[leetcode刷题]汇总(二)
文章目录
- 二分查找
-
- 69 x的平方根
- 367 有效的完全平方数
- 33 搜索旋转排序数组(中等)
- 74 搜索二维矩阵(中等)
- 153 找到旋转数组中的最小值(中等)
- 动态规划
-
- 斐波拉
- 62 不同路径(中等)
- 63 不同路径2(中等)(需要判断障碍)
- 1143 最长公共子序列(中等)
- 70爬楼梯(简单 重复 复习)
- 120 三角形最小路径和(中等)
- 53 最大子序列
- 198 打家劫舍(中等)认真看
- 121 买卖股票的最佳时机(简单)
- 122 买卖股票的最佳时机(2)(简单)
- 123买卖股票的最佳时候(困难)(其实也不难 注意看看优化空间的方法)
- 188 买卖股票的最佳时机(4)(困难)
- 309 买卖股票时机含冷冻期(中等)
- 714 买卖股票的最佳时机含手续费
- 字典树和并查集
-
- 208 实现Trie(前缀树)(中等)
- 79单词搜寻(中等)(待补充)
- 212. 单词搜索 II(困难)(待补充)
- 并查集
-
- 200 岛屿问题(中等)
- 高级搜索
-
- 爬楼梯
- 八皇后
- 36有效的数独(中等)
- 37 解数独(困难)(剪枝回溯)
- 其他还有但是我没做,等复习前面的深度和广度
- 红黑树和AVL
- 位运算
-
- 191 位1的个数(简单)
- 231 2的幂
- 190颠倒二进制位(主要就是考察位运算符用的怎么样)
- 51 N皇后(困难)(位运算判断)
- 338 比特位计数(简单)
- 布隆过滤器 LRU缓存
-
- 146 LRU 缓存机制(中等)(双向链表和hash)
- 排序算法
-
- 242 有效字母异位词
- 1122 数组的相对排序
- 56 合并区间(中等)
- 493 翻转对(困难)(待补充)
- 字符串
-
- 709 转换成小写字母(简单)
- 56 最后一个单词的长度(简单)
- 771宝石和石头(简单)
- 387 字符串中的第一个唯一字符
- 8 字符串转换成整数(中等)
- 前面都是字符串基础问题
- 这边是字符串操作问题
- 14 最长公共前缀(简单)
- 344 反转字符串(简单)
- 345 翻转字符串2(简单)
- 151翻转字符串里的单词(中等)(认真看)
- 557 反转字符串中的单词2(简单)
- 异位词问题
- 242 有效的字母异位
二分查找
![[leetcode刷题]汇总(二)_第1张图片](http://img.e-com-net.com/image/info8/66acfffd47b841f1a44c119fb67f1d8d.jpg)
69 x的平方根
- 其实有一个需要注意的是题目要的是整数 你想想什么时候会退出while 不就是l>r,为什么l会大于r,因为r–了,什么时候r会–,那就是数据大了left =mid –
class Solution {
public:
int mySqrt(int x) {
int l = 0, r = x, ans = -1;
while (l <= r) {
int mid = l + (r - l) / 2;
if ((long long)mid * mid <= x) {
ans = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
return ans;
}
};
class Solution {
public:
int mySqrt(int x) {
int l = 0, r = x;
while (l <= r)
{
int mid = l + (r - l) / 2;
if ((long long)mid * mid <= x)
{
// ans = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
return r;
//return l-1;
}
};
367 有效的完全平方数
- 有毒 必须mid 必须是 l + (r-l)/2; 就怕是左和右相等 一直循环走不出来
class Solution {
public:
bool isPerfectSquare(int num) {
int l = 0;
int r = num;
while( l <= r ){
long m = l + (r-l)/2;
long sqrt = m*m;
if( sqrt == num ) { return true; }
else if(sqrt > num ) { r = m-1; }
else { l = m+1;}
}
return false;
}
};
33 搜索旋转排序数组(中等)
-
其实她利用了一个技巧,当我们一分为二的时候,只要子序列的尾端点大于头端点,那么他就是有序的。而且毕竟一个有序一个没序
-
在判断中分四种情况如下,也通过这也来写的代码
-
左边有序
- 在这边
- 不在这边
-
右边有序
- 在这边
- 不在这边
-
需要注意进行的两个特判
class Solution {
public:
int search(vector<int>& nums, int target) {
int n = (int)nums.size();
if (!n)//长度为0
{
return -1;
}
if (n == 1) //长度为1
{
if (nums[0]==target) return 0;
else -1;
}
int l = 0, r = n - 1;//确定左边界 和右边界
while (l <= r)
{
int mid = l+(r-l) / 2;
if (nums[mid] == target) return mid;//符合条件
if (nums[0] <= nums[mid])//前半段有序
{
if (nums[0] <= target && target < nums[mid])//并且目标在这个区间
{
r = mid - 1;//在左半部分
} else {
l = mid + 1;//在右半部分
}
} else //后半段有序
{
if (nums[mid] < target && target <= nums[n - 1])//并且在这个区间
{
l = mid + 1;
} else
{
r = mid - 1;//不在这个区间
}
}
}
return -1;
}
};
74 搜索二维矩阵(中等)
-
方法一:由于每行的第一个元素大于前一行的最后一个元素,且每行元素是升序的,所以每行的第一个元素大于前一行的第一个元素,因此矩阵第一列的元素是升序的。我们可以对矩阵的第一列的元素二分查找,找到最后一个不大于目标值的元素,然后在该元素所在行中二分查找目标值是否存在。 -
方法二:若将矩阵每一行拼接在上一行的末尾,则会得到一个升序数组,我们可以在该数组上二分找到目标元素。代码实现时,可以二分升序数组的下标,将其映射到原矩阵的行和列上。 -
第一个方法代码没怎么看懂
-
还是第二个方法好,巧妙运用 / % 来得到所在行和所在列 而不是真正地拼接了它们
-
区别在于
int m = matrix.size(), n = matrix[0].size();// 得到矩阵行和列
int left = 0, right = m * n - 1;// 左边位置和右边位置
int x = matrix[mid / n][mid % n];// 善于利用矩阵位置和除法运算与取模运算的关系
-
当然还有一种方法就是利用右上角的那个值,如果比它小去掉所在列,如果比它大去掉所在行。重新判断对角的那个点,最后我们要的值一定能找到

class Solution {
public:
bool searchMatrix(vector<vector<int>> matrix, int target) {
auto row = upper_bound(matrix.begin(), matrix.end(), target, [](const int b, const vector<int> &a) {
return b < a[0];
});
if (row == matrix.begin()) {
return false;
}
--row;
return binary_search(row->begin(), row->end(), target);
}
};
![[leetcode刷题]汇总(二)_第2张图片](http://img.e-com-net.com/image/info8/c38b45e92ae6468fa788bd6b5cc22edd.jpg)
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) { // 二分法,核心思想是把矩阵拉成一条数组。
// 可行的原因是每一行开头的数值比上一行末尾的大。可以把下一行拼接到上一行,最后将矩阵变成一行。
int m = matrix.size(), n = matrix[0].size(); // 得到矩阵行和列
int left = 0, right = m * n - 1; // 左边位置和右边位置
while (left <= right) { // 二分法套路
int mid = (right - left) / 2 + left; // 这样设置防止溢出的风险
int x = matrix[mid / n][mid % n]; // 善于利用矩阵位置和除法运算与取模运算的关系
if (x < target) { // 目标数值太大
left = mid + 1;
} else if (x > target) { // 目标数值小
right = mid - 1;
} else {
return true; // 找到了
}
}
return false; // 没找到
}
};
153 找到旋转数组中的最小值(中等)
- 两种理解方式
-
官方就是 这个最小值一定是在 一段序列中 最左大于最右的那个序列
- 所以当mid 大于 right 说明就在右边
- 如果mid小于right 说明在左边
-
第二个理解就是 翻转一定是两个序列,而且最小值一定在第二个序列,如果有序则说明不在那一边
-
看代码需要理解的一种就是 当mid 小于 r的时候
r = mid没有-1 你想想 是不是有最小值在中间点的特殊情况 不要漏掉了,特比的地方 -
还有个需要注意的是返回值 ,我常用的二分查找,就是 <-= 就是 -1 你也可以换成< 那就直接返回 l 因为当退出 说明 r=l 也就是区间只有一个数 那必然这个数就是我们要的 -
注意返回值 要么 是 r 要么是 l-1
-
class Solution {
public:
int findMin(vector<int>& nums) {
int l = 0;
int r = nums.size() - 1;
while (l <= r)
{
int mid = l + (r - l) / 2;
if (nums[mid] < nums[r])//如果中间小于右边 说明在前半部分
{
r = mid;
}
else //反之在后半部分
{
l = mid + 1;
}
}
return nums[r];
}
};
动态规划
小小复习
-
递归三步走
- 终止条件
- 处理当前层逻辑
- 进入下一层
-
分治
- 终止条件
- 拆分
- 结果=进入下一层
- 结果汇总
-
回朔(常见类型题 自己看 选啊 还是b啊这种)
- 终止条件
- for
- 处理当前层逻辑
- 进入下一层
- 回退
-
贪心算法
-
局部最优推导全局最优
好好看下面的区别
![[leetcode刷题]汇总(二)_第3张图片](http://img.e-com-net.com/image/info8/0174e5b62d74466e89b4949f05fbe29c.jpg)
![[leetcode刷题]汇总(二)_第4张图片](http://img.e-com-net.com/image/info8/0d4ccfaf268441d7b531cdc101d1a5d6.jpg)
- 斐波拉,如果直接用递归,那只是傻递归,速度是指数级的,看下面的图
![[leetcode刷题]汇总(二)_第5张图片](http://img.e-com-net.com/image/info8/3a7294d6327449b1b7fe9b24283bd2cb.jpg)
-
记忆化搜索,增加一个缓存 如下
![[leetcode刷题]汇总(二)_第6张图片](http://img.e-com-net.com/image/info8/6ffb48633cbc4942924638b494605992.jpg)
-
简化写法
![[leetcode刷题]汇总(二)_第7张图片](http://img.e-com-net.com/image/info8/9bbbd3f95ee44a418bbce5834d5fc1f6.jpg)
-
变成了0(n)
![[leetcode刷题]汇总(二)_第8张图片](http://img.e-com-net.com/image/info8/b8ac75817551475282bf4af67cfd9dab.jpg)
-
这个时候我们想,那还不如写一个迭代,自低想上,之前那种是自顶向下。
斐波拉
62 不同路径(中等)
![[leetcode刷题]汇总(二)_第9张图片](http://img.e-com-net.com/image/info8/b3b970273ef147dfb5370633a0d3ba33.jpg)
