小米AI实验室最新研究论文收录于COLING 2022,介绍一种更有效的鲁棒性神经机器翻译训练方法...
COLING 全称为International Conference on Computational Linguistics,是自然语言处理领域重要的国际会议,由国际计算语言学委员会(International Committee on Computational Linguistics,ICCL)创办,每两年举办一次。小米AI实验室联合厦门大学提出的一种更有效的鲁棒神经机器翻译训练方法被COLING 2022 接收为大会口头报告(Oral)。

题目:Towards Robust Neural Machine with Iterative Scheduled Data-Switch Training
作者:缪忠剑,李响,康立言,张文,周楚伦,陈毅东,王斌,张民,苏劲松
01
▍研究背景
神经机器翻译(Neural Machine Translation,NMT)一般基于高质量双语平行语料训练模型,在干净无噪音的测试集上获得了显著的翻译质量,并成为主流范式。然而,当待翻译的句子含有少量错误时,例如语音翻译中语音识别产生的错误,NMT通常会被噪音干扰产生错误译文。在真实应用场景中含有少量错误的句子十分常见,因此,提升NMT的鲁棒性,使其具备一定的抗干扰能力,不仅具有重要的学术研究价值,而且也是实际机器翻译产品应有的能力。
此前的研究者们主要从两个方面提升NMT的鲁棒性:
1. 面向数据的方法:可以视为一种数据增强的方法,针对实际错误类型构造含有噪音的对抗训练样本(Adversarial Training Example),并将其添加到原始训练数据中形成混合类型训练数据用于训练NMT模型;
2. 面向模型的方法:从优化模型结构和训练方法等维度入手,研究者们探索过多任务学习, 对比学习,对抗训练,引入额外模块等方法提升NMT鲁棒性。
虽然上述方法有效提升了NMT的鲁棒性,但仍存在两点不足:
1. 在利用对抗训练样本时,往往不加区分地使用对抗训练数据和原始训练数据混合而成的训练数据,由于两种数据存在较大差异,因此直接粗暴使用混合数据不是最佳选择;
2. 在构建对抗训练样本时,往往按照固定比例对干净样本添加错误(噪声),比例过大降低模型在干净无噪音数据上的翻译质量,反之则无法有效提升模型对噪音数据的抗干扰能力,因此使用固定噪音比例不是最佳选择。
基于课程学习思想,我们提出了一种更有效的构建和使用对抗训练样本方法来提升NMT鲁棒性,引入了两个训练阶段,每个阶段使模型专注于基于原始训练数据或对抗训练样本进行优化,克服了同时使用混合数据的缺陷。为了更好地学习这两类数据,防止灾难遗忘问题,我们迭代式的开展两个训练阶段。此外,为了防止固定噪音比例构建对抗训练样本的不足,我们设计了一种基于课程学习的噪音比例采样方法,在每个训练阶段渐进式增加噪音比例使模型能够从易到难学习训练数据中的噪音。
本文方法具有如下优势:
我们的训练框架使得NMT能够更加专注优化原始干净样本和对抗样本,实验证实这种训练策略能够获得更好的性能;
设计了基于采样的课程学习策略来控制用于生成噪声数据的噪音比例,使得模型能以从易到难的顺序学习对抗样本的信息,实验证实了该方案的优越性;
和模型结构无关,适用于不同的NMT模型,并且可以应用于其他NLP任务。
02
▍方法介绍

图1 迭代式数据交替使用的鲁棒机器翻译训练框架
针对不加区分地使用对抗训练数据和原始训练数据的不足,我们提出了两个训练阶段迭代式的训练方法,每个阶段使模型更专注优化在一类训练数据上的性能。具体来说,图1所示粉色框训练阶段主要是基于对抗训练样本优化模型性能,侧重提升模型在噪音样本上的鲁棒性,其损失函数为:

而图1所示的蓝色框训练阶段主要是基于原始训练数据优化模型性能,侧重提升模型在干净样本上的泛化性,其损失函数为:

其中(x,y)和(x',y)分别表示原始训练样本和对抗训练样本,P表示模型的输出分布,KL表示KL-Divergence损失函数,α为超参数用于调节KL-Divergence损失的重要程度。以上两个训练阶段不断迭代进行,以更好学习原始训练样本和对抗训练样本。
针对使用固定噪音比例构建对抗训练样本的不足,我们提出了在训练过程中基于课程学习策略调节噪音比例来动态构建对抗训练样本。具体来说,每个训练阶段从一个动态变化的数值区间[0,R(t)]中均匀采样噪音比例,随着训练进行逐渐增大数值区间的上界R(t)。我们设计函数R(t)的出发点为:直觉上R(t)应该缓慢增大,过快地增大R(t)使得抗样本难度变化大,损害模型的优化。因此我们使R(t)满足以下约束:

其中c1为大于0的常数。该式表明,随着训练步数t的增加,R(t)在增加的同时,其对于t的导数(即:R(t)的增加速率)在减小,满足缓慢增加R(t)的目的。结合训练步数为零时噪音比例为0以及最大训练步数时达到最大噪音比例的约束:
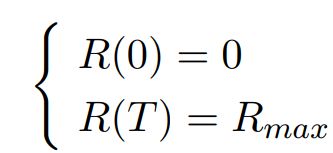
R(t)的最终表达式和曲线变化如下:


图2 噪音比例R(t)的变化曲线
其中Rmax表示最大的噪音比例,T表示每个训练阶段的最大训练步数,t表示当前的训练步数,R(t)的含义为动态变化的数值区间的上界。引入噪音比例控制后,每个训练阶段的具体流程如下:

图3 每个阶段的训练流程
03
▍实验结果
我们在如下4个不同规模的机器翻译数据集上分别对比了本文方法和现有其他方法的性能。
数据集 |
句对规模 |
IWSLT14 De→En(德语→英语) |
16万 |
MTNT Fr→En(法语→英语) |
220万 |
WMT'14 En→De(英语→德语) |
450万 |
WMT'20 Zh→En(中文→英语) |
2200万 |
1 在干净测试集和真实噪音测试集上的翻译质量
我们评估了本文方法在5个公开的干净测试集和2个真实噪音测试集上的有效性,其中MTNT Fr→En 数据集包含2个来源于社交媒体的噪声测试集(mtnt18和mtnt19)和2个常规干净测试集(NT14和NT15),具体实验结果如表1和表2所示。

表1 IWSLT'14 De→En,WMT'14 En→De和WMT'20 Zh→En干净测试集上的翻译质量
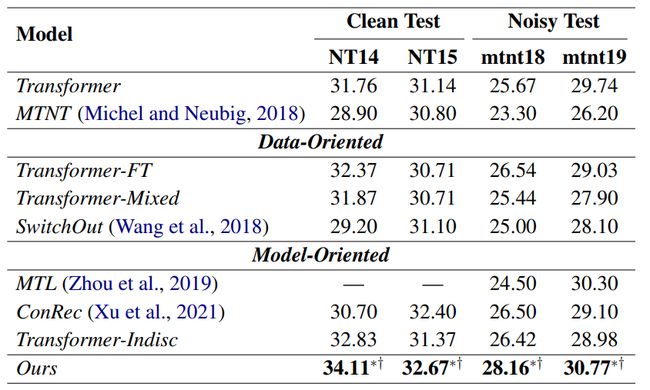
表2 MTNT Fr→En测试集上的翻译质量
2 在人工模拟噪音测试集上的翻译质量
我们构造了含有不同噪音比例的噪音测试集来全面评估本文方法的有效性,具体实验结果如图4所示。
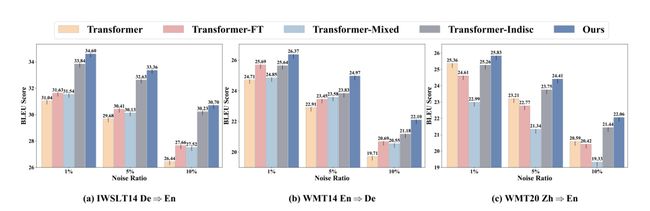
图4 在不同噪声比例的人工模拟噪音测试集上的模型性能
3 对抗样本和干净样本的降维表示
为了更加直观地展示本文方法的优势,我们绘制了不同模型在干净和对应的对抗训练数据上的源句子降维表示。具体地,我们利用词平均编码器输出代表每个源句子的表示,并利用PCA降维算法来获取其2维表示,具体结果如图5所示。
如图5(e),基于我们所提框架训练得到的模型相对于其他模型(图5(a)-(d))能够显著降低两类样本的源句差异,为得到更优的鲁棒机器翻译模型奠定了基础。

