一、为什么选择Python?
1、Python 追求的是找到最好的解决方案,相比之下,其他语言追求的是多种解决方案。
2、Python 的最大优点,是使你能够专注于解决问题而不是去搞明白语言本身。
二、准备工作
1、软件安装
使用 Anaconda 和 PyCharm。
使用 Anaconda 能帮你安装好许多麻烦的东西,包括: Python 环境、pip 包管理工具、 常用的库、配置好环境路径等等。
使用 PyCharm 的原因是它的功能齐全,一站式解决所有问题,报错提醒也更齐全。
2、Anaconda 安装方法
进入 Anaconda 官网:https://www.anaconda.com/download/ (附百度网盘:链接:https://pan.baidu.com/s/1UHvGgeJ-bohPmA8zhvxH8Q 密码:cc13),选择适合你的电脑系统 Python 版本,下载安装即可。
3、PyCharm 安装方法
进入 PyCharm 官网:https://www.jetbrains.com/pycharm/download/ (附百度网盘:链接:https://pan.baidu.com/s/1W1KqsahuRcAAq038iEYvbg 密码:eowx),初学者下载免费的 Community 社区版安装即可。
4、Anaconda + PyCharm 配置方法
打开 PyCharm,点击 Create New Project 。
然后在 Interpreter 解释器这一栏,选择 anaconda3 这一项,然后点击 Create 完成创建。如果没有anaconda这一项的话,点击旁边的小齿轮图标,选择 add local ,然后选择 anaconda 文件路路径下的 python.exe。
点击 File - New,然后选择文件类型,比如 Python File 。
然后就可以开始快乐的写代码了,在菜单栏点击 Run 可以运行代码。
三、变量与字符串
1、变量
变量是编程中最基本的存储单位,变量会暂时性地储存你放进去的东西。
变量的名字叫做标识符。
Python 对大小写敏感,“a” 和 “A” 是两个不同的变量。
2、print()
打印是Python 中最常用的功能。
驼峰命名法
帕斯卡命名法
3、字符串
单引号、双引号、三引号,,其中单引号和双引号完全一样,三引号被用于过长段的文字或者是说明。
字符串的基本用法——合并
1 what_he_does = ' plays '
2 his_instrument = 'guitar'
3 his_name = 'Robert Johnson'
4 artist_intro = his_name + what_he_does + his_instrument
5 print(artist_intro) # Robert Johnson plays guitar
运行:

type()函数查看变量的类型
由于中文注释会打字报错,所以需要在文件开头加一行魔法注释 # coding=utf-8 ,也可以在设置里面找到“File Encodings”设置为 UTF-8
数据类型转换
1 num = 1
2 string = '1'
3 num2 = int(string)
4 print(num + num2) # 输出2
字符串相乘
1 words = 'words' * 3
2 print(words) # wordswordswords
1 word ='a loooooong word'
2 num =12
3 string = 'bang!'
4 total = string * (len(word) - num) # 这里的意思是total = 'bang' * (16 - 12)
5 print(total) # bang!bang!bang!bang!
字符串的分片与索引
字符串可以通过 string[x] 的方式进行索引、分片,也就是加一个[]。
分片(slice)获得的每个字符串可以看做是原字符串的一个副本。
1 name = 'My name is Mike'
2 print(name[0]) # M
3 print(name[-4]) # M
4 print(name[11:14]) # Mik
5 print(name[11:15]) # Mike
6 print(name[5:]) # me is Mike
7 print(name[:5]) # My na
8 '''
9 1、:两边分别代表着字符串的分给是从哪里开始,并到哪里结束。
10 2、以name[11:14]为例,截取的编号从第11个字符开始,到位置为14但不包括第14个字符结束。
11 3、像name[5:]这样的写法代表着从编号为5的字符到结束的字符串分片。
12 4、像name[:5]代表着从编号为0的字符开始到编号为5单不包括第5个字符的字符分片
13 '''

找出你朋友中的魔鬼
1 word = 'friends'
2 find_the_evil_in_your_friends = word[0] + word[2:4] + word[-3:-1]
3 print(find_the_evil_in_your_friends) # fiend
过长的代码段可以使用'\'来进行换行
实际项目中的应用

字符串的方法
Python 是面向对象进行编程的语言,而对象拥有各种功能、特性,专业术语称之为——方法(Method)。
隐藏信息
1 phone_number = '1386-666-0006'
2 hiding_number = phone_number.replace(phone_number[:9], '*' * 9)
3 '''这里使用了新的字符串方法replace()进行“遮挡”,replace方法的括号中,第一个phone_number[:9] 代表要被替换掉的部分,
4 后面的'*' * 9 表示简要替换成什么字符,也就是把*乘以9,显示9个* '''
5 print(hiding_number) #输出 *********0006
模拟手机通讯录中的电话号码联想功能
1 search = '168'
2 num_a = '1386-168-0006'
3 num_b = '1681-222-0006'
4 print(search + ' is at ' + str(num_a.find(search) + 1) + ' to ' +str(num_a.find(search) + len(search)) + ' of num_a')
5 # 168 is at 6 to 8 of num_a
6
7 print(search + ' is at ' + str(num_b.find(search) + 1) + ' to ' +str(num_b.find(search) + len(search)) + ' of num_b')
