浅谈CSwin-Transformers
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达
![]()
【导语】局部自注意力已经被很多的VIT模型所采用,但是没有考虑过如何使得感受野进一步增长,为了解决这个问题,Cswin提出了使用交叉形状局部attention,同时提出了局部增强位置编码模块,超越了Swin等模型,在多个任务上效果SOTA,本文给出Cswin的详细解读和分析。
论文链接:https://arxiv.org/abs/2107.00652
论文代码:https://github.com/microsoft/CSWin-Transformer
知乎专栏: https://www.zhihu.com/people/flyegle
1. 出发点
基于global attention的transformer效果虽然好但是计算量太大了。
基于local attention的transformer的会限制每个token的感受野的交互,减缓感受野的增长。
2. 怎么做
提出了Cross-Shaped Window self-attention机制,可以并行计算水平和竖直方向的self-attention,可以在更小的计算量条件下获得更好的效果。
提出了Locally-enhanced Positional Encoding(LePE), 可以更好的处理局部位置信息,并且支持任意形状的输入。
3. 模型结构
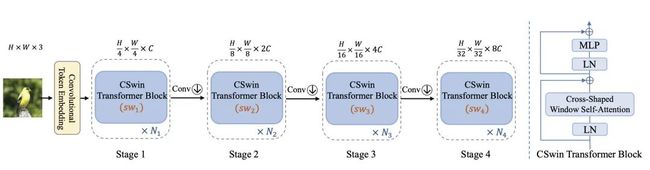
模型整体结构如上所示,由token embeeding layer和4个stageblock所堆叠而成,每个stage block后面都会接入一个conv层,用来对featuremap进行下采样。和典型的R50设计类似,每次下采样后,会增加dim的数量,一是为了提升感受野,二是为了增加特征性。下面详解每个部分的构成。
3.1. Convolutional Token Embeeding
顾名思义,用convolution来做embeeding,为了减少计算量,本文直接采用了7x7的卷积核,stride为4的卷积来直接对输入进行embeeding,假设输入为 ,那么输出为 。
3.2. Cross-Shaped Window Self-Attention
尽管有很强的长距离上下文建模能力,但原始的global self-attention的计算复杂度与特征图大小平方(H==W的情况)成正比的。因此,对于以高分辨率特征图为输入的视觉任务,如物体检测和分割,计算成本会非常大。为了缓解这个问题,现有的工作Swin等建议使用local windows self-attention,通过shift窗口来扩大感受野。然而,每个Transformer块内的token依旧是有限的注意区域,需要堆叠更多的block来实现全局感受野。为了更有效地扩大注意力区域和实现全局性的自我注意,有了Cross-shaped Window Self-attention,下面细讲是怎么做的以及代码实现。
