Docker原理详解
前言
统称来说,容器是一种工具,指的是可以装下其它物品的工具,以方便人类归纳放置物品、存储和异地运输,具体来说比如人类使用的衣柜、行李箱、背包等可以成为容器,但今天我们所说的容器是一种IT技术。
容器技术是虚拟化、云计算、大数据之后的一门新兴的并且是炙手可热的新技术,容器技术提高了硬件资源利用率(相对于物理机或者虚拟机)、方便了企业的业务快速横向扩容、实现了业务宕机自愈功能,因此未来数年会是一个容器愈发流行的时代,这是一个对于IT行业来说非常有影响和价值的技术,而对于IT行业的从业者来说,熟练掌握容器技术无疑是一个很有前景的行业工作机会。容器技术最早出现在freebsd叫做jail。
虚拟机是直接运行在物理机上的,可以实现嵌套虚拟化,但是性能较差,不经常使用。公司一般使用KVM+openstack对容器进行批量管理,创建以及批量维护,实现虚拟机的快速创建。KVM通过命令快速创建虚拟机,提供了虚拟机的运行环境,使用docker+k8s对容器进行管理,实现容器的快速创建,通过k8s快速创建容器,docker提供了容器的运行环境。
docker和虚拟机的差别主要在于: 横向扩容和故障自治愈。
故障自治愈指的是:业务跑在多个物理机或者虚拟机上vm1 vm2,当虚拟机或者物理机挂掉以后,可以自动转移到其他物理机或虚拟机并启动。
一、docker 简介
1.1 Docker 是什么
首先,Docker是一个在2013年开源的应用程序并且是一个基于go语言编写是一个开源的PAAS服务(Platform as a Service,平台即服务的缩写),
go语言是由google开发,docker公司最早叫dotCloud后由于Docker开源后大受欢迎就将公司改名为Docker Inc,总部位于美国加州的旧金山,
Docker是基于linux内核实现,Docker最早采用LXC技术(LinuX Container的简写,
LXC是Linux原生支持的容器技术,可以提供轻量级的虚拟化,可以说docker就是基于LXC发展起来的,提供LXC的高级封装,发展标准的配置方法),
而虚拟化技术KVM(Kernelbased Virtual Machine)基于模块实现,Docker后改为自己研发并开源的runc技术运行容器。
Docker相比虚拟机的交付速度更快,资源消耗更低,
Docker采用客户端/服务端架构,使用远程API来管理和创建Docker容器,其可以轻松的创建一个轻量级的、可移植的、自给自足的容器。
docker的三大理念是 build(构建)、ship(运输)、run(运行),Docker遵从apache 2.0协议,并通过(namespace及cgroup等)来提供容器的资源隔离与安全保障等,
所以Docke容器在运行时不需要类似虚拟机(空运行的虚拟机占用物理机6-8%性能)的额外资源开销,因此可以大幅提高资源利用率。
总而言之,Docker是一种用了新颖方式实现的轻量级虚拟机。
类似于VM但是在原理和应用上和VM的差别还是很大的,并且docker的专业叫法是应用容器(Application Container)。
> 可移植指的是:可以运行在多种不同的操作平台上
> 自给自足指的是:每个docker夺回包括自己服务的运行环境, 例如java (JDL + TOMCAT + APP代码),将服务封装在服务中就可以运行。
docker的三大理念是build(构建)、ship(运输)、run(运行)指的是:
一次构建到处运输到处运行将构建的结果运输到任何有docker环境的服务器上,就可以运行构建的结果就是一个image(镜像) 在KVM(虚拟机)中称为模板,
创建虚拟机的时候就是基于模板创建虚拟机,创建容器的时候就是基于镜像创建容器。
namespace及cgroup也调用宿主机的内核,实现了docker运行的两个核心机制,这就会导致支持的功能可能会不一样。
dockerd 是整个docker的守护进程,基于守护进程再创建容器,这些容器都属于docker的子进程,
优点在于结构简单,当dockerd进程被kill掉或者出现异常以后,所有容器都会无法使用。
远程API指的是创建容器的时候,使用Cli客户端命令,或者使用web界面(由k8s封装的界面,称为dashborad)
dashborad也是调用了dockerd来创建容器。
1.2 Docker 的组成
Docker官方文档:
https://docs.docker.com/engine/docker-overview/
Docker官方仓库:
https://hub.docker.com/ 包括第三方提供的镜像
Docker主机(Host/node节点/宿主机):一个物理机或虚拟机,用于运行Docker服务进程和容器。
Docker服务端(Server): Docker守护进程,用于启动创建和运行docker容器。
