caffe不支持relu6_【完结】12大深度学习开源框架(caffe,tf,pytorch,mxnet等)快速入门项目...


这是一篇总结文,给大家来捋清楚12大深度学习开源框架的快速入门,这是有三AI的GitHub项目,欢迎大家star/fork。
https://github.com/longpeng2008/yousan.ai

1 概述
1.1 开源框架总览
现如今开源生态非常完善,深度学习相关的开源框架众多,光是为人熟知的就有caffe,tensorflow,pytorch/caffe2,keras,mxnet,paddldpaddle,theano,cntk,deeplearning4j,matconvnet等。
如何选择最适合你的开源框架是一个问题。有三AI在前段时间里,给大家整理了12个深度学习开源框架快速入门的教程和代码,供初学者进行挑选,一个合格的深度学习算法工程师怎么着得熟悉其中的3个以上吧。
下面是各大开源框架的一个总览。
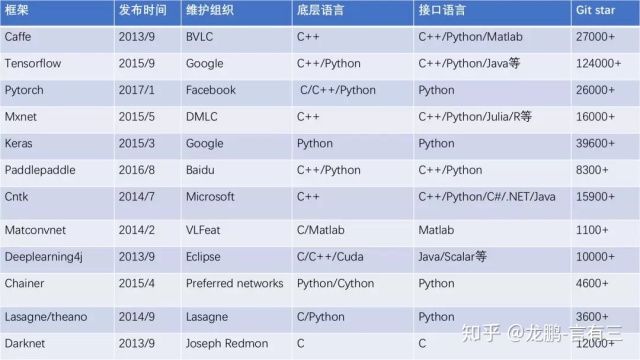
在这里我们还有一些框架没有放上来,是因为它们已经升级为大家更喜欢或者使用起来更加简单的版本,比如从torch->pytorch,从theano到lasagne。另外这些框架都支持CUDA,因此编程语言这里也没有写上cuda。
在选择开源框架时,要考虑很多原因,比如开源生态的完善性,比如自己项目的需求,比如自己熟悉的语言。当然,现在已经有很多开源框架之间进行互转的开源工具如MMDNN等,也降低了大家迁移框架的学习成本。
除此之外还有tiny-dnn,ConvNetJS,MarVin,Neon等等小众,以及CoreML等移动端框架,就不再一一介绍。
总的来说对于选择什么样的框架,有三可以给出一些建议。
(1) 不管怎么说,tensorflow/pytorch你都必须会,这是目前开发者最喜欢,开源项目最丰富的两个框架。
(2) 如果你要进行移动端算法的开发,那么Caffe是不能不会的。
(3) 如果你非常熟悉Matlab,matconvnet你不应该错过。
(4) 如果你追求高效轻量,那么darknet和mxnet你不能不熟悉。
(5) 如果你很懒,想写最少的代码完成任务,那么用keras吧。
(6) 如果你是java程序员,那么掌握deeplearning4j没错的。
其他的框架,也自有它的特点,大家可以自己多去用用。
1.2 如何学习开源框架
要掌握好一个开源框架,通常需要做到以下几点:
(1) 熟练掌握不同任务数据的准备和使用。
