其详细信息
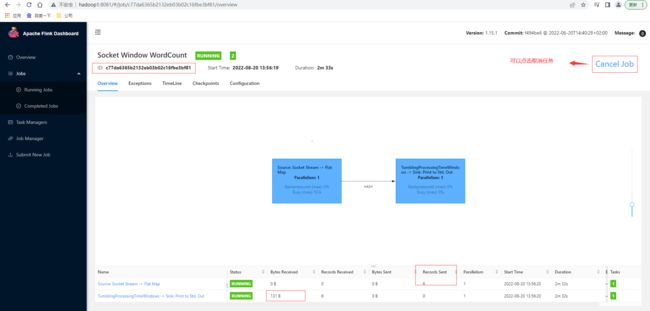
点击第二条即窗口sink的任务里的Stdout输出信息可以看到Flink每几秒的统计窗口输出单词数量

任务可以通过UI界面取消,也可以通过命令行取消,下述为几个常见命令或脚本
# 显示flink任务列表
flink -list
# 后边跟的任务id 是flink的任务ID,stop方式停止任务对 source 有要求,source必须实现了StopableFunction接口,才可以优雅的停止job,是更优雅的停止正在运行流作业的方式。stop() 仅适用于 source 实现了StoppableFunction 接口的作业。当用户请求停止作业时,作业的所有 source 都将接收 stop() 方法调用。直到所有 source 正常关闭时,作业才会正常结束。这种方式,使作业正常处理完所有作业
flink stop
# 取消任务。如果在 conf/flink-conf.yaml 里面配置了 state.savepoints.dir ,会保存savepoint,否则不会保存 savepoint。立即调用作业算子的 cancel() 方法,以尽快取消它们。如果算子在接到 cancel() 调用后没有停止,Flink 将开始定期中断算子线程的执行,直到所有算子停止为止。
flink cancel
Standalone部署
# 先停止Flink集群
./bin/stop-cluster.sh
# 删除日志目录
rm -rf log/*
部署1个master和3个worker修改flink的主配置文件,在前面local配置基础上修改,vim conf/flink-conf.yaml
# 分发给其他两台后
jobmanager.rpc.address: hadoop1
jobmanager.bind-host: 0.0.0.0
修改masters文件内容,vim conf/masters
hadoop1:8081
修改masters文件内容,vim conf/workers
hadoop1
hadoop2
hadoop3
将hadoop1Flink拷贝hadoop2和hadoop3上
# 分发给其他两台服务器上
scp -r /home/commons/flink-1.15.1 hadoop2:/home/commons/flink-1.15.1
scp -r /home/commons/flink-1.15.1 hadoop3:/home/commons/flink-1.15.1
# 将环境变量配置文件也分发到其他两台或者分别修改
scp -r /etc/profile hadoop2:/etc/
scp -r /etc/profile hadoop3:/etc/
# 分别在hadoop2和hadoop3上执行重载环境变量配置
source /etc/profile
# 在hadoop1上执行启动集群脚本
./bin/start-cluster.sh
查看
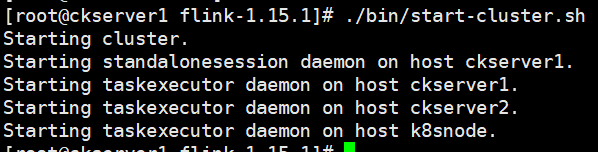
hadoop2和hadoop3上也看到TaskManagerRunner也成功启动