Docker客户端(Client): 客户端使用docker命令或其他工具调用docker API。
Docker仓库(Registry): 统一保存镜像的仓库,类似于git或svn这样的版本控制系统,公司内部一般使用harbor搭建
Docker镜像(Images): 镜像可以理解为创建实例使用的模板。
Docker容器(Container): 容器是从镜像生成对外提供服务的一个或一组服务。
1.3 Docker 对比虚拟机
1> 资源利用率更高:一台物理机可以运行数百个容器,但是一般只能运行数十个虚拟机。
> 虚拟机有内核
> docker没有内核,容器直接调用宿主机内核,所以也没有硬件的管理机制,所以容器才会轻量级(空间小,功能少)
2> 开销更小:不需要启动单独的虚拟机占用硬件资源。
3> 启动速度更快:可以在数秒内完成启动。
使用虚拟机是为了更好的实现服务运行环境隔离,每个虚拟机都有独立的内核,虚拟化可以实现不同操作系统的虚拟机,
但是通常一个虚拟机只运行一个服务,很明显资源利用率比较低且造成不必要的性能损耗,
我们创建虚拟机的目的是为了运行应用程序,比如 Nginx、PHP、Tomcat等web程序,
使用虚拟机无疑带来了一些不必要的资源开销,但是容器技术则基于减少中间运行环节带来较大的性能提升。
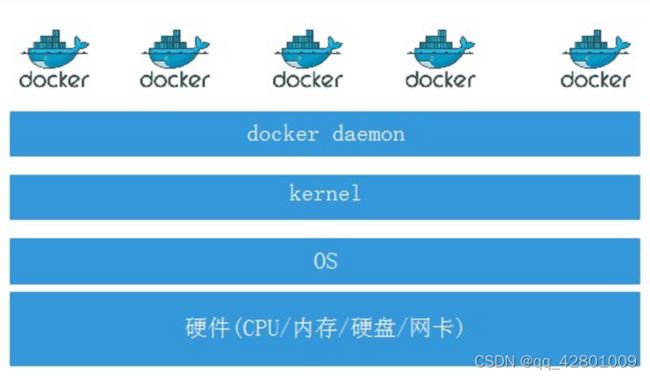
但是,如上图一个宿主机运行了N个容器,多个容器带来的以下问题怎么解决:
1.怎么样保证每个容器都有不同的文件系统并且能互不影响?
2.一个docker主进程内的各个容器都是其子进程,那么实现同一个主进程下不同类型的子进程?各个进程间通信能相互访问(内存数据)吗?
3.每个容器怎么解决IP及端口分配的问题?
4.多个容器的主机名能一样吗?
5.每个容器都要不要有root用户?怎么解决账户重名问题?
以上问题怎么解决?
使用Linux Namespace 技术解决
1.4 Linux Namespace 技术
namespace是Linux系统的底层概念,在宿主机内核层实现。
即有一些不同类型的命名空间被部署在内核中,各个docker容器运行在同一个docker主进程并且共用同一个宿主机系统内核,
各docker容器运行在宿主机的用户空间,每个容器都要有类似于虚拟机一样的相互隔离的运行空间,
但是容器技术是在一个进程内实现运行指定服务的运行环境,并且还可以保护宿主机内核不受其他进程的干扰和影响,
如文件系统空间(rootfs 可执行命令 目录结构)、网络空间(IP地址和端口)、进程空间等,目前主要通过以下技术实现容器运行空间的相互隔离:
| 隔离类型 | 功能 | 系统调用参数 | 内核版本 |
|---|---|---|---|
| MNT Namespace(mount) | 提供磁盘挂载点和文件系统的隔离能力 | CLONE_NEWNS | Linux 2.4.19 |
| IPC Namespace(Inter-Process Communication) | 提供进程间通信的隔离能力 | CLONE_NEWIPC | Linux 2.6.19 |
| UTS Namespace(UNIX Timesharing System) | 提供主机名隔离能力 | CLONE_NEWUTS | Linux 2.6.19 |
| PID Namespace(Process Identification) | 提供进程隔离能力 | CLONE_NEWPID | Linux 2.6.24 |
| Net Namespace(network) | 提供网络隔离能力 | CLONE_NEWNET | Linux 2.6.29 |
| User Namespace(user) | 提供用户隔离能力 | CLONE_NEWUSER | Linux 3.8 |
namespace指的是逻辑上隔离开的一个空间,叫命名空间。
每个容器之间都是相互隔离的,隔离开指的是用户的空间是隔离的,每个容器都有root用户和普通用户,且不互相冲突,网络空间也相互隔离,
每个容器都有80端口,但是还是不冲突,基于宿主机内核实现。
一个宿主机上运行好多容器,当一个容器出问题以后,不会影响其他容器服务。
MNT Namespace
每个容器都要有独立的根文件系统有独立的用户空间,以实现在容器里面启动服务并且使用容器的运行环境,
即一个宿主机是ubuntu的服务器,可以在里面启动一个centos运行环境的容器并且在容器里面启动一个Nginx服务,
此Nginx运行时使用的运行环境就是centos系统目录的运行环境,但是在容器里面是不能访问宿主机的资源,
宿主机是使用了chroot技术把容器锁定到一个指定的运行目录里面。
例如:/var/lib/containerd/io.containerd.runtime.v1.linux/moby/容器ID