8 # 168 is at 1 to 3 of num_b
字符串格式化符
当字符串中有多个“空”需要填写时,可以使用.format()进行批处理。
填空题
____ a word she can get what she ____ for.
1 print('{} a word she can get what she {} for.'.format('with', 'came'))
2 print('{preposition} a word she can get what she {verb} for.'.format(preposition='with', verb='came'))
3 # preposition 介词 , verb 动词
4 print('{0} a word she can get what she {1} for.'.format('with', 'came'))
利用百度提供的天气api实现客户端天气插件的开发的代码片段
1 city = input("write down the name of city:")
2 url = "http://apistore.baidu.com/microservice/weather?citypinyin={}.format(city)"
四、最基本的魔法函数
1、重新认识函数
print 是一个放入对象就能将结果打印的函数。
input 是一个让用户输入信息的函数。
len 是一个可以测量对象长度的函数。
int 是一个可以将字符串类型的数字转换成证书类型的函数。
Python 中所谓的使用函数就是把你要处理的对象放到一个名字的括号里面就可以了。
内建函数(Bulit-int Functions),在安装完成之后就可以使用它们,是“自带”的。
2、开始创建函数
def(即 define,定义)的含义是创建函数,也就是定义一个函数。
arg(即 argument,参数),另外一种写法是parameter 。
return 即返回结果。
咒语: Define a function named ‘function’ which has two arguments : args1 and args2, returns the result——'Something'
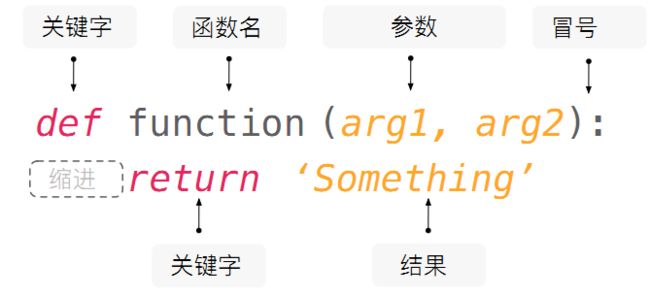
注意:
1、def 和 return 是关键字(keyword),Python 就是靠识别这些特定的关键字来明白用户的意图,实现更为复杂的编程。
2、在闭合括号后面的冒号必不可少,而且需要使用英文输入法进行输入,否则报错(SyntaxError: invalid character in identifier)。
3、在IDE中冒号后面回车(换行)会自动得到一个缩进。函数缩进后面的语法被称为语句块(block)。缩进是为了表明语句和逻辑的从属关系,是 Python 最显著的特征之一。
摄氏度转换华氏度
1 def fahrenheit_converter(C):
2 fahrenheit = C * 9 / 5 + 32
3 return str(fahrenheit) + '°F' # 计算的结果类型是float,不能与字符串"°F"相合并,所以需要先用str函数进行转换
4
5
6 # 把调用函数这种行为叫做“调用”(call),这里是有摄氏度(Celsius)转换器将35摄氏度转换成华氏度(fahrenheit),
7 # 将结果存储在名为C2F的变量并打印出来
8 C2F = fahrenheit_converter(35)
9 print(C2F) # 95.0°F
4、在 Python 中,return 是可选的(optional),意味着不写 return 也可以顺利地定义一个函数并使用,只不过返回值是‘None’ 。
5、在 Python 中,definition 和 declaration(声明) 是一体的。
6、练习题
(1)初级难度:设计一个重量转换器,输入以‘g’为单位的数字后返回换算成'kg'的结果。
参考答案:
1 def g2kg(g):
2 return str(g/1000) + 'kg'
3
4
5 print(g2kg(2000)) # 调用函数并打印结果
运行结果:
![]()
(2)中级难度:设计一个求直角三角形斜边长的函数(两条直角边为参数,求最长边),如果直角边边长分别为3和4,那么返回的结果应该像这样:
![]()
参考答案:
1 def Pythagorean_theorem(a, b):
2 return 'The right triangle third side\'s length is {}'.format((a**2 + b**2) ** (1/2))
3 # 等价于a的平方与b的平方之和的1/2次方(即开根)
4
5
6 print(Pythagorean_theorem(3, 4)) # 调用函数并打印结果
运行结果:
![]()
3、传递参数与参数类型
传递参数的方式有两种:
位置参数(positional argument)
关键词参数(keyword argument)
把函数的名称定位trapezoid_area(梯形面积),设定参数为base_up,base_down(下底),height(高)
(1)位置参数(positional argument)
