前言
最近公司准备接入ShardingJdbc做读写分离了,老大让我们理一理有没有写完数据立马读的场景,因为主从同步是有延迟的,如果写完读取数据走到从库,而从库正好有延迟,没读取到数据,岂不是造成了生产事故。
今天我们来看看,ShardingJdbc作为一个成熟的框架是怎么处理写完数据立即读取的场景的。
数据库介绍
我本地使用了两个库来做实验,写库(ds_0_master)和读库(ds_0_salve),两个库并没有配置主从,但也不影响实验操作。
库里有一个city 表。主库的 city 表没有数据,而从库的 city 表就一条数据。数据内容如下:

我们讨论 4 种业务场景:
- 常规写完读
- 在一个 service 里面调用另一个 service2 进行读
- 在一个 service 里面新开一个线程去调用 service2
- 在一个 service 里面调用 service2,但 service2 是新开的事务
先直接上实验结果:
1. 常规写完读
@Service
public class CityService {
@Autowired
private CityRepository cityRepository;
@Autowired
private CityService2 cityService2;
@Transactional(rollbackFor = Exception.class)
public void test(){
City city=new City();
city.setName("眉山");
city.setProvince("四川");
cityRepository.save(city);
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.out.println("cityService:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
打印结果:
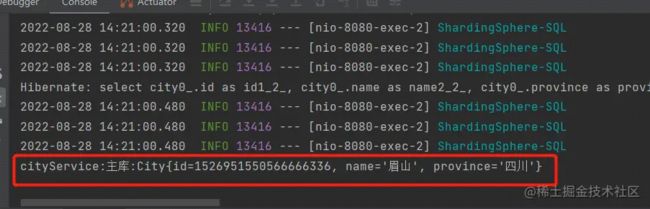
实验分析: 我们对 city 表进行插入后,紧接着对 city 表进行了查询,查出的内容是我们刚刚插入的内容。说明查询操作没有走读库,而是走了主库。
2. 在一个 service 里面调用另一个 service
代码如下:
@Transactional(rollbackFor = Exception.class)
public void test(){
City city=new City();
city.setName("眉山");
city.setProvince("四川");
cityRepository.save(city);
//调用其他service
cityService2.test();
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.out.println("cityService:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
service2 的代码:
public void test(){
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
打印结果:
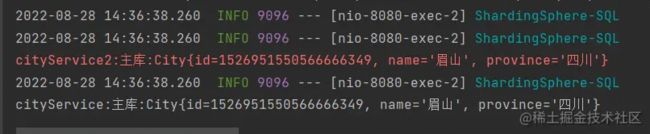
实验分析:在 service 方法里调用了其他 service,其他 service 也会受到影响。service2 也是走的主库。
3. 新开一个线程去调用 service2
代码如下:
@Service
public class CityService {
@Autowired
private CityRepository cityRepository;
@Autowired
private CityService2 cityService2;
@Transactional(rollbackFor = Exception.class)
public void test(){
City city=new City();
city.setName("眉山");
city.setProvince("四川");
cityRepository.save(city);
new Thread(()->{cityService2.test();}).start();
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.out.println("cityService:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
@Service
public class CityService2 {
@Autowired
private CityRepository cityRepository;
public void test(){
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
打印结果:
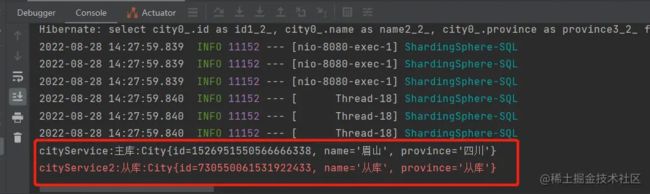
实验分析: 我们新开了线程对 city 表进行查询,此次查询读的是从库。新开的线程会走从库,我猜想是新开的线程它认为是没有写入/修改操作,所以走了从库。
我又改动了 service2,加了一段写入操作。代码如下:
public void test(){
City city=new City();
city.setName("成都");
city.setProvince("四川");
cityRepository.save(city);
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
再次执行,结果如下:

和预想的不一样,依旧是走的从库。
4. service2 新开一个事务执行
我们调整 service2 的事务传播行为级别。代码如下:
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void test(){
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
REQUIRES_NEW 的含义是:
强制自己开启一个新的事务,如果一个事务已经存在,那么将这个事务挂起.如 ServiceA.methodA()调用 ServiceB.methodB(),methodB()上的传播级别是 PROPAGATION_REQUIRES_NEW 的话,那么如果 methodA 报错,不影响 methodB 的事务,如果 methodB 报错,那么 methodA 是可以选择是回滚或者提交的,就看你是否将 methodB 报的错误抛出还是 try catch 了.
打印结果:
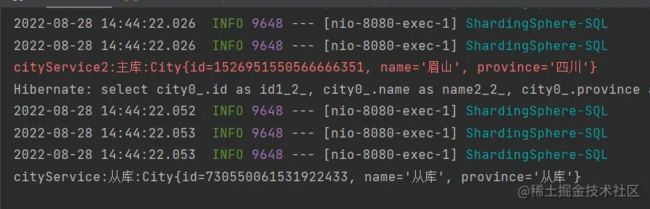
实验分析: 这个结果确实是没想到,service2 新开了个事务走的是主库,而 service 里面的同一个事务里的写后读,反而走了从库。
实验总结:
| 场景 | service | service2 |
|---|---|---|
| 同一个 service 里写完读 | 主库 | 主库 |
| service 里写完调用另一个 servcie 进行读操作 | 主库 | 主库 |
| service 里写完新开线程调用另一个 servcie 进行读操作 | 主库 | 从库 |
| service 里写完新开一个事务调用另一个 servcie 进行读操作 | 从库 | 主库 |
常规的写完读操作和写完在另一个 service 里进行读操作,都能够走到主库,保证了常规业务的正确性,也满足了我们一般的使用场景了。而新开线程进行读操作的情况其实比较少,如果非要使用,我们可以用强制指定主库的方式进行处理。
最后一种情况,service中调用另一个service2(新开事务),原本 service 里同一个事务的写完读操作走到了从库,一不注意容易引起实际业务bug,需要使用者谨慎使用。大家觉得这是不是ShardingJdbc的一个BUG呢?
以上就是ShardingJdbc读写分离的BUG踩坑解决的详细内容,更多关于ShardingJdbc读写分离BUG的资料请关注脚本之家其它相关文章!