docker 集群swarm搭建
docker 支持的集群部署有k8s和swarm,本次实现docker swarm搭建

0. 服务器
centos-7 虚拟机 6台,docker 环境

1.环境
开启4台虚拟机,重设其命令为如下,命令为
hostnamectl set-hostname swarm-manager-1
hostnamectl set-hostname swarm-worker-1
hostnamectl set-hostname swarm-worker-2
hostnamectl set-hostname swarm-worker-3
#重启
reboot
#查看
hostname 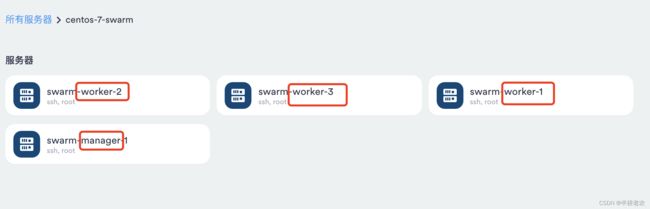 2.操作
2.操作
2.1将swarm-manager-1 声明为管理者
docker swarm init --advertise-addr 
2.2 关闭swarm-manager-1的防火墙
#不关闭其worker节点无法加入, ----让工人加入,至少门得给人家打开吧,合情合理
systemctl stop firewalld2.3 对worker-1,worker-2,worker-3执行命令,成为工人
注意:join后面的那一串是复制manager-1给出的命令
docker swarm join --token SWMTKN-1-2rsa1buh0jcx67zi776jfzd9zx5omkl6kjm0f1n4visz5ez8t4-bkh8wbubj2rs2b8tu7zsrtt3u 172.16.48.132:2377
在manager-1查看节点情况
docker node ls

如果,你只是想测试在多台服务器上跑docker 容器的集群,那么到这里集群的环境就结束了,这可比在同一台服务器上跑多个容器更具有真实性;
但是,如果是生产环境,怕是还不够;
我们现在的环境是,一个manager 管三个worker ,manager要是没了,谁分配任务,所以就有后续的,多个manager的做法,一个不行,怕宕机,那就再来几个。
3. 改进
增加两台虚拟机,一台叫swarm-manager-2 、一台为swarm-manager-3
修改其主机名,然后重启
注意:我们毕竟只是测试,如果电脑扛不住会卡顿,毕竟我们开了6台虚拟机了,可以把worker-1,worker-2 修改为manager,但是要先移除它的worker身份
在worker-1,worker-2 上执行命令为 docker swarm leave,然后再加入到manager ,加入方法同上

在manager-2,manager-3 执行如下操作


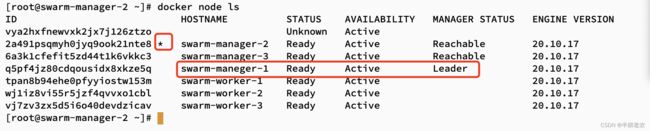
查看节点信息
注意,我是在swarm-manager-2上面查看的信息,标注" * "只是说当前在哪台机子上面,但是,leader还是manager-1,而manager-2,manager-3只是Reachble,可被发现的,也就是说,manager-1要是挂了,manager-2或者manager-3有一个会上位,但是manager-1 还活着,那就只能说是,机会等待者,等待上位。
3.1 测试宕机
如果把manager-1宕机了,会出现什么情况
对manager-1执行命令,poweroff
对manager-2执行 doker node ls ,发现,此时的节点leader为manager-3

这期间迟疑了大约3秒钟,那么 在执行这个命令的时候,是轮训选择一个leader吗,还是随机呢,在这几秒钟,是否有尝试重连的操作,或者说尝试连接manager-1的操作?
具体的可能就要去看docker采用的raft共识算法怎么实现了,动画做的还挺有意思的,可以去看看
官网:Raft
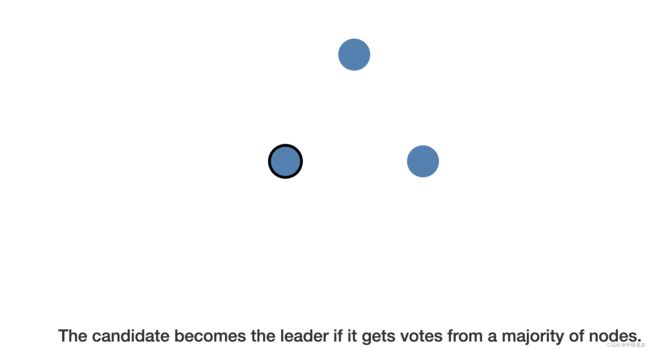
我以我的认知与大家分享它的大致实现流程 :
当有一个节点挂掉,另外的节点称为追随者,各自为其他节点投票,根据投票数多的节点获胜称为新一届的leader,并且在一段时间内,该leader要向其他节点发送心跳,如果该leader恰好在这个节点挂掉,那不好意思,重新选举,以此类推!!

此时,我们让manager-3也宕掉,然后在manager-2上查看
![]()
结果非常amazing,too few 译为,太少,请确保半数以上的managers是活的
就是说,如果你的manager团队里面,有N个,那你要确保(N-1)/2以上的manager要来上班,很好理解嘛,比如,我们是3个manager,它要求我们我们只能宕掉一个,好,假如现在只剩下两个,如果它还要可以继续工作,会出现什么情况,剩两个追随者,相互给对方投票,一人一票,然后谁都当不了leader。这也是很多技术像网络内部,集群等,涉及到是使用投票决策的继任,十分推荐节点个数为奇数个。
以上就是本次的集群swarm搭建的全部内容,后续有rabbitmq等集群服务的搭建。我们只是搭了个框架,具体能跑什么容器还需要进一步设计,静待佳音