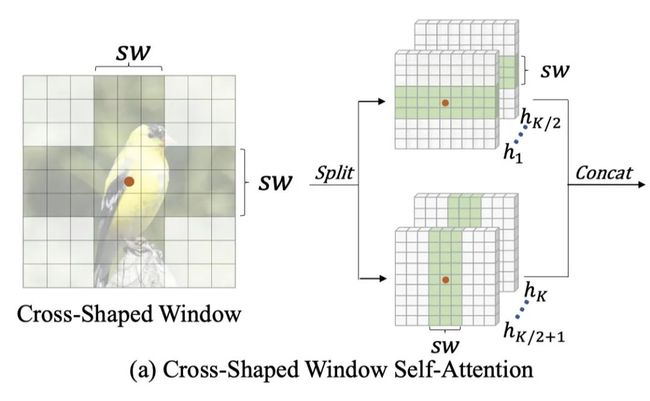
看图说话,很简单,假设原始的featuremap为 ,设置windows的大小为 ,如果我们希望做行attention,设置 为 ,设置 为 ,那么就可以获得一个 的局部窗口,同理,如果我们希望做列attention,设置 为 ,设置 为 ,可以获得一个 的窗口。同时,对应的dim一分为2,一部分用于计算行attention,另一部分用于计算列attention,最后在concat起来,实现并行处理。由于transformers在计算attention的时候是采用mutilhead的,为了保持计算量,本文对head一分为2,一部分用于行attention,一部分用于列attention。以行attention为例,公式如下:
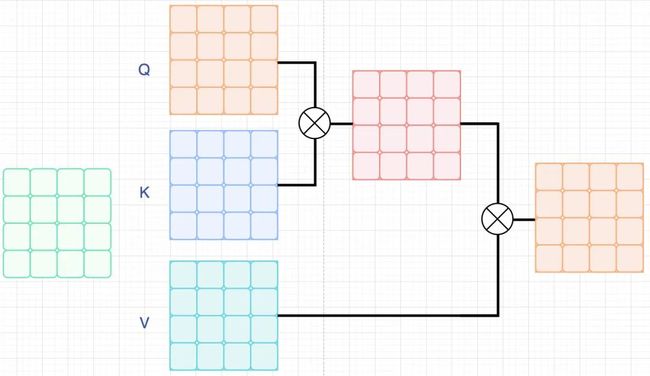
其中,窗口大小为 , 相比于标准的self-attention,区别在于H,或者W是部分的而不是全部的,如下图所示。
标准的self-attention
(行or列)self-attention
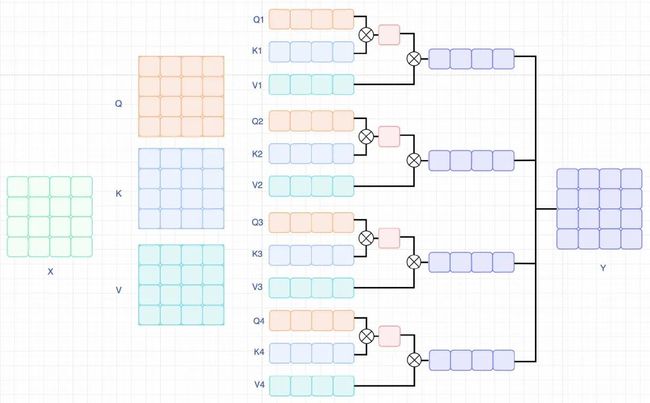
自己的思考其实乍一看很像ACNet和RepVGG,只不过他们是全都要,本文的话只要行和列的计算。在Transformers的attention中,Q实际上起指导的作用,K则是用来做token之间的交互,那么对于一个 的矩阵,会得到一个 的attention map,意义就是在Q的指导下得到的关于K的attention。很多的时候我们会发现这个attention map 高亮的部分往往都是集中于对角线区域以及周围的部分区域,也就是自己attention自己和对自己有用的token。那么我们是不是就可以拆解这两部分,构造两个attention,一个用于自己attn自己,一个用于attn对自己有价值的位置。那么先拆解为 表示的是第一个token,得到 的atten结果,那么意义就是当前的toke与其他的token之间的相似度。反过来, 表示的每个token,同样得到 的atten结果,但是意义为每个token指导第一个token的embeeding的变化。两者结合,就是找对自己有用的token。
Q&A Question: 本文的另一个核心思想是增大感受野,那么怎么才能增大感受野呢?