![[leetcode刷题]汇总(二)_第10张图片](http://img.e-com-net.com/image/info8/9fa65b7689ea49bca60a4c1d7a3a4959.jpg)
![[leetcode刷题]汇总(二)_第11张图片](http://img.e-com-net.com/image/info8/5e08ba5d986e45ecbf5e8b4e9753ee5e.jpg)
![[leetcode刷题]汇总(二)_第12张图片](http://img.e-com-net.com/image/info8/2b079a7feb5b44b89e022889ae65ba18.jpg)
-
其实这个题和斐波拉就散是一样的。每个格子的可能是右边和下边两个格子的可能,需要递推
重要 -
动态规划关键点
- 最优子结构
- 存储中间状态
- 递推公式(唯一一个不同就是这边可能会进行筛选)
-
比较经典的一个题目,知道就简单了,难点在于想到状态转移的方程,这个题的时间复杂度和空间复杂度都是o(mn)
-
好好看看vector如何初始化大小和初始值 一维和二维
-
还有一个就是这个坐标系的建议不要死脑经,他都是以目标店作为原点,出发点作为终止点。
class Solution {
public:
int uniquePaths(int m, int n) {
//m行 n列
vector<vector<int>> f(m,vector<int>(n));
for(int i=0;i<m;i++)
{
f[i][0]=1;//操作的是行
}
for (int j = 0; j < n; ++j)
{
f[0][j] = 1;
}
for (int i=1;i<m;i++)//需要注意这边是从1开始
{
for(int j=1;j<n;j++)
{
f[i][j]=f[i - 1][j] + f[i][j - 1];
}
}
return f[m - 1][n - 1];
}
};
63 不同路径2(中等)(需要判断障碍)
非常重要补充
-
所以在遇到求方案数的问题时,我们可以往动态规划的方向考虑。
-
多了和判断 就是状态转移方程变成 两个 一个是0 一个是正常的
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
int m = obstacleGrid.size();
int n = obstacleGrid[0].size();
vector<vector<int>> dp(m, vector<int>(n, 0));
for (int i = 0; i < m && obstacleGrid[i][0] == 0; i++) dp[i][0] = 1;
for (int j = 0; j < n && obstacleGrid[0][j] == 0; j++) dp[0][j] = 1;
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (obstacleGrid[i][j] == 1) continue;
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
1143 最长公共子序列(中等)
![[leetcode刷题]汇总(二)_第14张图片](http://img.e-com-net.com/image/info8/5e462d70bf4f4892b8876afa266f3bac.jpg)
-
简单的说 状态把两个字符串放在二维的空间上。
-
状态转移方程有两种情况
- 如果我们都加一个,这两个字母不一样,那状态就是字符串a变b不变 和 a不变b变的最大值。就好像我多了一个,你变化了没有啊,我变化了,你变化没有啊
- 如果两个值相同,就是我们都不加之前的最大长度+1
-
有一个问题就是不是很理解我自己写的第二种为什么不行,这个相比机器人就是i=0可以,但是i=-1不行啊 所以全部+1了。反正这种问题,你需要多考虑边界问题
![[leetcode刷题]汇总(二)_第15张图片](http://img.e-com-net.com/image/info8/341e241a01bd4c41a60557027451fc78.jpg)
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int m = text1.length(), n = text2.length();
vector<vector<int>> dp(m + 1, vector<int>(n + 1));//构建二维
for (int i = 1; i <= m; i++)
{
char c1 = text1.at(i - 1);//取出字母
for (int j = 1; j <= n; j++)
{
char c2 = text2.at(j - 1);//取出字母
if (c1 == c2) //如果两个字母
{
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
};
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int m = text1.length(), n = text2.length();
vector<vector<int>> dp(m , vector<int>(n));//构建二维
for (int i = 0; i < m; i++)
{
char c1 = text1.at(i);//取出字母
for (int j = 0; j < n; j++)
{
char c2 = text2.at(j);//取出字母
if (c1 == c2) //如果两个字母
{
if(i!=0&&j!=0) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j]=1;
} else
{
if(i!=0&&j!=0) dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
else dp[i][j]=0;
}
}
}
return dp[m-1][n-1];
}
};
70爬楼梯(简单 重复 复习)
- 每次上一阶 二阶 三阶 怎么办,多少种方法(简单)
- 如果相邻两步不能相同,怎么办()
120 三角形最小路径和(中等)
![[leetcode刷题]汇总(二)_第16张图片](http://img.e-com-net.com/image/info8/03735d33021143119581adef1f375d93.jpg)
- 区别在于不是工整的正方形
- f[i,j]=min(f[i+1,j],f[i+1,j+1]+c[i,j]//这就是状态转移方程
- 文字描述就是你下一层的每一个格子的最短路径就是上一层的正对的那个还有左边那个。你看看和谁加小
。需要特别判定就是靠在墙边的那些,以及最右边的那一排 自己画一个三角形在二维的看看就知道了
public:
int minimumTotal(vector<vector<int>>& triangle) {
int n = triangle.size();
vector<vector<int>> f(n, vector<int>(n));
f[0][0] = triangle[0][0];
for (int i = 1; i < n; ++i) {
f[i][0] = f[i - 1][0] + triangle[i][0];
for (int j = 1; j < i; ++j) {
f[i][j] = min(f[i - 1][j - 1], f[i - 1][j]) + triangle[i][j];
}
f[i][i] = f[i - 1][i - 1] + triangle[i][i];
}
return *min_element(f[n - 1].begin(), f[n - 1].end());
}
};
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
vector<int> dp(triangle.back());
for(int i = triangle.size() - 2; i >= 0; i --)
for(int j = 0; j <= i; j ++)
dp[j] = min(dp[j], dp[j + 1]) + triangle[i][j];
return dp[0];
}
};
53 最大子序列
![[leetcode刷题]汇总(二)_第17张图片](http://img.e-com-net.com/image/info8/9bb0b1bcd2e6458aad96df886f6b66df.jpg)
- 这个题做法很多,动态规划很难像,你看下面的图片描述,dp[i]表示的是以当前为结尾的最大子序列,状态转移方程也在下面。
注意:两个代码在下面,简洁版本的是因为只保留了两个两个变量pre上一个元素以及maxAns用来保存全部的最大值的,在便利过程中就不断比较- 还有一个ansmax初始值不能是0,需要只有一个元素并且负数,那就错了。
- 动态规划的时间复杂度是0(n)空间复杂度缩小到0(1)
- 贪心
![[leetcode刷题]汇总(二)_第18张图片](http://img.e-com-net.com/image/info8/f4f137b3c67447e2b90c6399508dc4d1.jpg)
![[leetcode刷题]汇总(二)_第19张图片](http://img.e-com-net.com/image/info8/79eb9e6bce1c4c31a4cda86919978ff9.jpg)
class Solution
{
public:
int maxSubArray(vector<int> &nums)
{
//类似寻找最大最小值的题目,初始值一定要定义成理论上的最小最大值
int result = INT_MIN;
int numsSize = int(nums.size());
//dp[i]表示nums中以nums[i]结尾的最大子序和
vector<int> dp(numsSize);
dp[0] = nums[0];
result = dp[0];
for (int i = 1; i < numsSize; i++)
{
dp[i] = max(dp[i - 1] + nums[i], nums[i]);
result = max(result, dp[i]);
}
return result;
}
};
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int pre=0;//你想想状态转移方程要考虑0前面那个,初始为0比较好
int maxAns=nums[0];//这边初始不能是0 如果一开始是-1 只有这一个就错了
for(int i=0;i<nums.size();i++)
{
pre=max(pre+nums[i],nums[i]);
maxAns=max(maxAns,pre);
}
return maxAns;
}
};
class Solution
{
public:
int maxSubArray(vector<int> &nums)
{
//类似寻找最大最小值的题目,初始值一定要定义成理论上的最小最大值
int result = INT_MIN;
int numsSize = int(nums.size());
int sum = 0;
for (int i = 0; i < numsSize; i++)
{
sum += nums[i];
result = max(result, sum);
//如果sum < 0,重新开始找子序串
if (sum < 0)
{
sum = 0;
}
}
return result;
}
};
作者:pinku-2
链接:https://leetcode-cn.com/problems/maximum-subarray/solution/zui-da-zi-xu-he-cshi-xian-si-chong-jie-fa-bao-li-f/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
198 打家劫舍(中等)认真看
-
这边可以看看代码随想录的代码
- 总结一下有一些问题:
- 背包问题
- 打家劫舍
- 股票问题
- 子序列问题
- 总结一下有一些问题:
-
动态规划5步骤
-
1 确定dp数组以及下标的含义
-
2 确定递推公式
-
3 dp数组如何初始化,根据递推公式
-
4 确定遍历顺序
-
5 举例推导dp数组
![[leetcode刷题]汇总(二)_第20张图片](http://img.e-com-net.com/image/info8/a6f3723bc87d4b91a42399b4685b4468.jpg)
-
以这个题分析
-

![[leetcode刷题]汇总(二)_第21张图片](http://img.e-com-net.com/image/info8/706048dc995c478d9e50a6491a054edd.jpg)
![[leetcode刷题]汇总(二)_第22张图片](http://img.e-com-net.com/image/info8/a2c5542e07e44ad8b0cc0c7568174c9b.jpg)
![[leetcode刷题]汇总(二)_第23张图片](http://img.e-com-net.com/image/info8/101fea02a97c4be7b1b4c08d9b14ccb5.jpg)