(2) 熟练掌握模型的定义。
(3) 熟练掌握训练过程和结果的可视化。
(4) 熟练掌握训练方法和测试方法。
一个框架,官方都会开放有若干的案例,最常见的案例就是以MNISI数据接口+预训练模型的形式,供大家快速获得结果,但是这明显还不够,学习不应该停留在跑通官方的demo上,而是要解决实际的问题。
我们要学会从自定义数据读取接口,自定义网络的搭建,模型的训练,模型的可视化,模型的测试与部署等全方位进行掌握。
因此,我们开设了一个《2小时快速入门开源框架系列》,以一个图像分类任务为基准,带领大家一步一步入门,后续会增加分割,检测等任务。
这是一个二分类任务,给大家准备了500张微笑表情的图片、500张无表情的图片,放置在git工程的data目录下,图片预览如下,已经全部缩放到60*60的大小:
这是无表情的图片:

这是微笑表情的图片。
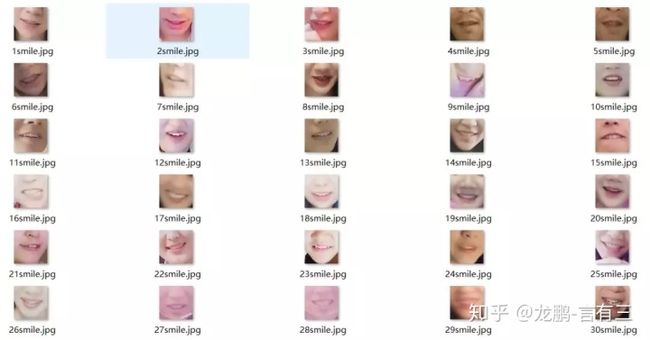
因此,我们的目标就是利用这500张图片完成好这个图像分类任务。
在下面的所有框架的学习过程中,我们都要完成下面这个流程,只有这样,才能叫做真正的完成了一个训练任务。

另外,所有的框架都使用同样的一个模型,这是一个3层卷积+2层全连接的网络,由卷积+BN层+激活层组成,有的使用带步长的卷积,有的使用池化,差别不大。
输入图像,48*48*3的RGB彩色图。
第一层卷积,通道数12,卷积核3*3。
第二层卷积,通道数24,卷积核3*3。
第三层卷积,通道数48,卷积核3*3。
第一层全连接,通道数128。
第二层全连接,通道数2,即类别数。
网络结构如下:
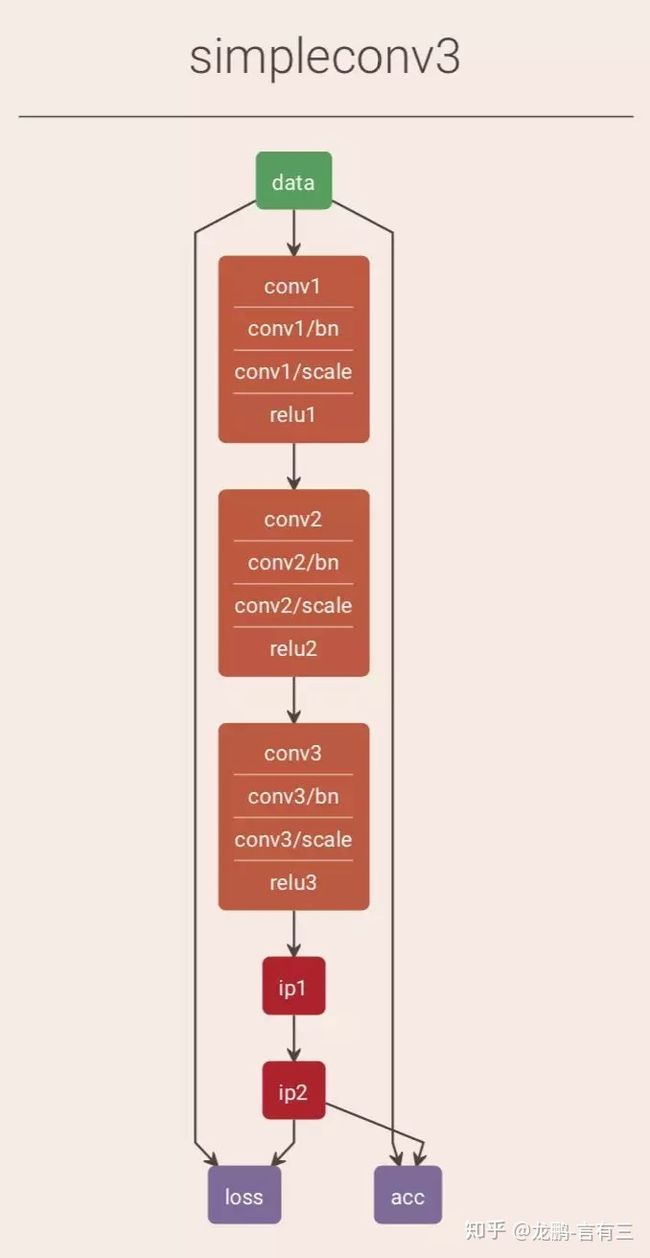
这是最简单的一种网络结构,优化的时候根据不同的框架,采用了略有不同的方案。因为此处的目标不是为了比较各个框架的性能,所以没有刻意保持完全一致。
2 开源框架
下面我们开始对各个框架进行简述。
2.1 Caffe
github地址:https://github.com/BVLC/caffe。
(1) 概述:
Caffe是伯克利的贾扬清主导开发,以C++/CUDA代码为主,最早的深度学习框架之一,比TensorFlow、Mxnet、Pytorch等都更早,需要进行编译安装。支持命令行、Python和Matlab接口,单机多卡、多机多卡等都可以很方便的使用。目前master分支已经停止更新,intel分支等还在维护,caffe框架已经非常稳定。
(2)caffe的使用通常是下面的流程:

以上的流程相互之间是解耦合的,所以caffe的使用非常优雅简单。
