BP+SGD+激活函数+代价函数+基本问题处理思路
0. 学习模型评价标准
1. 反向传播算法计算全过程

2. 随机梯度下降法计算全过程

3. 激活函数
3.1 为什么需要激活函数?
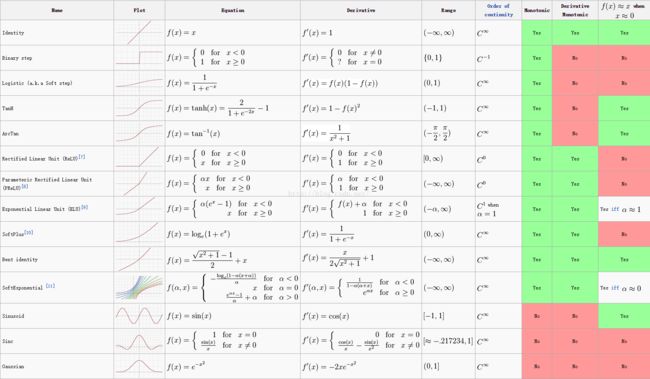
3.2 常见激活函数汇总
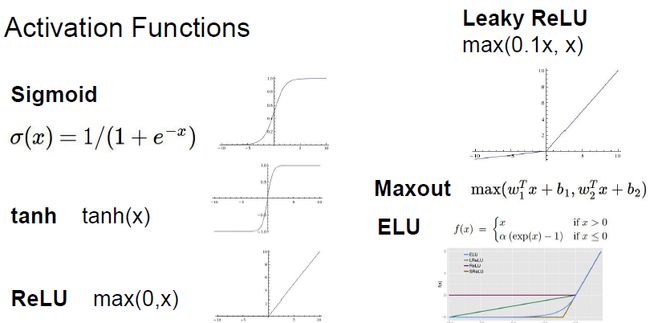
3.3 Sigmoid激活函数
3.3.1 Sigmoid激活函数
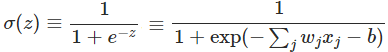
1)优点:
- 它可把输入的连续实值压缩到[0,1]之间
- 可解释为神经元饱和的“firing rate”
2)缺点:
- 饱和的神经元导致梯度消失
输入非常大或非常小时,其梯度接近于0
- 指数运算计算量大
- Sigmoid的输出不是以0为均值
产生的一个结果就是:如果数据进入神经元的时候是正的(e.g. x>0 elementwise in f=wTx+b),那么 w 计算出的梯度也会始终都是正的。 当然了,如果你是按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
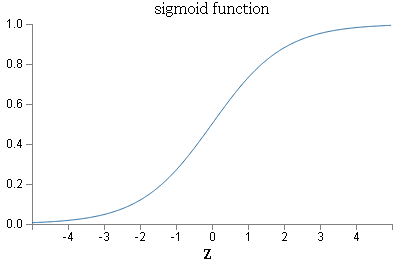
3.3.2 Sigmoid函数图形
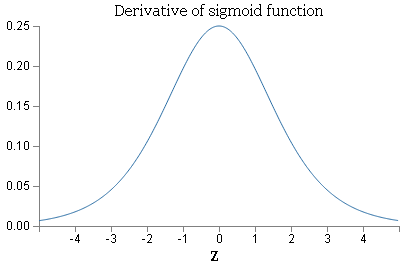
3.3.3 Sigmoid函数导数图形
3.4 Softmax激活函数
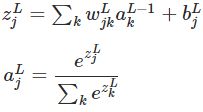
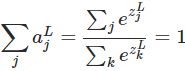
3.5 tanh激活函数
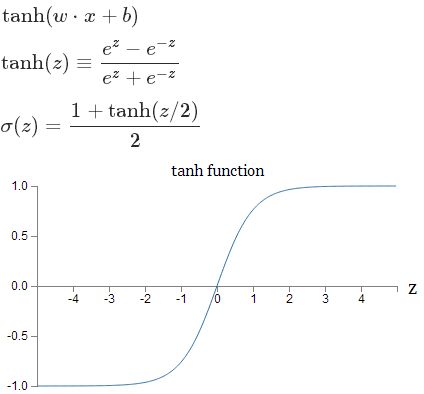
1)优点:
- 与Sigmoid相比,tanh是0均值的。
- 理论和实验证据表明tanh有时比Sigmoid性能更好。
- tanh(-z)=-tanh(z)
2)缺点:
- 饱和的神经元导致梯度消失
输入非常大或非常小时,其梯度接近于0
3.6 校正线性单元(Rectified Linear Unit:ReLU)
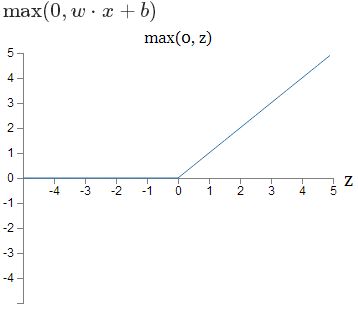
f(x) = max(0, wx+b)
1)优点:
相比于 sigmoid/tanh,有如下优点:
- 计算高效:采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计 算量相对大,而采用ReLU激活函数,整个过程的计算量节省很多。