![[leetcode刷题]汇总(二)_第24张图片](http://img.e-com-net.com/image/info8/28aff62231a54b6687ac2268cdbc13b7.jpg)
class Solution {
public:
int rob(vector<int>& nums) {
if (nums.size() == 0) return 0;
if (nums.size() == 1) return nums[0];
vector<int> dp(nums.size());
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < nums.size(); i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[nums.size() - 1];
}
};
121 买卖股票的最佳时机(简单)
添加链接描述
![[leetcode刷题]汇总(二)_第25张图片](http://img.e-com-net.com/image/info8/dbc825ecc98c49cca4e00b7bc9e3f9f0.jpg)
- 暴力 贪心 动态规划都可以求解
- 1 确定dp数组以及下标的含义,
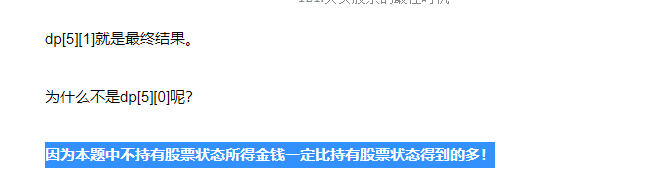
- dp[i][0] 表示第i天持有股票所得现金 ,这里可能有同学疑惑,本题中只能买卖一次,持有股票之后哪还有现金呢?其实一开始现金是0,那么加入第i天买入股票现金就是 -prices[i], 这是一个负数。
- dp[i][1] 表示第i天不持有股票所得现金注意这里说的是“持有”,“持有”不代表就是当天“买入”!也有可能是昨天就买入了,今天保持持有的状态
- 2 确定递归公式
- 如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
- 第i-1天就持有股票,那么就保持现状,所得现金就是昨天持有股票的所得现金 即:dp[i - 1][0]
- 第i天买入股票,所得现金就是买入今天的股票后所得现金即:-prices[i]
- 那么dp[i][0]应该选所得现金最大的,所以dp[i][0] = max(dp[i - 1][0], -prices[i]);
- 如果第i天不持有股票即dp[i][1], 也可以由两个状态推出来
- 第i-1天就不持有股票,那么就保持现状,所得现金就是昨天不持有股票的所得现金 即:dp[i - 1][1]
- 第i天卖出股票,所得现金就是按照今天股票佳价格卖出后所得现金即:prices[i] + dp[i - 1][0]
- 如果第i天持有股票即dp[i][0], 那么可以由两个状态推出来
- 3 dp数组如何初始化
- 由递推公式 dp[i][0] = max(dp[i - 1][0], -prices[i]); 和 dp[i][1] = max(dp[i - 1][1], prices[i] + dp[i - 1][0]);可以看出,其基础都是要从dp[0][0]和dp[0][1]推导出来。
- 那么dp[0][0]表示第0天持有股票,此时的持有股票就一定是买入股票了,因为不可能有前一天推出来,所以dp[0][0] -= prices[0];
- dp[0][1]表示第0天不持有股票,不持有股票那么现金就是0,所以dp[0][1] = 0;
- 4 确定遍历顺序
- 从递推公式可以看出dp[i]都是有dp[i - 1]推导出来的,那么一定是从前向后遍历。
- 5 举例推导dp数组以示例1,输入:[7,1,5,3,6,4]为例,dp数组状态如下:
![[leetcode刷题]汇总(二)_第26张图片](http://img.e-com-net.com/image/info8/6560027390ab467a8ba0367c8af50832.jpg)
// 版本一
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len =prices.size();
vector<vector<int>> dp(len,vector<int>(2));
dp[0][0]=-prices[0];//第一天持有股票
dp[0][1]=0;//第一天不持有股票
for(int i=1;i<len;i++)//从第二天开始
{
dp[i][0]=max(dp[i-1][0],-prices[i]);//今天持有股票 昨天就有了 今天才买
dp[i][1]=max(dp[i-1][1],prices[i]+dp[i-1][0]);//今天不持有股票 昨天不持有 今天才卖
}
return dp[len - 1][1];//注意看这边是返回最后一天不持有股票的利润
}
};
![[leetcode刷题]汇总(二)_第27张图片](http://img.e-com-net.com/image/info8/8a0fe31c0f844a6689c069e3a02afe53.jpg)
// 版本二
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(2, vector<int>(2)); // 注意这里只开辟了一个2 * 2大小的二维数组
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i % 2][0] = max(dp[(i - 1) % 2][0], -prices[i]);
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
}
return dp[(len - 1) % 2][1];
}
};
122 买卖股票的最佳时机(2)(简单)
-
和之前不同的在于可以多次交易
-
重复一下,dp表示当前剩下的钱。
-
唯一不同的在于,允许多次交易,那么今天持有股票(可能一昨天就持有,昨天不持有(但是可能是多次买卖了)今天买入
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);) -
对比一下之前的
dp[i][0] = max(dp[i - 1][0], - prices[i]);
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(len, vector<int>(2, 0));
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]); // 注意这里是和121. 买卖股票的最佳时机唯一不同的地方。
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i]);
}
return dp[len - 1][1];
}
};
// 版本二
class Solution {
public:
int maxProfit(vector<int>& prices) {
int len = prices.size();
vector<vector<int>> dp(2, vector<int>(2)); // 注意这里只开辟了一个2 * 2大小的二维数组
dp[0][0] -= prices[0];
dp[0][1] = 0;
for (int i = 1; i < len; i++) {
dp[i % 2][0] = max(dp[(i - 1) % 2][0], dp[(i - 1) % 2][1] - prices[i]);
dp[i % 2][1] = max(dp[(i - 1) % 2][1], prices[i] + dp[(i - 1) % 2][0]);
}
return dp[(len - 1) % 2][1];
}
};
123买卖股票的最佳时候(困难)(其实也不难 注意看看优化空间的方法)
-
要求最多只能进行两次交易
-
1 确定dp数组以及下标的含义
- 一天一共就有五个状态, 0. 没有操作
- 1 表示已经经历第一次买入
- 2 表示已经经历第一次卖出
- 3 表示已经经历第二次买入
- 4 表示已经经历第二次卖出
- dp[i][j]中 i表示第i天,j为 [0 - 4] 五个状态,dp[i][j]表示第i天状态j所剩最大现金。
-
2确定递推公式
- 达到dp[i][1]状态,有两个具体操作:
- 操作一:第i天买入股票了,那么dp[i][1] = dp[i-1][0] - prices[i]
- 操作二:第i天没有操作,而是沿用前一天买入的状态,即:dp[i][1] = dp[i - 1][1]
- 一定是选最大的,所以 dp[i][1] = max(dp[i-1][0] - prices[i], dp[i - 1][1]);
- 达到dp[i][1]状态,有两个具体操作:
-
同理dp[i][2]也有两个操作:
- 操作一:第i天卖出股票了,那么dp[i][2] = dp[i - 1][1] + prices[i]
- 操作二:第i天没有操作,沿用前一天卖出股票的状态,即:dp[i][2] = dp[i - 1][2]
- 所以dp[i][2] = max(dp[i - 1][1] + prices[i], dp[i - 1][2])
-
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]); dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
![[leetcode刷题]汇总(二)_第28张图片](http://img.e-com-net.com/image/info8/f3eddcd88e7d4192959eaca0ef794835.jpg)
- 4从递归公式其实已经可以看出,一定是从前向后遍历,因为dp[i],依靠dp[i - 1]的数值。
- 5举例推导dp数组
![[leetcode刷题]汇总(二)_第29张图片](http://img.e-com-net.com/image/info8/4f2622cf3a64402585437a4224e1aefb.jpg)
// 版本一
class Solution {
public:
int maxProfit(vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(5, 0));
dp[0][1] = -prices[0];
dp[0][3] = -prices[0];
for (int i = 1; i < prices.size(); i++) {
dp[i][0] = dp[i - 1][0];
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
dp[i][2] = max(dp[i - 1][2], dp[i - 1][1] + prices[i]);
dp[i][3] = max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
}
return dp[prices.size() - 1][4];
}
};
// 版本二
class Solution {
public:
int maxProfit(vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<int> dp(5, 0);
dp[1] = -prices[0];
dp[3] = -prices[0];
for (int i = 1; i < prices.size(); i++) {
dp[1] = max(dp[1], dp[0] - prices[i]);
dp[2] = max(dp[2], dp[1] + prices[i]);
dp[3] = max(dp[3], dp[2] - prices[i]);
dp[4] = max(dp[4], dp[3] + prices[i]);
}
return dp[4];
}
};
做到这边我想到一个问题,就是你认真看看股票的问题 他返回的结果都是最后面的,dp总是表示到今天为止的最好的结果,他也是用这个来搞递推了 和其他的有点区别
188 买卖股票的最佳时机(4)(困难)
- k的买入卖出
- 找到状态的内在规律 ,其实都是不断重复的,多一个for循环
class Solution {
public:
int maxProfit(int k, vector<int>& prices) {
if (prices.size() == 0) return 0;
vector<vector<int>> dp(prices.size(), vector<int>(2 * k + 1, 0));
for (int j = 1; j < 2 * k; j += 2) {
dp[0][j] = -prices[0];
}
for (int i = 1;i < prices.size(); i++) {
for (int j = 0; j < 2 * k - 1; j += 2) {
dp[i][j + 1] = max(dp[i - 1][j + 1], dp[i - 1][j] - prices[i]);
dp[i][j + 2] = max(dp[i - 1][j + 2], dp[i - 1][j + 1] + prices[i]);
}
}
return dp[prices.size() - 1][2 * k];
