python学习之数据分析必备库pandas,保姆级教学
文章目录
- 1.数据结构
-
- Series
- DataFrame
- 创建一个空的dataframe
- 用list的数据创建dataframe
- 用numpy的矩阵创建dataframe
- 用dict的数据创建DataFrame
- 读取数据
- 2. 查看数据
-
- 按列读取
- 按行读取
- 3.遍历数据
-
- 简单方式
- 函数方式
- 4.数值运算
- 5.可视化
听说点进蝈仔帖子的都喜欢点赞加关注~~
老规矩,官网附上,建议大佬直接看官网
https://pandas.pydata.org/
鸣谢:
https://zhuanlan.zhihu.com/p/35592464
https://zhuanlan.zhihu.com/p/131553804
https://mp.weixin.qq.com/s/KjQcf-OSmUrosqDCj6zWRg
1.数据结构

Pandas中有两种数据结构Series和DataFrame。
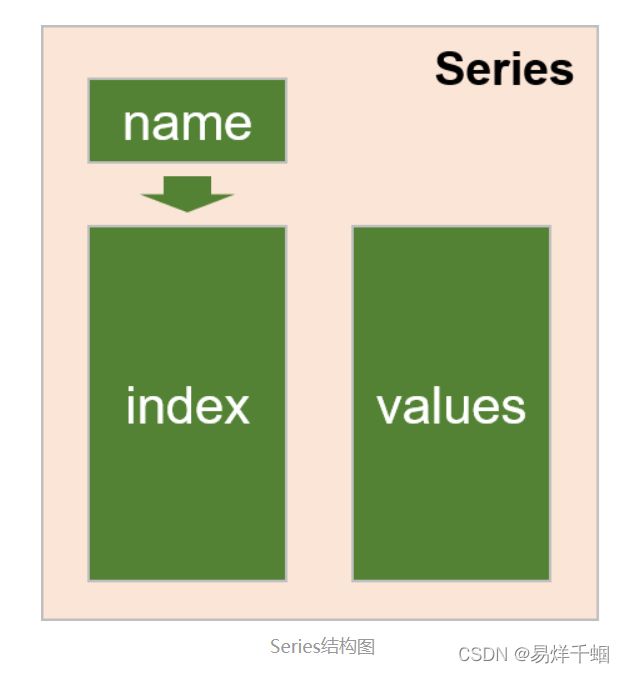
Series
Series用一维数组,可以存储不同类型的数据。
Pandas 是python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
pandas的两大主要数据结构 Series和DateFrame,其中Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引,它由两部分组成。
values:一组数据(ndarray类型)
index:相关的数据索引标签
创建方式:
- 列表创建
import pandas as pd
# Series组成部分:pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
lst = [1,3,5,6,10,23]
s = pd.Series(lst) # 可以通过index指定索引,如果不指定索引,则会自动从0开始生成索引,我们叫做隐式索引
s
- numpy创建
s = pd.Series(np.random.randint(1,10,size=(3,)),index=['a','b','c'])
s
- 字典创建
dic = {"A":1,"B":2,"C":3,"D":2}
s2 = pd.Series(dic)
s2
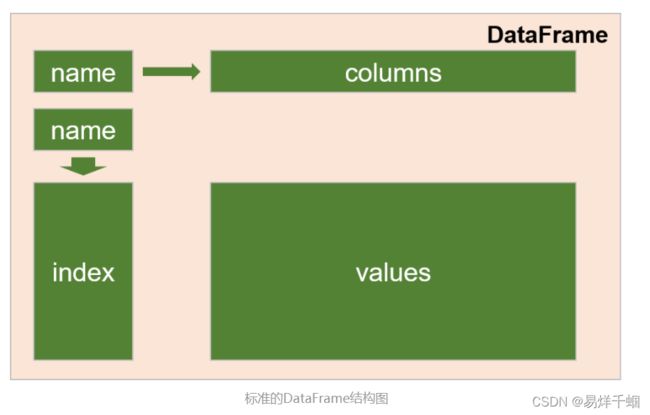
DataFrame
创建一个空的dataframe
df=pd.DataFrame(columns={"a":"","b":"","c":""},index=[0])
用list的数据创建dataframe
a = [['2', '1.2', '4.2'], ['0', '10', '0.3'], ['1', '5', '0']]
df = pd.DataFrame(a, columns=['one', 'two', 'three'])
print df
用numpy的矩阵创建dataframe
array = np.random.rand(5,3)
df = pd.DataFrame(array,columns=['first','second','third'])
用dict的数据创建DataFrame
data = { 'row1' : [1,2,3,4], 'row2' : ['a' , 'b' , 'c' , 'd'] }
df = pd.DataFrame(data)
读取数据
- 读取csv
df2 = pd.read_csv('doc/csvFile.csv')
print(df2)
- 读取excel
先给出完整函数
