背景描述
8.25上午10点55分左右,业务反馈测试环境容器平台无法访问,11点17分左右服务恢复,查询网关日志,发现容器服务出现大量504:
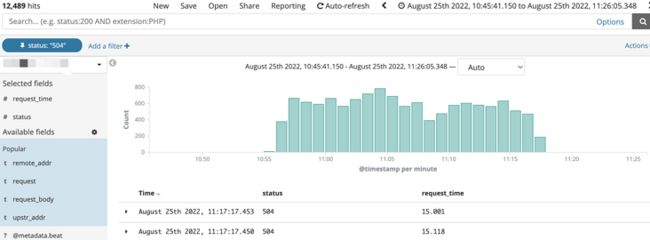
网关上游是容器集群ingress,ingress错误日志有什么线索吗?
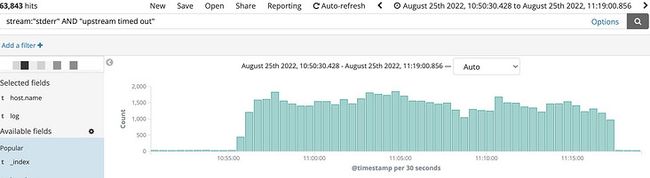
部分业务存在常态化超时情况,暂时排除再外不关注。分析域名发现,不止容器服务超时,还有其余几个服务存在超时现象,错误日志显示是在建立连接阶段就超时了("while connecting to upstream")。
为什么这些服务突然大量超时呢?难道是ingress异常了?
另外,同一时刻还发现直接在节点上执行kubectl命令响应也非常慢,apiserver服务为什么会这么慢呢?依赖的etcd或者自身异常了?容器平台也强依赖apiserver服务,是apiserver的慢导致的容器平台超时吗?那其他几个服务怎么解释呢?
初步排查
既然kubectl命令响应都非常慢,那先看看apiserver的监控以及日志吧。发现apiserver基本指标cpu、内存、网络等正常,一项指标非常符合:
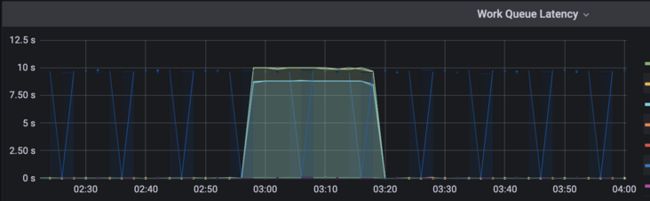
注意时区问题,横坐标时间点+8小时。
指标名称"Work Queue Latency",延迟?是这个问题吗?再看看apiserver的日志,发现竟然也存在大量的超时日志:
{"log":"E0825 10:56:05.015507 1 controller.go:114] loading OpenAPI spec for \"v1alpha1.proxies.clusternet.io\" failed with: failed to retrieve openAPI spec, http error: ResponseCode: 503, Body: Error trying to reach service: 'dial tcp 10.100.100.223:443: connect: connection timed out', Header: map[Content-Type:[text/plain; charset=utf-8] X-Content-Type-Options:[nosniff]]\n","stream":"stderr","time":"2022-08-25T02:56:05.015718744Z"}10.x.x.223这个节点是什么呢?貌似是一个serviceip,后端对应哪个服务呢?经查询发现是clusternet-hub,是这个服务导致的吗?
这里需要说明下,测试环境容器集群总共有3个master,10.x.x.21/10.x.x.22/10.x.x.23,而且监控显示的指标,以及错误日志,只存在22、23两个节点。为什么这两个节点有异常,21节点的apiserver却没有任何异常呢?