}
};
309 买卖股票时机含冷冻期(中等)
- 有点绕 我先跳过了
714 买卖股票的最佳时机含手续费
- 就是出售的时候多了一个手续费 ,没有
- 你可以再尝试一下 再修改成两个变量
class Solution {
public:
int maxProfit(vector<int>& prices, int fee) {
int n = prices.size();
vector<vector<int>> dp(n, vector<int>(2, 0));
dp[0][0] -= prices[0]; // 持股票
for (int i = 1; i < n; i++) {
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] - prices[i]);
dp[i][1] = max(dp[i - 1][1], dp[i - 1][0] + prices[i] - fee);
}
return max(dp[n - 1][0], dp[n - 1][1]);
}
};
字典树和并查集
![[leetcode刷题]汇总(二)_第30张图片](http://img.e-com-net.com/image/info8/64a3ceab67f045d9a263017bc56c5820.jpg)
![[leetcode刷题]汇总(二)_第31张图片](http://img.e-com-net.com/image/info8/f3aa011663474540bc8fc1b4ac36cc84.jpg)
![[leetcode刷题]汇总(二)_第32张图片](http://img.e-com-net.com/image/info8/de8f3378cadb47dcbb58b0d1ca8294f9.jpg)
![[leetcode刷题]汇总(二)_第33张图片](http://img.e-com-net.com/image/info8/72f93946c9434f14a9f48c54dbbdfa5f.jpg)
![[leetcode刷题]汇总(二)_第34张图片](http://img.e-com-net.com/image/info8/13175cf02d774707bf4ecfb63f88e897.jpg)
208 实现Trie(前缀树)(中等)
查看细节描述
![[leetcode刷题]汇总(二)_第35张图片](http://img.e-com-net.com/image/info8/f4a031273f6d467b9831e89107e637cc.png)
class Trie {
private:
bool isEnd;//用来判断是不是结尾
Trie* next[26];//存放的都是节点
public:
Trie()
{
isEnd = false;//初始化成员
memset(next, 0, sizeof(next));//清空数组
}
void insert(string word) {
Trie* node = this;//当前不就是根节点
for (int i=0;i<word.length();i++) {
if (node->next[word[i]-'a'] == NULL)
{
node->next[word[i]-'a'] = new Trie();
}
node = node->next[word[i]-'a'];//这边要记得不断进入下一层
}
node->isEnd = true;//这个也要记得,for循环结束记得标记结尾
}
bool search(string word) {
Trie* node = this;
for (int i=0;i<word.length();i++) {
node = node->next[word[i] - 'a'];
if (node == NULL) {
return false;
}
}
return node->isEnd;//并不是遍历结束就好了 你要看看最后的元素是不是结尾
}
bool startsWith(string prefix)
{
//和搜索基本完全一样,就是不需要判断是不是结尾 直接返回true
Trie* node = this;
for (int i=0;i<prefix.length();i++) {
node = node->next[prefix[i]-'a'];
if (node == NULL) {
return false;
}
}
return true;
}
};
79单词搜寻(中等)(待补充)
- 本意是想让你用字符串查找树 和 回溯的
- 这个跟网格的回溯好像啊 回头再看看 因为题解c++中都不是很好
![[leetcode刷题]汇总(二)_第36张图片](http://img.e-com-net.com/image/info8/fcdebb47dcdc4757ae0a081200356c38.png)
![[leetcode刷题]汇总(二)_第37张图片](http://img.e-com-net.com/image/info8/2fe972dc0ded491d88a130dcd4fb5f08.jpg)
class Solution {
public:
bool check(vector<vector<char>>& board, vector<vector<int>>& visited, int i, int j, string& s, int k) {
if (board[i][j] != s[k]) {
return false;
} else if (k == s.length() - 1) {
return true;
}
visited[i][j] = true;
vector<pair<int, int>> directions{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
bool result = false;
for (const auto& dir: directions) {
int newi = i + dir.first, newj = j + dir.second;
if (newi >= 0 && newi < board.size() && newj >= 0 && newj < board[0].size()) {
if (!visited[newi][newj]) {
bool flag = check(board, visited, newi, newj, s, k + 1);
if (flag) {
result = true;
break;
}
}
}
}
visited[i][j] = false;
return result;
}
bool exist(vector<vector<char>>& board, string word) {
int h = board.size(), w = board[0].size();
vector<vector<int>> visited(h, vector<int>(w));
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
bool flag = check(board, visited, i, j, word, 0);
if (flag) {
return true;
}
}
}
return false;
}
};
class Solution {
public:
bool DFS(vector<vector<char>>& board, string& word, int tmpi, int tmpj, int k)
{
if (k == word.size()) return true;
bool flag = false;
if (tmpi > 0 && board[tmpi - 1][tmpj] == word[k])
if (!flag)
{
board[tmpi - 1][tmpj] = 0;
flag = DFS(board, word, tmpi - 1, tmpj, k + 1);
board[tmpi - 1][tmpj] = word[k];
}
if (tmpj > 0 && board[tmpi][tmpj - 1] == word[k])
if (!flag)
{
board[tmpi][tmpj - 1] = 0;
flag = DFS(board, word, tmpi, tmpj - 1, k + 1);
board[tmpi][tmpj - 1] = word[k];
}
if (tmpi < board.size() - 1 && board[tmpi + 1][tmpj] == word[k])
if (!flag)
{
board[tmpi + 1][tmpj] = 0;
flag = DFS(board, word, tmpi + 1, tmpj, k + 1);
board[tmpi + 1][tmpj] = word[k];
}
if (tmpj < board[0].size() - 1 && board[tmpi][tmpj + 1] == word[k])
if (!flag)
{
board[tmpi][tmpj + 1] = 0;
flag = DFS(board, word, tmpi, tmpj + 1, k + 1);
board[tmpi][tmpj + 1] = word[k];
}
return flag;
}
bool exist(vector<vector<char>>& board, string word) {
int index = 0;
for (int i = 0; i < board.size(); ++i)
{
for (int j = 0; j < board[0].size(); ++j)
{
if (board[i][j] == word[0])
{
board[i][j] = 0;
if (DFS(board, word, i, j, 1))
return true;
board[i][j] = word[0];
}
}
}
return false;
}
};
212. 单词搜索 II(困难)(待补充)
并查集
![[leetcode刷题]汇总(二)_第38张图片](http://img.e-com-net.com/image/info8/e5907589a873467fbd81d3191fd6958b.jpg)
![[leetcode刷题]汇总(二)_第39张图片](http://img.e-com-net.com/image/info8/7a49b61dd8a94db6b32ac078f15d5802.jpg)
200 岛屿问题(中等)
- 我们之前用深度优先来做
- 现在想想用并查集来做,但是并不是主流做法,没办法,看看有没有其他的经典题目
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
int nr = grid.size();
if (!nr) return 0;
int nc = grid[0].size();
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
dfs(grid, r, c);
}
}
}
return num_islands;
}
bool inArea(vector<vector<char>>& grid,int r,int c)
{
return 0 <= r && r < grid.size() && 0 <= c && c < grid[0].size();
}
void dfs(vector<vector<char>>& grid, int r, int c)
{
if (!inArea(grid,r,c))//如果到达边界直接返回
{
return;
}
if(grid[r][c] != '1')//表示是海或者标记过了 注意这边 设置为2 就是为了防止一直转圈圈
{
return;
}
grid[r][c]=2;//把格子标记位已遍历过的 当前层的逻辑 就是
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
};
class UnionFind {
public:
UnionFind(vector<vector<char>>& grid) {
count = 0;
int m = grid.size();
int n = grid[0].size();
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] == '1') {
parent.push_back(i * n + j);
++count;
}
else {
parent.push_back(-1);
}
rank.push_back(0);
}
}
}
int find(int i) {
if (parent[i] != i) {
parent[i] = find(parent[i]);
}
return parent[i];
}
void unite(int x, int y) {
int rootx = find(x);
int rooty = find(y);
if (rootx != rooty) {
if (rank[rootx] < rank[rooty]) {
swap(rootx, rooty);
}