- 没有饱和及梯度消失问题:对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
- ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
- 收敛速度比sigmoid/tanh快6倍
2)缺点:
- 当然 ReLU 也有缺点,就是训练的时候很”脆弱”,很容易就”die”了. 什么意思呢?
举个例子:一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。如果这个情况发生了,那么这个神经元的梯度就永远都会是0.实际操作中,如果你的Learning Rate 很大,那么很有可能你网络中的40%的神经元都”dead”了。
当然,如果你设置了一个合适的较小的Learning Rate,这个问题发生的情况其实也不会太频繁。
- 当z<0时,梯度也消失了
- 非零居中输出
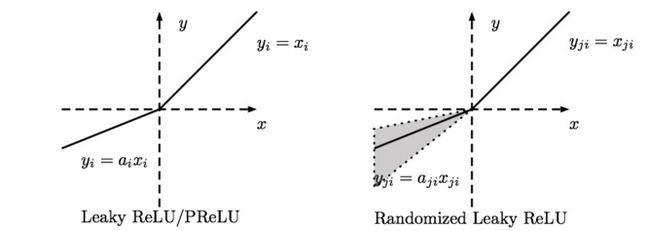
3.7 Leaky-ReLU、P-ReLU、R-ReLU
1)Leaky ReLU:
就是用来解决“Die ReLU”的,其定义如下:
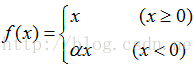
α 是一个很小的常数(如0.01)。这样,即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。关于Leaky ReLU 的效果,众说纷纭,没有清晰的定论。有些人做了实验发现 Leaky ReLU 表现的很好;有些实验则证明并不是这样。
优点:
- 不会饱和
- 计算高效
- 收敛速度快
- 不会死
2)Parametric ReLU:
对于 Leaky ReLU 中的 α ,通常都是通过先验知识人工赋值的。 而P-ReLU中, α 是一个变量,需要被学习。
然而可以观察到,损失函数对 α 的导数我们是可以求得的,可不可以将它作为一个参数进行训练呢?
Kaiming He的论文《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》指出,不仅可以训练,而且效果更好。
公式非常简单,反向传播至未激活前的神经元的公式就不写了,很容易就能得到。对 α 的导数如下:
原文说使用了Parametric ReLU后,最终效果比不用提高了1.03%.
3)Randomized ReLU:
Randomized Leaky ReLU 是 leaky ReLU 的random 版本 ( α 是random的).
