第二十天自然语言处理
目 录
- 自然语言处理(NLP)
-
- 一、NLP概述
-
- 1. NLP的定义
- 2. NLP的主要任务
-
- 1)分词
- 2)词义消歧
- 3)命名实体识别(NER)
- 4)词性标记(PoS)
- 5)文本分类
- 6)语言生成
- 5)问答(QA)系统
- 6)机器翻译(MT)
- 3. NLP的发展历程
-
- 1)萌芽期(1956年以前)
- 2)快速发展期(1957~1970)
- 3)低速发展期(1971~1993)
- 4)复苏融合期(1994年至今)
- 4. NLP的困难与挑战
-
- 1)语言歧义
- 2)不同语言结构差异
- 3)未知语言不可预测性
- 4)语言表达的复杂性
- 5)机器处理语言缺乏背景与常识
- 5. NLP相关知识构成
- 6. 语料库
-
- 1)什么是语料库
- 2)语料库的特征
- 3)语料库的作用
- 4)常用语料库介绍
自然语言处理(NLP)
一、NLP概述
1. NLP的定义
NLP(Nature Language Processing,自然语言处理)是计算机学科及人工智能领域一个重要的子学科,它主要研究计算机如何处理、理解及应用人类语言。所谓自然语言,指人说的话、人写的文章,是人类在长期进化过程中形成的一套复杂的符号系统(类似于C/Java等计算机语言则称为人造语言)。以下是关于自然语言处理常见的定义:
- 自然语言处理是计算机科学与语言中关于计算机与人类语言转换的领域。——中文维基百科
- 自然语言处理是人工智能领域中一个重要的方向。它研究实现人与计算机之间用自然语言进行有效沟通的各种理论和方法。——百度百科
- 自然语言处理研究在人与人交际中及人与计算机交际中的语言问题的一门学科。NLP要研制表示语言能力和语言应用的模型,建立计算机框架来实现这些语言模型,提出相应的方法来不断完善这种模型,并根据语言模型设计各种实用系统,以及对这些系统的评测技术。——Bill Manaris,《从人机交互的角度看自然语言处理》
自然语言处理还有其它一些名称,例如:自然语言理解(Natural Language Understanding),计算机语言学(Computational Linguistics),人类语言技术(Human Language Technology)等等。
2. NLP的主要任务
NLP的主要任务可以分为两大类,一类是基于现有文本或语料的分析,另一类是生成新的文本或语料。

1)分词
该任务将文本或语料分隔成更小的语言单元(例如,单词)。对于拉丁语系,词语之间有空格分隔,对于中文、日文等语言,分词就是一项重要的基本任务,分词直接影响对文本语义的理解。例如:
文本:吉林市长春药店
分词1:吉林市/长春/药店
分词2:吉林/市长/春药/店
2)词义消歧
词义消歧是识别单词正确含义的任务。例如,在句子“The dog barked at the mailman”(狗对邮递员吠叫)和“Tree bark is sometimes used as a medicine”(树皮有时用作药物)中,单词bark有两种不同的含义。词义消歧对于诸如问答之类的任务至关重要。
3)命名实体识别(NER)
NER尝试从给定的文本主体或文本语料库中提取实体(例如,人物、位置和组织)。例如,句子:
John gave Mary two apples at school on Monday
将转换为:
![]()
4)词性标记(PoS)
PoS标记是将单词分配到各自对应词性的任务。它既可以是名词、动词、形容词、副词、介词等基本词、也可以是专有名词、普通名词、短语动词、动词等。
5)文本分类
文本分类有许多应用场景,例如垃圾邮件检测、新闻文章分类(例如,政治、科技和运动)和产品评论评级(即正向或负向)。我们可以用标记数据(即人工对评论标上正面或负面的标签)训练一个分类模型来实现这项任务。
6)语言生成
可以利用NLP模型来生成新的文本或语料,例如机器写作(天气预报、新闻报道、模仿唐诗),生成文本摘要等。以下是一段机器合成的"诗":
向塞唯何近,空令极是辞。向睹一我扇,猛绶临来惊。
向面炎交好,荷莎正若隳。即住长非乱,休分去此垂。
却定何人改,松仙绕绮霞。偶笑寒栖咽,长闻暖顶时。
失个亦垂谏,守身丈韦鸿。忆及他年事,应愁一故名。
坐忆山高道,为随夏郭间。到乱唯无己,千方得命赊。
5)问答(QA)系统
QA技术具有很高的商业价值,这些技术是聊天机器人和VA(例如,Google Assistant和Apple Siri)的基础。许多公司已经采用聊天机器人来提供客户支持。以下是一段与聊天机器人的对话:
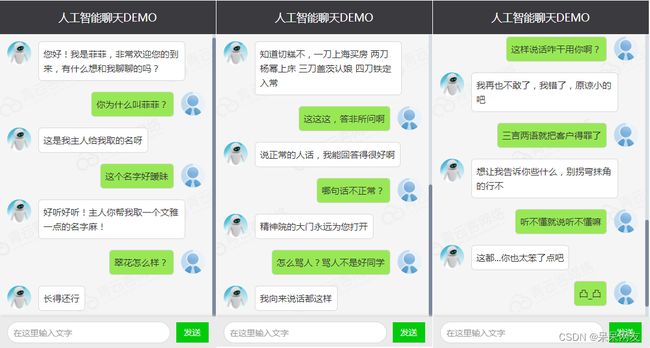
6)机器翻译(MT)
机器翻译(Machine Translation,MT)指将文本由一种语言翻译成另一种语言,本质是根据一个序列,生成语义最相近的另一种语言序列。