parent[rooty] = rootx;
if (rank[rootx] == rank[rooty]) rank[rootx] += 1;
--count;
}
}
int getCount() const {
return count;
}
private:
vector<int> parent;
vector<int> rank;
int count;
};
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
int nr = grid.size();
if (!nr) return 0;
int nc = grid[0].size();
UnionFind uf(grid);
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
grid[r][c] = '0';
if (r - 1 >= 0 && grid[r-1][c] == '1') uf.unite(r * nc + c, (r-1) * nc + c);
if (r + 1 < nr && grid[r+1][c] == '1') uf.unite(r * nc + c, (r+1) * nc + c);
if (c - 1 >= 0 && grid[r][c-1] == '1') uf.unite(r * nc + c, r * nc + c - 1);
if (c + 1 < nc && grid[r][c+1] == '1') uf.unite(r * nc + c, r * nc + c + 1);
}
}
}
return uf.getCount();
}
};
高级搜索
![[leetcode刷题]汇总(二)_第40张图片](http://img.e-com-net.com/image/info8/d094fe18854a4c64af805d276179b366.jpg)
![[leetcode刷题]汇总(二)_第41张图片](http://img.e-com-net.com/image/info8/03a95d53d8b64079a2889d9052d40469.jpg)
爬楼梯
八皇后
36有效的数独(中等)
- 这个单纯是循环和判断,但是很巧妙的是他利用了三个数组,分别判断是否出现所在行 所在列 所在33格子(特别注意他把这边的33格子转换成一行的方法)还有就是出现数字是几,就把对应下标对应的值修改值得学习。
class Solution {
public:
bool isValidSudoku(vector<vector<char>>& board) {
int row[9][10] = {0};// 哈希表存储每一行的每个数是否出现过,默认初始情况下,每一行每一个数都没有出现过
// 整个board有9行,第二维的维数10是为了让下标有9,和数独中的数字9对应。
int col[9][10] = {0};// 存储每一列的每个数是否出现过,默认初始情况下,每一列的每一个数都没有出现过
int box[9][10] = {0};// 存储每一个box的每个数是否出现过,默认初始情况下,在每个box中,每个数都没有出现过。整个board有9个box。
for(int i=0; i<9; i++){
for(int j = 0; j<9; j++){
// 遍历到第i行第j列的那个数,我们要判断这个数在其所在的行有没有出现过,
// 同时判断这个数在其所在的列有没有出现过
// 同时判断这个数在其所在的box中有没有出现过
if(board[i][j] == '.') continue;
int curNumber = board[i][j]-'0';
if(row[i][curNumber]) return false;
if(col[j][curNumber]) return false;
if(box[j/3 + (i/3)*3][curNumber]) return false;
row[i][curNumber] = 1;// 之前都没出现过,现在出现了,就给它置为1,下次再遇见就能够直接返回false了。
col[j][curNumber] = 1;
box[j/3 + (i/3)*3][curNumber] = 1;
}
}
return true;
}
};
37 解数独(困难)(剪枝回溯)
代码随想录的思路
我思考返回值类型是什么,你看看他这个把函数返回值作为判断条件,只要满足了一个就退出所有层函数的写法。- 还有一个,他这种写法虽然for循环重复走了好多(每次进入函数都要从头遍历),但是确实好理解,你可以把函数的传入参数看做每次都是一个新的棋盘(都填入一个的棋盘)
![[leetcode刷题]汇总(二)_第42张图片](http://img.e-com-net.com/image/info8/46efd4dfb96e4fce920687be2adfad41.jpg)
其他还有但是我没做,等复习前面的深度和广度
红黑树和AVL
![[leetcode刷题]汇总(二)_第43张图片](http://img.e-com-net.com/image/info8/36b83ec487374eb4b33da1818a242d1d.jpg)
![[leetcode刷题]汇总(二)_第44张图片](http://img.e-com-net.com/image/info8/035ef31f3d4d490aa5821a52552cf226.jpg)
![[leetcode刷题]汇总(二)_第45张图片](http://img.e-com-net.com/image/info8/92a70357193f46aabef23b801bb36350.jpg)
![[leetcode刷题]汇总(二)_第46张图片](http://img.e-com-net.com/image/info8/b6964a7a42ba4444bde18e40fea3cbb7.jpg)
![[leetcode刷题]汇总(二)_第47张图片](http://img.e-com-net.com/image/info8/d8c1df739a544e00aa2cb2bb9b60ca21.jpg)
![[leetcode刷题]汇总(二)_第48张图片](http://img.e-com-net.com/image/info8/f428add360a044759e8bb81022ce09d6.jpg)
![[leetcode刷题]汇总(二)_第49张图片](http://img.e-com-net.com/image/info8/128a2afb246241f384922e38c281f87b.jpg)
![[leetcode刷题]汇总(二)_第50张图片](http://img.e-com-net.com/image/info8/b85131b709214754a146e029b9634bbd.jpg)
![[leetcode刷题]汇总(二)_第51张图片](http://img.e-com-net.com/image/info8/82237c29d33d49efb2c9193ed15cf17d.jpg)
![[leetcode刷题]汇总(二)_第52张图片](http://img.e-com-net.com/image/info8/37f2e2c3981b4a9896e65eb8027c1fea.jpg)
![[leetcode刷题]汇总(二)_第53张图片](http://img.e-com-net.com/image/info8/e3bfc643c9a94546b582eb034a4ffbbf.jpg)
![[leetcode刷题]汇总(二)_第54张图片](http://img.e-com-net.com/image/info8/6d6db47e101b483bb58ecb422234d349.jpg)
![[leetcode刷题]汇总(二)_第55张图片](http://img.e-com-net.com/image/info8/43d01a7310f84c2aa36dbd30d5161a00.jpg)
![[leetcode刷题]汇总(二)_第56张图片](http://img.e-com-net.com/image/info8/7e1536fb228c48b7b893665ec91c5fa5.jpg)
![[leetcode刷题]汇总(二)_第57张图片](http://img.e-com-net.com/image/info8/62947f5a6f4e4f8fb5cf13760e813837.jpg)
![[leetcode刷题]汇总(二)_第58张图片](http://img.e-com-net.com/image/info8/ce22fa2609104fd2bda55a15e8e00ffe.jpg)
![[leetcode刷题]汇总(二)_第59张图片](http://img.e-com-net.com/image/info8/46f72a66b1764144bb6757f041230cee.jpg)
![[leetcode刷题]汇总(二)_第60张图片](http://img.e-com-net.com/image/info8/6602c9578f1c4f9a97258a9b07e1c8c9.jpg)
-
和红黑树相比,AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树)。
-
红黑树在查找方面和AVL树操作几乎相同。但是在插入和删除操作上,AVL树每次插入删除会进行大量的平衡度计算,红黑树是牺牲了严格的高度平衡的优越条件为代价,它只要求部分地达到平衡要求,结合变色,降低了对旋转的要求,从而提高了性能。红黑树能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决。
![[leetcode刷题]汇总(二)_第61张图片](http://img.e-com-net.com/image/info8/66f325a537394bb28fd70d3201b98c15.jpg)
位运算
- 10进制和2进制的转换,一个是除2取余,一个是幂
- 位运算符
![[leetcode刷题]汇总(二)_第62张图片](http://img.e-com-net.com/image/info8/7ff79c2856154f3fb311b2b5f484855b.jpg)
- 或 与 取反 异或(相同为0 不同为1)
![[leetcode刷题]汇总(二)_第63张图片](http://img.e-com-net.com/image/info8/ae5d7acbff4347e1a1cd8de82e8f8f57.jpg)
![[leetcode刷题]汇总(二)_第64张图片](http://img.e-com-net.com/image/info8/81dd2341d8f045c9b7b210de50f85a00.jpg)
![[leetcode刷题]汇总(二)_第65张图片](http://img.e-com-net.com/image/info8/f5b6397ab9ab4a419a13b72bd290f28b.jpg)
![[leetcode刷题]汇总(二)_第66张图片](http://img.e-com-net.com/image/info8/3075182f4ca3495aadcd653e0ccbfc2a.jpg)
- 比较常见的如上
191 位1的个数(简单)
![[leetcode刷题]汇总(二)_第67张图片](http://img.e-com-net.com/image/info8/b753238584e14325b0dc9f456eef21a2.jpg)
- 方法一:就是遍历一遍
- 方法二:位运算 利用 x&(x-1)就是打掉最低位的一,举个例子6(110)&5(101)=4(100)
class Solution {
public:
int hammingWeight(uint32_t n) {
int ret=0;
while(n!=0)
{
n=n&(n-1);
ret++;//看看进入几次循环 就有几个1
}
return ret;
}
};
231 2的幂
![[leetcode刷题]汇总(二)_第68张图片](http://img.e-com-net.com/image/info8/e35b8586b2a94dc293a7f123388c1dd0.png)
- 就是不要忘记了 如果是2的次幂 那么二进制只有一个2这个特点
class Solution {
public:
bool isPowerOfTwo(int n)
{
if(n>0)
{
n=n & (n - 1);
if (n==0) return true;
else return false;
}
return false;
}
};
190颠倒二进制位(主要就是考察位运算符用的怎么样)
- 0|n 就是拷贝
- ans<<1 就是移动
- n&1 就是取最低位
class Solution {
public:
uint32_t reverseBits(uint32_t n) {
uint32_t ans=0; //初始化
for(int i=0; i<32; ++i){
ans = (ans<<1) | (n&1); //逐位计算,每次将n的末位放入ans中
n>>=1; //右移
}
return ans;
}
};
51 N皇后(困难)(位运算判断)
- 回头再看
class Solution {
public:
