基于DFA算法实现过滤敏感词
该篇文章主要是记录我在实现敏感词过滤的实现,
通常我们如果对于敏感词过滤的话,首先想到的肯定是,把敏感词库制成一个数组或List,然后循环查询该list或数组,然后判断该次循环的敏感词是否在传入的字符串中,这种方法我们一看就知道很浪费时间与内存。
那么我们看看DFA算法(执行速度很快不需要我们异步判断处理):
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA中不会有从同一状态出发的两条边标志有相同的符号。
我的实现是参照这篇文章,
实现上大致相同,但是有一些区别,主要解决在实现是出现的一些问题,下面会详细解释.
首先我们需要根据敏感词库构造一个树,敏感词库我们可以维护一个配置文件,也可以直接存储到数据库,不过我建议直接存储数据库比较好,因为这样日后的删减维护都比较方便。
那么我们构造数据的原理是什么呢,下面我用几个个词来描述
我们、我是、我们是、我们不是、测试、测试Ap
这几个词所构成的树如下图所示:
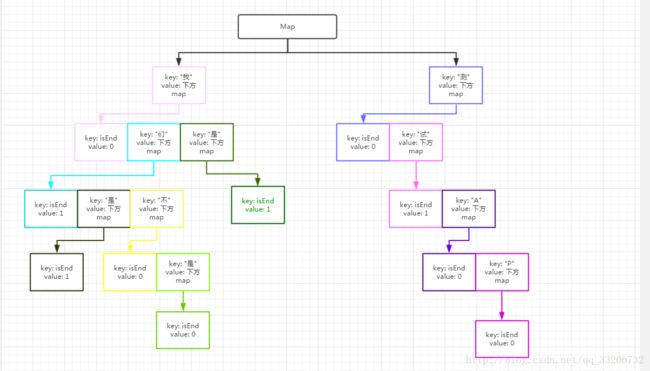
如果你拿着敏感词根据上图走一遍,我感觉你应该对于树的构成原理应该就比较清楚了。
如果是json格式,那么是这样的:
{
"我": {
"们": {
"isEnd": "1",
"不": {
"isEnd": "0",
"是": {
"isEnd": "1" }
},
"是": {
"isEnd": "1"
}
},
"是": {
"isEnd": "1"
},
"isEnd": "0"
},
"测": {
"试": {
"A": {
"p": {
"isEnd": "1" },
"isEnd": "0"
},
"isEnd": "1"
},
"isEnd": "0"
}
}具体逻辑我就不说了,如果还不懂的话可以看示例代码:
private static void addSensitiveMap(Set sensitiveSet) {
sensitiveMap = new HashMap(sensitiveSet.size());
String key = null;
Map nowMap = null;
Map nowWorMap = null;
Iterator ite = sensitiveSet.iterator();
while (ite.hasNext()){
key = ite.next();
nowMap = sensitiveMap;
for (int i = 0;ichar keyChar = key.charAt(i);
Object wordMap = nowMap.get(keyChar);
if (wordMap != null){
nowMap = (Map) wordMap;
}else{
nowWorMap = new HashMap();
nowWorMap.put("isEnd","0");
nowMap.put(keyChar,nowWorMap);
nowMap = nowWorMap;
}
if (i == key.length() - 1){
nowMap.put("isEnd","1");
}
}
}
} 这个代码和我参考的那篇文章是一致的。这里就不多说了(总是要研究的,不研究你也不敢用是吧-。-)。
然后就是我们的如何过滤一段话了,这里我和参考的文章不一致,文章是有敏感词就返回,而我需要把所有敏感词都要拉出来,先看示例代码(先别复制,下面这段有bug的):
private static List checkSensitive(String testString) {
//去除无意义字符
testString= testString.replaceAll(" ", "");
char[] test = testString.toCharArray();
int start = 0;//用于截取字符串的开始位置
Map nowMap = sensitiveMap;
List senList = new ArrayList<>();
for (int i = 0 ; i < test.length ; i ++){
nowMap = (Map)nowMap.get(test[i]);//获取
if (nowMap == null){//如果没获取到该字符下的数组,直接返回,开始下一轮循环
start = i+1;
nowMap = sensitiveMap;
continue;
}else{//获取到Map,说明该字符为敏感词库中的数据
if ("1".equals(nowMap.get("isEnd"))){//如果该词结束,将该敏感词填入列表中,并初始化开始数
senList.add(testString.substring(start,i+1)+start);
start = i+1;
nowMap = sensitiveMap;
}
}
}
return senList;
} 判断的逻辑比较简单,就是先把字符串过滤一下去除空字符串和一些无意义字符,去除无意义字符你可以使用正则表达式,比如下面的只留中文、英文、数字:
testString= testString.replaceAll(“[^(a-zA-Z0-9\u4e00-\u9fa5)+]”, “”);
然后我们将字符串转为字符数组,
定义一个int变量,用于当确定遍历的词为敏感词时,用于截取字符,
一个初始为敏感词树的nowMap ,用于在遍历中map的转换(这个值在遍历中会不停的变化的,它的变化非常重要),
一个List用于存储查询到的敏感词
遍历字符数组,从nowMap 中获取key为当前循环的字符的value值,
如果没获取到value值,说明敏感词树里面没有以该词开始的敏感词,那么我们维护start数和初始化nowMap。
如过能获取到value值,先判断isEnd是否为1,如果为1的话说明该敏感词结束,也就说明了从start到该次循环的字符所组成的字符串为敏感词,将敏感词放入List,并维护start值,初始化nowMap。
上面的逻辑看着没什么问题,但是有一个bug,就是如果“我们是程序猿,测试”是两个敏感词,那么有这么一个字符串“他说我们是测试”,那么按照上面的逻辑就会出现问题,“测试”是过滤不出来的。因为我们过滤到“是”的时候获取的map是“是”下面的map,里面的isEnd为0,那么不做处理继续下一循环“测”字符,因为map中是没有“测”这个key的数据的,所以我们走的是nowMap == null;那么这个就过了,就直接下一循环了”试”。这样“测试”这个就会华丽的逃掉了。
那么什么情况下会出现这样的情况呢,就是我们正在一个敏感词的下面的数据过滤中,还没过滤完,直接出现了另一个敏感词,就会出现这种情况。
那么我们如何解决呢?