1 def trapezoid_area(base_up, base_down, height):
2 return 1/2 * (base_up + base_down) * height
调用函数
1 trapezoid_area(1, 2, 3)
2 # 填入的参数1,2,3分别对应着参数base_up, base_down, height,这种传入参数的方式被称为位置参数
(2)关键词参数(keyword argument)
1 trapezoid_area(base_up=1, base_down=2, height=3)
2 # 将每个参数名称后面赋予一个我们想要传入的值,这种以名称作为一一对应的参数传入方式被称作是关键词参数
4、设计自己的函数
认识新的函数——open
这个函数使用起来很简单,只需要传入两个参数就可以正常运转了:文件的完整路径和名称,打开的方式。
在E盘的根目录下创建text.txt
1 file = open('E://text.txt', 'w')
2 file.write('hello World')
运行程序后

设计函数
需求:传入参数 name 与 msg 就可以控制在E盘根目录写入的文件名称和内容的函数text_create, 并且如果当E盘根目录没有这个可以写入的文件时,那么就要创建一个之后,再写入。
1 def text_create(name, msg): # 定义函数的名称和参数
2 e_path = 'E:' # 定义 open 函数要打开的路径
3 full_path = e_path + name + '.txt' # 传入的参数加上路径再加上后缀就是完整的文件路径
4 file = open(full_path, 'w')
5 # 打开文件,'w'参数代表作为写入模式,意思:如果没有就在该路径创建一个有该名称文本,有则追加覆盖文本内容。
6
7 file.write(msg) # 写入传入的参数 msg,即内容
8 file.close() # 关闭文本
9 print('Done') # 表明上面的所有语句均已执行,提示作用。
敏感词过滤:
需求:定义一个函数text_filter 的函数,传入参数 word,cencored_word 和 changed_word 实现过滤,敏感词cencored_word 默认为 'lame',替换词changed_word默认为'Awesome'
1 def text_filter(word, censored_word='lame', changed_word='Awesome'):
2 return word.replace(censored_word, changed_word)
3
4
5 text_filter('Python is lame!') # 调用函数
把两个函数合并
创建一个名为text-consored_create 的函数,功能是在桌面上创建一个文本可以在其中输入文字,但是如果信息中含有敏感词的话将被默认过滤后写入文件。其中,文本的文件名参数为 name,信息参数为msg
1 def censored_text_create(name, msg):
2 clean_msg = text_filter(msg)
3 text_create(name, clean_msg)
4
5
6 censored_text_create('Try', 'lame!lame!lame!') #调用函数
数学运算
a=10,b=20
+ 加,两个对象相加 a + b 输出结果 30
- 减,得到负数或是一个数减去两外一个数 a - b输出结果 -10
* 乘,两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200
/ 除,x除以y b / a 输出结果 2
% 取模,返回除法的余数 b % a 输出结果 0
** 幂,返回x的y次幂 a**b为10的20次方,输出结果100000000000000000000
// 取整数,返回商的整数部分 9//2 输出结果 4, 9.0//2.0 输出结果 4.0
五、循环与判断
逻辑控制与循环
逻辑判断——True & False
if-else 结构是常见的逻辑控制的手段。
逻辑判断的最基本准则——布尔类型(Boolean Type)
布尔类型(Boolean)的数据只有两种类型,True 和False(需要注意的是首字母大写)。
在命令行/终端环境输入代码(更快展示结果)
但凡能够产生一个布尔值的表达式为布尔表达式(Boolean Expressions)
比较运算(Comparison)
== 左右两边等值的时候返回 True
!= 左右两边不相等时返回 True
> 左边大于右边的时候返回 True
< 左边小于右边的时候返回 True
<= 左边小于或等于右边的时候返回 True
>= 左边大于或等于右边的时候返回 True
比较运算还支持更为复杂的表达方式,例如:
多条件的比较。先给变量赋值,并在多条件下比较大小:
1 middle = 5
2 1< middle < 10 # True
变量的比较。将两个运算结果储存在不同的变量中,再进行比较:
1 two = 1+1 2 three = 1+3 3 two# True
字符串的比较。其实就是对比左右两边的字符串是否完全一致,下面的代码就是不一致的,因为在 Python 中有着严格的大小写区分:
1 'Eddie Van Helen' == 'eddie van helen' # False
两个函数产生的结果进行比较:比较运算符两边会先行调用函数后再进行比较,其结果等价于10>19 :
1 abs(-10) > len('length of this word') # false,其中abs() 是一个会返回输入参数的绝对值的函数
比较运算的一些小问题
不同类型的对象不能使用“<,>,<=,>=”进行比较,却可以使用‘==’和‘!=’,例如字符串和数字:
1 42 > 'the answer' # 无法比较
2 42 == 'the answer' # False
3 42 != 'the answer' # True
需要注意的是,浮点和整数虽是不同类型,但是不影响到比较运算:
1 5.0 == 5 # True
2 3.0 > 1 # True
“=”在 Python 中代表着赋值,并非是“等于”,使用“==”这种表达方式,可以理解成是表达两个对象的值是相等的。
True 和 False 对于计算机就像是1和0一样,如果在命令行中敲入True + True +False 实际上等价于1+1+0
类似 1<>3这种表达式,与 1!=3 是等价的。
成员运算符和身份运算符(Membership & Identify Operators)
成员运算符和身份运算符的关键词是 in 和 is 。把 in 放在两个对象中间的含义是,测试前者是否存在于 in 后面的集合中。
简单易懂的集合类型——列表(list)
字符串、浮点、整数、布尔类型、变量甚至是另一个列表都可以存储在列表中,列表是非常实用的数据结构。
1 # album = [] # 此时列表是空的
2 album = ['Black Star', 'David Bowie', 25, True] # 创建了一个非空的列表
3 album.append('new song') # 使用列表的 append 方法可以向列表中添加新的元素,且自动排列到列表的尾部
4 print(album[0], album[-1]) # 列表的索引,这里是打印列表中的第一个和最后一个元素
5 print('Black Start' in album) # 使用in来测试字符串'Black Start'是否在列表 album 中,在则显示 True,不在则显示 False
is 和 is not ,它们是表示身份鉴别(Identify Operator)的布尔运算符,in 和 not in 则是表示归属关系的布尔运算符号(Membership Operator)。
在 Python 中,任何一个对象都要满足身份(Identify)、类型(Type)、值(Value)这三个点,缺一不可。is 操作符号就是用来进行身份的对比的。
在 Python 中,任何对象都可判断其布尔值,除了 0 、None 和所有空的序列与集合(列表,字典,集合)布尔值为 False 之外,其他为 True ,我们可以使用函数 bool()进行判别。
布尔运算符(Boolean Operators)
and 、or 用于布尔值之间的运算,具体规则如下:
not x 如果 x 是True,则返回 False,否则返回 True
x and y and 表示“并且”,如果 x 和 y 都是True,则返回 True;如果x 和 y 有一个 False,则返回 False
x or y or 表示“或者”,如果 x 或 y 有其中一个是 True,则返回 True;如果 x 和 y 都是 False ,则返回 False
and 和 or 经常用于处理复合条件,类似于1 < n <3,也就是两个条件同时满足。
条件控制
条件控制其实就是if …else 的使用。
用一句话概括 if…else 的作用:如果…条件是成立的,就做…;反之,就做…
所谓条件(condition)指的是成立的条件,即是返回值为 True 的布尔表达式。
1 def account_login(): # 定义函数,并不需要参数
2 password = input('Password:') # 使用 input 获得用户输入的字符串并存储在变量 password 中
3 if password == '12345': # 设置条件,如果用户输入的字符串和预设的密码12345相等时,就执行打印文本'Login success!'
4 print('Login success!')
5 else:
6 print('Wrong password or invalid input!') # 一切不等于预设密码的输入结果,全部会执行打印错误提示
7 account_login() # 再次调用函数,让用户再次输入密码
8
9
10 account_login() # 调用函数
如果 if 后面的布尔表达式过长或者难以理解,可以采取给变量赋值的方法来存储布尔表达式返回的布尔值 True 或 False
1 def account_login():
2 password = input('Password:')
3 password_correct = password == '12345'
4 # 如果 if 后面的布尔表达式过长或者难以理解,可以采取给变量赋值的方法来存储布尔表达式返回的布尔值 True 或 False
5 if password_correct:
6 print('Login success!')
