【Druid】(三)Apache Druid 的数据结构
文章目录
-
- 一、前言
- 二、DataSource 结构
-
- 2.1 数据结构(维度列)
- 2.2 结构说明
- 三、Segment 结构
-
- 3.1 小总结
一、前言
与Druid 架构相辅相成的是其基于DataSource 与Segment 的数据结构,它们共同成就了Druid 的高性能优势。
二、DataSource 结构
若与传统的关系型数据库管理系统( RDBMS)做比较,Druid 的DataSource 可以理解为 RDBMS 中的表(Table)。DataSource 的结构包含以下几个方面。
- 时间列( TimeStamp):表明每行数据的时间值,默认使用UTC 时间格式且精确到毫秒级别。这个列是数据聚合与范围查询的重要维度。
- 维度列(Dimension):维度来自于OLAP 的概念,用来标识数据行的各个类别信息,参与事件过滤。
- 指标列( Metric):指标对应于OLAP 概念中的Fact,是用于聚合和计算的列。这些指标列通常是一些数字,计算操作通常包括Count、Sum 和Mean 等。
- DataSource 结构 结构如图所示:

无论是实时数据消费还是批量数据处理, Druid 在基于DataSource 结构存储数据时即可选择对任意的指标列进行聚合( RollUp)操作。该聚合操作主要基于维度列与时间范围两方面的情况。
Druid读取数据的入口并不会直接存储原始数据, 而是使用Roll-up这种first-level聚合操作压缩原始数据。
- 下图显示的是执行聚合操作后DataSource 的数据情况。

相对于其他时序数据库, Druid 在数据存储时便可对数据进行聚合操作是其一大特点,该特点使得Druid 不仅能够节省存储空间,而且能够提高聚合查询的效率。
用SQL表示类似于对时间撮和所有维度列进行分组,并以原始的指标列做常用的聚合操作。
GROUP BY timestamp, publisher, advertiser, gender, country
:: impressions = COUNT(1), clicks = SUM(click), revenue = SUM(price)
为什么不存原始数据? 因为原始数据量可能非常大,对于广告的场景,一秒钟的点击数是以千万计数。 如果能够在读取数据的同时就进行一点聚合运算,就可以大大减少数据量的存储,这种方式的缺点是不能查询单条事件,也就是你无法查到每条事件具体的click和price值了。
由于后面的查询都将以上面的查询为基础,所以Roll-up的结果一定要能满足查询的需求。通常count和sum就足够了,因此Rollup的粒度是你能查询的数据的最小时间单位。 假设每隔1秒Rollup一次,后面的查询你最小只能以一秒为单位,不能查询一毫秒的事件,默认的粒度单位是ms。
2.1 数据结构(维度列)
维度列因为要支持过滤和分组,每一个维度列的数据结构包含了三部分:
- 值到ID的Map映射
- 列的值列表,存储的是上一步对应的ID
- 倒排索引
示例进行说明:

