Python 获取旅游景点信息及评论并作词云、数据可视化
正所谓:有朋自远方来,不亦乐乎?有朋友来找我们玩,是一件很快乐的事情,那么我们要尽地主之谊,好好带朋友去玩耍!那么问题来了,什么时候去哪里玩最好呢,哪里玩的地方最多呢?
今天将手把手教你使用线程池爬取同程旅行的景点信息及评论数据并做词云、数据可视化!!!带你了解各个城市的游玩景点信息。喜欢本文记得收藏、点赞、关注。
在开始爬取数据之前,我们首先来了解一下线程。
线程
进程:进程是代码在数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位。
线程:是轻量级的进程,是程序执行的最小单元,是进程的一个执行路径。
一个进程中至少有一个线程,进程中的多个线程共享进程的资源。
线程生命周期
在创建多线程之前,我们先来学习一下线程生命周期,如下图所示:
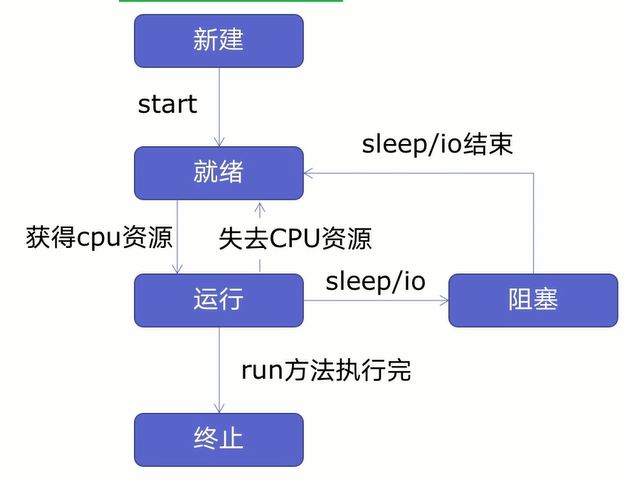
由图可知,线程可以分为五个状态——新建、就绪、运行、阻塞、终止。
首先新建一个线程并开启线程后线程进入就绪状态,就绪状态的线程不会马上运行,要获得CPU资源才会进入运行状态,在进入运行状态后,线程有可能会失去CPU资源或者遇到休眠、io操作(读写等操作)线程进入就绪状态或者阻塞状态,要等休眠、io操作结束或者重新获得CPU资源后,才会进入运行状态,等到运行完后进入终止状态。
注意:新建线程系统是需要分配资源的,终止线程系统是需要回收资源的,那么如何减去新建/终止线程的系统开销呢,这时我们可以创建线程池来重用线程,这样就可以减少系统的开销了。
在创建线程池之前,我们先来学习如何创建多线程。
创建多线程
创建多线程可以分为四步:
-
创建函数;
-
创建线程;
-
启动线程;
-
等待结束;
创建函数
为了方便演示,我们拿博客园的网页做爬虫函数,具体代码如下所示:
import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))
首先导入requests网络请求库,把我们所有的要爬取的URL保存在列表中,然后自定义函数get_parse来发送网络请求、打印请求的URL和响应的字符长度。
创建线程
在上一步我们创建了爬虫函数,接下来将创建线程了,具体代码如下所示:
import threading
#多线程
def multi_thread():
threads=[]
for url in urls:
threads.append(
threading.Thread(target=get_parse,args=(url,))
)
首先我们导入threading模块,自定义multi_thread函数,再创建一个空列表threads来存放线程任务,通过threading.Thread()方法来创建线程。其中:
-
target为运行函数;
-
args为运行函数所需的参数。
注意args中的参数要以元组的方式传入,然后通过.append()方法把线程添加到threads空列表中。
启动线程
线程已经创建好了,接下来将启动线程了,启动线程很简单,具体代码如下所示:
for thread in threads:
thread.start()
首先我们通过for循环把threads列表中的线程任务获取下来,通过.start()来启动线程。
等待结束
启动线程后,接下来将等待线程结束,具体代码如下所示:
for thread in threads:
thread.join()
和启动线程一样,先通过for循环把threads列表中的线程任务获取下来,再使用.join()方法等待线程结束。
多线程已经创建好了,接下来将测试一下多线程的速度如何,具体代码如下所示:
if __name__ == '__main__':
