Tiramisu:一种基于Polyheral的深度学习模型编译器
1. 推理引擎编译模型的一般过程
业界主流的深度学习推理引擎,如TensorRT、Tensorflow Lite、TVM等,均由两个主要组件构成:模型编译器和推理运行时,前者负责将模型编译为可运行于目标设备的IR/代码,后者则负责在目标设备上导入编译后的IR/代码并执行推理过程。很明显,模型编译器是否能生成合理运用设备资源的代码,是保证模型推理性能的关键。模型编译器编译模型的一般过程,就是将模型由高级表示,转换为一系列中间表示(IR)的过程。如下图,以TVM为例,这个过程是:原始模型->Relay IR(图级别IR)-> Tensor IR(算子级别IR)-> Runtime IR(运行时IR)。

TVM框架模型编译过程
其中,由Relay IR转化为Tensor IR的步骤称为“调度生成”,对于TVM以外的推理引擎,该步骤的名称可能有差异,但都是必须的。调度的关键在于从时间、空间两个维度上彻底挖掘计算资源的极限潜能:
时间维度上,任意时刻应尽可能地并行化数据无依赖关系的计算(CPU多物理核、GPU流处理器、CPU/GPU高级指令集),以避免不必要的串行计算
空间维度上,尽可能将计算所需的数据放置于存取速度最快的区域(CPU L1 Cache、GPU L1 Cache、GPU C-Cache、GPU共享内存等),减少数据读写时间
综上可知,推理引擎的核心在于模型编译器,模型编译器的核心在于调度过程的生成技术。
2. 调度生成技术的分类
调度过程是否合理直接决定了CodeGen生成的运行时代码的执行效率,目前业界的调度编译技术可以归纳到下表的四个象限中:
调度生成技术分类| 调度自动生成 | 调度非自动生成 | |
|---|---|---|
| 依赖分析 | PolyMage, Tensor, Comprehensions | AlphaZ,CHiLL,URUK,Tiramisu |
| 区间分析 | AutoScheduler(TVM) | Halide,AutoTVM |
如上表,编译技术根据循环嵌套分析算法的不同可以分为基于依赖分析和基于区间分析的两大类:依赖分析也即传统编译器的应用仿射变换优化循环嵌套代码的多面体分析技术,由于深度学习模型的算子在推理阶段的循环控制流是静态可判定的,因此非常适合应用该技术优化计算过程;相比依赖分析,区间分析针对图像处理领域的常用计算(针对图像矩阵的卷积、池化操作)简化了循环计算过程为循环轴对齐,即简化依赖分析的多面体抽象为长方体抽象,以牺牲一定的资源利用为代价简化常用算子的编译过程。
 两者相比,基于依赖分析的Polyhedral模型的调度描述更加细化、表达力更强,理论上可以将优化做到极致,但缺点是算法原理相对复杂且优化分析的复杂度更高;而基于区间分析的调度模型的优势在于,其在图像处理领域的优化效果和前者相差无几,但优化分析的复杂度低很多,缺点则是对于图像处理领域外的代码调度表达力不足,难以优化运行代码到极致性能。
两者相比,基于依赖分析的Polyhedral模型的调度描述更加细化、表达力更强,理论上可以将优化做到极致,但缺点是算法原理相对复杂且优化分析的复杂度更高;而基于区间分析的调度模型的优势在于,其在图像处理领域的优化效果和前者相差无几,但优化分析的复杂度低很多,缺点则是对于图像处理领域外的代码调度表达力不足,难以优化运行代码到极致性能。

另一种分类方式是调度生成的自动化程度,非自动化生成调度的编译器通常会向用户提供一种领域特定语言(DSL),如TVM的Tensor Expression、Tiramisu的Tiramisu Language,用户使用DSL语言描述由算子的计算到具体调度的转化过程;而自动化生成调度的编译器则会内置一套或多套编译准则,这套准则根据用户定义的计算过程描述以及设备性能描述自动生成最优的调度过程。
