c++入门基础(命名冲突问题和缺省参数)
1.命名冲突问题
我们先按c语言的写法来写串代码
代码
#include
int rand = 0;
int main()
{
printf("%d\n", rand);
return 0;
} 运行一下
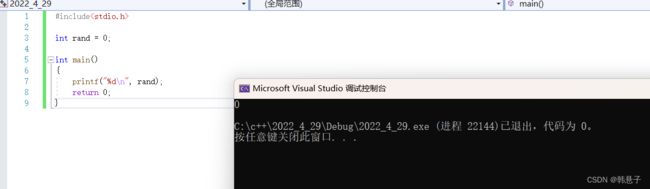
没有出现问题,可以看出c++是支持C语言的语法的
但是c语言有个很致命的问题命名冲突问题,我们在代码里面加入#include
代码
#include
#include
int rand = 0;
int main()
{
printf("%d\n", rand);
return 0;
} 运行结果
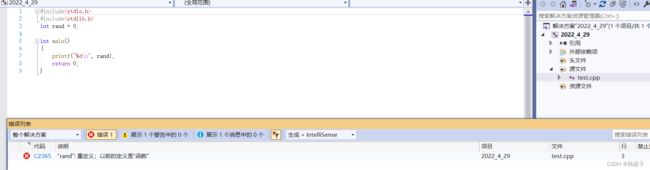
运行了一下结果就发现报错了,这就是C语言致命的问题名字冲突
就是头文件展开,#include
打个比喻,我写了个代码和我的同事的名字冲突了,C语言怎么解决呢?只能改名字了,这样子只能是治标不治本,所以说c语言是没有很好的解决这个问题的
但是c++引入了命名空间来解决命名冲突的问题(命名空间就是namespace这个关键字)
代码
#include
#include
namespace li//namespace后面跟什么都可以,这是自己命名的
{
int rand = 0;
}
int main()
{
printf("%d\n", rand);
return 0;
} 运行结果
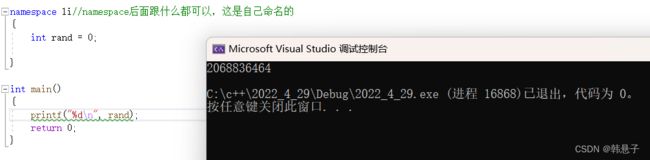
这样子就没有问题了,这里打印出来的一堆数字是函数的地址
那么这个函数是怎么解决这个问题的
相当于把rand关在里面,让它们隔离。
如果按这样写行不行?
代码
namespace li//namespace后面跟什么都可以,这是自己命名的
{
int rand = 0;
}
int f = 0;
void f()
{
}
int main()
{
printf("%d\n", rand);
return 0;
}运行结果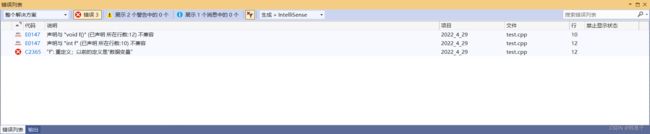
答案是不行的,因为它们在同一个作用域里面,但是把其中一个函数放入命名空间里面就可以
代码
#include
#include
namespace li//namespace后面跟什么都可以,这是自己命名的
{
int f = 0;
int rand = 0;
}
void f()
{
}
int main()
{
printf("%d\n", rand);
return 0;
} 运行结果
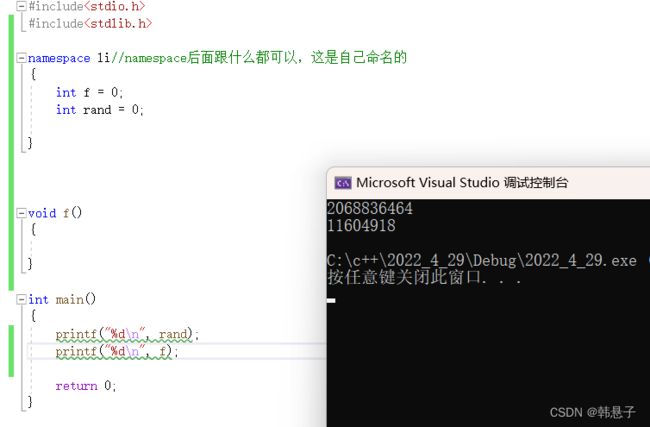
可以看到是没有问题的
总结:只要不在同一个作用域有相同的名字,就不会出现命名冲突问题,而namesapce这个关键字就是把函数的作用域给隔离开来。
那么来看下个问题
代码
#include
int x = 0;
int main()
{
int x = 1;
printf("%d\n", x);
return 0;
} 这样子会报错吗?