t1=time.time()
multi_thread()
t2=time.time()
print(t2-t1)
运行结果如下图所示:

多线程爬取50个博客园网页只要1秒多,而且多线程的发送网络请求的URL是随机的。
我们来测试一下单线程的运行时间,具体代码如下所示:
if __name__ == '__main__':
t1=time.time()
for i in urls:
get_parse(i)
t2=time.time()
print(t2-t1)
运行结果如下图所示:
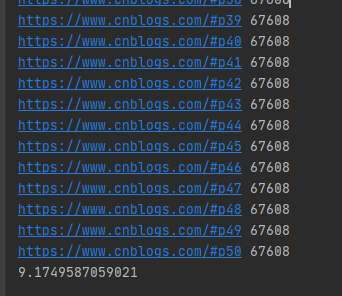
单线程爬取50个博客园网页用了9秒多,单线程的发送网络请求的URL是按顺序的。
在上面我们说了,新建线程系统是需要分配资源的,终止线程系统是需要回收资源的,为了减少系统的开销,我们可以创建线程池。
线程池原理
一个线程池由两部分组成,如下图所示:
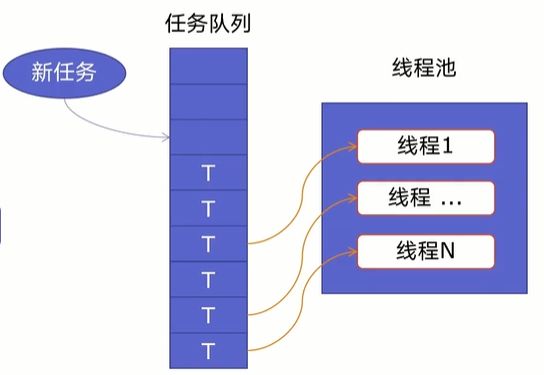
-
线程池:里面提前建好N个线程,这些都会被重复利用;
-
任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
-
max_workers:最大线程数;
-
thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
-
initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
-
initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requests
import concurrent.futures
import time
urls=[ f'https://www.cnblogs.com/#p{page}' for page in range(1,50)]
def get_parse(url):
response=requests.get(url)
return response.text
def map_pool():
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool: htmls=pool.map(get_parse,urls)
htmls=list(zip(urls,htmls))
for url,html in htmls:
print(url,len(html))
if __name__ == '__main__':
t1=time.time()
map_pool()
t2=time.time()
print(t2-t1)
首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
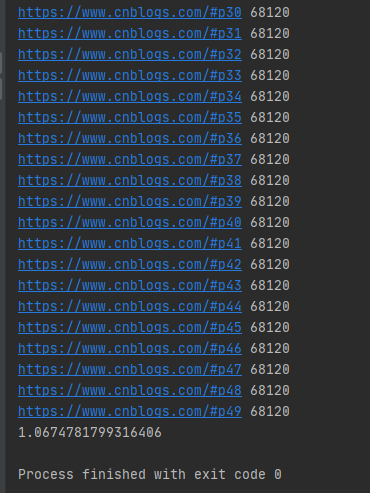
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():
with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:
futuress=[pool.submit(get_parse,url)for url in urls]
futures=zip(urls,futuress)
for url,future in futures:
print(url,len(future.result()))
运行结果如下图所示:
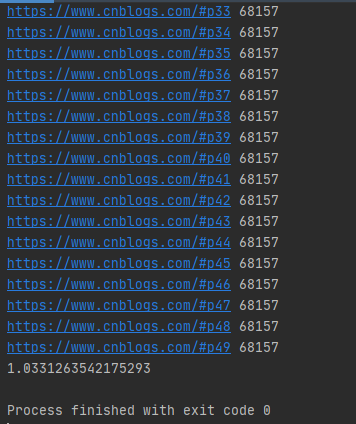
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