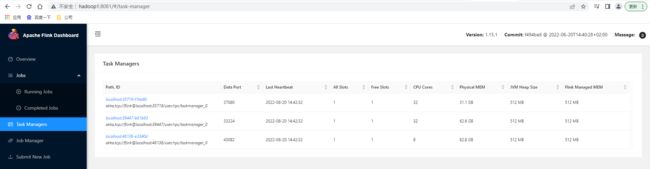
查看控制台UI页面,已经显示Available Task Slots为3,Total Task Slots为3,Task Managers为3,3个TaskManager的信息如下:
跑一个本地文件测试
flink run ./examples/batch/WordCount.jar --input /home/commons/word.txt --output /home/commons/out/01
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4PBRiKRl-1661011137824)(http://www.itxiaoshen.com:3001/assets/1661010991517jdB5bSyZ.png)]
通过JobID ab79b7f681dcf2bc6e10fb53b71f745e查看UI信息,任务成功执行完毕
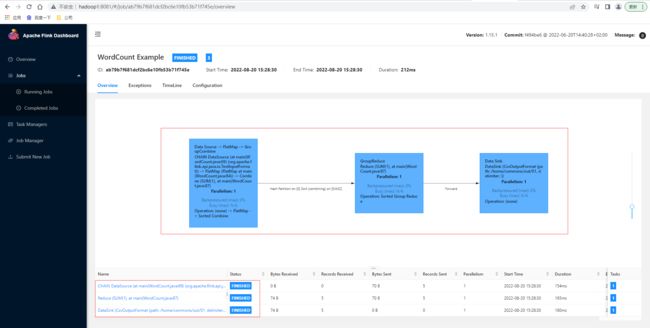
查看输入文件和输出文件内容,已输出正确单词信息
Standalone HA部署
# 先停止Flink集群
./bin/stop-cluster.sh
三台服务器上添加HADOOP环境变量,也可以采用修改一台,scp方式
export HADOOP_HOME=/home/commons/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`hadoop classpath`
完成后三台都执行更新生效环境变量
source /etc/profile
配置高可用模式和ZooKeeper仲裁,在前面配置基础上修改,vim conf/flink-conf.yaml中
high-availability: zookeeper
high-availability.zookeeper.quorum: zk1:2181,zk2:2181,zk3:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_flink # important: customize per cluster
high-availability.storageDir: hdfs://hadoop2:9000/flink/recovery
修改hadoop1的masters内容,vim conf/masters:
hadoop1:8081
hadoop2:8081
将hadoop1Flink更新配置拷贝hadoop2和hadoop3上
# 分发给其他两台服务器上
scp -r conf/flink-conf.yaml conf/masters hadoop2:/home/commons/flink-1.15.1/conf/
scp -r conf/flink-conf.yaml conf/masters hadoop3:/home/commons/flink-1.15.1/conf/
修改hadoop2的conf/flink-conf.yaml 内容
jobmanager.rpc.address: hadoop2
rest.port: 8081
rest.address: hadoop2
rest.bind-address: hadoop2
在在hadoop1上执行启动集群脚本
./bin/start-cluster.sh
查看hadoop2也有一个StandaloneSessionClusterEntrypoint进程,支持HA

访问hadoop2上也有http://hadoop2:8081/ 出现flink 任务管理主页面

同样跑一个HDFS文件测试下
hdfs dfs -mkdir /mytest/input
hdfs dfs -mkdir /mytest/output
hdfs dfs -put /home/commons/word.txt /mytest/input/
flink run ./examples/batch/WordCount.jar --input hdfs://hadoop2:9000/mytest/input/word.txt --output hdfs://hadoop2:9000/mytest/output/w100
查看运行结果

Standalone HA=切换测试
nc -l 6000
flink run ./examples/streaming/SocketWindowWordCount.jar --port 6000

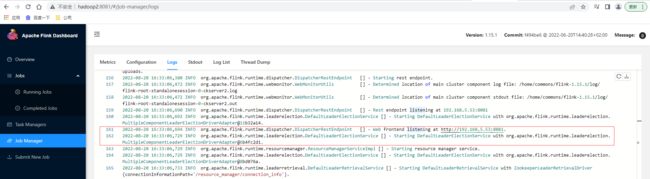
访问hadoop1的Flink控制台页面,从Job Manager的Logs可以看出目前hadoop1是leader激活的状态
访问hadoop2的Flink控制台页面,从其Job Manager的Logs可以看出目前hadoop2没有leadership标志也即是为standby状态
手动杀死hadoop1上的JobManager也即是进程名为StandaloneSessionClusterEntrypoint

