阿里+中科院提出:将角度margin引入到对比学习目标函数中并建模句子间不同相似程度...
![]()
作者:李加贝 (浙江工商大学)
方向:跨模态搜索

标题:A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Space -- ACL2022
链接:https://aclanthology.org/2022.acl-long.336v2.pdf
虽然bert等预训练语言模型取得了巨大的成功,但直接使用它们的句子表征往往会导致在语义文本相似度任务上表现不佳。近年来,人们提出了几种比较学习方法来学习句子表征,并取得了良好的结果。但它们大多集中在正、负对的构建上,对NT-Xent这样的训练目标关注较少,不足以获得判别能力,也无法对句子间语义的部分语义顺序进行建模。在这篇论文中,作者提出了一种新的方法ArcCSE,其训练目标是增强判别能力和建模三元组句子的蕴含关系。
如图1(a),没有经过微调的预训练语言句子模型,不能很好的捕捉句子的语义含义;如图1(b),SimCSE-BERT采用NT-Xent loss,不能完全分离sb和sc。此外,目前的优化目标只是从两两的角度对句子关系进行建模,试图将语义相似的句子拉得更近,将语义不相似的句子推得更远。但是,相关句子之间存在着不同程度的语义相似,如图1(d),sb比sc与sa更加相似。目前的优化目标缺少这样建模句子间语义关系的能力。
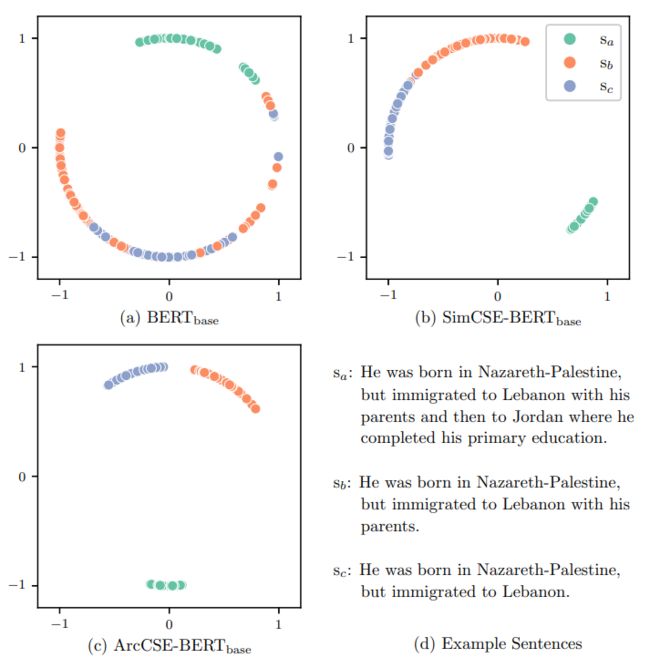 图1
图1
模型
 ArcCSE
ArcCSE
基于对比学习的角度Margin
给定一个句子集合D,Following SimCSE,使用dropout作为数据增强,对于每个句子输入到预训练语言模型中两次,得到两个不同的特征作为正样本和,同batch内的其他样本作为负样本:
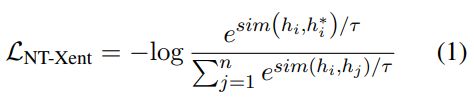 采用的是预先相似度, 为温度超参
采用的是预先相似度, 为温度超参
但是,这种损失函数没有足够的判别能力和对噪声的鲁棒性
作者使用两个特征之间的预先相似度的角度表示:
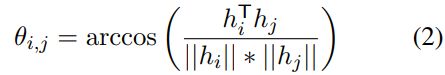 余弦相似度越大,角度越小
余弦相似度越大,角度越小
如图3所示,在NT-Xent中,的决策边界为,由于缺少decision margin,决策边界周围的小扰动可能导致错误的决策:
 图3
图3
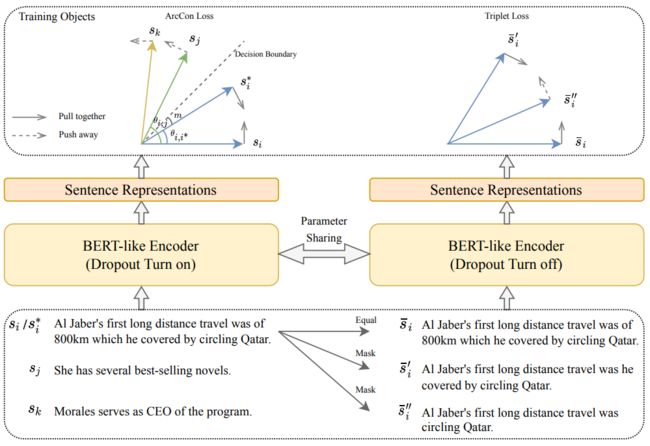
为了解决这个问题,作者在正样本和之间添加了一个angular margin m,称为Additive Angular Margin Contrastive Loss (ArcCon Loss)
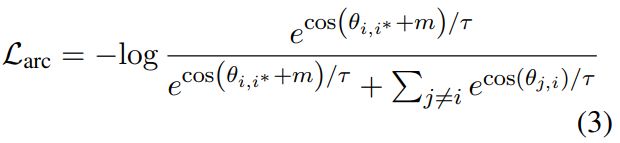
在这个损失中,决策边界为,与NT-Xent相比,它通过增加相同语义的句子表征的紧凑性和增大不同语义表征的差异性,将进一步推到变小和变大的区域。
句子三元组蕴含关系建模
之前的损失函数如NT-Xent loss,只考虑成对间句子关系,要么相似,要么不相似。但是,句子间的相似度有着不同程度的相似。为了区分不同句子之间的轻微语义差异,作者提出了一个新的自监督学习任务,对自动生成的三元组句子的蕴涵关系进行建模。