Answer: 首先明确一点,cross-shaped windows self-attention,并不是基于一个H和W相等的window来做attention的,实际的窗口大小是随着featuremap和滑动步长的改变而变化的。我们知道R50是通过1/32的下采样来获得很大的感受野,cross-shaped也是如此,通过降采样图像大小,同时增加窗口滑动步长, 最终从local-attention 变为 global-attention, 实现扩张感受野。(这里说感受野不准,应该表示为长距离依赖)
3.3. Locally-Enhanced Positional Encoding(LePE)

上图所示,左边为VIT模型的PE,使用的绝对位置编码或者是条件位置编码,只在embeeding的时候与token一起进入transformer,中间的是Swin,CrossFormer等模型的PE,使用相对位置编码偏差,不再和输入的embeeding一起进入transformer,通过引入token图的权重,来和attention一起计算,灵活度更好相对APE效果更好。最后就是本文所提出的LePE,相比于RPE,本文的方法更加直接,直接作用在value上,公式如下:
这里, 表示的是Value的位置权重,有 。但是直接去计算 , 还是有一定程度的计算量,假设对于输入,对其影响大的元素只在他的附近,所以改写公式为:
这样,LePE可以友好地应用于将任意输入分辨率作为输入的下游任务。
3.4. CSWin Transformer Block
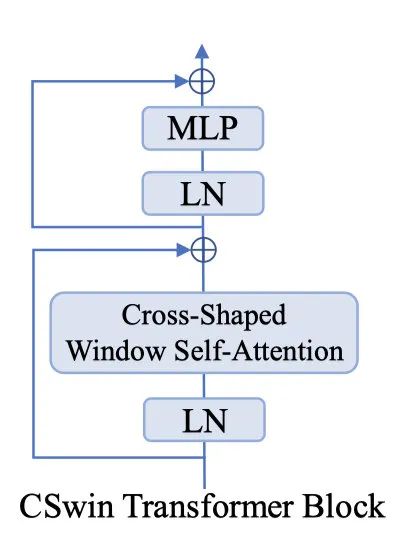
CSwin的block很简单,有两个prenorm堆叠而成,一个是做LayerNorm和Cross-shaped window self-attention并接一个shortcut,另一个则是做LayerNorm和MLP,相比于Swin和Twins来说,block的计算量大大的降低了(swin,twins则是有两个attention+两个MLP堆叠一个block)。公式如下:
3.5. Code Review
class LePEAttention(nn.Module):
def __init__(self, dim, resolution, idx, split_size=7, dim_out=None, num_heads=8, attn_drop=0., proj_drop=0., qk_scale=None):
super().__init__()
self.dim = dim
self.dim_out = dim_out or dim
self.resolution = resolution
self.split_size = split_size
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
if idx == -1: # global attenton
H_sp, W_sp = self.resolution, self.resolution
elif idx == 0: # row attention
H_sp, W_sp = self.resolution, self.split_size
elif idx == 1: # column attention
W_sp, H_sp = self.resolution, self.split_size
else:
print ("ERROR MODE", idx)
exit(0)
self.H_sp = H_sp
self.W_sp = W_sp
stride = 1
self.get_v = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1,groups=dim)
