Android音视频【一】H264编码基础
人间观察
岁月催人,时间过的太快了
音视频编码解码就是指通过特定的压缩/解压技术,将某个音视频格式的数据转换为另一种音视频格式数据。目前在Android中的音视频用的最多的就是H264+aac的方式进行编码和解码,其实不止Android,H264在整个音视频领域都是使用最广泛的编码方式。H264是新一代的编码标准,以高压缩高质量和支持多种网络的流媒体传输。当然还有比H264更好的H265编码,H265是基于H264优化的。
1.H264标准的演进
国际上主流制定视频编解码技术的组织有两个,一个是国际电联(ITU-T),它制定的标准有H.261、H.263、H.263+、H.264等。
一个是**国际标准化组织(ISO)**它制定的标准有MPEG-1、MPEG-2、MPEG-4等。他们各自发展,随着时间的推移这两个基友融在一起了,推出了H.264/MPEG-4 AVC,他们都保留了各自的叫法,在ITU-T这边叫做H.264,在ISO那边叫MPEG-4 AVC。所以你在电脑上看视频文件(如果是h264编码的话)的简介都是H.264/MPEG-4 AVC,但是在代码中不是h264而是avc,哈哈。简单了解下h264标准的形成就行。
2.前提
我们为什么要进行编码呢?这个要搞清楚,因为原始数据太大了,举个例子比如android 摄像头采集视频的分辨率是720*1280,帧率是30fps,YCbCr_420_SP(NV21) ,那1s的数据大小是:
720 *1280*1.5byte(12 bits per pixel)*30(张图片)/1024/1024=40mb。如果这1s的数据进行网络传输和磁盘保存是非常不合理的,除非电影院的视频,电影院的视频都是原始的,一部电影上1000G,好家伙,简直就是在放高清图片。666
所以我们要经过压缩,其中就是h264的压缩,编码的时候经过去掉图像内的冗余和保留图像之间的差异的数据进行传输/保存,解码的时候进行还原即可。这就是我们的先辈们努力了10多年的成果。
这篇是理论,尽可能的保留所谓的官方概念。也会加入自己的理解。
3.H264相关概念
h264中有很多很多的概念,这些很重要。下面的3个帧的总结来自有关书籍也加入了自己的理解,如果我只写自己的理解可能会导致真正意义上的丢失,所以我这里还是保留了,大家可以细细品读这3个帧的描述。
3.1 帧 Frame
简单的理解帧就是为视频或者动画中的每一张画面,而视频和动画特效就是由无数张画面组合而成,每一张画面都是一帧。
3.2 三种视频帧
分为I 帧 B帧 P帧,当然是编码后数据。
3.2.1 I 帧
I 帧是帧内编码帧,I 帧是完整帧,可以理解为一副画面的完整保留,当然也不是保留最原始数据,删掉了人眼不敏感的数据(人眼对色度不敏感对亮度敏感),解码时只需要本帧数据就可以完成,就可以出来画面,直播秒开就是这个原理,首帧为I帧,配合云端缓存最近的I帧。
I 帧特点:
- 它是一个全帧压缩编码帧,它将全帧的图像进行jpeg压缩编码
- 既然是完整的图像那所占数据的信息量比较大
- 解码时仅用I帧的数据就可以重构完整图像
- 不需要参考其他画面进行编码生成
- I 帧是序列gop的基础帧(第一帧),在一个gop里只有一个I 帧
- I 帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量),如果I帧质量不行,那这个序列质量都不行。
- I 帧描述了图像背景和运动主体的详情
总之,I 帧很nb,I 帧越多说明该视频画面变换多越复杂。
3.2.2 P帧-前向预测编码帧
P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧的画面差别的数据)。
P帧的预测与重构:P帧是以 I 帧为参考帧,在 I 帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端根据运行矢量从 I 帧找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
P帧的特点:
- P帧是 I 帧后面相隔1~2帧的编码帧
- P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差)
- 解码时必须将i帧中的预测值与预测误差求和后才能重构完整的P帧图像
- P帧属于前向预测的帧间编码。它只参考前面最靠近它的 I 帧或P帧
- 由于P帧是参考帧,它可能造成解码错误的扩散。也就是说如果p帧解码失败了,一组内的gop后面的b帧/p帧失败。它最多也就影响一个gop序列。
- 由于是差值传送,P帧的压缩比较高。
总之,p帧就是差别帧,p帧越多,说明画面变化不多。
3.2.3 B帧-双向预测内插编码帧
B帧是双向差别帧,也就是B帧记录的是本帧与前后帧的差别,要解码B帧。不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码时费时间,如果是软解码就耗cpu了。