图5 干净数据和对应噪声数据的源句子降维表示(其中蓝色和粉色圆点分别对应噪声数据和干净数据)
主要实验结论如下:
本文方法在真实和人工模拟的噪声测试集上取得了最佳翻译质量,有效提升了NMT的鲁棒性。
本文方法在常规的干净测试集上也获得了最佳翻译质量,可作为提升NMT泛化性的一种有效方法。
04
▍鲁棒性机器翻译的用武之地
目前,小米自研同声传译技术已在多款手机和小爱翻译等产品中落地应用。今年,小米AI实验室机器翻译团队不仅获得第十九届国际口语机器翻译大会(IWSLT 2022)“英中文本同传”赛道冠军(夺冠!小米在 IWSLT 2022国际机器同传比赛中获佳绩),而且还获得了第三届国际机器同传挑战赛“中英文本同传”赛道冠军。

对于同声传译来说,语音识别受说话人口音和环境噪音等影响难免会出现错误,这些错误一般来说会干扰机器翻译正确性,严重影响用户体验。因此,本文提出的工作对于改善用户体验具有重要价值。
1 小爱实时字幕
高通骁龙8+芯片内置的第七代AI芯片提供了强大算力,小米MIX Fold 2折叠屏手机行业首发了全离线语音识别和机器翻译(详见又快又准又安全?实时字幕有“芯”秘密!),用户在观看外语视频、开外语在线会议、甚至无网需要外语交流时都可以接近实时的看到双语字幕,同时,音频数据默认保存在手机本地,无需上传云端处理,隐私更安全。

2 小爱同声传译
双人对话,边说边译,面对面跨语言沟通无障碍,能轻松应对全球多个国家的不同英文口音。

3 小爱通话传译
解决跨语言通话中的语言障碍问题,说话人直接说母语,接收方听到的也是用母语发音的译文,实现通话双方自由交流。

4 MIUI笔记会议秘书
涉外会议中,使用小米MIX Fold 2折叠屏手机可以直接翻译并记录会议内容,还有精细的声纹识别可以将会中角色也区别开来,全面解放你的双手和头脑,把时间留给思考,实现高效的AI会议纪要。

5 米家眼镜相机
最新发布的米家眼镜相机也内置了能通提供实时中英互译的“小爱翻译”功能,用户在参加外语会议和出国旅游时,佩戴眼镜就可以轻松理解外语内容和应对外语交流。
近年来,小米在机器翻译方向的技术积累日渐丰厚,并已在小米手机和 AIoT 智能硬件产品中广泛落地,陆续自研了“同声传译”、“会议秘书”、“实时字幕”、“通话翻译”,“图片翻译”,“网页翻译”等功能。
通过“全能翻,极速译”的小爱翻译App,小米手机用户无论是与外国友人面对面还是通话沟通、观看没有字幕外语视频,浏览外文网页、甚至遇到含有外文的图片时,都能随时随地便捷的获得机器翻译译文,实现了边说边译、边听边译、边看边译,轻松应对各种语言障碍,让全球每个人享受没有语言障碍的美好生活。
参考文献
[1] Belinkov et al. 2018. Synthetic and Natural Noise Both Break Neural Machine Translation. In Proc. of ICLR.
[2] Cheng et al. 2018. Towards Robust Neural Machine Translation. In Proc. of ACL.
[3] Jiao et al. 2021. Alternated Training with Synthetic and Authentic Data for Neural Machine Translation. In Proc. of ACL Findings.
[4] Karpukhin et al. 2019. Training on Synthetic Noise Improves Robustness to Natural Noise in Machine Translation. In Proc. of W-NUT@EMNLP.
[5] Wang et al. 2021. Secoco: Self-Correcting Encoding for Neural Machine Translation. In Proc. of EMNLP Findings.
[6] Wang et al. 2021. A Comprehensive Survey on Curriculum Learning. IEEE T-PAMI.
[7] Xu et al. 2021. Addressing the Vulnerability of NMT in Input Perturbations. In Proc. of NAACL.
[8] Zhou et al. 2019. Improving Robustness of Neural Machine Translation with Multi-task Learning. In Proc. of WMT.
[9] Qin et al. 2021. Modeling Homophone Noise for Robust Neural Machine Translation. In Proc. of ICASSP.
[10] Michel et al. 2018. MTNT: A Testbed for Machine Translation of Noisy Text. In Proc. of EMNLP.
[11] Cheng et al. 2020. Advaug: Robust Adversarial Augmentation for Neural Machine Translation. In Proc. of ACL.
[12] Lee et al. 2021. Contrastive Learning with Adversarial Perturbations for Conditional Text Generation. In Proc. of ICLR.