self.attn_drop = nn.Dropout(attn_drop)
def im2cswin(self, x):
B, N, C = x.shape
H = W = int(np.sqrt(N))
# (B, N, C) -> (B, C, N) -> (B, C, H, W)
x = x.transpose(-2,-1).contiguous().view(B, C, H, W)
x = img2windows(x, self.H_sp, self.W_sp) # (B*(H//h_sp, W//w_sp), h_sp * w_sp, C)
# (B*(H//h_sp, W//w_sp), h_sp * w_sp, C) -> (B*(H//h_sp, W//w_sp), h_sp*w_sp, h, C//h) -> (B*(H//h_sp, W//w_sp),h, h_sp*w_sp, C//h)
x = x.reshape(-1, self.H_sp* self.W_sp, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3).contiguous()
return x
def get_lepe(self, x, func):
B, N, C = x.shape
H = W = int(np.sqrt(N))
x = x.transpose(-2,-1).contiguous().view(B, C, H, W)
H_sp, W_sp = self.H_sp, self.W_sp
x = x.view(B, C, H // H_sp, H_sp, W // W_sp, W_sp)
x = x.permute(0, 2, 4, 1, 3, 5).contiguous().reshape(-1, C, H_sp, W_sp) ### B', C, H', W'
lepe = func(x) ### B', C, H', W' # dw conv
# (B', C, H', W') -> (B, h, C//h, h_sp * w_sp) -> (B, h, h_sp*w_sp, C//h)
lepe = lepe.reshape(-1, self.num_heads, C // self.num_heads, H_sp * W_sp).permute(0, 1, 3, 2).contiguous()
x = x.reshape(-1, self.num_heads, C // self.num_heads, self.H_sp* self.W_sp).permute(0, 1, 3, 2).contiguous()
return x, lepe
def forward(self, qkv):
"""
x: B L C
"""
q,k,v = qkv[0], qkv[1], qkv[2]
### Img2Window
H = W = self.resolution
B, L, C = q.shape
assert L == H * W, "flatten img_tokens has wrong size"
q = self.im2cswin(q)
k = self.im2cswin(k)
v, lepe = self.get_lepe(v, self.get_v)
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # B head N C @ B head C N --> B head N N
attn = nn.functional.softmax(attn, dim=-1, dtype=attn.dtype)
attn = self.attn_drop(attn)
x = (attn @ v) + lepe # B head N N @ B head N C