7 else:
8 print('Wrong password or invalid input!')
9 account_login()
一般情况下,设计程序的时候需要考虑到逻辑的完备性,并对用户可能会产生困扰的情况进行预防性设计,这时候会有多条件判断。多条件判断只需要在 if 和 else 之间加上elif ,用法和 if 是一致的。而且条件的判断也是依次进行的,首先看条件是否成立,如果成立那么就进行下面的代码,如果不成立就接着顺次地看下面的条件是否成立,如果都不成立则运行 else 对应的语句。
1 password_list = ['*#*#', '12345'] # 创建一个列表,用于储存用户的密码、初始密码和其他数据(对实际数据库的简化模拟)
2
3
4 def account_login(): # 定义函数
5 password = input('Password:') # 使用input 获得用户输入的字符串并存储在变量 password 中
6
7 # 当用户输入的密码等于密码列表最后一个元素的时候(即用户最新设定的密码,登录成功)
8 password_correct = password == password_list[-1]
9 password_reset =password == password_list[0]
10 if password_correct:
11 print('Login success!')
12
13 # 当用户输入的密码等于密码列表中第一个元素的时候(即重置密码的“口令”)触发密码变更,并将变呢狗的密码存储至列表的最后一个,称为最新的用户密码
14 elif password_reset:
15 new_password = input('Enter a new password:')
16 password_list.append(new_password)
17 print('Your password has changed successfully!')
18 account_login()
19
20 # 一切不等于预设密码的输入结果,全部会执行打印错误提示,并且再次调用函数,让用户输入密码
21 else:
22 print('Wrong password or invalid input!')
23 account_login()
24
25
26 account_login() # 调用函数
代码块(Code Block),代码块的产生是由于缩进,具有相同缩进量的代码实际上实在共同完成相同层面的事情。
循环(Loop)
for循环
1 for every_letter in 'Hello world':
2 print(every_letter) # 使用 for 循环打印出"hello world" 这段字符串中的每一个字符。
把 for 循环所做的事情概括成一句话就是:于…其中的每一个元素,做…事情。
1 for num in range(1, 11): # 不包括11,因此实际范围是1-10
2 print(str(num) + ' + 1 = ', num + 1)
3 # 将1-10范围内的每一个数字依次装入变量 num 中,每次展示一个 num +1 的结果。在这个过程中,变量 num 被循环赋值10次。
嵌套循环(Nested Loop)
嵌套循环实现“九九乘法表”
1 for i in range(1, 10):
2 for j in range(1, 10):
3 print('{} × {} = {}'.format(i, j, i*j))
while 循环
for 循环会在可迭代的序列被穷尽的时候停止,while 则是在条件不成立的时候停止,因此 while 的作用概括成一句话就是:只要…条件成立,就一直做…
1 while 1 < 3:
2 print('1 is smaller that 3')
3 # 在终端或者命令行中按 Ctrl + C 停止运行,在 PyCharm 中则点击红色的 X 停止
4 # 一定要及时停止运行代码,因为在 while 后面的表达式是永远成立的,所以 print 会一直进行下去直到你的CPU过热。
5 # 这种条件永远为 True 的循环,我们称之为死循环(Infinite Loop)
让 while 循环停下来的方法:
(1)在循环过程中制造某种可以使循环停下来的条件
1 count = 0
2 while True:
3 print('Repeat this line!')
4 count = count + 1
5 if count == 5:
6 break
(2)改变使循环成立的条件
1 password_list = ['*#*#', '12345'] # 创建一个列表,用于储存用户的密码、初始密码和其他数据(对实际数据库的简化模拟)
2
3
4 def account_login(): # 定义函数
5 tries = 3
6 while tries > 0: # 如果 tries > 0 这个条件成立,那么便可输入密码,从而执行辨别密码是否正确的逻辑判断
7 password = input('Password:') # 使用input 获得用户输入的字符串并存储在变量 password 中
8
9 # 当用户输入的密码等于密码列表最后一个元素的时候(即用户最新设定的密码,登录成功)
10 password_correct = password == password_list[-1]
11 password_reset = password == password_list[0]
12 if password_correct:
13 print('Login success!')
14
15 # 当用户输入的密码等于密码列表中第一个元素的时候(即重置密码的“口令”)触发密码变更,并将变呢狗的密码存储至列表的最后一个,称为最新的用户密码
16 elif password_reset:
17 new_password = input('Enter a new password:')
18 password_list.append(new_password)
19 print('Your password has changed successfully!')