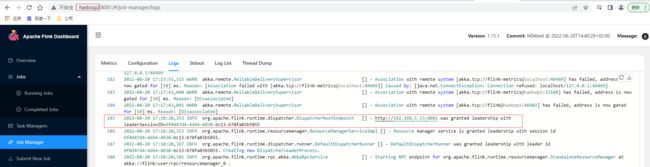
现在访问http://hadoop1:8081/ 后会自动跳转到http://hadoop2:8081/ 控制台页面,在hadoop2的Flink控制台页面Job Manager的Logs可以看出目前hadoop2已经切换为leader active的状态实现HA的切换
重新提交任务也是正常运行和出结果,完成HA模式验证

Flink On Yarn演示案例
概述
-
Yarn 模式的优点有:
- 资源的统一管理和调度。Yarn 集群中所有节点的资源(内存、CPU、磁盘、网络等)被抽象为 Container。计算框架需要资源进行运算任务时需要向 Resource Manager 申请 Container,Yarn 按照特定的策略对资源进行调度和进行 Container 的分配。Yarn 模式能通过多种任务调度策略来利用提高集群资源利用率。例如 FIFO Scheduler、Capacity Scheduler、Fair Scheduler,并能设置任务优先级。
- 资源隔离。Yarn 使用了轻量级资源隔离机制 Cgroups 进行资源隔离以避免相互干扰,一旦 Container 使用的资源量超过事先定义的上限值,就将其杀死。
- 自动failover处理。例如 Yarn NodeManager 监控、Yarn ApplicationManager 异常恢复。
-
相对于 Standalone 模式,在Yarn 模式下有以下几点好处:
-
资源按需使用,提高集群的资源利用率;
-
任务有优先级,根据优先级运行作业;
-
基于 Yarn 调度系统,能够自动化地处理各个角色的 Failover: JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控;
-
如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器;
如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager。
-
-
-
Yarn 模式虽然有不少优点,但是也有诸多缺点,例如运维部署成本较高,灵活性不够;
-
session(会话)模式提交作业时,所有的作业都提交到一个集群,资源是共享的,一个作业的失败会影响另外一个作业,作业失败恢复时,重启Job的时候,会并发 访问文件系统,可能导致文件系统对其他服务不可用。此外因为是单集群,JobManager的负载会很大。
会话(Session)模式
# 先停止之前集群
./bin/stop-cluster.sh
# 删除日志目录
rm -rf log/*
再将前面Standalone HA 3台服务上高可用配置注释掉,
conf/flink-conf.yaml
#high-availability: zookeeper
#high-availability.zookeeper.quorum: 192.168.50.156:2181
#high-availability.zookeeper.path.root: /flink
#high-availability.cluster-id: /cluster_flink # important: customize per cluster
#high-availability.storageDir: hdfs://hadoop2:9000/flink/recovery
conf/masters
#hadoop2:8081
# 分发给其他2台
scp -r conf/flink-conf.yaml conf/masters hadoop2:/home/commons/flink-1.15.1/conf/
scp -r conf/flink-conf.yaml conf/masters hadoop3:/home/commons/flink-1.15.1/conf/
保证下面前置条件
# 保证有YARN运行环境和hadoop环境变量,已有
export HADOOP_CLASSPATH=`hadoop classpath`
# 启动YARN Session
./bin/yarn-session.sh --detached

# 测试停止yarn-session.sh,通过yarn查询页面找到名称为Flink session cluster的ID
yarn application -kill application_1660632118438_0001
# 或者根据运行yarn-session.sh提示操作语句进行
echo "stop" | ./bin/yarn-session.sh -id application_1660632118438_0001
设置参数后重新启动
# -s为slot的个数 -jm为jobmanager的堆内存大小 -tm为taskmanager的堆内存大小 --detached分离模式,启动好后立即断开
./bin/yarn-session.sh -s 3 -jm 1024 -tm 1024 --detached