代表这一维度列的数据结构如下:
1: Dictionary that encodes column values
{
"Justin Bieber": 0,
"Ke$ha": 1
}
2: Column data
[0,
0,
1,
1]
3: Bitmaps - one for each unique value of the column
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,0,1,1]
注意:在最坏情况下前面两种会随着数据量的大小而线性增长. 而BitMap的大小则等于数据量大小 * 列的个数。
2.2 结构说明
字典表的key都是唯一的,所以Map的key是unique的column value,Map的value从0开始不断增加。示例数据的page列只有两个不同的值。所以为Bieber编号0,Ke$ha编号为1。
Key |Value
---------------|-----
Justin Bieber |0
Ke$ha |1
列的数据: 要保存的是每一行中这一列的值, 值是ID而不是原始的值。因为有了上面的Map字典,所以有下面的对应关系,这样列的值列表直接取最后一列: [0,0,1,1]。
rowNum page ID
1 Justin Bieber 0
2 Justin Bieber 0
3 Ke$ha 1
4 Ke$ha 1
BitMap的key是第一步Map的key(列的原始值)。value数组的每个元素表示指定列的某一行是否包含/存在/等于当前key。注意:BitMap保存的value数组只有两个值:1和0,1表示这一行包含或等于BitMap的key, 0表示不存在/不包含/不等于,如下:
第一行的page列值为Justin Bieber/列值为Justin Bieber的在第一行里
^
|
value="Justin Bieber": [1,1,0,0]
value="Ke$ha": [0,0,1,1]
^
|
第一行的page列值不是Ke$ha
这种存储方式,如果unique重复的列很少,比如page列的每一个值都是不同的。BitMap就会是一个稀疏矩阵。
A: [1,0,0,0,0,0,0,0,0,0,0]
B: [0,1,0,0,0,0,0,0,0,0,0]
C: [0,0,1,0,0,0,0,0,0,0,0]
D: [0,0,0,1,0,0,0,0,0,0,0]
E: [0,0,0,0,1,0,0,0,0,0,0]
-
unique的重复数量很少也叫做high cardinality,表示基数很高,不同列的数量很多,列值相同的记录数很少。
-
稀疏矩阵对于BitMap而言却是有优点的,因为越是稀疏,它可以被压缩的比例越大,最后存储的空间越少(相对原始数据)。
-
上面只是针对page列的BitMap,对于其他的维度列,都有自己的BitMap!即每一个维度列都有一个BitMap。
三、Segment 结构
DataSource 是一个逻辑概念, Segment 却是数据的实际物理存储格式, Druid 正是通过Segment 实现了对数据的 横纵向切割( Slice and Dice)操作。从数据按时间分布的角度来看,通过参数segmentGranularity 的设置,Druid 将不同时间范围内的数据存储在不同的Segment 数据块中,这便是所谓的数据横向切割。
这种设计为Druid 带来一个显而易见的优点:按时间范围查询数据时,仅需要访问对应时间段内的这些Segment 数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
Druid的分片是Segment文件。 Druid首先总是以时间戳进行分片,因为事件数据总是有时间戳。假设以小时为粒度创建下面的两个Segment文件。
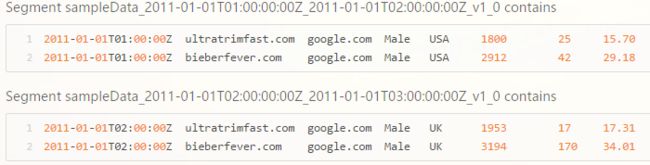
通过Segment 将数据按时间范围存储,同时,在Segment 中也面向列进行数据压缩存储,这便是所谓的数据纵向切割。而且在Segment 中使用了Bitmap 等技术对数据的访问进行了优化。
-
在几乎所有的NoSQL中都有数据分片的概念:比如ES的分片,HBase的Region,都表示的是数据的存储介质。为什么要进行分片,因为数据大了,不能都存成一个大文件吧,所以要拆分成小文件以便于快速查询,伴随拆分通常都有合并小文件。
-
从Segment文件的名称可以看出它包含的数据一定是在文件名称对应的起始和结束时间间隔之内的。
-
Segment文件名称的格式:
dataSource_interval_version_partitionNumber。最后一个分区号是当同一个时间戳下数据量超过阈值要分成多个分区。- 分片和分区都表示将数据进行切分。分片是将不同时间戳分布在不同的文件中,而分区是相同时间戳放不下了,分成多个分区。
- 巧合的是Kafka中也有Segment和Partition的概念。Kafka的Partition是topic物理上的分组,一个topic可以分为多个partition,它的partition物理上由多个segment组成。即Partition包含Segment,而Druid是Segment包含Partition。
3.1 小总结
数据进入到Druid首先会进行索引,这给予了Druid一个机会可以进行分析数据,添加索引结构、压缩、为查询优化调整存储结构。
- 转换为列式结构
- 使用BitMap索引
- 使用不同的压缩算法
-
索引的结果是生成Segment文件,Segment中除了保存不同的维度和指标,还保存了这些列的索引信息
-
Druid将索引数据保存到Segment文件中,Segment文件根据时间进行分片。最基本的设置中,每一个时间间隔都会创建一个Segment文件。
-
这个时间间隔的长度配置在
granularitySpec的segmentGranularity参数。为了Druid工作良好,通常Segment文件大小为300-700M。 -
前面Roll-up时也有一个时间粒度:
queryGranularity指的是在读取时就进行聚合,segmentGranularity则是用于分片进来之后的数据。