看这段修改的代码:
private static List checkSensitive(String testString) {
//去除无意义字符
testString= testString.replaceAll("[^(a-zA-Z0-9\\u4e00-\\u9fa5)+]", "");
char[] test = testString.toCharArray();
int start = 0;//用于截取字符串的开始位置
int senStart = 0;//敏感字符开始
Map nowMap = sensitiveMap;
boolean flag = false;
List senList = new ArrayList<>();
for (int i = 0 ; i < test.length ; i ++){
nowMap = (Map)nowMap.get(test[i]);//获取
if (nowMap == null){//如果没获取到该字符下的数组,直接返回,开始下一轮循环
if (flag){
i = senStart;
flag = false;
}
senStart = start = i+1;
nowMap = sensitiveMap;
continue;
}else{//获取到Map,说明该字符为敏感词库中的数据
flag = true;
if ("1".equals(nowMap.get("isEnd"))){//如果该词结束,将该敏感词填入列表中,并初始化开始数
senList.add(testString.substring(start,i+1)+start);
start = i+1;
flag = false;
nowMap = sensitiveMap;
}
}
}
return senList;
} 这里我加了两个参数senStart 、flag ,
senStart初始为0,用于标注当前判断到哪个敏感字符了。
flag初始为false,用于当前循环是否是对于一个疑似敏感词的过滤的开始。
上面这种逻辑是一个字符一个字符的判断是否以有以该字符开始的敏感词,如果有就继续下去,无论以该字符下面的几个字符组成的字符串是否为敏感词,下一次敏感词都已该字符的下一字符开始判断。
上面描述的比较模糊,希望大家看代码能看懂,就不画图了-。-
下面是我的测试代码:
package com.binggou.circle.BinggouCircle;
import com.alibaba.fastjson.JSONObject;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.*;
/**
* Created by yefuliang on 2017/11/3.
*/
public class test {
public static Map sensitiveMap = null;
public static void main(String[] args){
String sensitive = txt2String();
Set sensitiveSet = new HashSet<>();
Collections.addAll(sensitiveSet,sensitive.split(","));
System.out.println("---------1-----------"+System.currentTimeMillis());
addSensitiveMap(sensitiveSet);
System.out.println("---------2-----------"+System.currentTimeMillis());
System.out.println(JSONObject.toJSONString(sensitiveMap));
String testString = "是雅昌就山本五十六日本";
Long start = System.currentTimeMillis();
List senList = checkSensitive(testString);
Long end = System.currentTimeMillis();
System.out.println("---------敏感词校验处理时间-----------"+(end - start));
System.out.println(JSONObject.toJSONString(senList));
}
private static List checkSensitive(String testString) {
//去除无意义字符
testString= testString.replaceAll("[^(a-zA-Z0-9\\u4e00-\\u9fa5)+]", "");
char[] test = testString.toCharArray();
int start = 0;//用于截取字符串的开始位置
int senStart = 0;//敏感字符开始
Map nowMap = sensitiveMap;
boolean flag = false;
List senList = new ArrayList<>();
for (int i = 0 ; i < test.length ; i ++){
nowMap = (Map)nowMap.get(test[i]);//获取
if (nowMap == null){//如果没获取到该字符下的数组,直接返回,开始下一轮循环
if (flag){
i = senStart;
flag = false;
}
senStart = start = i+1;
nowMap = sensitiveMap;
continue;
}else{//获取到Map,说明该字符为敏感词库中的数据
flag = true;
if ("1".equals(nowMap.get("isEnd"))){//如果该词结束,将该敏感词填入列表中,并初始化开始数
senList.add(testString.substring(start,i+1)+start);
start = i+1;
flag = false;
nowMap = sensitiveMap;
}
}
}
return senList;
}
private static void addSensitiveMap(Set sensitiveSet) {
sensitiveMap = new HashMap(sensitiveSet.size());
String key = null;
Map nowMap = null;
Map nowWorMap = null;
Iterator ite = sensitiveSet.iterator();
while (ite.hasNext()){
key = ite.next();
nowMap = sensitiveMap;
for (int i = 0;ichar keyChar = key.charAt(i);
Object wordMap = nowMap.get(keyChar);
if (wordMap != null){
nowMap = (Map) wordMap;
}else{
nowWorMap = new HashMap();
nowWorMap.put("isEnd","0");
nowMap.put(keyChar,nowWorMap);
nowMap = nowWorMap;
}
if (i == key.length() - 1){
nowMap.put("isEnd","1");
}
}
}
}
/**
* 读取txt文件的内容
* @return 返回文件内容
*/
public static String txt2String(){
File file = new File("E:/ideaWorkSpace/BinggouCircle/src/test/java/com/binggou/circle/BinggouCircle/敏感词.txt");
StringBuilder result = new StringBuilder();
try{
BufferedReader br = new BufferedReader(new FileReader(file));//构造一个BufferedReader类来读取文件
String s = "";
while((s = br.readLine())!=null){//使用readLine方法,一次读一行
result.append(System.lineSeparator()+s);
}
br.close();
}catch(Exception e){
e.printStackTrace();
}
return result.toString();
}
}