一个容器业务(moby)会有很多的小服务,在业务中会有很多分支,docker只是其中的一个会有创建容器的服务,管理容器的服务,保存容器的仓库服务,小服务来实现具体功能
/var/lib/containerd/io.containerd.runtime.v1.linux 为锁定目录,会将容器锁定在此目录中,但是容器的数据目录和根目录不在一块,实现了联合挂载。
联合挂载指的是在宿主机上将不同的目录挂在容器中给容器使用。
IPC Namespace
一个容器内的进程间通信,允许一个容器内的不同进程的(内存、缓存等)数据访问,但是不能夸容器访问其他容器的数据。
UTS Namespace
UTS namespace(UNIX Timesharing System包含了运行内核的名称、版本、底层体系结构类型等信息)用于系统标识,其中包含了hostname和域名domainname,它使得一个容器拥有属于自己的hostname标识,这个主机名标识独立于宿主机系统和其上的其他容器。 每一个容器都有一个独立的主机名,并且相互之间互相隔离,容器中使用的是宿主机的内核
PID Namespace
Linux系统中,有一个PID为1的进程(init/systemd)是其他所有进程的父进程,那么在每个容器内也要有一个父进程来管理其下属的子进程,那么多个容器的进程通PID namespace进程隔离(比如PID编号重复、器内的主进程生成与回收子进程等)。
在容器中启动服务的时候,不是拿init.service start 或者systemctl start启动,因为容器没有独立的内核
容器启动服务,会直接使用某一个服务的命令来启动,例如nginx。
会使用nginx命令直接起来,而不是systemd,nginx命令后面有很多选项,其中一个选项就是-g,通过-g传递指令
容器启动nginx的时候,启动的是nginx -g daemon off 将后台守护进程关掉了,直接让它在前台启动
由于nginx -g daemon off 是第一个在前台启动的进程,所以是唯一的,然后会启动多个work进程,生成多个子进程
nginx -g daemon off -> 可以在当前终端可以长久执行的进程,当容器遇到这样的进程就会将PID改为 1
容器和虚拟机一样,在宿主机上就是一个进程,
nginx容器无非就是在宿主机上起了一个nginx进程,将进程封装成了一个容器
在宿主机 通过pstree -p 1 观察进程关系
systemd(1) 为所有宿主机的子进程的父进程
containerd(4145) containerd进程用于管理容器,守护进程,可以生成多个容器
containerd-shim(6773) 容器进程,多个容器进程共用一个守护进程
由此解决了用户的启动。
systemd(1)
dockerd(6269) 用于管理网络访问服务,主要体现在iptables规则上
docker-proxy(6766) 用于生成iptables规则
由此解决用户的网络访问。
Net Namespace
每一个容器都类似于虚拟机一样有自己的网卡、监听端口、TCP/IP 协议栈等, Docker使用network namespace启动一个vethX接口,这样你的容器将拥有它自己的桥接ip地址,通常是docker0,而docker0实质就是Linux的虚拟网桥,网桥是在OSI七层模型的数据链路层的网络设备,通过mac地址对网络进行划分,并且在不同网络直接传递数据。
每个容器中都会有一个eth0,这个eth0会体现在宿主机的vethX网卡上。通常情况下,容器中只有一块网卡eth0。
容器中的eth0 MAC地址一定不会和宿主机的MAC地址一致。
docker0是一个虚拟交换机也称为网桥,存在于物理机。
docker0的接口叫做vethX,有多少个容器就有多少个veth接口,保证宿主机和容器连接起来做对接
docker0将用户的请求转发到宿主机的eth0
宿主机的eth0再将请求向外发送,到达宿主机网关
中间走了iptables来转发,如果走iptables的话,跨网段的转发,则需要开启ipv4_forword 路由转发功能
网桥的一端和宿主机的vethX连接,另外一端和容器的eth0连接,从而保证可以相互通信。
1> 同一个宿主机,容器之间的通信,当A容器去访问B容器,直接在本机网桥(docker0)上就可以实现
在宿主机上通过iptables -nvL 查看iptables规则,都是docker自动生成的规则,不需要人为管理
iptables -t nat -vnL 在nat规则中做了路由转发,所有同一宿主机之间的容器之间的通信,都是基于iptables做转发实现,因此必须开启路由转发功能
User Namespace
各个容器内可能会出现重名的用户和用户组名称,或重复的用户UID或者GID,那么怎么隔离各个容器内的用户空间呢?