另外发现,clusternet-hub只有一个pod,就在10.x.x.21节点。服务依赖如下所示:
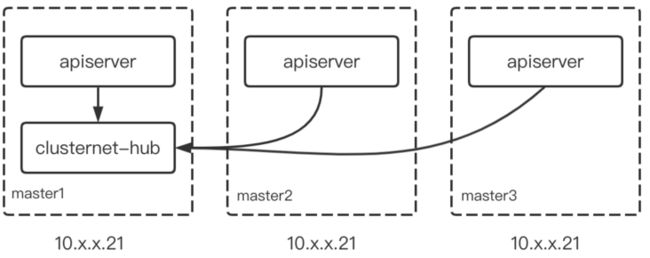
感觉特别像是10.x.x.21节点网络故障?这里网络伙伴不背锅,不要查不出来就说是网络原因。
再回顾下ingress的错误日志,统计所有服务的超时upstream_addr,发现这些pod都集中在两个节点。而且容器平台的服务也刚好在10.x.x.21节点,其他服务的超时都集中在10.x.x.55节点。此时整个链路是这样的:
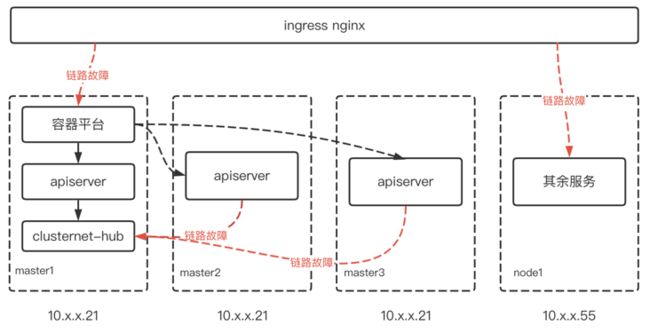
红色线条的访问,都出现了连接超时现象,难道真是这两个节点的网络出现故障了吗?
确定原因
这里需要说明下测试环境的网络架构,基于kube-router(ipvs + bgp路由)实现的,kube-router部署在每一个容器集群节点,ipvs实现service负载均衡,bgp路由实现pod跨节点通信。
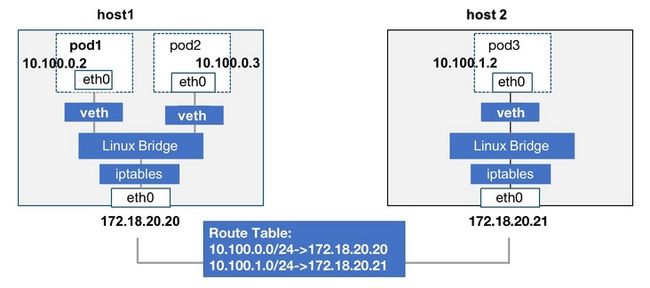
如上图所示,pod1访问pod3时,依赖kube-router在本节点生成的路由表。而如果kube-router异常之后,路由的缺失,将导致pod跨节点间的通信异常。
查看10.x.x.21节点部署的kube-router,发现pod在上午11点17分重新启动了(10.x.x.55同样):
State: Running
Started: Thu, 25 Aug 2022 11:16:51 +0800
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Thu, 25 Aug 2022 11:11:25 +0800
Finished: Thu, 25 Aug 2022 11:16:50 +0800再查看ingress节点上部署的kube-router日志,显示10点54分10.x.x.21节点Peer Down,11点17分10.x.x.21节点Peer Up(10.x.x.55节点类似)
time="2022-08-25T10:54:07+08:00" level=info msg="Peer Down" Key=10.90.31.21 Reason=graceful-restart State=BGP_FSM_ESTABLISHED Topic=Peer
time="2022-08-25T10:58:48+08:00" level=info msg="Peer Down" Key=10.90.31.55 Reason=graceful-restart State=BGP_FSM_ESTABLISHED Topic=Peer
time="2022-08-25T11:17:02+08:00" level=info msg="Peer Up" Key=10.90.31.55 State=BGP_FSM_OPENCONFIRM Topic=Peer
time="2022-08-25T11:17:13+08:00" level=info msg="Peer Up" Key=10.90.31.21 State=BGP_FSM_OPENCONFIRM Topic=Peer根据这些日志,基本可以确定,kube-router异常退出,导致10.x.x.21/10.x.x.55节点短时间内的不可达。这两个节点上的kube-router为什么异常重启呢?由于测试环境没有采集日志,之前的日志也已丢失,目前具体原因也不得而知。
其他超时
在分析这起case时,发现还有部分服务持续存在connect超时情况,并且比例较小,也就是持续性的偶现超时。又是网络问题吗?