它首次试在 kaggle 的NDSB 比赛中被提出的。 核心思想就是,在训练过程中,α 是从一个高斯分布
U(l,u) 中 随机出来的,然后再测试过程中进行修正(有点像dropout的用法)。
数学表示如下:
在测试阶段,把训练过程中所有的 αij 取个平均值。NDSB 冠军的 α 是从 U(3,8) 中随机出来的。那么,在测试阶段,激活函数就是就是:

4) Exponential Linear Units (ELU)
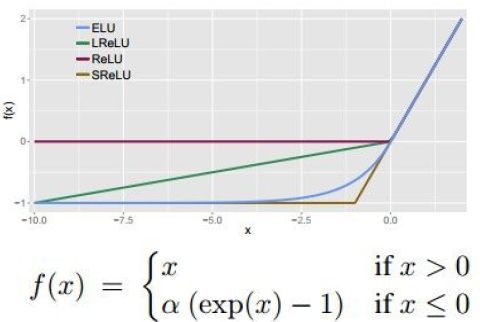
1)优点:
- 所有ReLU的优点
- 不会死
- 输出接近0均值
2)缺点:
- 计算量大,需要指数运算
3.8 Maxout
Maxout定义如下:
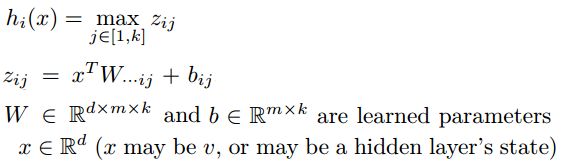
Maxout其实是改变了神经元的形式,它将每个神经元由原来一次训练一组参数扩展为同时训练多组参数,然后选择激活值最大的作为下一层的激活值,比如同时训练3组参数:
![]()
可以看出ReLu为Maxout同时训练两组参数且w2,b2取0时的情形,因此maxout拥有ReLu的所有优点同时避免了神经元“死亡”的现象;但是,由于需要多训练了几组参数,网络的效率也大大降低了。
Maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。最直观的解释就是任意的凸函数都可以由分段线性函数以任意精度拟合,而Maxout又是取k个“隐隐含层”节点的最大值,这些”隐隐含层"节点也是线性的,所以在不同的取值范围下,最大值也可以看做是分段线性的(分段的个数与k值有关)。论文中的图1如下(它表达的意思就是可以拟合任意凸函数,当然也包括了ReLU了):
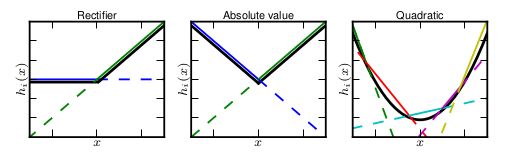
3.9 激活函数表
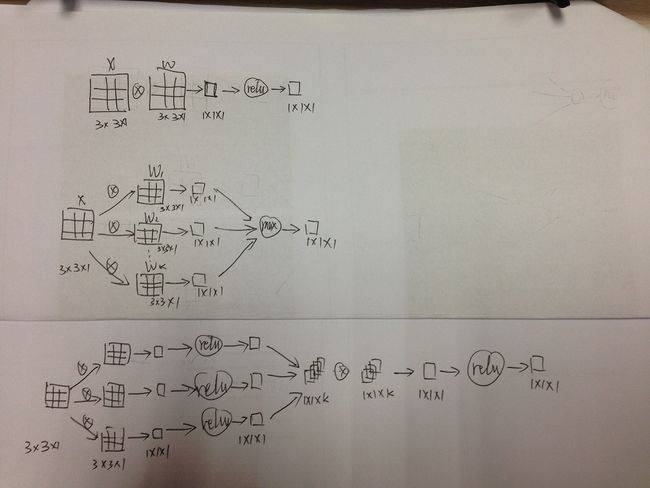
3.10 Conv&Maxout&NIN
NIN: Network in Network
Maxout和NIN都是对传统conv+relu的改进;Maxout想表明它能够拟合任何凸函数,也就能够拟合任何的激活函数(默认了激活函数都是凸的);NIN想表明它不仅能够拟合任何凸函数,而且能够拟合任何函数,因为它本质上可以说是一个小型的全连接神经网络。
3.10.1 工作流程
1)常规卷积层:conv→relu
- conv: conv_out=∑(x·w)
- ReLU: y=max(0, conv_out)
2)Maxout:several conv(full)→max
- several conv (full): conv_out1 = x·w_1, conv_out2 = x·w_2, …
- max: y = max(conv_out1, conv_out2, …)
3)NIN: conv→relu→conv(1x1)→relu
- several conv (full): conv_out1 = x·w_1, conv_out2 = x·w_2, …
- relu: relu_out1 = max(0, conv_out1), relu_out2 = max(0, conv_out2), …