3. NLP的发展历程
NLP的发展轨迹为:基于规则 → 基于统计 → 基于深度学习,其发展大致经历了4个阶段:1956年以前的萌芽期;19571970年的快速发展期;19711993年的低速发展期;1994年至今的复苏融合期。
1)萌芽期(1956年以前)
- 1946年:第一台电子计算机诞生
- 1948年:Shannon把离散马尔可夫过程的概率模型应用于描述语言的自动机。接着,他又把热力学中“熵”(entropy)的概念引用于语言处理的概率算法中
- 1956年:Chomsky又提出了上下文无关语法,并把它运用到自然语言处理中
2)快速发展期(1957~1970)
自然语言处理在这一时期很快融入了人工智能的研究领域中。由于有基于规则和基于概率这两种不同方法的存在,自然语言处理的研究在这一时期分为了两大阵营。一个是基于规则方法的符号派(symbolic),另一个是采用概率方法的随机派(stochastic)。这一时期,两种方法的研究都取得了长足的发展。从50年代中期开始到60年代中期,以Chomsky为代表的符号派学者开始了形式语言理论和生成句法的研究,60年代末又进行了形式逻辑系统的研究。而随机派学者采用基于贝叶斯方法的统计学研究方法,在这一时期也取得了很大的进步。
这一时期的重要研究成果包括1959年宾夕法尼亚大学研制成功的TDAP系统,布朗美国英语语料库的建立等。1967年美国心理学家Neisser提出认知心理学的概念,直接把自然语言处理与人类的认知联系起来了。
3)低速发展期(1971~1993)
随着研究的深入,由于人们看到基于自然语言处理的应用并不能在短时间内得到解决,而一连串的新问题又不断地涌现,于是,许多人对自然语言处理的研究丧失了信心。从70年代开始,自然语言处理的研究进入了低谷时期。
但尽管如此,一些研究人员依旧坚持继续着他们的研究。由于他们的出色工作,自然语言处理在这一低谷时期同样取得了一些成果。70年代,基于隐马尔可夫模型(Hidden Markov Model, HMM)的统计方法在语音识别领域获得成功。80年代初,话语分析(Discourse Analysis)也取得了重大进展。之后,由于自然语言处理研究者对于过去的研究进行了反思,有限状态模型和经验主义研究方法也开始复苏。
4)复苏融合期(1994年至今)
90年代中期以后,有两件事从根本上促进了自然语言处理研究的复苏与发展。一件事是90年代中期以来,计算机的速度和存储量大幅增加,为自然语言处理改善了物质基础,使得语音和语言处理的商品化开发成为可能;另一件事是1994年Internet商业化和同期网络技术的发展使得基于自然语言的信息检索和信息抽取的需求变得更加突出。以下列举除了2000年之后NLP领域的几个里程碑事件:
-
2001年:神经语言模型
-
2008年:多任务学习
-
2013年: Word嵌入
-
2013年:NLP的神经网络
-
2014年:序列到序列模型
-
2015年:注意力机制
-
2015年:基于记忆的神经网络
-
2018年:预训练语言模型
4. NLP的困难与挑战
1)语言歧义
不同分词导致的歧义
例如:自动化研究所取得的成就
理解一:自动化 / 研究 / 所 / 取得 / 的 / 成就
理解二:自动化 / 研究所 / 取得 / 的 / 成就
词性歧义
动物保护警察
“保护”理解成动词、名词,语义不一样
结构歧义
喜欢乡下的孩子
关于鲁迅的文章
语音歧义
节假日期间,所有博物馆全部(不)对外开放
2)不同语言结构差异

3)未知语言不可预测性
语言在不断演化,每年都有为数不少的新词语、新语料出现,给一些NLP处理任务造成困难。以下列举了几个2021年网络上出现的新词语:
双减
元宇宙
绝绝子
躺平
4)语言表达的复杂性
甲:你这是什么意思?
乙:没什么意思,意思意思。
甲:你这就不够意思了。
乙:小意思,小意思。
甲:你这人真有意思。
乙:其实也没有别的意思。
甲:那我就不好意思了。
5)机器处理语言缺乏背景与常识
中国国家队比赛最没悬念的是乒乓球和足球,他们一个谁也打不过,另一个谁也打不过
如果希拉里当选,她就是全世界唯一一个干过美国总统和干过美国总统的女人,克林顿也将成为全世界唯一一个干过美国总统和干过美国总统的男人
5. NLP相关知识构成

6. 语料库
1)什么是语料库
语料库(corpus)是指存放语言材料的仓库。现代的语料库是指存放在计算机里的原始语料文本或经过加工后带有语言学信息标注的语料文本。以语言的真实材料为基础来呈现语言知识,反映语言单位的用法和意义,基本以知识的原型形态表现——语言的原貌。
2)语料库的特征
- 语料库中存放的是实际中真实出现过的语言材料
- 语料库是以计算机为载体承载语言知识的基础资源,但不等于语言知识
- 真实语料需要经过分析、处理和加工,才能成为有用的资源
3)语料库的作用
- 支持语言学研究和语言教学研究
- 支持NLP系统的开发
4)常用语料库介绍
-
北京大学计算机语言所语料库标记(中文),地址:http://opendata.pku.edu.cn/dataverse/icl
-
London-Lund英语口语语料库,地址:http://www.helsinki.fi/varieng/CoRD/copora.LLC/
-
腾讯中文语料库。包含800多万个中文词汇,其中每个词对应一个200维的向量,覆盖很多现代词汇,包括最近一两年出现的新词。采用了更大规模的数据和更好算法。https://ai.tencent.com/ailab/nlp/data/Tencent_AILab_ChineseEmbedding.tar.gz
-
中文维基百科语料库。维基百科是最常用且权威的开放网络数据集之一,作为极少数人工编辑、内容丰富、格式规范的文本语料,各类语言的维基百科在NLP中广泛应用。