20 account_login()
21
22 # 一切不等于预设密码的输入结果,全部会执行打印错误提示,并且再次调用函数,让用户输入密码
23 else:
24 print('Wrong password or invalid input!')
25 tries = tries - 1 # 当密码输入错误时,可尝试的次数 tries 减少 1
26 print(tries, 'times left')
27 else:
28 print('Your account has been suspended') # while 循环的条件不成立时,就意味着尝试次数用完,通知用户账号被锁。
29
30
31 account_login() # 调用函数
练习题
1、设计这样一个函数,在桌面的d文件夹上创建10个文本,以数字给它们命名。
1 # 在桌面的d文件夹上创建10个文本,以数字给它们命名 2 def text_creation(): 3 # 创建文本的路径 4 path = 'C://Users//Lamfai//Desktop//d//' 5 for name in range(1, 11): 6 with open(path + str(name) + '.txt', 'w') as text: 7 text.write(str(name)) 8 text.close() 9 print('Done') 10 11 12 # 函数调用 13 text_creation()
运行结果:

2、复利是一件神奇的事情,正如富兰克林所说:“复利是能够将所有铅块变成金块的石头”。设计一个复利计算函数 invest(),它包含三个参数:amount(资金),rate(利率),time(投资时间)。 输入每个参数后调用函数,应该返回每一年的资金总额。它看起来就应该像这样(假设利率为5%)。
1 # 复利公式 2 def invest(amount, rate, time): 3 print("principal amount:{}".format(amount)) 4 for t in range(1, time + 1): 5 amount = amount * (1 + rate) 6 print("year {} :${}".format(t, amount)) 7 8 9 # 本金为100美元,利率为5%的8年的本息和 10 invest(100, .05, 8)
运行结果: 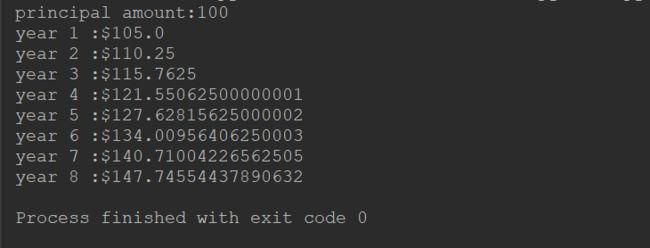
3、打印100以内的偶数。
# 打印100以内的偶数 def even_print(): for i in range(1, 101): if i % 2 == 0: print(i) even_print()
综合练习
六、数据结构
数据结构(Data Structure)
储存大量数据的容器,在 Python 中被称为内置数据结构(Built-in Data Structure)
Python 有四种数据结构,分别是:列表、字典、元组、集合。
list = [val1,val2,val3,val4]
dict = {key1:val1,key2:val2}
tuple = (val1,val2,val3,val4)
set = {val1,val2,val3,val4}
列表(list)
列表中的每一个元素都是可变的,这意味着我们可以在列表中添加、删除和修改元素。
列表中的元素是有序的,也就是说每一个元素都有一个位置,我们通过输入位置而查询该位置所对应的值,试着输入:
1 Weekday = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
2 print(Weekday[0]) # 输出Monday
列表可以容纳 Python 中的任何对象。
列表的增删改查
1、列表的插入。在使用 insert 方法的时候,必须指定在列表中要插入新的元素的位置,插入元素的实际位置是在指定元素之前的位置,如果指定插入的位置在列表中不存在(实际上是超出指定列表长度),那么这个元素一定会被放在列表的最后位置。
1 fruit = ['pineapple', 'pear']
2 fruit.insert(1, 'grape')
3 print(fruit) # 输出['pineapple', 'grape', 'pear']
另外一种插入的方法
1 fruit = ['pineapple', 'pear']
2 fruit[0:0] = ['Orange']
3 print(fruit)# 输出['Orange', 'pineapple', 'pear']
2、删除列表中元素的方法是使用 remove()
1 fruit = ['pineapple', 'pear', 'grape']
2 fruit.remove('grape')
3 print(fruit) # 输出['pineapple', 'pear']
另外一种删除的方法,使用 del 关键字来声明
1 fruit = ['pineapple', 'pear', 'grape']
2 del fruit[0:2]
3 print(fruit) # 输出['grape']
3、替换修改其中的元素
1 fruit = ['pineapple', 'pear', 'grape']
2 fruit[0] = 'Grapefruit'
3 print(fruit) # 输出['Grapefruit', 'pear', 'grape']
4、查询元素
列表的索引与字符串的分片十分相似,同样是正反两种索引方式,只要输入对应的位置就会返回给你这个位置上的值。
1 periodic_table = ['H', 'He', 'Li', 'Be', 'B', 'C', 'N', 'O', 'F', 'Ne']