B帧的预测与重构
B帧以前面的 I 或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。接收端根据运动矢量在两个参考帧中“找出(算出)”预测值并与差值求和,得到B帧“某点”样值,从而可得到完整的B帧。
B帧的特点:
- B帧是由前面的 I 或P帧和后面的P帧进行预测的
- B帧传送的是它与前面的 I 或P帧和后面的P帧之间的预测误差及运动矢量
- B帧是双向预测编码帧
- B帧压缩比最高,因为它只反映并参考帧间运动主体的变化情况,预测比较准确
- B帧不是参考帧,不会造成解码错误的扩散
总之,b帧数据较小,b帧越多,视频越小。
注:I、B、P帧是根据压缩算法是人为定义的,一般来说,帧的压缩率是7(跟JPG差不多),P帧是20,B帧可以达到50。
3.3 GOP/序列
Group of picture(图像组)。
在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内,我们认为这样的图可以分到一组。在这样一组帧中,经过h264编码后,只保留第一帧的完整数据,其它帧都通过参考上一帧计算出来。我们称第一帧为IDR/I帧,其它帧我们称为P/B帧,这样编码后的数据帧组我们称为GOP。GOP如下,图片来源网络:
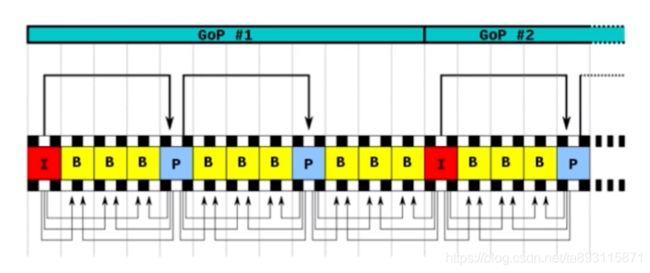
当视频的元素运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面内容的变动很小,所以就可以是一个I帧,然后是P帧B帧。如果变化很大,比如图片形成的视频,一个序列可能就比较短了,可能就包含一个i帧,几个P帧B帧了。
3.4 IDR图像
1个序列的第一个图像叫做IDR图像(立刻刷新图像),IDR图像都是I帧图像。h264引入IDR图像是为了解码的重新同步,当解码器解码到IDR图像时,立刻将参考帧队列清空,将已经解码的全部输出或者抛弃,重新查找下一个参数集,开始解码下一个新的序列。这样当钱一个序列出现重大错误,在这里可以重新获得同步的机会。IDR图像之后的图像不会使用IDR之前图像的数据进行解码。
所以说IDR图像都是I帧,但是I帧不一定是IDR图像。
3.5 DTS和PTS
DTS: Decode Time Stamp,表示读入内存的比特流在什么时候开始送入解码器中进行解码。解码的顺序
PTS: Presentation Time Stamp,表示解码后的视频帧什么时候被显示出来,显示顺序。
图片来源网络:
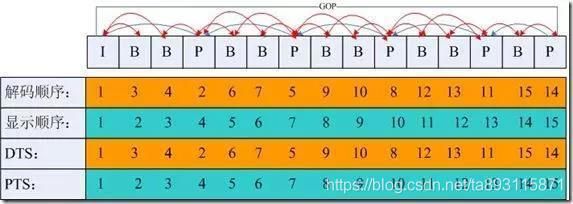
因为B帧需要前后的帧(前面的 I 或P帧和后面的P帧)才能解出图像。也就是说一组GOP必须解码出I帧P帧后才能解码出来B帧,并不是B帧的数据先到了就先解码b帧的数据
3.6 宏块/MB(Macroblock)
就是图像中的一小块区域。h264位了压缩而采用的一种划分方法。
H264编码器为每一幅图片划分宏块,默认是使用 16X16 大小的区域作为一个宏块,也可以划分成 8X8 大小。一般比较平坦的图像使用 16X16 大小的宏块,为了更高的压缩率在在16X16 的宏块上分出更小的子块。子块的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4
4.H264的压缩原理
我个人理解这个代码实现是很复杂的,发展了10几年才稳定成熟。不用你手写实现也不用关注特别细的实现,但是需要了解下它的基本原理,压缩的过程,采用的方法进行的视频压缩。
4.1压缩技术
简单点说就是:视频数据主要分为两类数据冗余,一个是时间上的冗余,一个是空间上的冗余。分别对其进行压缩,压缩技术我们分别叫做帧间压缩技术和帧内压缩技术。
时间上: 将一定时间内视频图像运动变化不大关联性性很强的进行分组(GOP),然后对这组序列进行编码,只保留第一帧的完整数据,其它帧都通过参考上一帧计算出来。那第一帧为IDR/I帧,其它帧为P/B帧,这样编码后的数据帧组我们称为GOP。压缩过程中有运动矢量与补偿算法和划分宏块(MB)以及对宏块的处理压缩。当下一组视频内的图像变化很大的时候又是一组新的GOP,反复循环。这种我们就叫帧间压缩技术,解决的是时域数据冗余问题。
空间上:对视频图像划分宏块,H264对比较平坦的图像使用 16X16 大小的宏块,可以在16x16的基础上更细粒度的划分,这样再经过帧内压缩,得到更高效的数据。这种我们就叫帧内压缩技术,解决的是空域数据冗余问题。
帧间压缩和帧内压缩后还需要进行压缩,比如:
还有编码上冗余:根据不同像素值出现的概率不同进行算法处理
还有视觉冗余:人的视觉系统对某些细节不敏感就可以适当的删减
基本原理参考这篇文章https://zhuanlan.zhihu.com/p/31056455
介绍了些h264的基本知识和有关概念,h264的知识远远不止这些。如有描述不准确欢迎指正。下篇介绍h264数据流格式以及如何在Android中硬解码播放h264码流。