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False,dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0,
convert_float=True, **kwds)
df=pd.read_excel('test.xlsx')
height,width = df.shape
print(height,width,type(df))
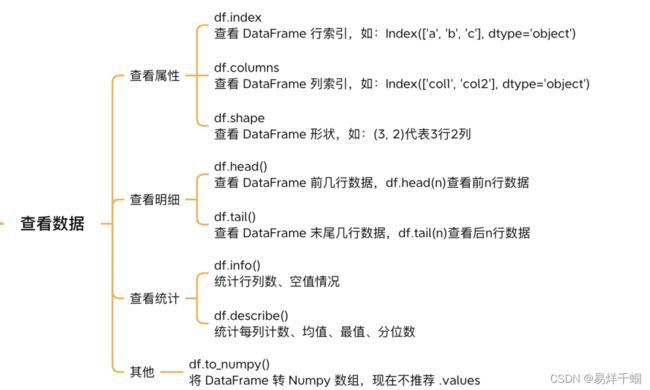
2. 查看数据
按列读取
方法1:df.列名
该方法每次只能读取一列。
方法2:df[‘列名’]or df[[‘列名’]]、df[[‘列名1’,‘列名2’,‘列名n’]]
方法3 .iloc[:,colNo] or .iloc[:,colNo1:colNo2]
按列号读取,有时候我们可能更希望通过列号(1,2,3…)读取数据而不是列名,又或着我们要读取多行的时候一个一个输入列名是很麻烦的,我们希望有最简单的代码读取我们最想要的内容,.iloc方法可以让我们通过列号索引数据,具体如下:
df.iloc[:1]读取第一列
df.iloc[:,1:3]读取第1列到第3列
df.iloc[:,2:]读取第2列之后的数据
df.iloc[:,:3]读取前3列数据
ps:这其实是按单元格读取数据的特殊写法,如果有疑问请看 2.3 按单元格读取数据。
按行读取
方法1:.loc[‘行标签’]or.loc[[‘行标签’]]、.loc[[‘行标签1’,‘行标签2’,‘行标签n’]]
.loc根据行标签索引数据,这里的行标签可以理解为索引(没有深入研究,但是在这里,行标签=索引),比如我们要分别读取第1行和第3行就是df[[1]]、df[[‘a’]],如果该df的索引变为[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’],分别读取第1行和第3行的操作将变成df[[‘a’]],df[[‘c’]],也就是说.loc后面的’行标签’必须在索引中。
方法2:.iloc[‘行号’]or.iloc[[‘行号’]]、.iloc[[‘行号1’,‘行号2’,‘行号n’]]
.iloc根据行号索引数据,行号是固定不变的,不受索引变化的影响,如果df的索引是默认值,则.loc和.iloc的用法没有区别,因为此时行号和行标签相同。
方法3:.ix
根据其他网友的说法,.ix是.loc和.iloc的综合版,既可以通过行标签检索也可以根据行号检索。通过实验发现这个说法并不完成正确。
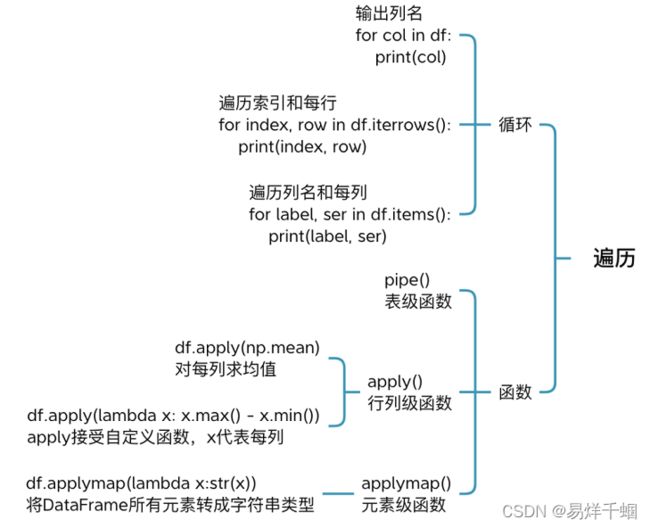
3.遍历数据
简单方式
可以使用for循环遍历DataFrame每行、每列。

df.iterrows()函数可遍历行,df.items()函数可遍历列
简单对上面三种方法进行说明:
iterrows(): 按行遍历,将DataFrame的每一行迭代为(index, Series)对,可以通过row[name]对元素进行访问。
itertuples(): 按行遍历,将DataFrame的每一行迭代为元祖,可以通过row[name]对元素进行访问,比iterrows()效率高。
iteritems():按列遍历,将DataFrame的每一列迭代为(列名, Series)对,可以通过row[index]对元素进行访问。
函数方式
df.apply()函数遍历行或列,并接收函数作为参数,用来对行、列处理。
df.applymap() 函数遍历所有元素,接收函数作为参数,用来处理处理。
4.数值运算
加减乘除自然可以,这里介绍一些复杂的。

5.可视化
Pandas 集成了 Matplotlib ,可以帮助我们快速作图。
支持图的类型:
- 折线图
- 柱状图
- 直方图
- 箱线图
- 区域图
- 散点图
- 饼图六边形容器图