不会报错会打印谁?
运行结果
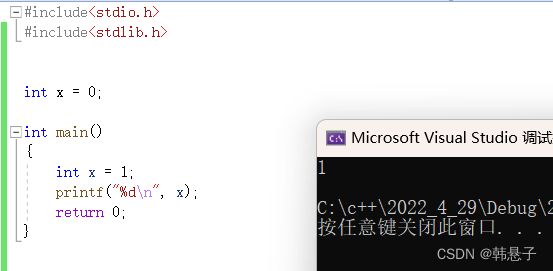
答案是不会报错,打印出来的是1,毕竟局部优先原理
那么要是我们想打印全局变量的x呢?
代码
int x = 0;
int main()
{
int x = 1;
printf("%d\n", ::x);//域作用符
return 0;
}打印结果
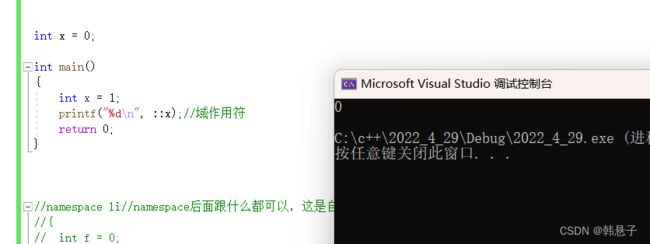
::代表访问全局的,::左边没有空格也是可以
那么要是想访问命名空间里面的呢?
代码
namespace li//namespace后面跟什么都可以,这是自己命名的
{
int f = 0;
int rand = 0;
}
void f()
{
}
int x = 0;
int main()
{
int x = 1;
printf("%d\n", ::x);
printf("%d\n", rand);
printf("%p\n",li::rand);
printf("%d\n", f);
printf("%p\n", li::f);
return 0;
}
打印结果
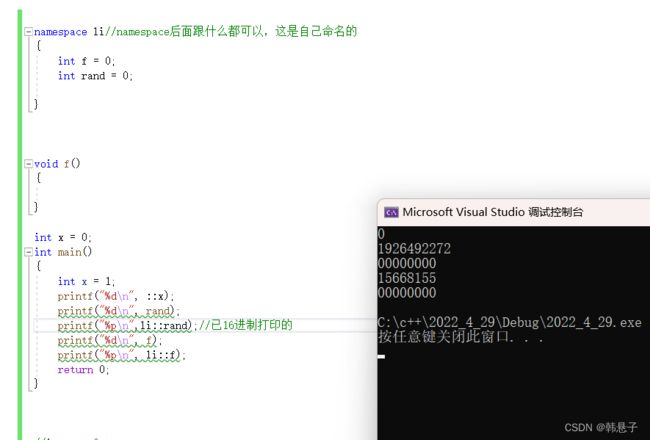
这里有二个头文件,它们命名空间都叫network,那么要怎么使用呢?
第一个头文件代码
#pragma once
namespace network
{
int a = 0;
namespace cache
{
struct Node
{
int val;
struct Node* next;
};
}
}第二个头文件代码
#pragma once
namespace network
{
int b = 0;
namespace data
{
struct Node
{
int val;
struct Node* next;
};
}
}主函数代码
#include
#include"list.h"
#include"queue.h"
int main()
{
//同名的命名空间是可以存在的,因为编译器编译时会合并
struct network::cache::Node n1;
n1.val = 10;
struct network::data::Node n2;
n2.val = 20;
return 0;
} 运行结果
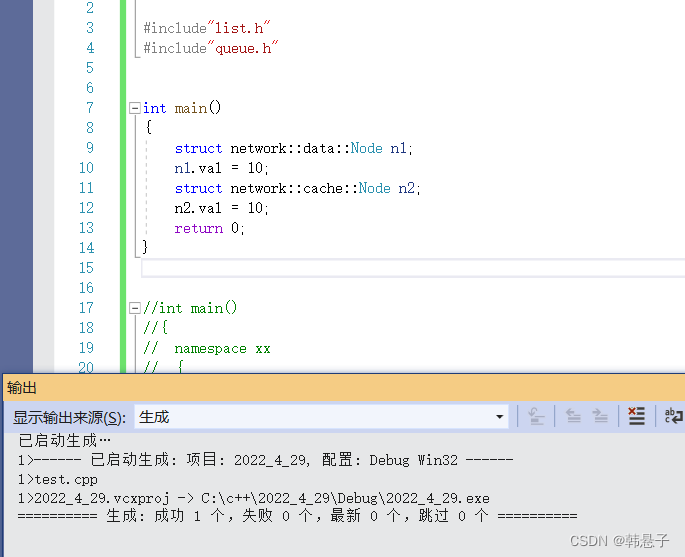
可以看到没有任何问题
还有一种情况
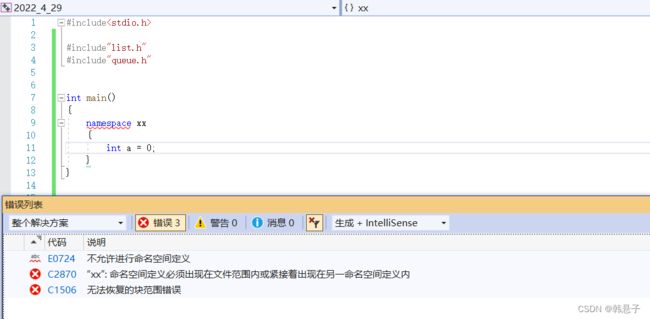
命名空间不能在局部定义
总结:
1.同名的名字空间是可以同时存在的,因为编译器编译时会合并
2.同名的命名空间可以嵌套(这个是怕命名空间里面又有同名)
3.命名空间不影响生命周期,比如第二个头文件的b就是全局变量
4.命名空间是不能放在局部里面的
但是像这样子使用就很麻烦
#include
#include"list.h"
#include"queue.h"
//这个意思是把network的这个命名空间定义的东西放出来
using namespace network;