(3) caffe有很明显的优点和缺点。
优点:
- 以C++/CUDA/python代码为主,速度快,性能高。
- 工厂设计模式,代码结构清晰,可读性和拓展性强。
- 支持命令行、Python和Matlab接口,使用方便。
- CPU和GPU之间切换方便,多GPU训练方便。
- 工具丰富,社区活跃。
缺点:
- 源代码修改门槛较高,需要实现前向反向传播,以及CUDA代码。
- 不支持自动求导。
- 不支持模型级并行,只支持数据级并行
- 不适合于非图像任务。
鉴于caffe的学习有一定门槛,我给新手们提供一个自己录制的视频。
有三说深度学习 - 网易云课堂study.163.com其他框架后续也会录制,完整的系列视频在网易云上,见《有三说深度学习》。
同时可以看下面的快速入门文档,以及阅读相关的源代码。
【caffe速成】caffe图像分类从模型自定义到测试mp.weixin.qq.com
2.2 Tensorflow
github地址:https://github.com/tensorflow/tensorflow。
(1) 概述
TensorFlow是Google brain推出的开源机器学习库,可用作各类深度学习相关的任务。
TensorFlow = Tensor + Flow,Tensor就是张量,代表N维数组,这与Caffe中的blob是类似的;Flow即流,代表基于数据流图的计算。
(2) 特点
TensorFlow最大的特点是计算图,即先定义好图,然后进行运算,所以所有的TensorFlow代码,都包含两部分:
- 创建计算图,表示计算的数据流。它做了什么呢?实际上就是定义好了一些操作,你可以将它看做是Caffe中的prototxt的定义过程。
- 运行会话,执行图中的运算,可以看作是Caffe中的训练过程。只是TensorFlow的会话比Caffe灵活很多,由于是Python 接口,取中间结果分析,Debug等方便很多。
目前tensorflow已经更新到2.0,由于精力原因,笔者的代码仍然以1.x版本为例。
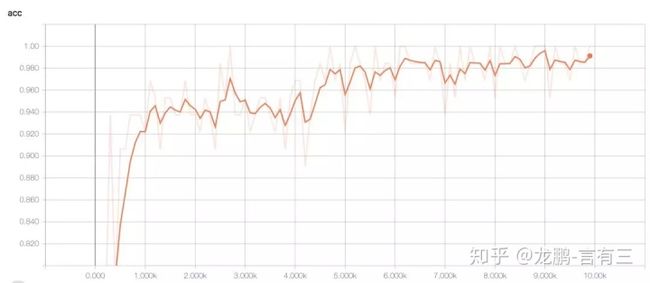
2.3 Pytorch
github地址:https://github.com/pytorch/pytorch。
(1) 概述:一句话总结Pytorch = Python + Torch。