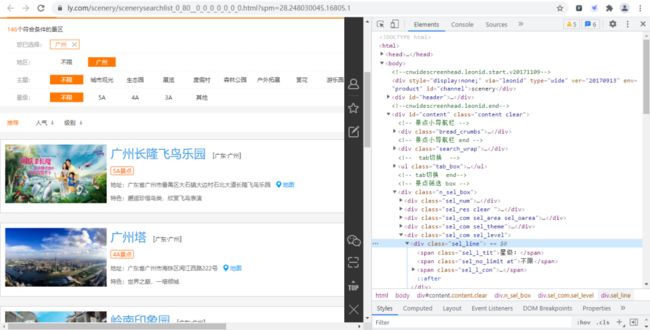
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
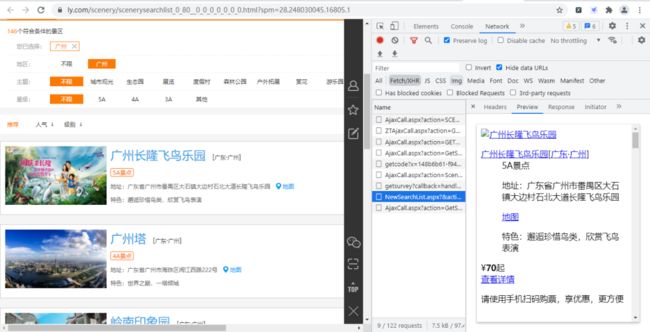
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
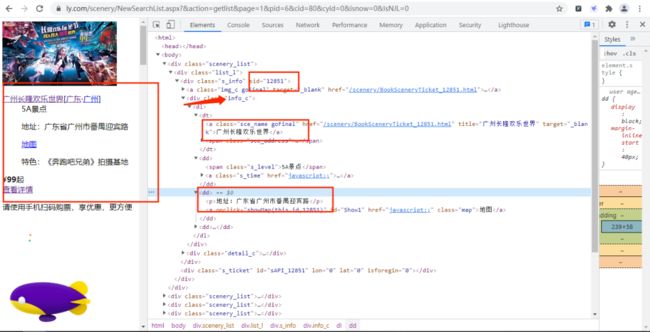
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
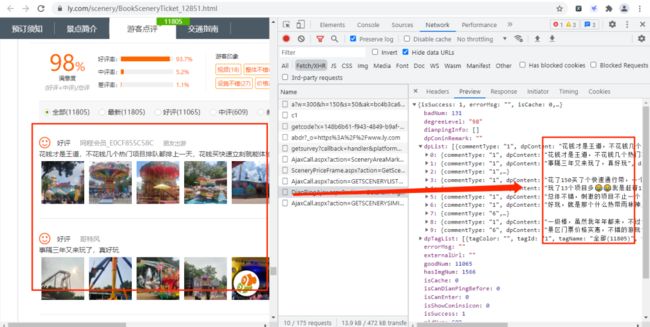
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
-
获取景点基本信息
-
获取评论数据
-
创建MySQL数据库
-
保存数据
-
创建线程池
-
数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url): response=requests.get(url,headers=headers) Xpath=parsel.Selector(response.text) data=Xpath.xpath('/html/body/div') for i in data: Scenery_data={ 'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(), 'sid':i.xpath('//div[@class="list_l"]/div/@sid').extract_first(), 'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''), 'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(), 'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(), 'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8] }
首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):
for i in range(1,3):
link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832' response=requests.get(link,headers=headers)
Json=response.json()
commtent_detailed=Json.get('dpList') # 有评论数据
if commtent_detailed!=None:
for i in commtent_detailed:
Comment_information={'dptitle':Scenery_data['title'], 'dpContent':i.get('dpContent'), 'dpDate':i.get('dpDate')[5:7], 'lineAccess':i.get('lineAccess') } #没有评论数据 elif commtent_detailed==None: Comment_information={ 'dptitle':Scenery_data['title'], 'dpContent':'没有评论', 'dpDate':'没有评论', 'lineAccess':'没有评论' }