int main()
{
struct data::Node n1;
n1.val = 10;
struct cache::Node n2;
n2.val = 10;
return 0;
} 当然也可以这样,再展开里面的data,这样子就不会打这么多代码
#include
#include"list.h"
#include"queue.h"
//这个意思是把network的这个命名空间定义的东西放出来
using namespace network;
using namespace data;
int main()
{
struct Node n1;
n1.val = 10;
struct cache::Node n2;
n2.val = 10;
return 0;
}
代码
#include
#include"list.h"
#include"queue.h"
//这个意思是把network的这个命名空间定义的东西放出来
using namespace network;
using namespace data;
using namespace cache;
int main()
{
struct Node n1;
n1.val = 10;
struct cache::Node n2;
n2.val = 10;
return 0;
} 这样子全展开的话,编译器就不知道是data的Node还时cache的Node会报错
代码
#include
#include"list.h"
#include"queue.h"
//这个意思是把network的这个命名空间定义的东西放出来
using namespace data;
using namespace network;
int main()
{
struct Node n1;
n1.val = 10;
struct cache::Node n2;
n2.val = 10;
return 0;
} 这样子会报错的,因为先展开data,编译器找不到data
代码
#include
#include"list.h"
#include"queue.h"
//这个意思是把network的这个命名空间定义的东西放出来
using namespace network::data;
int main()
{
struct Node n1;
n1.val = 10;
struct cache::Node n2;
n2.val = 10;
return 0;
} 这样子展开可以,但是struct cache::Node是不能用的,会报错
运行结果
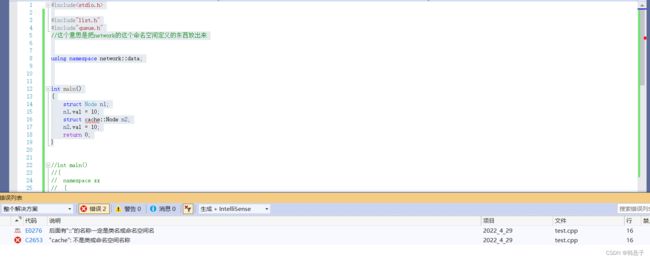
相信看过c++的代码的,都知道开头会加
#include
using namespace std; std是封c++库的命名空间
代码
#include
using namespace std;
int main()
{
cout << "hello world" << endl;
return 0;
} 运行结果

cout是c++里面的流插入运算符,edl相当与“\n”,那么为什么讲这个呢?