int totalNQueens(int n) {
return solve(n, 0, 0, 0, 0);
}
int solve(int n, int row, int columns, int diagonals1, int diagonals2) {
if (row == n) {
return 1;
} else {
int count = 0;
int availablePositions = ((1 << n) - 1) & (~(columns | diagonals1 | diagonals2));
while (availablePositions != 0) {
int position = availablePositions & (-availablePositions);
availablePositions = availablePositions & (availablePositions - 1);
count += solve(n, row + 1, columns | position, (diagonals1 | position) << 1, (diagonals2 | position) >> 1);
}
return count;
}
}
};
338 比特位计数(简单)
- 没什么特别的 ,就是习惯一下而已
![[leetcode刷题]汇总(二)_第69张图片](http://img.e-com-net.com/image/info8/a28b2b7511b54e6a97041184d14fc0d8.jpg)
class Solution {
public:
int countOnes(int x) {
int ones = 0;
while (x > 0) {
x &= (x - 1);
ones++;
}
return ones;
}
vector<int> countBits(int n) {
vector<int> bits(n + 1);
for (int i = 0; i <= n; i++) {
bits[i] = countOnes(i);
}
return bits;
}
};
布隆过滤器 LRU缓存
- 复习对比了一下哈希映射和哈希冲突
![[leetcode刷题]汇总(二)_第70张图片](http://img.e-com-net.com/image/info8/f8e231a0d4e84d25900b91440d1647ba.jpg)
![[leetcode刷题]汇总(二)_第71张图片](http://img.e-com-net.com/image/info8/7a267b688f6d4f0a95510a726d92391f.jpg)
- 对比在于hash表不只是判断在不在集合 还可以存其他很多冗余的信息
- 布隆过滤器之判断在不在,有点就是空间效率(二进制节省空间)和查询时间都很快
![[leetcode刷题]汇总(二)_第72张图片](http://img.e-com-net.com/image/info8/07f6dae43b1b46bc9dcce6e6b969f6fe.jpg)
- 看上图 ,就是每一个元素都分配几个二进制位(可以有重叠)。这会出现上面的情况(左边是插入的,右边是测试的,很明显B判断错了)。
- 总结起来就是布隆过滤器判断不存在就一定不存在,判断存在可能存在。那他有什么用呢,就是放在一台机器(数据库)前面的快速查询的缓存(判断在了再去数据库判断一遍)
![[leetcode刷题]汇总(二)_第73张图片](http://img.e-com-net.com/image/info8/b5dde4a8b91849f4a12019d5d64e05fd.jpg)
- 上面的图片几种常用的场景。
- 我们都知道一个元素对应多二进制位(这就需要多个hash函数进行hash映射)
![[leetcode刷题]汇总(二)_第74张图片](http://img.e-com-net.com/image/info8/9f760861f2324b36bb1a170b6dfb94e2.jpg)
- 实现就是 hash+一个双向链表来实现,非常的快
![[leetcode刷题]汇总(二)_第75张图片](http://img.e-com-net.com/image/info8/3ad11cb64d154249b79b2124559282d4.jpg)
- 你注意看他这个缓存的替换算法,就是最旧没用的就给他剔除,
- LRU 这个名字意思就是最少最近未使用,表示的是一种替换规则,当然也有其他的 LFU
146 LRU 缓存机制(中等)(双向链表和hash)
- 比较考验基本功 需要好好写
- 第二个代码我自己写的 节点用class 可能好看一点
- 有一个需要注意的是 链表节点除了左右节点还有key和value,key的作用主要用于当缓存满了,我们取出链表的最后一个进行删除,并且我们要知道他在hash表中的key才能erase进行删除
- 头结点 和尾节点 没有放在hash表中,并且是空的,实际上放-1就好
看看这个代码解释 写的很好
![[leetcode刷题]汇总(二)_第76张图片](http://img.e-com-net.com/image/info8/a6ca396134f04a538666730e628f7a31.jpg)
![[leetcode刷题]汇总(二)_第77张图片](http://img.e-com-net.com/image/info8/c6e446e41aa04ebb87da2d7bcbc0f5b0.jpg)
class LRUCache {
public:
//定义双链表
struct Node{
int key,value;//一个放时间戳 一个放具体的值
Node* left ,*right;//左指针 右指针
Node(int _key,int _value): key(_key),value(_value),left(NULL),right(NULL){} //初始化
}*L,*R;//双链表的最左和最右节点,不存贮值。
int n;
unordered_map<int,Node*>hash;//初始化一个哈希表
void remove(Node* p)//删除操作
{
p->right->left = p->left;//这个都简单 就是简单就该指向
p->left->right = p->right;
}
void insert(Node *p)//插入操作 插入到首个
{
//先安置好l右边原来的指向 再来处理l和p之间的关系
p->right = L->right;
p->left = L;
L->right->left = p;//主要是注意这边是下面的语句的前面
L->right = p;
}
LRUCache(int capacity) {
n = capacity;//这个是容量大小
L = new Node(-1,-1),R = new Node(-1,-1);
L->right = R;
R->left = L;
}
//或许某个元素的值
int get(int key)
{
if(hash.count(key) == 0) return -1; //不存在关键字 key
auto p = hash[key];//有点意思 不知道返回值类型直接用auto
remove(p);//移除
insert(p);//将当前节点放在双链表的第一位
return p->value;
}
//放入
void put(int key, int value) {
if(hash.count(key)) //如果key存在,则修改对应的value
{
auto p = hash[key];
p->value = value;
remove(p);
insert(p);
}
else
{
if(hash.size() == n) //如果缓存已满,则删除双链表最右侧的节点
{
auto p = R->left;
remove(p);
hash.erase(p->key); //更新哈希表
delete p; //释放内存
}
//否则,插入(key, value)
auto p = new Node(key,value);
hash[key] = p;
insert(p);
}
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
class Node{
public:
int key,value;
Node* right;
Node* left;
Node(int _key,int _value)
{
key=_key;
value=_value;
}
};
class LRUCache {
public:
//四个成员
Node* L;//尾节点
Node* R;//头结点
int n;//容量
unordered_map<int,Node*>hash;//初始化一个哈希表
//构造函数 初始化
LRUCache(int capacity)
{
n = capacity;//这个是容量大小
L = new Node(-1,-1),R = new Node(-1,-1); //这两个节点 没有实际的值并且不插入哈希表
//下面这个好容易忘记 头尾串起来 一开始
L->right = R;
R->left = L;
}
void remove(Node* p)//链表节点的删除操作,并不是真的释放空间 特别注意
{
p->right->left = p->left;//这个都简单 就是简单就该指向
p->left->right = p->right;
}
void insert(Node *p)//链表的插入操作 插入到首个
{
//先安置好l右边原来的指向 再来处理l和p之间的关系
p->right = L->right;
p->left = L;
L->right->left = p;//主要是注意这边是下面的语句的前面
L->right = p;
}
//得到某个元素的值
int get(int key)
{
if(hash.count(key) == 0) return -1; //不存在关键字 key
auto p = hash[key];//有点意思 不知道返回值类型直接用auto
remove(p);//移除,没有释放空间
insert(p);//将当前节点放在双链表的第一位
return p->value;//注意这边 key是int value是地址 我们要返回地址的值
}
//放入
void put(int key, int value)
{
if(hash.count(key)) //如果key存在,则修改对应的value
{
auto p = hash[key];
p->value = value;//直接修改 内部的值
remove(p);//移除 p
insert(p);//插入到开头
}
else
{
if(hash.size() == n) //如果缓存已满,则删除双链表最右侧的节点
{
auto p = R->left;//这个表示实际数据的最后一个
remove(p);
hash.erase(p->key); //更新哈希表,这个很容易忘记
delete p; //释放内存
}
//否则,插入(key, value)
auto p = new Node(key,value);
hash[key] = p;
insert(p);
}
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
排序算法
![[leetcode刷题]汇总(二)_第78张图片](http://img.e-com-net.com/image/info8/8cb272fc4d3c4e3ab58a34beaea67789.jpg)
![[leetcode刷题]汇总(二)_第79张图片](http://img.e-com-net.com/image/info8/b1a02bd5a688404c8930845deb11371c.jpg)
![[leetcode刷题]汇总(二)_第80张图片](http://img.e-com-net.com/image/info8/20d5923e446d4c52b19ffc5a7a235ebf.jpg)
![[leetcode刷题]汇总(二)_第81张图片](http://img.e-com-net.com/image/info8/1068b125c3cd435ba281a3470871cbbd.jpg)
![[leetcode刷题]汇总(二)_第82张图片](http://img.e-com-net.com/image/info8/bcbe392c3ce944a9a515ebd997751ab8.jpg)
![[leetcode刷题]汇总(二)_第83张图片](http://img.e-com-net.com/image/info8/807e307256544e14a498c9641c44bda9.jpg)
![[leetcode刷题]汇总(二)_第84张图片](http://img.e-com-net.com/image/info8/d50b592997f24c62a257e810d9b1a804.jpg)
![[leetcode刷题]汇总(二)_第85张图片](http://img.e-com-net.com/image/info8/49c778bb102345308eb90376559872e8.jpg)
- 9种排序描述
![[leetcode刷题]汇总(二)_第86张图片](http://img.e-com-net.com/image/info8/dde962014e3c4cb09dadd2d6ac3f29f1.jpg)