2 print(periodic_table[0]) # H
3 print(periodic_table[-2]) # F
4 print(periodic_table[0:3]) # ['H', 'He', 'Li']
5 print(periodic_table[-10:-7]) # ['H', 'He', 'Li']
6 print(periodic_table[-10:]) # ['H', 'He', 'Li', 'Be', 'B', 'C', 'N', 'O', 'F', 'Ne']
7 print(periodic_table[:9]) # ['H', 'He', 'Li', 'Be', 'B', 'C', 'N', 'O', 'F']
字典(Dictionary)
使用名称 — 内容进行数据的构建,在 Python 中分别对应着键(key) — 值(value),习惯上称之为键值对。
字典的特征总结如下:
1、字典中数据必须是以键值对的形式出现的。
2、逻辑上讲,键是不能重复的,而值可以重复。
3、字典中的键(key)是不可变的,也就是无法修改的;而值(value)是可变的,可修改的,可以使任何对象。
1 NASDAQ_code = {
2 'BIDU':'Baidu',
3 'SINA':'Sina',
4 'YOKU':'Youku'
5 }
字典的增删改查
1、按照映射关系创建一个字典
1 NASDAQ_code = { 'BIDU': 'Baidu', 'SINA': 'Sina'}
2、添加
1 NASDAQ_code['YOUKU'] = 'Youku'
2 print(NASDAQ_code)
添加多个元素的方法 update()
1 NASDAQ_code = { 'BIDU': 'Baidu', 'SINA': 'Sina'}
2 NASDAQ_code.update({'FB': 'Facebook', 'TSLA': 'Tesla'})
3 print(NASDAQ_code)
3、删除使用 del 方法
1 del NASDAQ_code['FB']
元组(Tuple)
元组其实可以理解成一个稳固版的列表,因为元组是不可修改的,因此在列表中的存在的方法均不可以使用在元组上,但是元组是可以被查看索引的,方式就和列表一样。
1 letters = ('a', 'b', 'c', 'd', 'e', 'f', 'g')
2 print(letters[0])
集合(Set)
集合更接近数学上集合的概念。每一个集合中的元素是无序的、不重复的任意对象,我们可以通过集合去判断数据的从属关系,有时还可以通过集合把数据结构中重复的元素减掉。
集合不能被切片也不能被索引,除了做集合运算之外,集合元素可以被添加还有删除。
1 a_set = {1, 2, 3, 4}
2 a_set.add(5)
3 print(a_set) # {1, 2, 3, 4, 5}
4 a_set.discard(5)
5 print(a_set) # {1, 2, 3, 4}
数据结构的一些技巧
多重循环
sorted 函数按照长短、大小、英文字母的顺序给每个列表中的元素进行排序。这个函数会经常在数据的展示中石油,其中有一个非常重要的地方,storted 函数并不会改变列表本身(先将列表进行复制,然后再进行顺序的整理)。
1 num_list = [6, 2, 7, 4, 1, 3, 5]
2 print(sorted(num_list)) # [1, 2, 3, 4, 5, 6, 7]
在使用默认参数 reverse 后,列表可以被按照逆序整理。
1 num_list = [6, 2, 7, 4, 1, 3, 5]
2 print(sorted(num_list)) # [1, 2, 3, 4, 5, 6, 7]
3 print(sorted(num_list, reverse=True)) # [7, 6, 5, 4, 3, 2, 1]
推导式(List comprehension)
数据结构中的推导式,也叫列表的解析式。
1 import time
2
3 # 普通写法
4 a = []
5 t0 = time.clock()
6 for i in range(1, 20000):
7 a.append(i)
8 print(time.clock() - t0, "seconds process time")
9
10 # 列表解析式,不仅非常方便,并且在执行效率上要远远胜于前者
11 t0 = time.clock()
12 b = [i for i in range(1, 20000)]
13 print(time.clock() - t0, "seconds process time")
循环列表时获取元素的索引
1 letters = ('a', 'b', 'c', 'd', 'e', 'f', 'g')
2 for num, letters in enumerate(letters):
3 print(letters, 'is', num+1)
综合项目
词频统计
1 import string
2 path = 'E:\\Walden.txt'
3 with open(path, 'r') as text:
4 words = text.read().split()
5 print(words)
6 for word in words:
7 print('{}-{} times'.format(word, words.count(word)))
8 '''
9 这个代码的缺点:
10 1、有一些带标点符号的单词背单独统计了次数
11 2、有些单词不止一次地展示了出现的次数
12 3、由于 Python 对大小写敏感,开头大写的单词背单独统计了
13 '''
根据上面代码的缺点进行调整,对单词进行预处理