- conv(1x1): conv_1x1_out = [relu_out1, relu_out2, …]·w_1x1
- relu: y = max(0, conv_1x1_out)
3.10.2 实例说明
1)常规卷积层:直接x和w求卷积,然后relu一下就好了。
3)NIN:有k个3x3的w(这里的k也是自由设定的),分别卷积得到k个1x1的输出,然后对它们都进行ReLU,然后再次对它们进行卷积,结果再ReLU。(这个过程,等效于一个小型的全连接网络)
3.11 如何选择激活函数
1)不要使用sigmoid;
2)可以考虑使用tanh,但期望不要太高;
3)使用ReLU激活函数的话,注意不要把学习率设得太高,避免产生结点”死亡”现象;
4)最好使用Maxout / Leaky ReLU / ELU, 他们的效果比tanh好。
4. 代价函数
4.1 交叉熵代价函数
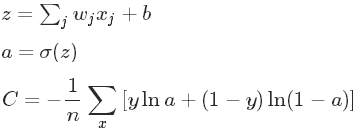
如果激活函数为sigmoid函数,则有:
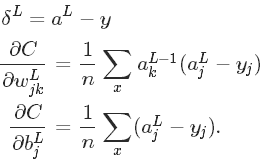
4.2 二次代价函数
如果激活函数为sigmoid函数,则有:

4.3 对数似然代价函数

从以上梯度公式中可知,对于解决学习速度慢的问题:【Softmax输出层+对数似然成本函数】与【Sigmoid输出层+交叉熵成本函数】效果相当。
5. 基本问题处理思路
5.1 减少参数数量
1)主要是减少权重参数数量,如CNN与全连接神经网络相比,通过共享权重和偏差,大大减少了权重参数的数量;从而使学习变得更加容易。
5.2 减少过拟合
5.2.1 使用强有力的规范化技术
- L1规范化
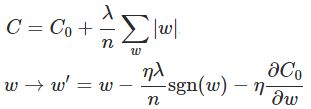
- L2规范化(或权重衰减:weight decay)
获取小的权重,且使代价函数的值最小。

- dropout(弃权)
dropout不修改代价函数,而是修改网络本身。基本思路是:保持输入和输出神经元不变,对于一个mini-batch训练样本,随机删除一半的隐层神经元,然后根据BP+SGD更新权重和偏差;然后基于另一个mini-batch做同样的操作;一直重复下去。
可以理解为训练多个神经网络,然后多个神经网络再对结果进行投票,从而排除overfitting。其目标是:在丢失部分证据的条件下,此方法同样健壮。
Dropout用于训练大的深度网络很有用,因为在此类网络中,overfitting问题非常严重。
- 卷积层
共享权重:意味着卷积滤波器被强制从整个图像中学习,于是对过拟合就有了很强的抵抗性。
- 人工扩展训练数据
5.2.2 增加训练数据的数量
5.3 加速训练
1)使用ReLU而不是Sigmoid,可以加速训练。
5.4 训练时间长
1)可通过GPU来进行长期训练。
5.5 学习速度下降
1)使用正确的代价函数(如交叉熵代价函数):避免梯度消失或爆炸,即梯度不稳定问题。
2)使用好的权重初始化:避免神经元饱和。
参考:http://www.cnblogs.com/tornadomeet/tag/Deep%20Learning/