Redis分布式事务锁的原理(上)
我们在单机服务器,出现资源的竞争,一般使用synchronized 就可以解决,但是在分布式的服务器上,synchronized 就无法解决这个问题,这就需要一个分布式事务锁。
除此之外面试,基本会问springboot、Redis,然后都会一路再聊到分布式事务、分布式事务锁的实现。
1、常见的分布式事务锁
1、数据库级别的锁
- 乐观锁,基于加入版本号实现
- 悲观锁,基于数据库的 for update 实现
2、Redis ,基于 SETNX、EXPIRE 实现
3、Zookeeper,基于InterProcessMutex 实现
4、Redisson,lcok、tryLock(背后原理也是Redis)
本文主要介绍一下Redis和Redisson的分布式事务锁的原理。
2、Redis 搭建模式
Redis 的搭建方式:
- 单机
- 主从
- 哨兵
- 集群
单机,只要一台Redis服务器,挂了就无法工作了
主从,是备份关系, 数据也会同步到从库,还可以读写分离
哨兵:master挂了,哨兵就行选举,选出新的master,作用是监控主从,主从切换
集群:高可用,分散请求。目的是将数据分片存储,节省内存。
单机:

主从:

哨兵:

集群:
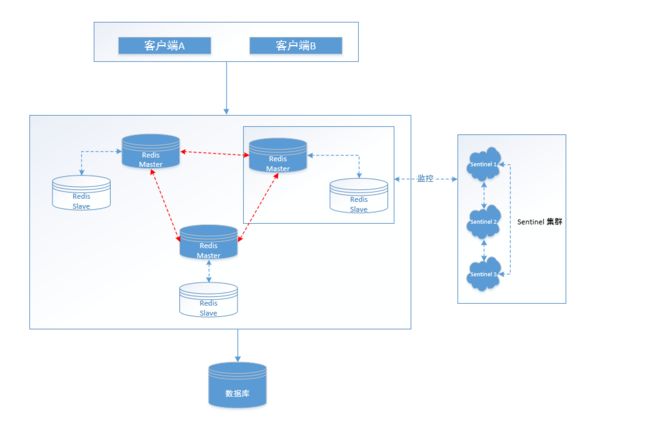
3、几个概念
分布式:简单来说就是将业务进行拆分,部署到不同的机器来协调处理。比如用户在网上买东西,大致分为:订单系统、库存系统、支付系统、、、、这些系统共同来完成用户买东西这个业务操作。
集群:同一个业务,通过部署多个实例来完成,保证应用的高可用,如果其中某个实例挂了,业务仍然可以正常进行,通常集群和分布式配合使用。来保证系统的高可用、高性能。
分布式事务:按照传统的系统架构,下单、扣库存等等,这一系列的操作都是一在一个应用一个数据库中完成的,也就是说保证了事务的ACID特性。如果在分布式应用中就会涉及到跨应用、跨库。这样就涉及到了分布式事务,就要考虑怎么保证这一系列的操作要么都成功要么都失败。保证数据的一致性。
**分布式锁:**因为资源有限,要通过互斥来保持一致性,引入分布式事务锁。
4、Redis分布式锁原理
简单的来说,其实现原理如下:
-
互斥性
-
- 保证同一时间只有一个客户端可以拿到锁。
-
安全性
-
- 只有加锁的服务才能有解锁权限,也就是不能让客户端A加的锁,客户端B、C 都可以解锁。
-
避免死锁
-
保证加锁与解锁操作是原子性操作
-
- 这个其实属于是实现分布式锁的问题,假设a用redis实现分布式锁
- 假设加锁操作,操作步骤分为两步:1,设置key set(key,value) 2,给key设置过期时间
-
- 假设现在a刚实现set后,程序崩了就导致了没给key设置过期时间就导致key一直存在就发生了死锁。
讲了这么多,Redis实现分布式锁的核心就是:
加锁:
SET key value NX EX timeOut
参数解释:
NX:只有这个key不存才的时候才会进行操作,即 if not exists;
EX:设置key的过期时间为秒,具体时间由第5个参数决定
timeOut:设置过期时间保证不会出现死锁【避免宕机死锁】
代码实现:
public Boolean lock(String key,String value,Long timeOut){
String var1 = jedis.set(key,value,"NX","EX",timeOut); //加锁,设置超时时间 原子性操作
if(LOCK_SUCCESS.equals(var1)){
return true;
}
return false;
}
总的来说,执行上面的set()方法就只会导致两种结果:
- 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。
- 已有锁存在,不做任何操作。
注:从2.6.12版本后, 就可以使用set来获取锁、Lua 脚本来释放锁。setnx是以前刚开始的实现方式,set命令nx、xx等参数,,就是为了实现 setnx 的功能。
解锁:
代码实现:
public Boolean redisUnLock(String key, String value) {
String luaScript = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object var2 = jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value));
if (UNLOCK_SUCCESS == var2) {
return true;
}
return false;
}
这段lua代码的意思:首先获取锁对应的value值,检查是否与输入的value相等,如果相等则删除锁(解锁)。
上面加锁、解锁,看着是挺麻烦的,所以就出现了Redisson。
5、Redisson 分布式锁原理
官方介绍:
Redisson是一个在Redis的基础上实现的Java驻内存数据网格。
就是在Redis的基础上封装了很多功能,以便于我们更方便的使用。
只需要三行代码:
RLock lock = redisson.getLock("myLock");
lock.lock(); //加锁
lock.unlock(); //解锁
(1)加锁机制
加锁流程:

redisson的lock()、tryLock()方法 底层 其实是发送一段lua脚本到一台服务器:
if (redis.call('exists' KEYS[1]) == 0) then + -- exists 判断key是否存在
redis.call('hset' KEYS[1] ARGV[2] 1); + --如果不存在,hset存哈希表
redis.call('pexpire' KEYS[1] ARGV[1]); + --设置过期时间
return nil; + -- 返回null 就是加锁成功
end; +
if (redis.call('hexists' KEYS[1] ARGV[2]) == 1) then + -- 如果key存在,查看哈希表中是否存在(当前线程)
redis.call('hincrby' KEYS[1] ARGV[2] 1); + -- 给哈希中的key加1,代表重入1次,以此类推
redis.call('pexpire' KEYS[1] ARGV[1]); + -- 重设过期时间
return nil; +
end; +
return redis.call('pttl' KEYS[1]); --如果前面的if都没进去,说明ARGV[2]的值不同,也就是不是同一线程的锁,这时候直接返回该锁的过期时间
参数解释:
KEYS[1]:即加锁的key,
RLock lock = redisson.getLock("myLock"); 中的myLockARGV[1]:即 TimeOut 锁key的默认生存时间,默认30秒
**ARGV[2]:**代表的是加锁的客户端的ID,类似于这样的:
99ead457-bd16-4ec0-81b6-9b7c73546469:1
其中lock()默认是30秒的生存时间。
(2)锁互斥
假如客户端A已经拿到了 myLock,现在 有一客户端(未知) 想进入:
1、第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
2、第二个if判断,判断一下,myLock锁key的hash数据结构中, 如果是客户端A重新请求,证明当前是同一个客户端同一个线程重新进入,所以可从入标志+1,重新刷新生存时间(可重入); 否则进入下一个if。
3、第三个if判断,客户端B 会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
此时客户端B会进入一个while循环,不停的尝试加锁。
(3)watch dog 看门狗自动延期机制
官方介绍:
lockWatchdogTimeout(监控锁的看门狗超时,单位:毫秒)
默认值:30000
监控锁的看门狗超时时间单位为毫秒。该参数只适用于分布式锁的加锁请求中未明确使用leaseTimeout参数的情况。(如果设置了leaseTimeout那就会自动失效了呀~)
看门狗的时间可以自定义设置:
config.setLockWatchdogTimeout(30000);
看门狗有什么用呢?
假如客户端A在超时时间内还没执行完毕怎么办呢? redisson于是提供了这个看门狗,如果还没执行完毕,监听到这个客户端A的线程还持有锁,就去续期,默认是 LockWatchdogTimeout/ 3 即 10 秒监听一次,如果还持有,就不断的延长锁的有效期(重新给锁设置过期时间,30s)
可以在lock的参数里面指定:
lock.lock(); //如果不设置,默认的生存时间是30s,启动看门狗
lock.lock(10, TimeUnit.SECONDS);//10秒以后自动解锁,不启动看门狗,锁到期不续
如果是使用了可重入锁( leaseTimeout):
lock.tryLock(); //如果不设置,默认的生存时间是30s,启动看门狗
lock.tryLock(100, 10, TimeUnit.SECONDS);//尝试加锁最多等待100秒,上锁以后10秒自动解锁,不启动看门狗
这里的第二个参数leaseTimeout 设置为 10 就会覆盖 看门狗的设置(看门狗无效),在10秒后锁就自动失效,不会去续期;如果是 -1 ,就表示 使用看门狗的默认值。
(4)释放锁机制
lock.unlock(),就可以释放分布式锁。就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从redis里删除这个key。
为了安全,会先校验是否持有锁再释放,防止
- 业务执行还没执行完,锁到期了。(此时没占用锁,再unlock就会报错)
- 主线程异常退出、或者假死
finally {
if (rLock.isLocked()) {
if (rLock.isHeldByCurrentThread()) {
rLock.unlock();
}
}
}
(5) 缺点
如果是 主从、哨兵模式,当客户端A 把 myLock这个锁 key 的value写入了 master,此时会异步复制给slave实例。
万一在这个主从复制的过程中 master 宕机了,主备切换,slave 变成了master。
那么这个时候 slave还没来得及加锁,此时 客户端A的myLock的 值是没有的,客户端B在请求时,myLock却成功为自己加了锁。这时候分布式锁就失效了,就会导致数据有问题。
所以说Redis分布式说最大的缺点就是宕机导致多个客户端加锁,导致脏数据,不过这种几率还是很小的。
参考:
- https://www.cnblogs.com/demingblog/p/10295236.html
- http://www.voidcc.com/redisson/redisson-single-sentinel-mode-configuration
- https://juejin.im/post/6844903874675867656