访问yarn webUI http://hadoop2:8088/cluster 可以查看到刚才application_1660632118438_0003

上面出现的JobManager Web Interface: http://ckserver1:8081 ,ckserver1是主机名,也就是hadoop1服务器,访问ckserver1和hadoop1是一样的,可以看到task slots为0,这就是flink on yarn的特点,按需启动。

# 运行作业测试下
flink run ./examples/batch/WordCount.jar --input hdfs://hadoop2:9000/mytest/input/word.txt --output hdfs://hadoop2:9000/mytest/output/w103
# 查看结果
hdfs dfs -cat /mytest/output/w103

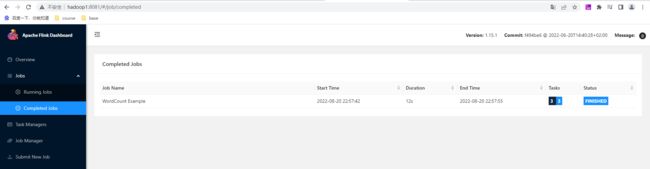
查看flink的任务可以看到完成的任务就有刚才的这个WordCount,基于yarn session 提交的作业在yarn webUI看不到的,可以通过flink --list或者通过yarn 进入到相应Application后点击Tracking URL:后面ApplicationMaster跳转到flink的webUI上查看

单作业(Per-Job)模式
流程
在单作业模式下,Flink 集群不会预先启动,而是在提交作业时,才启动新的 JobManager。具体流程如图所示。

- 客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器。
- YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给JobMaster。这里省略了 Dispatcher 组件。
- JobMaster 向资源管理器请求资源(slots)。
- 资源管理器向 YARN 的资源管理器请求 container 资源。
- YARN 启动新的 TaskManager 容器。
- TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的 JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,以及省去了分发器。当第 2 步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
演示
# 先停止前面创建的yarn-session
yarn application -kill application_1660632118438_0003
对于Flink Per-Job的操作直接运行flink run即可
# 开一个连接窗口
nc -l 5000
# 另外一个连接窗口执行
flink run -t yarn-per-job -ys 1 -ynm flinkstreamwordcount -yjm 1024 -ytm 1024 ./examples/streaming/SocketWindowWordCount.jar --port 5000
查看yarn上已经有Flink per-job cluster的应用
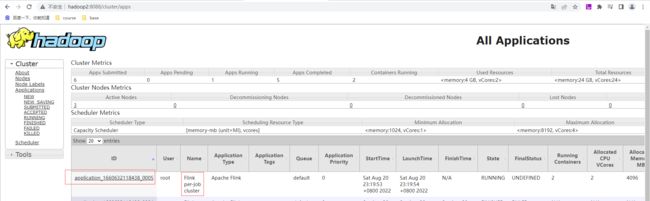
点击ID后在Application后点击Tracking URL:后面ApplicationMaster跳转到flink的webUI上查看

在监听端口5000输入数据后查看flink任务已有数据

应用(Application)模式
应用模式与单作业模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的 JobMaster。
由于资源不足,先配置yarn-site.xml
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>102400value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>32value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>51200value>
property>
先停止前面创建的yarn-session
yarn application -kill application_1660632118438_0006
# 启动监听端口
nc -l 5000
# 启动run-application
./bin/flink run-application -t yarn-application \
-Dparallelism.default=1 \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dyarn.application.name="MyFlinkWordCount" \
-Dtaskmanager.numberOfTaskSlots=3 \
./examples/streaming/SocketWindowWordCount.jar --port 5000
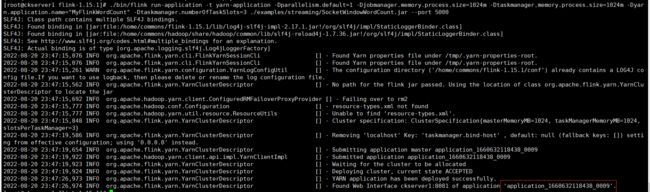
查看yarn已经有对应的application_1660632118438_0009

从yarn点击跳转flink也有相应的job,在监听端口5000输入数据后查看flink任务已有数据

**本人博客网站 **IT小神 www.itxiaoshen.com