5.Spark框架入门
Spark框架入门
1. Spark概述
1.1 什么是Spark

![]()
- Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Hadoop与Spark历史
-
回顾Hadoop历史
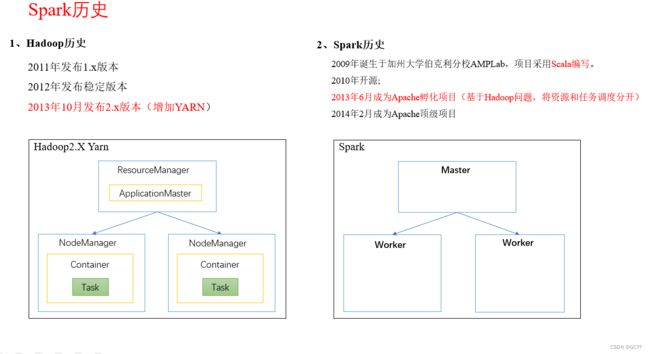
-
Spark历史
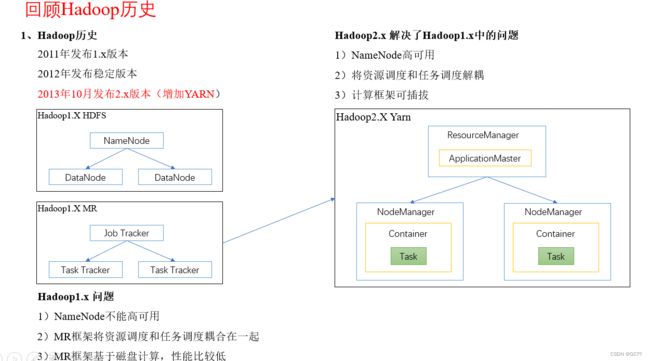
1.3 Hadoop与Spark框架对比
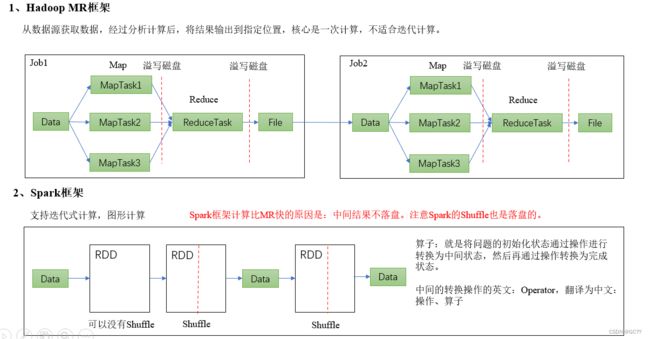
1.3.1 从时间节点