Torch是纽约大学的一个机器学习开源框架,几年前在学术界非常流行,包括Lecun等大佬都在使用。但是由于使用的是一种绝大部分人绝对没有听过的Lua语言,导致很多人都被吓退。后来随着Python的生态越来越完善,Facebook人工智能研究院推出了Pytorch并开源。Pytorch不是简单的封装Torch 并提供Python接口,而是对Tensor以上的所有代码进行了重构,同TensorFlow一样,增加了自动求导。
后来Caffe2全部并入Pytorch,如今已经成为了非常流行的框架。很多最新的研究如风格化、GAN等大多数采用Pytorch源码。
(2) 特点
- 动态图计算。TensorFlow从静态图发展到了动态图机制Eager Execution,pytorch则一开始就是动态图机制。动态图机制的好处就是随时随地修改,随处debug,没有类似编译的过程。
- 简单。相比TensorFlow1.0中Tensor、Variable、Session等概念充斥,数据读取接口频繁更新,tf.nn、tf.layers、tf.contrib各自重复,Pytorch则是从Tensor到Variable再到nn.Module,最新的Pytorch已经将Tensor和Variable合并,这分别就是从数据张量到网络的抽象层次的递进。有人调侃TensorFlow的设计是“make it complicated”,那么 Pytorch的设计就是“keep it simple”。
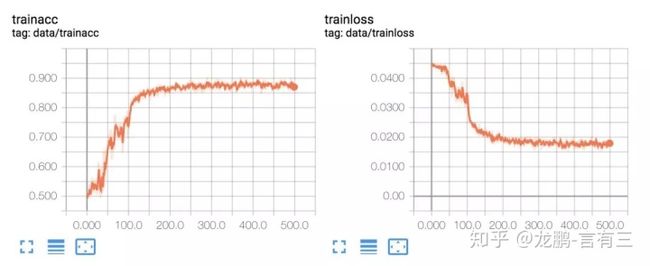
2.4 Mxnet
github地址:https://github.com/apache/incubator-mxnet。
(1) 概述
Mxnet是由李沐等人领导开发的非常灵活,扩展性很强的框架,被Amazon定为官方框架。
(2) 特点
Mxnet同时拥有命令式编程和符号式编程的特点。在命令式编程上MXNet提供张量运算,进行模型的迭代训练和更新中的控制逻辑;在声明式编程中MXNet支持符号表达式,用来描述神经网络,并利用系统提供的自动求导来训练模型。Mxnet性能非常高,推荐资源不够的同学使用。
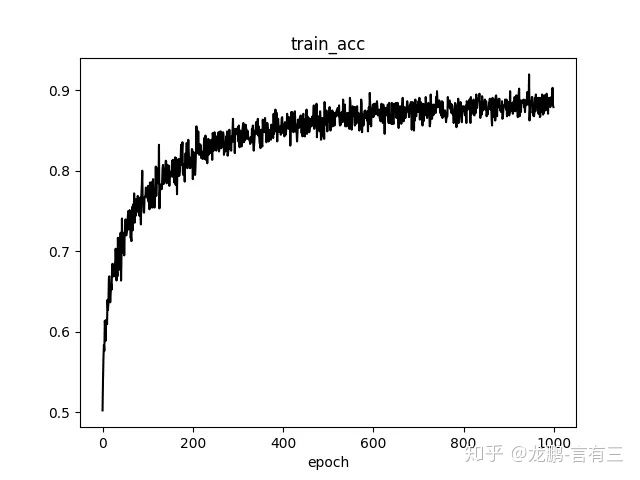
2.5 Keras
github网址:https://github.com/keras-team/keras。
(1) 概述
Keras是一个对小白用户非常友好而简单的深度学习框架,严格来说并不是一个开源框架,而是一个高度模块化的神经网络库。
Keras在高层可以调用TensorFlow,CNTK,Theano,还有更多的库也在被陆续支持中。 Keras的特点是能够快速实现模型的搭建,是高效地进行科学研究的关键。
