Springboot集成(整合)JPA(maven项目)
1、什么是JPA(spring data jpa)
JPA由EJB 3.0软件专家组开发,作为JSR-220实现的一部分。但它又不限于EJB 3.0,你可以在Web应用、甚至桌面应用中使用。JPA的宗旨是为POJO提供持久化标准规范,由此可见,经过这几年的实践探索,能够脱离容器独立运行,方便开发和测试的理念已经深入人心了。Hibernate3.2+、TopLink 10.1.3以及OpenJPA都提供了JPA的实现。
JPA仅仅是一种规范,也就是说JPA仅仅定义了一些接口,而接口是需要实现才能工作的。所以底层需要某种实现,而Hibernate(与mybaits相比是全自动的)就是实现了JPA接口的ORM框架。
说再直白一点,就是就是Spring的亲儿子,而mybatis不是,JPA可以帮我们自动写好相关的SQL语句以及映射关系。
2、项目实现
1.项目结构图示
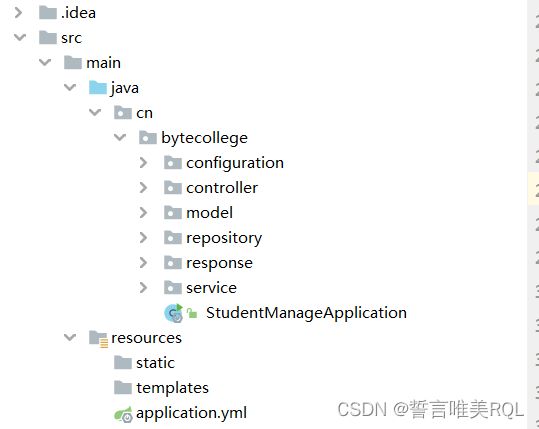
2.首先在pom中导入jpa以及mysql的相关依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
3.在application.yml中配置mysql数据库以及jpa
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/student?serverTimezone=Asia/Shanghai
username: root
password: root
jpa:
show-sql: true
properties:
hibernate:
enable_lazy_load_no_trans: true
mvc:
pathmatch:
matching-strategy: ANT_PATH_MATCHER
4.查看数据库信息

这里需要说明的是我们在MySql中新建数据库,命名为student,不需要自己去建表,运行项目后会自动生成相关的表,但是自己创建也是可以的。
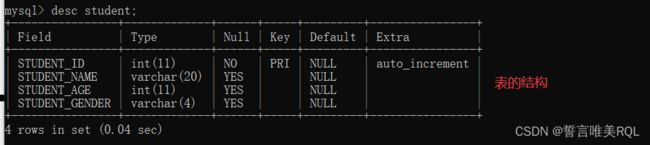
5.编写model层,也就是大家常说的实体,我这里数据库中存在student表,然后编写Student.java如下:
@Table(name ="student") //标明数据库表名,需要跟数据库中的名字一致
@Entity //指定此类为实体类
@Data //lombok注解,帮我们自动编写setting、getting等
public class Student {
@Id //表明该属性为表的主键
@GeneratedValue(strategy = GenerationType.IDENTITY) //主键的生成策略
private Integer studentId;
@Column(name = "student_name") //数据库中的字段
private String studentName;
@Column(name = "student_gender") //数据库中的字段
private String studentGender;
@Column(name = "student_age") //数据库中的字段
private Integer studentAge;
6.编写controller层,StudentController.java类
@Controller
public class StudentController {
@Autowired
private StudentService studentService;
//这里只演示分页查询所有学生数据
@GetMapping("/studentList")
@ResponseBody//该注解会将方法的返回值转换为json,并返回界面
//pageIndex为当前页面,pageSize为每页条数
public List<Student> findAll(Integer pageIndex, Integer pageSize){
List<Student> list = studentService.findAll(pageIndex, pageSize);
return list;
}
}
7.编写service层,StudentService.java类
@Service
public class StudentService {
@Autowired
private StudentRepository studentRepository;
//StudentRepository相当于用mybaits框架时的StudentMapper接口
/**
* 分页查询
* @param pageIndex
* @param pageSize
* @return
*/
public List<Student> findAll(Integer pageIndex,Integer pageSize){
Pageable pageable = (pageIndex==null&&pageSize==null)?PageRequest.of(0,5):PageRequest.of(pageIndex,pageSize);
Page<Student> page = studentRepository.findAll(pageable);
return page.getContent();
}
}
8.编写repository层,实现StudentRepository接口
@Repository //@Repository,表示包含增删改查等功能的接口
//这里需要注意的是,<>中的Student表示实体模型,Integer代表主键类型。
public interface StudentRepository extends JpaRepository<Student,Integer> {
}
到此JPA的整合就完成了,不需要我们去编写SQL语句跟映射层,jpa里面内置了相关的增删改查方法。
9.结果展示
启动springboot的启动类
我们查询出来了全部的结果

因为我们没有编写视图层,@ResponseBody该注解会将方法的返回值转换为json,并返回界面
到此你就能简单的使用jpa了,但是为了提升自己,我们去看一下相关的源码。
3、深入挖掘
我们打开JpaJpaRepository接口看到下面的代码,发现里面实现了很多的CRUD接口,这里面需要我们注意SaveXXX接口,它会先去查找数据库是否存在该记录,如果不存在则会新增,否则起到修改的作用。
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
/** @deprecated */
@Deprecated
default void deleteInBatch(Iterable<T> entities) {
this.deleteAllInBatch(entities);
}
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
/** @deprecated */
@Deprecated
T getOne(ID id);
T getById(ID id);
<S extends T> List<S> findAll(Example<S> example);
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
同时我们需要知道的是,我们发现这里面没有存在通过某种条件查询相关的数据,这是需要我们自己在相关的repository层对应的接口中编写凑想方法的,比如在StudentRepository接口中编写一个根据学生姓名进行查找,其他地方不需要做修改,剩下的JPA能自动的帮我们做。需要注意的是,查询时的方法开头必须用findByxxx或getByxxx,当有多个条件查询时,可以用And连接
public interface StudentRepository extends JpaRepository<Student,Integer> {
Student findByStudentName(String StudentName);
}
感兴趣的同学,可以继续挖掘每一个接口,或者打断点测试,这里因为篇幅问题,将不再继续描述。