两类方法相比,非自动化的方法需要用户对目标设备的体系结构有足够理解并提供调度生成模板(AutoTVM)或具体调度过程(Tiramisu),用户在自定义的模板/过程上可以调整调度参数以优化调度过程;而自动化的方法则是对编译准则的设计者在计算机体系结构、代码编译原理方面提出了很高的要求,以确保设计的编译准则可以根据给定算子以及运行设备信息生成高效的调度过程。
根据以上对比可知,“四象限表”列出的所有调度生成技术并不存在绝对的优劣之分,每一种技术都是根据自身需求在通用性/特定领域性能两个维度上做取舍。本文即将介绍的Tiramisu可以归类于“基于依赖分析的调度非自动化生成”中。
3. Tiramisu DSL
Tiramisu定义了一套领域专用语言(DSL),该语言以C++为基础,提供了一套API供用户调用。用户可基于Tiramisu DSL APIs定义循环优化、内存布局等转化规则以指导算子调度的生成过程,Tiramisu Compiler进而根据用户定义的规则将原始深度学习模型的所有算子转化为低级别IR,并最终生成运行于设备后端的优化代码。理解Tiramisu DSL的一个高效方法是了解其定义的数据结构和算法,下图展示了Tiramisu转化代码为设备代码的全过程。
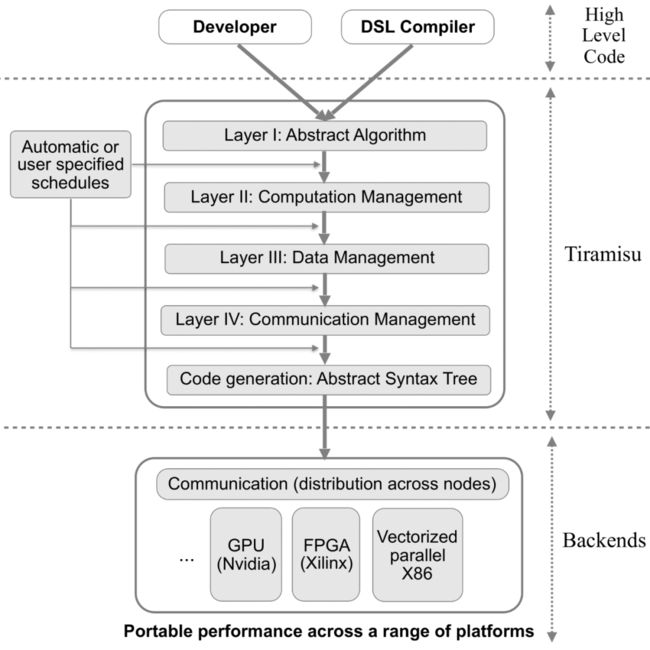
3.1 Tiramisu DSL——算法篇
Tiramisu定义的算法更准确的称呼是调度命令,用于描述数据排布如何设置、多层循环如何做仿射变换、设备计算资源如何利用等信息。Tiramisu共定义了4种类型的调度命令:
循环嵌套变换命令:这一类型的调度命令包括常见的仿射变换,如循环展开、分割、移位等。
循环-硬件关联命令:该类型的调度命令包括循环并行、向量化以及绑定循环到指定计算资源的操作等。
数据操作命令:数据操作命令可以分为4种类型:(1) 分配Tensor空间命令 (2) 设置Tensor属性命令,如设置数据存储位置(host/device/shared) (3)数据拷贝命令 (4) 设置数据存取属性命令。如表所示,数据操作命令也有高级和低级之分,通常用户使用高级命令即可完成一般的调度规划,更细致的规划则需要低级命令参与
数据同步操作命令:Tiramisu相比其他Compiler比较有特色的命令,类似于MapReduce的思路。设计者考虑到一次计算的数据量非常大的情况下可能需要多节点共同计算,因此设计了send/recv的调度操作,籍此可以在多节点之间共享数据或数据片段。
以blur算法为例,原始的blur算法计算定义如下:

与之等价的计算过程为:

接下来可以应用Tiramisu定义的调度命令优化blur算法的计算过程,如下图(a)所示,tile()命令将by计算作了循环展开操作;同时compute_at()命令在j0循环开始的地方计算了bx,供后续by的计算过程调用;parallelize()命令在i0循环处并行计算i0对应的循环体(即i0循环对应的代码块)。

同样的blur算法,在GPU上优化的方式则大不相同,如上图(b):首先,tile_gpu()命令展开by循环的计算并映射展开后的循环到GPU block上;compute_at()命令和(a)的功能相当;cache_shared_at()表示将bx的计算结果保存于共享内存中;store_in()指定了bx和by的入口函数,本例中表示bx和by的计算结果以SOA格式存储;最后的device_to_host_copy明显是计算后的结果拷贝(GPU到内存)。上图(c)考虑blur算法运行在分布式系统上,假设数组in[][][]在分布式系统中的所有节点上都已初始化,每个节点n根据数组in的一个chunk执行各自的计算任务,再用send()和recv()命令在节点间同步计算结果。
3.2 Tiramisu DSL——数据结构篇
数据结构方面Tiramisu定义了4层中间表示,分层式设计的目的在于解耦循环嵌套、内存排布以及分布式计算通信三类优化操作,以简化调度命令的设计过程。第一层IR用producer-consumer关系描述原始算法的计算过程(不考虑内存分配);第二层IR指定算法涉及的所有子计算的执行顺序;第三层IR指定数据在被调用之前应当以何种布局被放置于哪里;第四层IR(可选)指定在分布式系统中各节点协同计算的方式。