对于一个句子,对其分别掩码20%和40%得到句子和,组成一个三元组(,,), 用dropout噪声生成它们的特征可能会模糊它们的蕴涵关系,并在特征学习过程中添加不准确的信号。所以在建模三元组关系时没有使用编码器的dropout。由于与更加相似,使用三元组损失函数来建模这种关系
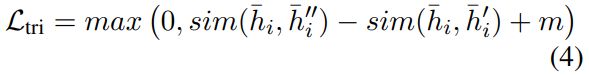
最终的目标函数为: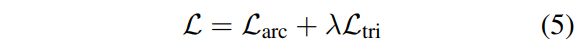
实验
对7个语义文本相似度(STS)任务进行了实验:
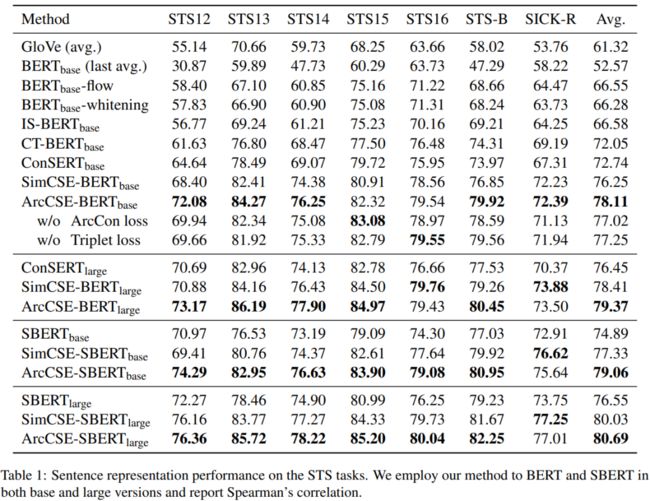
在几个监督迁移任务上进行了实验,对于每个任务,SentEval在句子嵌入的基础上训练逻辑回归分类器,并测试其在下游任务上的表现。为了进行公平的比较,作者不包括具有掩码语言建模等辅助任务的模型。

消融实验
角度Margin的影响
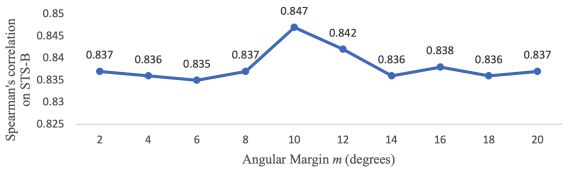
为了研究m的影响,将m从0度改变到20度,每一步增加2度。当m=10时,性能最好。因为小m可能影响不大,而大m可能会对正样本对关系建模产生负面影响。
温度的影响
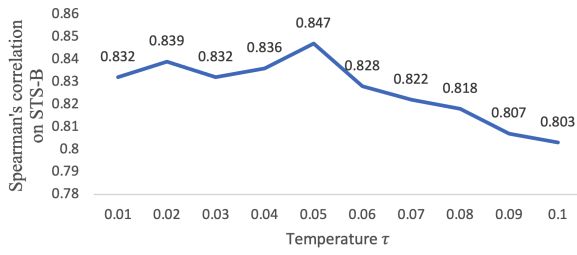
τ从0.01变化到0.1,每一步增加0.01。τ = 0.05,性能最好
Masking Ratios的影响
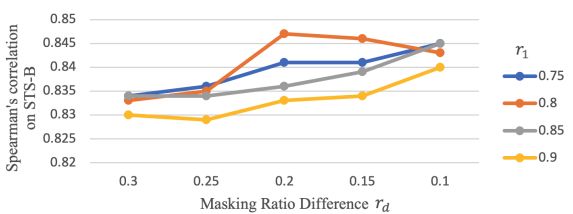
掩码率决定了蕴涵关系建模生成的句子及其语义差异。我们可以看到,与较小的掩码率相比,两种掩码率之间的较大差异往往导致较低的Spearman’s correlation。这可能是因为语义差异越大,模型越容易估计出三元组句之间的蕴涵关系,对triplet loss帮助较小。当r1=20%,r2=40%时,性能最好
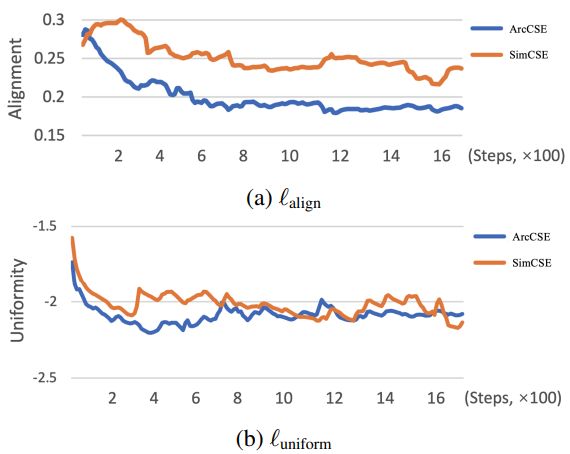
对齐和均匀性分析
对齐和均匀性是与对比学习密切相关的两个属性,可以用来衡量表征的质量。有好的对齐性的编码器可以为相似的实例生成相似的特征表示。它可以用正对实例嵌入之间的期望距离来定义
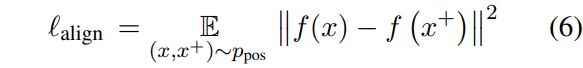
均匀性倾向于均匀分布的表示,这有助于保存最大的信息。

在STS-B development set的训练期间,每10步计算对齐和均匀度指标。结果表明,ArcCSE可以提升句子特征的质量
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
中文小样本NER模型方法总结和实战
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!