(2) 特点
- 高度模块化,搭建网络非常简洁。
- API很简单,具有统一的风格。
- 容易扩展,只需使用python添加新类和函数。
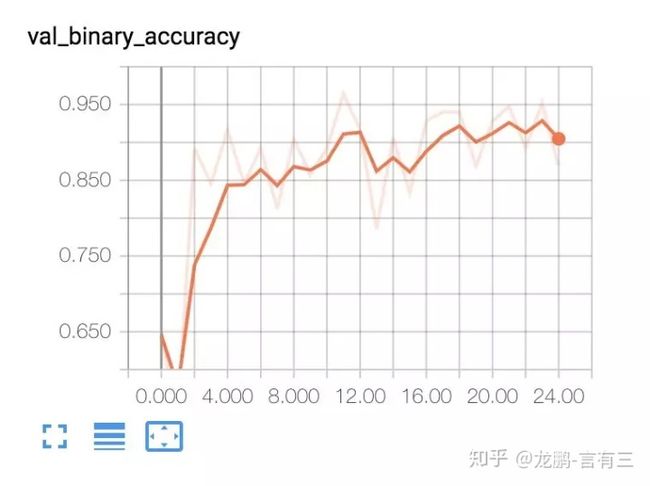
2.6 Paddlepaddle
github网址:https://github.com/PaddlePaddle/Paddle。
(1) 概述
正所谓Google有Tensorflow,Facebook有Pytorch,Amazon有Mxnet,作为国内机器学习的先驱,百度也有PaddlePaddle,其中Paddle即Parallel Distributed Deep Learning(并行分布式深度学习)。
(2) 特点
paddlepaddle的性能也很不错,整体使用起来与tensorflow非常类似,拥有中文帮助文档,在百度内部也被用于推荐等任务。另外,配套了一个可视化框架visualdl,与tensorboard也有异曲同工之妙。国产框架不多,大家多支持啊!
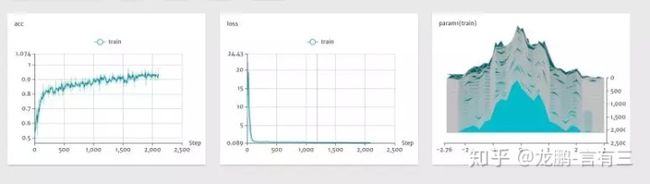
2.7 CNTK
github地址:https://github.com/Microsoft/CNTK。
(1) 概述
CNTK是微软开源的深度学习工具包,它通过有向图将神经网络描述为一系列计算步骤。在有向图中,叶节点表示输入值或网络参数,而其他节点表示其输入上的矩阵运算。
CNTK允许用户非常轻松地实现和组合流行的模型,包括前馈DNN,卷积网络(CNN)和循环网络(RNN / LSTM)。与目前大部分框架一样,实现了自动求导,利用随机梯度下降方法进行优化。
(2)特点
- CNTK性能较高,按照其官方的说法,比其他的开源框架性能都更高。
- 适合做语音,CNTK本就是微软语音团队开源的,自然是更合适做语音任务,使用RNN等模型,以及在时空尺度分别进行卷积非常容易。
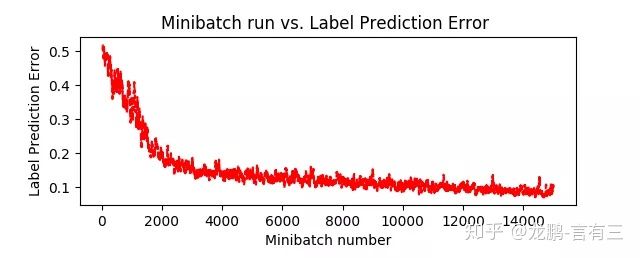
2.8 Matconvnet
github地址:https://github.com/vlfeat/matconvnet。
(1) 概述
不同于各类深度学习框架广泛使用的语言Python,MatConvnet是用matlab作为接口语言的开源深度学习库,底层语言是cuda。
(2) 特点
因为是在matlab下面,所以debug的过程非常的方便,而且本身就有很多的研究者一直都使用matlab语言,所以其实该语言的群体非常大。