理解基于多面体模型(Polyheral)优化过程以及后文的IR定义需要掌握两个基本概念:整数集合与映射。在Polyhedral模型中,整数集合代表的是迭代域,映射用于表示内存访问并转换迭代域和内存访问(应用循环嵌套和内存访问转换)。例如,以下的整数元组集合描述了一个两重循环:
正式的表示中不会列出所有的元组,而是用以下符号表示:
映射表示的是两个整数集合的关系,如下表示的是S1到S2的映射
多级IR详解
第一层IR(抽象算法层)
本层的计算过程仅以producer-consumer关系表示,不定义计算顺序、数据存储等调度属性。仍以blur算法为例,第一层IR表示by的计算过程为:
冒号前的部分指定了by计算过程的迭代域,冒号后面的部分则是具体的计算表达式。Tiramisu在第一层IR中仅声明所有的计算过程,并不指定计算顺序。
第二层IR(计算管理层)
第二层IR将指定计算顺序以及具体计算过程使用的处理单元,但不指定中间的计算结果的内存排布方式。以图x-(b)为例,经过调度命令的处理,by的计算过程对应的第二层IR可表示为:
第二层IR中所有计算过程以词典顺序排列,上例中冒号前的集合是一组有序的计算。i0和j0上的标签gpuB表示迭代(i0, j0)映射到(i0, j0)GPU block下。在第二层IR,这些元组的顺序决定了计算的执行顺序。
计算在第二层IR上除了被排序以外,还会以打标签的方式被分配到特定的处理器上,目前Tiramisu支持的处理器标签包括CPU/node/gpuT/gpuB。Tiramisu编译器中,第二层IR由第一层IR自动生成。
第三层IR
第三层IR具体化了运算过程所有的临时变量的存放位置以及缓存的内存分配/释放的过程。和上一层相同,第三层IR也是由第二层IR自动生成的。在图x-(b)中,使用调度命令store_in()表示by(i, j, c)的计算结果将存储于数组by[c, i, j]中。该命令将生成以下映射:
第四层IR
第四层IR加入了同步和通信调度,这一设计在深度学习模型/算子编译过程几乎没有应用场景。和前两层相同,本层IR也是由第三层IR自动生成。
和所有的编译器一样,Tiramisu的第四层IR也需要借助CodeGen生成设备相关的机器码。实际操作时,Tiramisu首先将第四层IR转化为一棵抽象语法树(AST),再根据目标设备选择不同的CodeGen(CPU/GPU)。以CPU CodeGen为例,作者在这里偷了个懒——将AST先转为Halide IR,再用Halide定义的CodeGen将Hadide IR转为LLVM IR。需要强调的是,Tiramisu在此处仅仅将Hadlide作为CodeGen的库使用,并没有用到其任何上层的IR优化功能。
4. 结果与总结
Tiramisu在两组基准测试上做了评估:第一组是深度学习和线性代数领域的测试,第二组是图像处理领域的测试。测试环境的计算单元包括CPU和GPU,CPU环境为双路CPU,每一路为24物理核的Intel Xeon E5-2680v3,配套128G内存;GPU环境为Tesla K40。
深度学习和线性代数基准测试
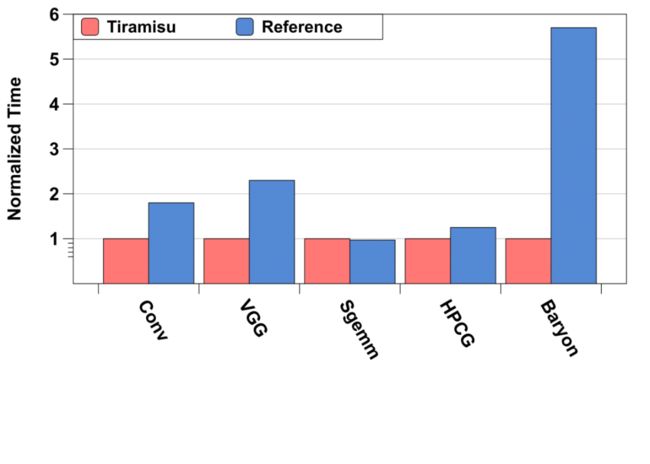 上图展示了本组基准测试的结果,测试项目包括Conv(神经网络卷积层实现)、VGG(VGG网络的一个block)、Sgemm(实现卷积的矩阵乘法)、HPCG(多重网格预处理共轭梯度)、Baryon(用于构造Baryon Block的密集张量压缩代码)。其中,Conv/VGG/Sgemm的对标基准为MKL-DNN 测试结果显示,TIRAMISU的Conv实现优于Intel MKL,原因是TIRAMISU可以针对不同大小的常用卷积核(3×3、5×5、7×7、9×9和11×11)生成专用版本的调度,与之对应的MKL-DNN并没有对应的手工优化实现。在VGG测试中,TIRAMISU获得了2.3倍于Intel MKL的加速效果。原因包括亮点:首先,将VGG块的两个卷积循环融合在一起以改善了数据局部性;其次,和Conv优化类似,Tiramisu也根据VGG Block中的卷积核的大小生成特定优化的代码。