首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库
def create_db():
db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)
cursor=db.cursor()
sql='create database if not exists commtent default character set utf8'
cursor.execute(sql)
db.close()
create_table()#创建景点信息数据表def create_table(): db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')
cursor=db.cursor()
sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)' cursor.execute(sql) db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
#保存景点数据到景点数据表中
def saving_scenery_data(srr):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')
cursor = db.cursor()
sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)' try: cursor.execute(sql, srr)
db.commit() except:
db.rollback() db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [ f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'
for i in range(1, 6)]
def multi_thread():
with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:
h=pool.map(get_parse,urls)
if __name__ == '__main__':
create_db()
multi_thread()
创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
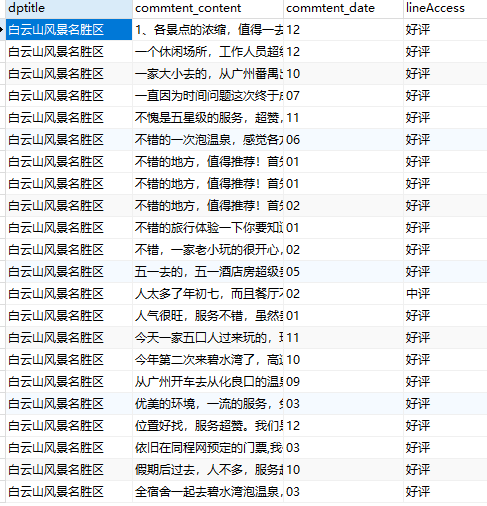
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
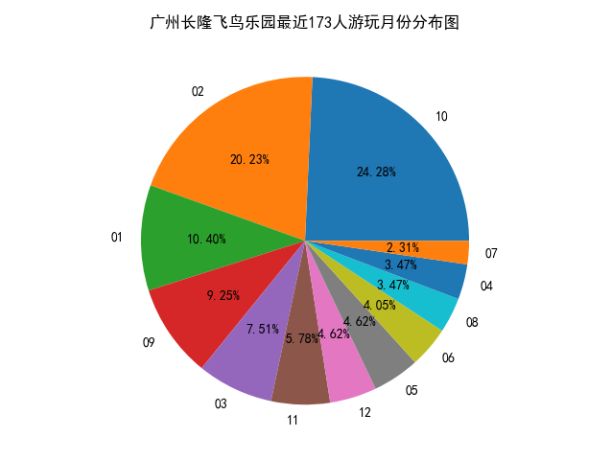
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
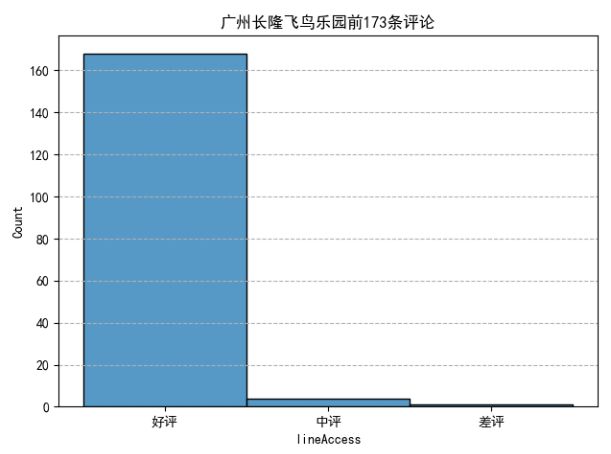
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
我们的文章到此就结束啦,原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
推荐文章
-
李宏毅《机器学习》国语课程(2022)来了
-
有人把吴恩达老师的机器学习和深度学习做成了中文版
-
上瘾了,最近又给公司撸了一个可视化大屏(附源码)
-
如此优雅,4款 Python 自动数据分析神器真香啊
-
梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
-
年终汇总:20份可视化大屏模板,直接套用真香(文末附源码)