![[leetcode刷题]汇总(二)_第87张图片](http://img.e-com-net.com/image/info8/81020b6a8793477eb1dc57e46dbf7f92.jpg)
![[leetcode刷题]汇总(二)_第88张图片](http://img.e-com-net.com/image/info8/68867c6b208f4e4aa7c872b64ec53135.jpg)
242 有效字母异位词
- 我们之前用的就是特殊排序中的计数排序 但是之前不知道
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length()!=t.length())
{
return false;
}
vector<int> table(26,0);
for (int i=0;i<s.length();i++)
{
table[s[i]-'a']++;
}
for (int i=0;i<t.length();i++)
{
table[t[i]-'a']--;
if(table[t[i]-'a']<0)
{
return false;
}
}
return true;
}
};
1122 数组的相对排序
- 计数排序的方式,很巧妙,把arr1 放入到辅助数组内部。然后用arr2来判断是否存在取出。最后把辅助数组内没取出的按照顺序取出来就可以达到一个排序的效果了。
- 三个循环,如果是普通的排序只要两个循环 第一个和第三个
- 这边的三个循环
- 第一个是对操作的数组进行放入辅助数组计数
- 第二个 进行对比有没有出现在arr2 出现的输出到结果(按照出现的频率 输出对应的个数)
- 第三个就是 对哪些没有取出,也就是arr2没出现的arr1出现的按照下标从1 到1001 逐个输出来
- 需要注意的是辅助数组的大小根据题目的要求进行设定
![[leetcode刷题]汇总(二)_第89张图片](http://img.e-com-net.com/image/info8/185a757b72a342b2bf53fc48003062c3.jpg)
class Solution {
public:
vector<int> relativeSortArray(vector<int>& arr1, vector<int>& arr2) {
vector<int> result;//存放结果的
vector<int> freq(1001,0);//辅助的 计数用的
for (int i=0;i<arr1.size();i++)//对arr1进行计数
{
freq[arr1[i]]++;
}
for(int i=0;i<arr2.size();i++)
{
while(freq[arr2[i]]!=0)//数字作为下标 或许数量
{
result.push_back(arr2[i]);//把数字放入到结果
freq[arr2[i]]--;//计数统计少一
}
}
for(int i=0;i<1001;i++)//这个就是把没取完的arr1取出来放入结果 按照递增的
{
while(freq[i]!=0)
{
result.push_back(i);//下标就是数值
freq[i]--;
}
}
return result;
}
};
56 合并区间(中等)
- 根据左边界进行排序
- 如果第二个值的左边界 小于第一个值的右边界 那就合并(左边界其实就是第一值的左边界 右边界就是max())如果出现第一个不符合了 就把边界放入结果 重新取start 和 end 继续循环
- 如果第二个值的
- 第三个代码 放了个简洁版本的添加链接描述
class Solution {
public:
// 按照区间左边界从小到大排序
static bool cmp (const vector<int>& a, const vector<int>& b) {
return a[0] < b[0];
}
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> result;
if (intervals.size() == 0) return result;
sort(intervals.begin(), intervals.end(), cmp);
bool flag = false; // 标记最后一个区间有没有合并
int length = intervals.size();
for (int i = 1; i < length; i++) {
int start = intervals[i - 1][0]; // 初始为i-1区间的左边界
int end = intervals[i - 1][1]; // 初始i-1区间的右边界
while (i < length && intervals[i][0] <= end) { // 合并区间
end = max(end, intervals[i][1]); // 不断更新右区间
if (i == length - 1) flag = true; // 最后一个区间也合并了
i++; // 继续合并下一个区间
}
// start和end是表示intervals[i - 1]的左边界右边界,所以最优intervals[i]区间是否合并了要标记一下
result.push_back({start, end});
}
// 如果最后一个区间没有合并,将其加入result
if (flag == false) {
result.push_back({intervals[length - 1][0], intervals[length - 1][1]});
}
return result;
}
};
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
vector<vector<int>> result;
if (intervals.size() == 0) return result;
// 排序的参数使用了lamda表达式
sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){return a[0] < b[0];});
result.push_back(intervals[0]);
for (int i = 1; i < intervals.size(); i++) {
if (result.back()[1] >= intervals[i][0]) { // 合并区间
result.back()[1] = max(result.back()[1], intervals[i][1]);
} else {
result.push_back(intervals[i]);
}
}
return result;
}
};
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
sort(intervals.begin(), intervals.end());
vector<vector<int>> ans;
for (int i = 0; i < intervals.size();) {
int t = intervals[i][1];
int j = i + 1;
while (j < intervals.size() && intervals[j][0] <= t) {
t = max(t, intervals[j][1]);
j++;
}
ans.push_back({ intervals[i][0], t });
i = j;
}
return ans;
}
};
493 翻转对(困难)(待补充)
- 看题解3 复习完归并排序再来看这个 有点没看懂
字符串
- c++中的字符串是可变的 python 和 java中的字符串是不可变的 ,你修改他就是创建一个新的
- 字符处的遍历方式 就是 length
709 转换成小写字母(简单)
- 给你一个字符串 s ,将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。
- 还算巧妙 最起码 我第一个时间只是想ascil
class Solution {
public:
string toLowerCase(string s) {
for (int i=0; i<s.length();i++)
{
if(s[i]<='Z'&&s[i]>='A')
{
s[i]=s[i]-'A'+'a';
}
}
return s;
}
};
56 最后一个单词的长度(简单)
- 给你一个字符串 s,由若干单词组成,单词之间用单个或多个连续的空格字符隔开。返回字符串中最后一个单词的长度。如果不存在最后一个单词,请返回 0 。
- 这个就是需要考虑最后前置和后置空格的情况(通过遍历 修改起始坐标),毫无疑问肯定要从后面遍历
- 还有一个 ‘ ’ 这个来表示空格
class Solution {
public:
int lengthOfLastWord(string s) {
int count = 0, i = s.length()-1;
while(i>=0&&s[i]==' ')
{
i--;
}
for(i;i>=0;i--)
{
if(s[i]!=' ')
{
count++;
}
else
break;
}
return count;
}
};
771宝石和石头(简单)
![[leetcode刷题]汇总(二)_第90张图片](http://img.e-com-net.com/image/info8/1880fa9b519e460a9d8e9f63b962af71.jpg)
- 其实这个题一看知道遍历或者哈希来做了
- hash也简单 你要么就把宝石放在hash中每次遍历石头看看在不在宝石中,在的化+1
class Solution {
public:
int numJewelsInStones(string jewels, string stones)
{
int count=0;
for(int i=0;i<stones.length();i++)
{
for(int j=0;j<jewels.length();j++)
{
if(stones[i]==jewels[j])
{
count++;
}
}
}
return count;
}
};
class Solution {
public:
map<char, int> Map;
int numJewelsInStones(string jewels, string stones) {
int count=0;
for(int i=0; i<jewels.length();i++){
Map[jewels[i]]=1;
}
for(int i=0; i<stones.length();i++){
if(Map.count(stones[i])==1){
count++;
}
}
return count;
}
};
387 字符串中的第一个唯一字符
![[leetcode刷题]汇总(二)_第91张图片](http://img.e-com-net.com/image/info8/a07862ac04f64f788678dc94e0913fd3.jpg)
-建立一个hash 键是char 值是频率 看他出现了几次,第一个循环就拉构建这个hash 第二个循环用来判断
class Solution {
public:
int firstUniqChar(string s) {
unordered_map<char, int> frequency;
for (int i=0;i<s.length();i++) {
frequency[s[i]]++;
}
for (int i = 0; i < s.length(); i++) {
if (frequency[s[i]] == 1)//他的值只有一个
{
return i;
}
}//循环结束都没有那就返回-1了
return -1;
}
};
8 字符串转换成整数(中等)
![[leetcode刷题]汇总(二)_第92张图片](http://img.e-com-net.com/image/info8/3db13af3e6ff47db80f85a4f4e577038.jpg)
- 这个题目要求有点多
- 首先要考虑前置的空格
- 其次要判断正负号
- 读到最后 遇到非数字就去掉
- 还要判断有没有超过32位有符号的整数范围,超过了怎么就用那个极值来表示
题解
![[leetcode刷题]汇总(二)_第93张图片](http://img.e-com-net.com/image/info8/13579bca25d74586946406b701f4b4ad.jpg)
- 取出前置空格
- 判断如果不是数字 不是整号 不是负号直接结束
- 这个时候开始只有3种可能数字 负 正,如果不是负 那就那就设置标记 =1 如果是负 设置标记位 -1 后面用来乘
- 继续往后读呗 循环条件就是不超过范围并且是数字,这个时候设置res 每次*10+digit(注意看字母怎么转换成数字的)同时在循环不断判断有没有res有没有超过范围
class Solution {
public:
/* 辅助函数:
- 返回整数是否超过整数范围
*/
bool tooLarge(long long res) {
return res >= INT_MAX || res <= INT_MIN;
}
/*
函数功能: 输入字符串, 输出对应的整数.