在ingress节点与服务所在节点,同时开启tcpdump抓包,发现ingress节点正常发起SYN包,而且服务所在节点也正常收到了SYN包,但是却没有响应:
//目的节点抓包
21:30:59.071873 IP 10.100.100.26.31506 > 10.0.0.183.10086: Flags [S], seq 2272650563, win 29200, options [mss 1460,sackOK,TS val 3041591460 ecr 0,nop,wscale 9], length 0
21:31:00.073425 IP 10.100.100.26.31506 > 10.0.0.183.10086: Flags [S], seq 2272650563, win 29200, options [mss 1460,sackOK,TS val 3041592462 ecr 0,nop,wscale 9], length 0
21:31:02.075437 IP 10.100.100.26.31506 > 10.0.0.183.10086: Flags [S], seq 2272650563, win 29200, options [mss 1460,sackOK,TS val 3041594464 ecr 0,nop,wscale 9], length 0为什么没有响应该SYN包呢,这里估计大概率是tcp队列溢出了(半连接队列)。netstat查看socket的统计信息:
netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 101 0 0.0.0.0:10086 0.0.0.0:* LISTEN 1/java
tcp 0 0 10.0.0.183:10086 10.100.100.26:13138 SYN_RECV -
tcp 0 0 10.0.0.183:10086 10.100.100.26:14460 SYN_RECV -
tcp 0 0 10.0.0.183:10086 10.100.100.26:14354 SYN_RECV -
tcp 0 0 10.0.0.183:10086 10.100.100.26:13250 SYN_RECV -
tcp 0 0 10.0.0.183:10086 10.100.100.26:13476 SYN_RECV -可以看到监听的socket,Recv-Q持续性大于0,而且存在大量SYN_RECV状态的tcp连接。
LISTEN状态下的socket,Recv-Q表示当前队列中等待应用程序处理的连接请求数,大于0说明有tcp连接已经建立成功,但是应用程序却没有执行accept处理。
为什么存在大量SYN_RECV状态的tcp连接呢?说明服务端收到SYN包之后,已经向客户端返回了SYN+ACK包,在等待客户端ACK包。需要注意的是,当服务端tcp全连接队列溢出时,收到的客户端ACK也会直接丢弃,而该连接继续保持在SYN_RECV状态(没法进入ESTABLISHED状态)。
所以基本可以断定,服务端tcp半连接以及全连接队列溢出导致的连接超时情况。这种情况就需要服务端程序调整backlog大小了(listen函数的参数backlog,当然tcp队列大小不仅由backlog参数决定,还依赖内核参数)。
其实在某些情况下,tcp队列溢出后,服务端并不是丢弃这个包,还有可能返回RST,这时候客户端看到的错误就是"connection reset by peer"。这些行为也有内核参数决定。
总结反思
测试环境k8s集群网络架构基于kube-router实现,线上环境目前基于cilium + bgp实现,这些组件的底层原理还是需要研究,不然遇到网络故障怎么排查?
备注:k8s网络架构不是一篇文章能介绍清楚的,包括tcp协议全连接队列&半连接队列,这类知识往上文章很多,有兴趣的读者可以自己研究研究。
参考文献
- k8s网络基础:https://www.cnblogs.com/bakar...
- k8s网络架构:https://my.oschina.net/u/4471...
- kube-router:https://www.kube-router.io/docs/
- cilium:https://docs.cilium.io/en/sta...
- tcp队列:https://segmentfault.com/a/11...