1.3.2 从功能上来看
hadoop
-
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架
-
作为Hadoop分布式文件系统,HDFS处于Hadoop生态圈的最下层,存储着所有的数据,支持着Hadoop的所有服务。它的理论基础源于Google的TheGoogleFileSystem这篇论文,它是GFS的开源实现。
-
MapReduce是一种编程模型,Hadoop根据Google的MapReduce论文将其实现,作为Hadoop的分布式计算模型,是Hadoop的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了HDFS的分布式存储和MapReduce的分布式计算,Hadoop在处理海量数据时,性能横向扩展变得非常容易。
-
HBase是对Google的Bigtable的开源实现,但又和Bigtable存在许多不同之处。HBase是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是Hadoop非常重要的组件。
Spark
-
Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
-
Spark Core中提供了Spark最基础与最核心的功能
-
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
-
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
由上面的信息可以获知,Spark出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实Spark一直被认为是Hadoop 框架的升级版。
1.3.3 选择hadoop或者spark
-
Hadoop MapReduce由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以Spark应运而生,Spark就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。
-
机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。而Spark所基于的scala语言恰恰擅长函数的处理。
-
Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
-
Spark和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
-
Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。
-
Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互。
-
Spark的缓存机制比HDFS的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR。
1.4 Spark内置模块
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0921FC5j-1655393770855)(assets/1649501577857.png)]
-
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
-
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
-
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
-
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
-
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
2. 编写WordCount案例实操
2.1 创建一个Maven项目WordCount
-
配置项目pom文件(pom.xml)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <groupId>com.gecgroupId> <artifactId>WordCountSparkartifactId> <version>1.0-SNAPSHOTversion> <properties> <maven.compiler.source>8maven.compiler.source> <maven.compiler.target>8maven.compiler.target> properties> <dependencies> <dependency> <groupId>org.apache.sparkgroupId> <artifactId>spark-core_2.12artifactId> <version>3.0.0version> dependency> dependencies> project>
2.2 创建数据文件
-
输入文件夹准备:在新建的WordCount项目名称上右键=》新建data目录=》在data文件夹上右键=》分别新建word.txt。每个文件里面准备一些word单词。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IoWEyOaf-1655393770855)(assets/1649603276040.png)]
-
编辑word.txt文件
hadoop scala spark hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop scala scala scala scala scala scala spark spark spark scala hadoop hadoop
-
2.3 编写scala类
package com.gec.bigdata.spark.wc
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_WordCount_Env {
def main(args: Array[String]): Unit = {
// TODO 使用Spark 25
// Spark是一个计算【框架】。
// 1. 能找到他 :增加依赖
// 2. 获取Spark的连接(环境)
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
// 读取文件
val lines = sc.textFile("data/word.txt")
println(lines)
println("--------------------")
// 将文件中的数据进行了分词
val words = lines.flatMap(_.split(" "))
// 将分词后的数据进行了分组
val wordGroup = words.groupBy(word => word)
// 对分组后的数据进行统计分析
val wordCount = wordGroup.mapValues(_.size)
// 将统计结果打印在控制台上
wordCount.collect().foreach(println)
sc.stop()
}
}
2.4 scala统计单词个数
2.4.1 创建集合
val lines = List("hello tom hello jerry", "hello jerry", "hello kitty")
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MOfYjdtk-1655393770856)(assets/1649608811936.png)]
2.4.2 先按空格切分
val lines_1 = lines.map(_.split(" "))
![]()
2.4.3 压平
val lines_2 = lines_1.flatten
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ba6y3uCZ-1655393770857)(assets/1649608862820.png)]
2.4.4 用flatMap 两步合并成一步
val lines_2= lines.flatMap(_.split(" "))
2.4.5 将每一个单词映射为元组
val wordToOne = lines_3.map(x=>(x,1))
//简化成以下写法
val wordToOne = lines_3.map((_,1))
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z0B7e4gv-1655393770857)(assets/1649608893689.png)]
2.4.5 分组
val grouped = wordToOne.groupBy(_._1)

2.4.6 组内求和
val grouped_1 = grouped.map(t => (t._1,t._2.size))
![]()
2.4.7 将map转化成List
val result = grouped_1.toList
![]()
2.4.8 排序
val result_1 = result.sortBy(_._2).reverse
![]()
2.4.9 合并为一句
val words = lines.flatMap(_.split(" ")).map((_,1)).groupBy(_._1).map(t=>(t._1,t._2.size)).toList.sortBy(_._2).reverse
2.5 reduce统计
- 将分词后的数据进行了分组,对分组后的数据进行统计分析
package com.atguigu.bigdata.spark.wc
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// TODO 使用Spark
// Spark是一个计算【框架】。
// 1. 能找到他 :增加依赖
// 2. 获取Spark的连接(环境)
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
// 读取文件
val lines = sc.textFile("data/word.txt")
// 将文件中的数据进行了分词
// word => (word, 1)
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map((_,1))
// 将分词后的数据进行了分组
// word => List((word,1), (word,1)) => List((word, 2))
val wordGroup = wordToOne.groupBy(_._1)
// 对分组后的数据进行统计分析
val wordCount = wordGroup.mapValues(
list => {
list.reduce(
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)._2
}
)
// 将统计结果打印在控制台上
wordCount.collect().foreach(println)
sc.stop()
}
}
list => {
list.reduce(
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)._2
}
)
// 将统计结果打印在控制台上
wordCount.collect().foreach(println)
sc.stop()
}
}