User Namespace允许在各个宿主机的各个容器空间内创建相同的用户名以及相同的用户UID和GID,只是会把用户的作用范围限制在每个容器内,即A容器和B容器可以有相同的用户名称和ID的账户,但是此用户的有效范围仅是当前容器内,不能访问另外一个容器内的文件系统,即相互隔离、互补影响、永不相见。
1.5 Linux control groups 资源限制
在一个容器,如果不对其做任何资源限制,则宿主机会允许其占用无限大的内存空间,有时候会因为代码bug程序会一直申请内存,直到把宿主机内存占完,为了避免此类的问题出现,宿主机有必要对容器进行资源分配限制,比如CPU、内存等,
Linux Cgroups的全称是Linux Control Groups,它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。此外,还能够对进程进行优先级设置和CPU绑定,以及将进程挂起和恢复等操作。
验证系统 cgroups
Cgroups在内核层默认已经开启,从centos和ubuntu对比结果来看,显然内核较新的ubuntu支持的功能更多。
### 查看内核编译文件
cat /boot/config-4.15.0-55-generic | grep CGROUP
cgroups 中内存模块
cat /boot/config-4.15.0-54-generic | grep MEMCG
CONFIG_MEMCG=y #开启内核支持内存的功能,限制物理内存
CONFIG_MEMCG_SWAP=y #限制交换分区
CONFIG_MEMCG_SWAP_ENABLED is not set
CONFIG_SLUB_MEMCG_SYSFS_ON=y
cgroups 具体实现
blkio: 块设备IO限制。 主要用于限制磁盘
cpu: 使用调度程序为cgroup任务提供cpu的访问。可以让docker调用,也可以让nginx调用,去调用cpu,banging在哪个cpu上。
cpuacct:产生cgroup任务的cpu资源报告。 资源限制以后,资源利用率是多少,会提供报告清单
cpuset: 如果是多核心的cpu,这个子系统会为cgroup任务分配单独cpu和内存。将进程绑定在cpu上
devices:允许或拒绝cgroup任务对设备的访问。
freezer:暂停和恢复cgroup任务。
memory: 设置每个cgroup的内存限制以及产生内存资源报告。
net_cls:标记每个网络包以供cgroup方便使用。
ns: 命名空间子系统。
perf_event:增加了对每group的监测跟踪的能力,可以监测属于某个特定的group的所有线程以及运行在特定CPU上的线程。
查看系统 cgroups
ll /sys/fs/cgroup/
# 加载完以后产生的文件目录
drwxr-xr-x 5 root root 0 Jun 30 18:12 blkio
lrwxrwxrwx 1 root root 11 Jun 30 18:12 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 Jun 30 18:12 cpuacct -> cpu,cpuacct
drwxr-xr-x 5 root root 0 Jun 30 18:12 cpu,cpuacct
drwxr-xr-x 3 root root 0 Jun 30 18:12 cpuset
drwxr-xr-x 5 root root 0 Jun 30 18:12 devices
drwxr-xr-x 3 root root 0 Jun 30 18:12 freezer
drwxr-xr-x 3 root root 0 Jun 30 18:12 hugetlb
drwxr-xr-x 5 root root 0 Jun 30 18:12 memory
drwxr-xr-x 3 root root 0 Jun 30 18:12 net_cls
drwxr-xr-x 3 root root 0 Jun 30 18:12 perf_event
drwxr-xr-x 5 root root 0 Jun 30 18:12 systemd
有了以上的 chroot、namespace、cgroups 就具备了基础的容器运行环境,
但是还需要有相应的容器创建与删除的管理工具、以及怎么样把容器运行起来、