上图展示了本组基准测试的结果,测试项目包括Conv(神经网络卷积层实现)、VGG(VGG网络的一个block)、Sgemm(实现卷积的矩阵乘法)、HPCG(多重网格预处理共轭梯度)、Baryon(用于构造Baryon Block的密集张量压缩代码)。其中,Conv/VGG/Sgemm的对标基准为MKL-DNN 测试结果显示,TIRAMISU的Conv实现优于Intel MKL,原因是TIRAMISU可以针对不同大小的常用卷积核(3×3、5×5、7×7、9×9和11×11)生成专用版本的调度,与之对应的MKL-DNN并没有对应的手工优化实现。在VGG测试中,TIRAMISU获得了2.3倍于Intel MKL的加速效果。原因包括亮点:首先,将VGG块的两个卷积循环融合在一起以改善了数据局部性;其次,和Conv优化类似,Tiramisu也根据VGG Block中的卷积核的大小生成特定优化的代码。
Sgemm测试项目下,TIRAMISU的表现与Intel MKL的手工实现性能相当。Tiramisu的优化包括三维sgemm循环的两级blocking,矢量化,循环展开,数组打包,寄存器阻塞以及全部和部分图块的分离等。
图像处理基准测试

图像处理领域的基准测试项目包括:edgeDetector(基于ring平滑的边缘检测模型)、cvtColor(图像灰度化)、conv2D(二维卷积)、warpAffine(图像仿射变形)、gaussian(高斯平滑)、nb(计算负图像和增亮图像)、ticket#2373( a code snippet from a bug filed against Halide)。该项测试Tiramisu的对标基准为Halide和PENCIL,测试环境为CPU和GPU。
1)CPU测试结果 在cvtColor、Conv2D、warpAffine以及gaussian四个测试项目上,Tiramisu的自动调度和Halide专家手写的调度效率相当;由于Halide是一种无法描述有环图且基于区间分析的语言,因此edgeDetector和ticket#2373无法在Halide上实现,但基于Polyheral的Tiramisu可以轻松优化;nb算法测试中,Tiramisu优化的代码运行速度是Halide的3.77倍,原因在于Tiramisu的自动循环融合——同等条件下,Halide的保守代码假设无法保证循环融合的正确性,而Tiramisu的依赖分析却可以做到。
和Tiramisu同样使用Polyhedral模型的PENCIL,在几乎所有的测试项中被大幅超越,原因主要在于这些测试项目偏重于深度学习和线性代数领域,Tiramisu应用了不少该领域的最佳调度方案,而PENCIL兼顾的场景更多,其应用的Pluto算法在循环连续性和数据局部性之间取了个折衷点,故而在需要强数据局部性的场景下表现远不及Tiramisu。2)GPU测试结果 GPU环境下,Tiramisu在conv2D和gaussian测试项的表现优于Halide,原因是Tiramisu使用常量内存来保存模型权重,而Halide PTX后端并不支持;nb测试项的差距和CPU一样,仍然源自Halide无法实现自动循环融合。PENCEL在GPU环境下仅conv2D和gaussian项和Tiramisu相比存在差距,原因在于PENCIL在CUDA环境下会生成复杂的控制流调度,影响运算效率。
4.3 总结
Tiramisu是一种4层IR结构的,基于Polyhedral模型的编译器,相比基于区间分析的Halide具有更好的领域适用性。在深度学习模型、算子仍在持续演进发展的未来,类似Tiramisu这样的模型编译器必将成为推理引擎从业者的趁手利器。