linux 文本处理命令
文章目录
- 总览
- 详细介绍
-
- head
- tail
- tr
- sort
- uniq
- sed
- awk
总览
- 显示、仅浏览: cat less more nl head tail
- 手动编辑: vi vim
- 匹配查找: grep sed
- 替换:tr(字符替换)
- 指定行编辑:sed
- 特殊:sort、unique
详细介绍
head
-n 后面接数字,代表显示几行的意思
-c 指定显示头部内容的字符数
-v 总是显示文件名的头信息
-q 不显示文件名的头信息
head -n 2 test.txt 显示前两行
head -c 5 test.txt 显示前5字符
tail
tail +20 file.txt 第20行至文件末尾:
tail -c 10 file 最后的10个字符
tr
替换字符。
tr a b 字母a换成b
tr a-z A-Z
-c 取补集
-d 删除而不是替换
-s 多个重复出现则删除重复的。
tr -d "[a-z]" <file_1 删除小写字母
tr -s "[\n]" <file_2 删除重复回车,即删除空白行
sort
-n 按数值大小
-k 按第几列排 ,列于列之间的分隔符默认是 空格或\t
-t 指定分隔符
-u 删除相同的,具体
例子
按照空格分割,比较第二列
sort -t ' ' -k 2 a.txt
比较第2列的数值
sort -n -k 2 a.txt
sort -kn 2 a.txt
sort -k 2n a.txt
按照第3列降序,相同则按照第2列升序
sort -n -k 3r -k 2 a.txt
sort -k 3nr -k 2n a.txt
sort的关键是找出没一行的key,并按照key的字典序排序,-k用于指定排序所用的key开始和结束的位置。不指定key则默认是整行作为key。
-k可以加的具体参数格式为:
[ FStart [ .CStart ] ] [ Modifier ] [ , [ FEnd [ .CEnd ] ][ Modifier ] ]
如果不指定逗号后面的end部分,则默认从start到行的最后。
如"1n"表示从第一列开始按数值排序,此时key是从第一列到最后,即整行。
n表示先提取key的开头的数字比较,开头没有数字则当成比0略大。
1.2, 1.3nr 表示从第1列截取第2到第3个字符组成单词(从1开始数,这里是"23"),利用这个单词进行数值大小逆向排序。
此外,FEnd指定了也没用,如1.2,2.3nr等价于1.2,1.3nr;
如果两行-k指定的部分都相同,或者没有指定-k,则按照整行的字符排序,因此最终的结果总是固定的,不依赖于初始顺序。
关于字典序:
两个key比较,从第一个字符开始,字符相同则比较下一个,否则按照ascii码比较:空白<0<A<a
如 01<A<AB<a
uniq
去掉后去相同的行,标准输出。
-c 统计出现次数
-d -u仅显示有重复/没有重复的记录。
sed
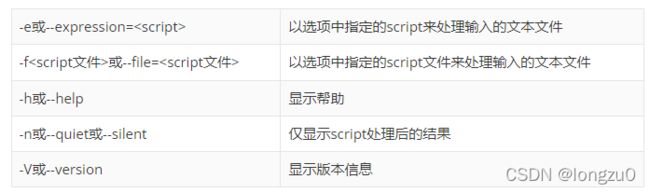
功能:把输入处理,并标准输出。功能强大
支持的处理方式:
a: sed '2a mm' 第2行后插入一行mm
c: sed '2,5c mm' 2-5行换成mm
d: sed '2,$d' 只留第1行
i: sed '2i mm' 第2行前插入一行mm
p: sed -n '2,5p' 显示第2-5行
s 正则替换
除了直接指定行号,也可以指定字符串匹配,可以实现grep的效果
sed '/abc/c mm' 有‘abc’的行换成mm
以下等价:
nl /etc/passwd | sed -n '/root/p'
nl /etc/passwd | grep root
复合指令:
nl /etc/passwd | sed -n '/root/{s/bash/blueshell/;p;q}'
对比nl /etc/passwd | sed -n '/root/p',把p换成了大括号,并在p前面增加了语句。实现了替换并显示的功能。
awk
支持用户自定义函数和动态正则表达式,功能强大。
语法:
awk [选项参数] 'script' var=value file(s)
例如
awk '{ print $2,$3 }' file 打印每一行的第二和第三个字段
awk -v OFS="~"'{print $1,$NF}' 修改输出分隔符号,特殊字符需转义
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本
awk 更适合格式化文本,对文本进行较复杂格式处理
awk很复杂,类似一门编程语言,不多介绍了。