容器数据怎么处理、怎么进行启动与关闭等问题需要解决,于是容器管理技术出现了。
chroot 将容器锁定在某一个宿主机目录,将此目录当作容器的根目录
namespace 各种用户,PID等等的空间隔离技术
cgroups 对容器进行资源限制
1.6 Docker 的优缺点
Docker的优点:
快速部署: 短时间内可以部署成百上千个应用,更快速交付到线上。
高效虚拟化:不需要额外的hypervisor支持,直接基于linux实现应用虚拟化,相比虚拟机大幅提高性能和效率。
节省开支: 提高服务器利用率,降低IT支出。
简化配置: 将运行环境打包保存至容器,使用时直接启动即可。
快速迁移和扩展:可夸平台运行在物理机、虚拟机、公有云等环境,良好的兼容性可以方便将应用从A宿主机迁移到B宿主机,甚至是A平台迁移到B平台。
Docker 的缺点:
隔离性:各应用之间的隔离不如虚拟机彻底。
1.7 docker(容器)的核心技术
容器规范
容器技术除了的docker之外,还有coreOS的rkt,还有阿里的Pouch,
为了保证容器生态的标准性和健康可持续发展,包括Linux基金会、Docker、微软、红帽谷歌和、IBM、等公司
在2015年6月共同成立了一个叫open container(OCI)的组织,其目的就是制定开放的标准的容器规范。
目前OCI一共发布了两个规范,分别是runtime spec(容器的运行时,定义容器是怎么运行的)和image format spec(镜像格式,定义了在打镜像的时候,必须按照这个标准打镜像),有了这两个规范,不同的容器公司开发的容器只要兼容这两个规范,就可以保证容器的可移植性和相互可操作性。
容器 runtime(容器运行时)
runtime 是真正运行容器的地方,因此为了运行不同的容器,runtime需要和操作系统内核紧密合作相互在支持,以便为容器提供相应的运行环境。
目前主流的三种 runtime:
1> Lxc: linux上早期的runtime,Docker早期就是采用lxc作为runtime。
2> runc:目前Docker默认的runtime,runc遵守OCI规范,因此可以兼容lxc。
3> rkt: 是CoreOS开发的容器runtime,也符合OCI规范,所以使用rktruntime也可以运行Docker容器。
容器管理工具
管理工具连接runtime与用户,对用户提供图形或命令方式操作,然后管理工具将用户操作传递给runtime执行。
1> lxc是lxd的管理工具。lvd是一个守护进程,通过lxc调用。
2> Runc的管理工具是docker engine,docker engine包含后台deamon(服务端)和cli(客户端)两部分,
大家经常提到的Docker就是指的docker engine。通过docker version可以查看详细信息
3> Rkt的管理工具是rkt cli。
容器定义工具
容器定义工具允许用户定义容器的属性和内容,以方便容器能够被保存、共享和重建。
Docker image(镜像):是docker容器的模板,runtime依据docker image创建容器。
Dockerfile:包含N个命令的文本文件,通过dockerfile创建出docker image。
ACI(App container image):与docker image类似,是CoreOS开发的rkt容器的镜像格式。
制作docker image的两种常见方式:
1> dockerfile
2> 手动打镜像,将一个正在运行中的容器,提升为一个镜像(不常用)
Registry 镜像仓库
Registry:用于保存镜像
统一保存镜像而且是多个不同镜像版本的地方,叫做镜像仓库。
打完镜像需要存放到一个地方,目的是为了做分发/共享,而且一定实在内网中进行
1> Image registry:docker官方提供的私有仓库部署工具。
2> Docker hub:docker官方的公共仓库,已经保存了大量的常用镜像,可以方便大家直接使用。
3> Harbor:vmware提供的自带web界面自带认证功能的镜像仓库,目前有很多公司使用。
镜像访问示例:
harbor地址/镜像仓库的名称(一般会以业务名称命名)/镜像
172.18.200.101/project/centos:7.2.1511
172.18.200.101/project/centos: latest
172.18.200.101/project/java-7.0.59:v2