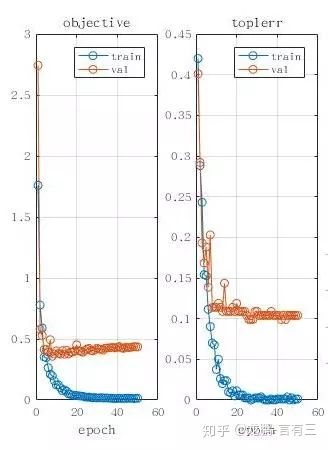
2.9 Deeplearning4j
github地址:https://github.com/deeplearning4j/deeplearning4j。
(1) 概述
不同于深度学习广泛应用的语言Python,DL4J是为java和jvm编写的开源深度学习库,支持各种深度学习模型。
(2)特点
DL4J最重要的特点是支持分布式,可以在Spark和Hadoop上运行,支持分布式CPU和GPU运行。DL4J是为商业环境,而非研究所设计的,因此更加贴近某些生产环境。
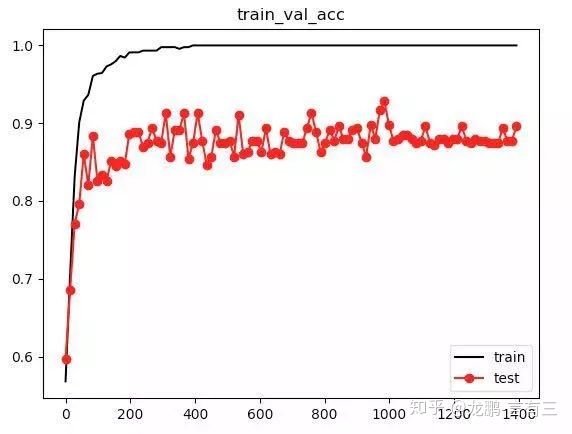
2.10 Chainer
github地址:https://github.com/chainer/chainer。
(1) 概述
chainer也是一个基于python的深度学习框架,能够轻松直观地编写复杂的神经网络架构,在日本企业中应用广泛。
(2) 特点
chainer采用“Define-by-Run”方案,即通过实际的前向计算动态定义网络。更确切地说,chainer存储计算历史而不是编程逻辑,pytorch的动态图机制思想主要就来源于chainer。

2.11 Lasagne/Theano
github地址:https://github.com/Lasagne/Lasagne。
(1)概述
Lasagen其实就是封装了theano,后者是一个很老牌的框架,在2008年的时候就由Yoshua Bengio领导的蒙特利尔LISA组开源了。
(2)特点
theano的使用成本高,需要从底层开始写代码构建模型,Lasagen对其进行了封装,使得theano使用起来更简单。
2.12 Darknet
github地址:https://github.com/pjreddie/darknet。
(1) 概述
Darknet本身是Joseph Redmon为了Yolo系列开发的框架。
Joseph Redmon提出了Yolo v1,Yolo v2,Yolo v3。
(2) 特点
Darknet几乎没有依赖库,是从C和CUDA开始撰写的深度学习开源框架,支持CPU和GPU。Darknet跟caffe颇有几分相似之处,却更加轻量级,非常值得学习使用。
1、今天开源的这一套代码还只包含图像分类任务,后续我们会增加其他计算机视觉任务,欢迎小伙伴们前来参与,需要力量!
2、开源框架众多,使用过程中必会出现N多问题,如果你想要更多的交流,就来有三AI知识星球吧,来日方长。