逻辑:
1. 去除前置空格
2. 检查下一个字符是正还是负, 若两者都不存在, 假设为正.
3. 往后读字符, 直到到达非数字字符, 或是到达字符串的末尾.
4. 把读入的字符转为带符号整数
5. 如果整数超过整数范围, 做截断.
*/
int myAtoi(string s) {
int i = 0;
int len = s.length();
if (len == 0) return 0;
// 1. 去除前置空格
while (i < len && s[i] == ' ')++i;
// 2. 检查下一个字符是正还是负, 若两者都不存在, 假设为正
if(isdigit(s[i]) == false && s[i] != '-' && s[i] != '+') return 0;
int poitiveSign = (s[i] != '-') ? 1 : -1;
if (isdigit(s[i]) == false) ++i;
// 3. 往后读字符, 直到到达非数字字符, 或是到达字符串的末尾.
long long res = 0;
bool beginPos = true;
while (i < len && isdigit(s[i])) {
int digit = s[i] - '0';
// 4. 把读入的字符转为整数
res = res * 10 + digit;
bool stop = tooLarge(res * poitiveSign);
if (stop) return poitiveSign == 1 ? INT_MAX : INT_MIN; // 数字的绝对值已经很大了, 后面的数不用再考虑.
++i;
}
return (int)(res * poitiveSign);
}
};
前面都是字符串基础问题
这边是字符串操作问题
14 最长公共前缀(简单)
- 这个我没有认真看 直接遍历扫描不就好了,高度固定 长度随便取一个(或者提前遍历一遍min找出最小值就好了 我觉的可以)
class Solution {
public:
string longestCommonPrefix(vector<string>& strs) {
if (!strs.size()) {
return "";
}
string prefix = strs[0];
int count = strs.size();
for (int i = 1; i < count; ++i) {
prefix = longestCommonPrefix(prefix, strs[i]);
if (!prefix.size()) {
break;
}
}
return prefix;
}
string longestCommonPrefix(const string& str1, const string& str2) {
int length = min(str1.size(), str2.size());
int index = 0;
while (index < length && str1[index] == str2[index]) {
++index;
}
return str1.substr(0, index);
}
};
344 反转字符串(简单)
![[leetcode刷题]汇总(二)_第94张图片](http://img.e-com-net.com/image/info8/0164759d674b47c48283b70e02de7848.jpg)
- 想想就知道 不就是收尾交换么,这个就是要注意他的写法 ,很常见一定要掌握
- c++有很多好用的函数 如 swap isdigit等等常见要掌握
class Solution {
public:
void reverseString(vector<char>& s) {
int n = s.size();
for (int left = 0, right = n - 1; left < right; ++left, --right) {
swap(s[left], s[right]);
}
}
};
345 翻转字符串2(简单)
- 这个还挺有意思的
- 虽然我们调用了 reserve这个函数,但是这个我们可以自己实现,344不就是了
![[leetcode刷题]汇总(二)_第95张图片](http://img.e-com-net.com/image/info8/1e665021aa4949c3b0f9009f5e60f94e.jpg)
- 注意看i的变化,比较少见 可以学习
class Solution {
public:
string reverseStr(string s, int k) {
for (int i = 0; i < s.size(); i += (2 * k)) {
// 1. 每隔 2k 个字符的前 k 个字符进行反转
// 2. 剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符
if (i + k <= s.size()) {
reverse(s.begin() + i, s.begin() + i + k );
continue;
}
// 3. 剩余字符少于 k 个,则将剩余字符全部反转。
reverse(s.begin() + i, s.begin() + s.size());
}
return s;
}
};
151翻转字符串里的单词(中等)(认真看)
![[leetcode刷题]汇总(二)_第96张图片](http://img.e-com-net.com/image/info8/a75af455ae8f467cb226f79daebda0de.jpg)
![[leetcode刷题]汇总(二)_第97张图片](http://img.e-com-net.com/image/info8/0287b1d69f424838acf42684375bc2ac.jpg)
![[leetcode刷题]汇总(二)_第98张图片](http://img.e-com-net.com/image/info8/6386d99e243b4221a68a2914710fce2b.jpg)
![[leetcode刷题]汇总(二)_第99张图片](http://img.e-com-net.com/image/info8/21b19cd4633d460594832ce0110774d8.jpg)
-
简单就是把字符串都截取出来 然后倒着拼接
-
还有一个就是上面说的 全部倒着reserve(end 表示的是最后一个字母的后一个),然后搞一个双指针(好好想想这个双指针如何设置 毕竟我们要指向一个字符串的头和尾) 逐个reserve
-
认真看代码的逻辑 可以学到很多
- 注意
- 双指针的使用 一开始 i赋值给j 最后j复制给i
- 第二个就是不用额外空间 字母前移,需要k这和变量(特别注意那边的i
- 第三就是每次补上一个空格
- 第四就是注意j的含义 表示的是最后一个字母下一个的坐标
- 第五就是一开始整体翻转 ,后面才逐个翻转
class Solution {
public:
string reverseWords(string s) {
reverse(s.begin(), s.end());//首先翻转整个列表
int n = s.size();//求一下藏毒
int k = 0;//用来向前移动的
for (int i = 0; i < n; i ++ ) //一次循环就是翻转一个单词
{
if (s[i] == ' ') continue;//如果是空格后移
int j = i;//去除出空格后 就可以开始把i复制给j了
//如果没到结尾 那就一直j 这边的j你想想是不是可以表示个数 他就是最后一个字母的后一位
while (j < n && s[j] != ' ') j++;
reverse(s.begin() + i, s.begin() + j);//翻转 是j不是j-1 因为要表示最后有一个字母的后一个
while( i < j) s[k++] = s[i++];//(易错)开始前移动 这边很巧妙 并且是i
if (k != 0) s[k ++ ] = ' ';//用来填充一个空格 一开始不用填充,移动后 马上填充一个空格
i = j;//修改初始点
}
s.erase(s.begin() + k-1, s.end());//删除后面的空格
return s;
}
};
557 反转字符串中的单词2(简单)
- 上面都懂了 这边不用说了
class Solution {
public:
string reverseWords(string s) {
//reverse(s.begin(), s.end());//首先翻转整个列表
int n = s.size();//求一下藏毒
int k = 0;//用来向前移动的
for (int i = 0; i < n; i ++ ) //一次循环就是翻转一个单词
{
if (s[i] == ' ') continue;//如果是空格后移
int j = i;//去除出空格后 就可以开始把i复制给j了
//如果没到结尾 那就一直j 这边的j你想想是不是可以表示个数 他就是最后一个字母的后一位
while (j < n && s[j] != ' ') j++;
reverse(s.begin() + i, s.begin() + j);//翻转 是j不是j-1 因为要表示最后有一个字母的后一个
while( i < j) s[k++] = s[i++];//(易错)开始前移动 这边很巧妙 并且是i
if (k != 0) s[k ++ ] = ' ';//用来填充一个空格 一开始不用填充,移动后 马上填充一个空格
i = j;//修改初始点
}
s.erase(s.begin() + k-1, s.end());//删除后面的空格
return s;
}
};