在机房内部做代码升级
在公网上拉镜像会占据带宽出口的带宽,在端时间内做多个应用的升级,会频繁的上传和拉去镜像,影响其他业务的正常访问,不可取。
我们通常会在公司内部,搭建一个镜像服务器叫Harbor,在做代码升级时候直接让web服务器通过内网拉去镜像
打镜像或者上传下载等操作是不会影响带宽出口的带宽,也不会影响业务
编排工具
当多个容器在多个主机运行的时候,单独管理容器是相当复杂而且很容易出错,而且也无法实现某一台主机宕机后容器自动迁移到其他主机从而实现高可用的目的,也无法实现动态伸缩的功能。因此需要有一种工具可以实现统一管理、动态伸缩、故障自愈、批量执行等功能,这就是容器编排引擎。
容器编排通常包括容器管理、调度、集群定义和服务发现等功能。
动态伸缩: 在业务量高峰期自动多创建一部分容器,在高峰期过后再自动回收
故障自愈: 当其中一台节点挂掉以后,编排工具可以发现节点宕机,会自动将服务在其他节点起来
批量执行;可以将某些容器直接批量删除或重启
目前比较主流的编排引擎
1> Docker swarm:docker 开发的容器编排引擎。
2> Kubernetes:google领导开发的容器编排引擎,内部项目为Borg,且其同时支持docker和CoreOS。
3> Mesos+Marathon:通用的集群组员调度平台,mesos(实现资源分配)与marathon(容器编排平台)一起提供容器编排引擎功能。
服务发现
假如业务量突然猛增,需要扩展容器,如何保证扩展的容器被用户访问到?
1> 更改负载均衡,手动添加
2> k8s可以实现自动添加功能,叫做动态识别
k8s中有一个内置服务叫做service,跑在k8s的内部环境中,它会打通各个服务器的内网通信,service是逻辑上存在的东西。
service是k8s内部的负载均衡,我们会给它配置一些label标签,label会具备选择功能,他会选择出来容器上所带的特征,在k8s称为pod(容器的名称、属于什么业务、或者自定义标签)。将所选择的标签进行自动发现、自动添加,我们访问的时候并不是直接访问容器,尤其是在k8s上,并不能直接访问容器。
我们会先访问service,然后再将service在宿主机上暴露一个端口(30001),30001会将请求转发给service
所以说当我们访问的时候,实际上访问的是30001端口,30001会转发给service,service再将我们的请求交给各个后端的容器。service会自动发现已经起来的容器
1.8 docker容器的依赖技术
1. 容器网络:
docker自带的网络docker network仅支持管理单机上的容器网络,当多主机运行的时候需要使用第三方开源网络,
例如calico、flannel等,用于解决容器跨主机通信,以及网络管理(自动分配IP地址,保证每个容器拿到的IP地址都不一样)
2. 服务发现:
容器的动态扩容特性决定了容器IP也会随之变化(每个服务器都有一个独立的地址段),因此需要有一种机制可以自动识别并将用户请求动态转发到新创建的容器上,kubernetes自带服务发现功能,需要结合kube-dns服务解析内部域名。
3. 容器监控:
可以通过原生命令docker ps/top/stats查看容器运行状态,另外也可以使heapster/Prometheus等第三方监控工具监控容器的运行状态。
4. 数据管理:
容器的动态迁移会导致其在不同的Host之间迁移,因此如何保证与容器相关的数据也能随之迁移或随时访问,可以使用逻辑卷/存储挂载等方式解决。
5. 日志收集:
docker原生的日志查看工具docker logs,但是容器内部的日志需要通过ELK等专门的日志收集分析和展示工具进行处理。
搭建docker需要解决的问题
监控报警
日志收集
代码部署回滚
网络问题-容器跨主机通信和IP地址管理
数据存储-依赖于外部存储或者PV/PVC
动态识别-容器扩容之后,自动让用户访问到新创建的容器
二、docker 存储引擎
目前docker的默认存储引擎为overlay2,不同的存储引擎需要相应的系统支持,如需要磁盘分区的时候传递d-type文件分层功能,即需要传递内核参数开启格式化磁盘的时候的指定功能。
支持d-type的功能的参数是 ftype=1
历史更新信息:
https://github.com/moby/moby/blob/master/CHANGELOG.md
官方文档关于存储引擎的选择文档:
https://docs.docker.com/storage/storagedriver/select-storage-driver/
存储驱动类型:
1> AUFS(AnotherUnionFS)是一种 Union FS,是文件级的存储驱动。
所谓 UnionFS 就是把不同物理位置的目录合并mount到同一个目录中。
简单来说就是支持将不同目录挂载到同一个虚拟文件系统下的文件系统。
这种文件系统可以一层一层地叠加修改文件。无论底下有多少层都是只读的,只有最上层的文件系统是可写的。
当需要修改一个文件时,AUFS 创建该文件的一个副本,使用 CoW 将文件从只读层复制到可写层进行修改,结果也保存在可写层。
在Docker中,底下的只读层就是image,可写层就是Container,
是Docker 18.06及更早版本的首选存储驱动程序,在内核3.13上运行Ubuntu 14.04时不支持overlay2。
OverlayFS是一种现代的联合文件系统,与AUFS类似,但速度更快且实现更简单。
Docker为OverlayFS提供了两个存储驱动程序:原始的overlay,更新的和更稳定的overlay2。
2> Overlay:一种Union FS文件系统,Linux内核3.18后支持。
3> overlay2: Overlay的升级版,到目前为止,所有Linux发行版推荐使用的存储类型。
4> devicemapper:是CentOS 和 RHEL的推荐存储驱动程序,
因为之前的内核版本不支持overlay2,但是当前较新版本的CentOS 和 RHEL现在已经支持overlay2,
因此推荐使用 overlay2。
5> ZFS(Sun-2005)/btrfs(Oracle-2007):目前没有广泛使用。
6> vfs:用于测试环境,适用于无法使用copy-on-write文件系统的情况。 此存储驱动程序的性能很差,通常不建议用于生产。
Docker官方推荐首选存储引擎为 overlay2,devicemapper存在使用空间方面的一些限制,虽然可以通过后期配置解决,但是官方依然推荐使用overlay2,以下是网上查到的部分资料:
https://www.cnblogs.com/youruncloud/p/5736718.html
不推荐更改文件系统,更改文件系统,会导致所有数据丢失
更改存储引擎:
1> 停止Docker
2> vim /etc/docker/daemon.json
{
"storage-driver": "overlay"
}
3> 重启生效
systemctl restart docker
更改存储引擎会重新生成/var/lib/docker中的数据
如果docker数据目录是一块单独的磁盘分区而且是xfs格式的,
那么需要在格式化的时候加上参数-n ftype=1,否则后期在启动容器的时候会报错不支持dtype。
推荐是以较新的操作系统,以支持overlay2驱动程序,更好的支持UnionFS 联合文件挂载
在宿主机上启动一个容器,在容器中看,就只有一个文件系统/opt、/etc等目录结构
但是这个容器会在宿主机上有多个目录 work 工作目录 image 保存镜像的目录 diff 保存差异数据的目录
将这些目录联合起来都指向容器的系统盘,供容器使用,当从容器中看的时候,这些目录都在一起
并不知道这些目录是挂载在一块的,我们把这种方式叫做联合文件挂载
通过这种方法是来解决镜像的只读层
只读的意思是,我们的镜像在加载容器的时候,会将镜像拉取下来,放在某个位置
因为镜像中有文件系统(可执行程序、目录结构、应用环境以及代码)都会放到镜像中,是只读的
还有一个地方是可写的,在创建容器的时候,会生成一个可写目录,将可写的目录也挂载在容器中
当镜像加载完以后,底层是只读的,往镜像中写入数据会写到可写的目录中
在容器中查看可写的数据,没有任何区别,只是在的底层的宿主机上查看是两个完全不同的目录,一个是只读的,一个是可写的
还有一个目录叫做工作目录,容器在启动完成以后,会被锁定到work目录中去,
work目录其实在宿主机上就是最大的可跳转的空间,不可以跳到其他目录
这些目录挂载到容器中,供容器使用,我们称为联合挂载
联合挂载需要overlay2驱动引擎支持, overlay2又需要宿主机的文件系统支持(ext4、xfs)
centos 7.2在格式化系统盘的时候需要加上一个-n ftype=1才能支持overlay2,否则仅支持devicemapper