1 import string # 引入了一个新的模块 string,里面静静是包含了所有的标点符号——!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
2
3 path = 'E:\\Walden.txt' # 文本路径
4
5 with open(path, 'r') as text:
6 words = [raw_word.strip(string.punctuation).lower() for raw_word in text.read().split()]
7 # 在文字的首位去掉了连在一起的标点符号,并把首字母大写的单词转化为小写
8
9 words_index = set(words)
10 # 将列表用 set 函数转换成集合,自动去掉了其中所有重复的元素
11
12 counts_dict = {index: words.count(index) for index in words_index}
13 # 创建了一个以单词为键(key)出现频率为值(value)的字典
14
15 for word in sorted(counts_dict, key=lambda x: counts_dict[x], reverse=True):
16 print('{} -- {} times'.format(word, counts_dict[word]))
17 # 打印整理后的函数,其中 key=lambda x: counts_dict[x] 叫做lambda 表达式,可以暂且理解为以字典中的值为排序的参数
七、类
定义一个类
类是有一些系列有共同特征和行为事物的抽象概念的总和。
1 class Cococola:
2 formula = ['caffeine', 'sugar', 'water', 'soda']
类的实例化
1 class Cocacola:
2 formula = ['caffeine', 'sugar', 'water', 'soda']
3
4
5 coke_for_me = Cocacola()
6 coke_for_you = Cocacola()
7
8 print(Cocacola.formula)
9 print(coke_for_me.formula)
10 print(coke_for_you.formula)
类属性引用
在类的名字后面输入 . ,IDE 就会自动联想出我们之前在定义类的时候写在里面的属性,而这就是类属性的引用(attribute reference)。
类的属性会被所有类的实例共享。
类的属性和正常的变量并无区别。
实例属性
1 class Cococola:
2 formula = ['caffeine', 'sugar', 'water', 'soda']
3
4
5 coke_for_China = Cococola()
6 coke_for_China.local_logo = '可口可乐' # 创建实例属性
7
8 print(coke_for_China.local_logo) # 打印实例属性引用结果
实例方法
1 class CocaCola:
2 formula = ['caffeine', 'sugar', 'water', 'soda']
3
4 def drink(self): # self 这个参数是可以随意修改名称的,编译器不会因此而报错,按照 Python 的规矩,统一使用 self
5 print('Energy!')
6
7
8 coke = CocaCola()
9 coke.drink() # 相当于 CocaCola.drink(coke)
类的方法也能有属于自己的参数。
1 class CocaCola:
2 formula = ['caffeine', 'sugar', 'water', 'soda']
3
4 def drink(self, how_much):
5 if how_much == 'a sip':
6 print('Cool')
7 elif how_much == 'whole bottle':
8 print('Headache')
9
10
11 ice_coke = CocaCola()
12 ice_coke.drink('a sip')
魔术方法
Python 的类中存在一些方法,被称为“魔术方法”,_init_()_ 就是其中之一。
_init()_ 的神奇之处在于,如果你在类里定义了它,在创建实例的时候它就能帮你自动地处理很多事情 —— 比如新增实例属性。
_init()_ 是 initialize (初始化)的缩写,这意味着即使我们在创建实例的时候不去引用 init()方法,其中的命令也会被自动地执行。
1 class Cocacola:
2 formula = ['caffeine', 'sugar', 'water', 'soda']
3
4 def __init__(self):
5 for element in self.formula:
6 print('Coke has {}!'.format(element))
7
8 def drink(self):
9 print('Energy!')
10
11
12 coke = Cocacola()
类的继承(Inheritance)
类中的变量和方法可以完全被子类继承,但如需要特殊的改动也可以进行覆盖(Override)。
八、第三方库
1、在 PyCharm 中安装第三方库
(1)在 PyChram 的菜单中选择:File > Default Settings ;
(2)搜索 Project Interpreter,选择当前版本 Python 环境,,点击 “+” 添加库;
(3)输入库的名称,勾选并点击 Install Package。
2、使用第三方库
在 Python 中输入库的名字,就会自动提示补全了。