因为把using namespace std:给注释了就报错了,找不到该函数
运行结果
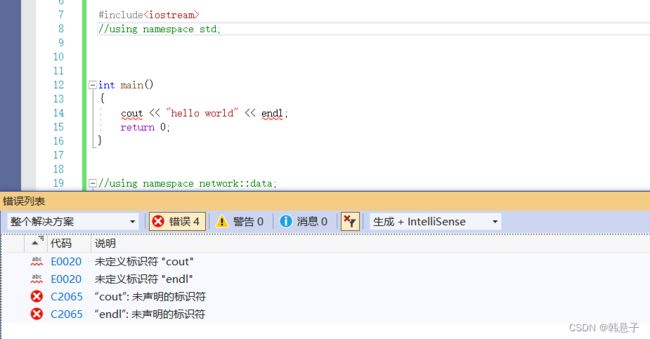
不过当然,如果把std的命名空间放出来的话,方便使用了,但是可能存在一些冲突
那么有什么办法解决呢?
运行结果

也可以只放namespace std::cout这个函数
总结::
放命名空间尽量放部分有用的,而不是全部放完,因为可能会有命名冲突,不过如果不是做项目,之类的,只是自己练习代码,全部展开问题也不大
现在我们来了解一下c++的输入输出
#include
using namespace std;
int main()
{
int i;
double d;
//流提取运算符
cin >> i >> d;
//流插入运算符
cout << i <<" " << d< 运行结果
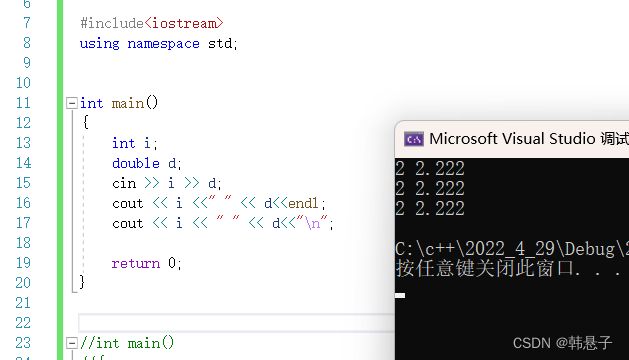
总结:
和c语言的输入输出来说,可能不用识别类型
2.缺省参数/默认参数
代码
#include
using namespace std;
//缺省参数
void TestFunc(int a = 0)
{
cout << a << endl;
}
int main()
{
TestFunc();
TestFunc(1);
return 0;
} 运行结果
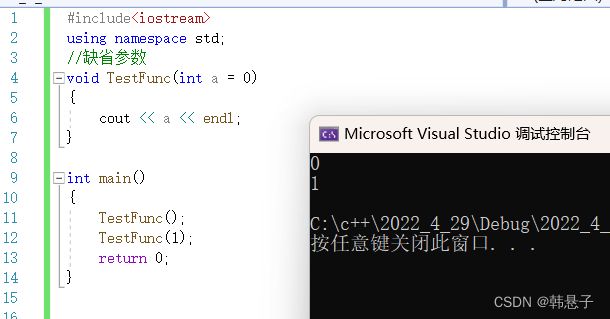
这个参数是有参数传进去就用传进去的参数,如果没有传参数就用,原本的参数
个人觉得这个叫备胎参数会更好
比如 喜羊羊不在沸羊羊就顶上,喜羊羊在了,美羊羊就对沸羊羊说你走吧,我不需要你了,喜羊羊不在就说我又需要你了
我们现在不用1个备胎我们用三个备胎会出现多少情况
代码
#include
using namespace std;
//缺省参数
void TestFunc(int a = 10,int b=20,int c=30)
{
cout <<"a=" << a << endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl< 运行结果

然后是不支持 TestFunc(,2,3);这样的,必须要传了第一个才能传第二个
上面那种叫全缺省,有全缺省就有半缺省
半缺省代码
#include
using namespace std;
//缺省参数
void TestFunc(int a ,int b=20,int c=30)
{
cout <<"a=" << a << endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl< 像这个,这个就必须的给一个值要不然会运行不了
像这种半缺省,我觉得用来初始化空间就很不错
代码
#include
using namespace std;
struct stack
{
int* a;
int size;
int capacity;
};
void StackInit(struct stack* ps, int n = 4)
{
assert(ps);
ps->a =(int*)malloc(sizeof(int)*n);
ps->size = 0;
ps->capacity = n;
}
int main()
{
stack st;
StackInit(&st);
return 0;
} 不给值就开四个空间,如果我知道要给多少值,那我就直接给多少值,多方便
总结:
1. 半缺省参数必须从右往左依次来给出,不能间隔着给
2. 缺省参数不能在函数声明和定义中同时出现(函数声明出现,定义不出现可以,声明不出现,定义出现不行,因为头文件是在上面先展开的,而定义是在链接的时候找定义的)
3. 缺省值必须是常量或者全局变量