# (B, h, N, C//h) --> (B, N, C)
x = x.transpose(1, 2).reshape(-1, self.H_sp* self.W_sp, C)
### Window2Img
x = windows2img(x, self.H_sp, self.W_sp, H, W).view(B, -1, C) # B (H' W') C
return x
代码很简单,对于滑窗后的处理,都是把外循环并入到了batch的维度了,可以并行处理。因为是按照dim来进行分水平和竖直的, 所以对应的heads也进行相应的分发处理。
4. 实验
4.1. 模型设计

还是按照FLOPs的分布,来设计了四种模型,CSWin-T,CSWin-S,CSWin-B,CSwin-L,这里的FLOPs都是在224x224条件下计算的。
4.2. imagenet结果
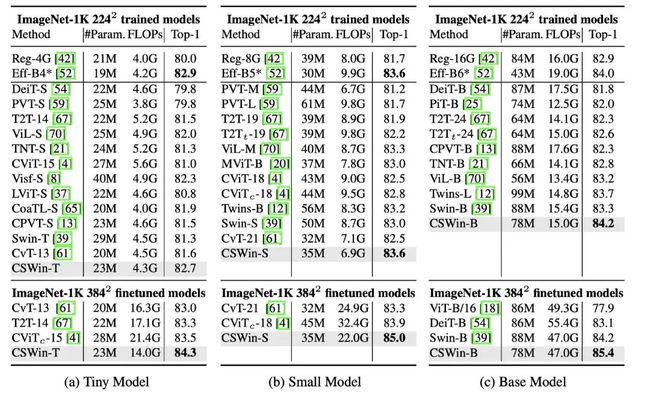
224表示的是模型在224x224的输入下,使用imagenet1k的数据来训练得到的结果,384表示的是在384x384上进行微调后的结果,可以看到CSWin取得了比较SOTA的结果。
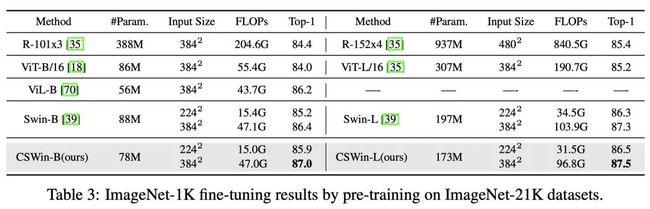
使用imagenet21k做pretrain后在imagenet1k上微调的结果,可以发现用更多的数据训练出来的模型做pretrain对于所有模型都有提升,cswin无论是224和384尺度训练都取得了SOTA。
4.3. 检测和分割结果
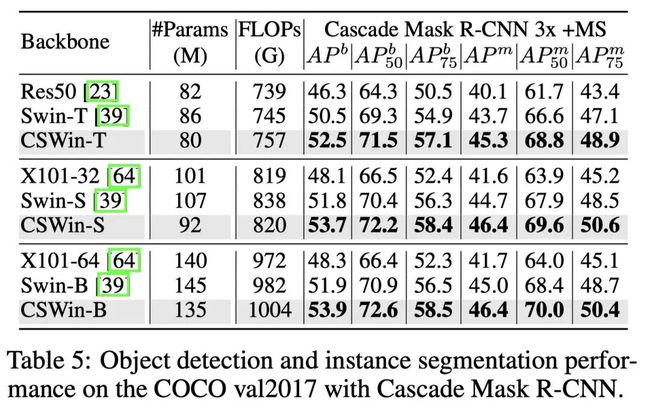
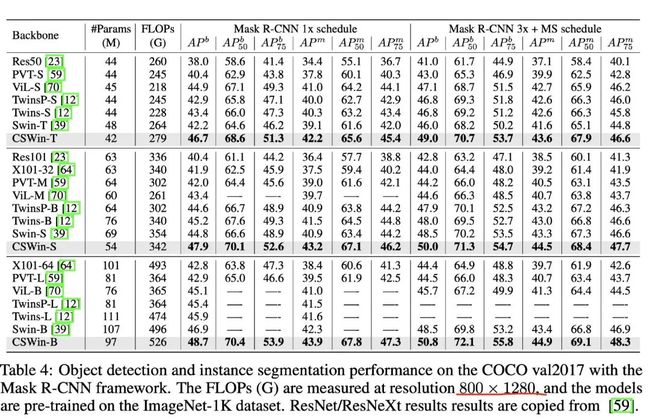
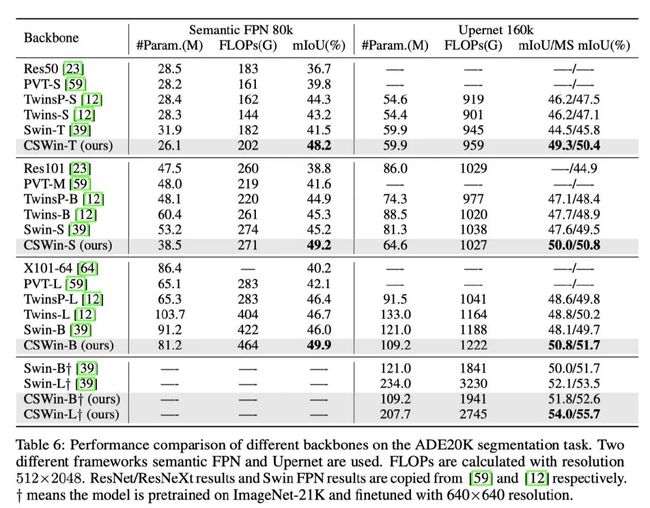
下游任务上,均有着非常sota的表现。
4.4. 消融实验
模型结构+trick
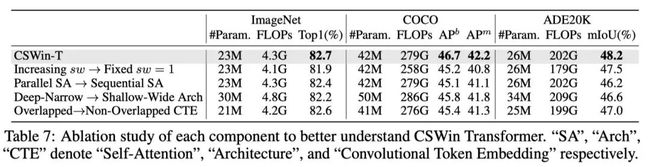
实验采用的模型是CSWin-T,imagenet上的结果为82.7%。
滑动窗口的步长从每个stage增长改为每个stage固定为1,发现性能下降了0.8个点,说明感受野的大小会影响模型的结果
并行attention改成序列化attention,性能降低了0.3%个点。
模型的设计,从深窄变成矮胖结构,性能下降了0.5%个点,这一点实际上在CNN都已经有过证明了。
卷积获取embeeding改为非重叠切片获取embeeding,性能下降了0.1%个点,说明overlap和非overlap对于token来说意义不大,因为最终也是可以看到全局的。
attention&position embeeding
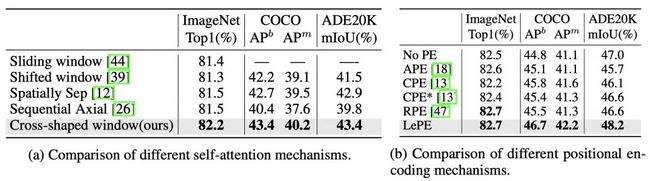
本文提出的Cross-shaped window self-attention机制,不仅在分类任务上超过之前的attention,同时检测和分割这样的dense任务上效果也非常不错,说明对于感受野的考虑是非常正确的。
虽然RPE和LePE在分类的任务上性能类似,但是对于形状变化多的dense任务上,LePE更深一筹。
5. 结论
在本文中,提出了CSWin Transformer。CSWin Transformer的核心设计是CSWin Self-Attention,它通过将多头分成平行组来执行水平和垂直条纹的自我注意。这种多头分组设计可以有效地扩大一个Transformer块内每个token的注意区域。同时,进一步将局部增强的位置编码引入CSWin Transformer,可以更有效的用于下游任务。大量的实验证明了CSWin Transformer的有效性和高效性。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 