MybatisPlus 知识点总结
文章目录
- 一、MyBatisPlus概述
- 二、快速入门
- 三、CURD
-
- 3.1 insert插入操作
- 3.2 update 更新操作
- 3.3 delete删除操作
-
- 3.3.1 普通删除
- 3.3.2 逻辑删除
- 3.4 select查询方法
-
- 3.4.1 基本查询
- 3.4.2 分页查询
- 四、性能分析插件
一、MyBatisPlus概述
需要的基础:把我的MyBatis、Spring、SpringMVC就可以学习这个了!
为什么要学习它呢?MyBatisPlus可以节省我们大量工作时间,所有的CRUD代码它都可以自动化完成!
MyBatisPlus特性
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作,BaseMapper
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分CRUD 操作,更有强大的条件构造器,满足各类使用需求, 以后简单的CRUD操作,它不用自己编写了!
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用(自动帮你生成代码)
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、
Postgre、SQLServer 等多种数据库
内置性能分析插件:可输出 Sql 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢
查询
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
二、快速入门
地址:https://mp.baomidou.com/guide/quick-start.html#初始化工程
使用第三方组件:
1、导入对应的依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
2、研究依赖如何配置
3、代码如何编写
4、提高扩展技术能力
1、创建数据库 mybatis_plus
2、创建user表
3、编写项目,初始化项目,使用SpringBoot初始化
4、导入依赖
5、连接数据库,这一步和 mybatis 相同
6、传统方式pojo-dao(连接mybatis,配置mapper.xml文件)-service-controller
7、使用了mybatis-plus 之后
pojo
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
private static final long serialVersionUID = 810655175047208129L;
/**
* 主键ID
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 邮箱
*/
private String email;
@TableField(fill = FieldFill.INSERT)
private Date createTime;
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
@Version //乐观锁Version注解
private Integer version;
@TableLogic //逻辑删除
private Integer deleted;
mapper接口
@Mapper
public interface UserMapper extends BaseMapper<User> {}
注意点,我们需要在主启动类上去扫描我们的mapper包下的所有接口,如果扫描不到会报Mapper没有注入Bean的错误
@MapperScan("com.sys.mm.mapper")
8、 测试类
@SpringBootTest
class MmApplicationTests {
@Resource
private UserMapper userMapper;
@Test
public void test() {
System.out.println(("----- selectAll method test ------"));
List<User> userList = userMapper.selectList(null);
userList.forEach(System.out::println);
}
}
9、配置日志
# 配置日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
三、CURD
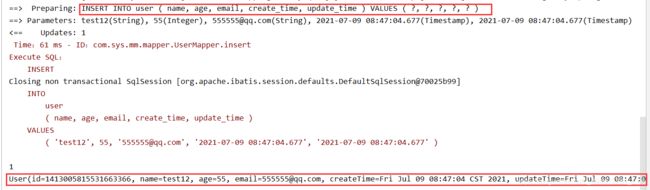
3.1 insert插入操作
@Test
void test1(){
User user = new User();
user.setAge(55);
user.setEmail("[email protected]");
user.setName("test12");
int i = userMapper.insert(user);
System.out.println(i);
System.out.println(user);
}
数据库插入的id的默认值为:全局的唯一id
主键生成策略 --雪花算法
我们需要配置主键自增:
1、实体类字段上 @TableId(type = IdType.AUTO)
2、数据库字段一定要是自增
3、测试插入即可
对应的源码解释
public enum IdType {
AUTO(0), // 数据库id自增
NONE(1), // 未设置主键
INPUT(2), // 手动输入
ID_WORKER(3), // 默认的全局唯一id
UUID(4), // 全局唯一id uuid
ID_WORKER_STR(5); //ID_WORKER 字符串表示法
}
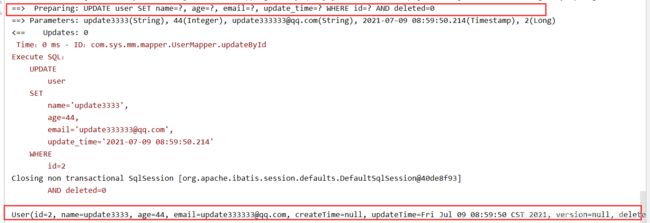
3.2 update 更新操作
@Test
void test2(){
User user = new User();
user.setAge(44);
user.setEmail("[email protected]");
user.setName("update3333");
user.setId(2L);
int i = userMapper.updateById(user);
System.out.println(user);
System.out.println(i);
}
3.3 delete删除操作
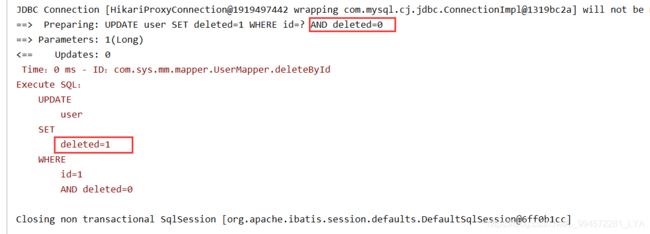
3.3.1 普通删除
// 测试删除
@Test
public void testDeleteById(){
userMapper.deleteById(1L);
}
// 通过id批量删除
@Test
public void testDeleteBatchId(){
userMapper.deleteBatchIds(Arrays.asList(2L,3L));
}
// 通过map删除
@Test
public void testDeleteMap() {
HashMap<String, Object> map = new HashMap<>();
map.put("name", "Billie");
userMapper.deleteByMap(map);
}
3.3.2 逻辑删除
物理删除 :从数据库中直接移除
逻辑删除 :再数据库中没有被移除,而是通过一个变量来让他失效! deleted = 0 => deleted = 1
管理员可以查看被删除的记录!防止数据的丢失,类似于回收站
1、在数据表中增加一个 deleted 字段
2、实体类中增加属性
@TableLogic //逻辑删除
private Integer deleted;
3、配置
// 逻辑删除组件!
@Bean
public ISqlInjector sqlInjector() {
return new LogicSqlInjector();
}
4、测试删除
# 配置逻辑删除
mybatis-plus.global-config.db-config.logic-delete-value=1
mybatis-plus.global-config.db-config.logic-not-delete-value=0
3.4 select查询方法
3.4.1 基本查询
// 测试查询
@Test
public void testSelectById(){
User user = userMapper.selectById(1L);
System.out.println(user);
}
// 测试批量查询!
@Test
public void testSelectByBatchId(){
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
users.forEach(System.out::println);
}
// 按条件查询之一使用map操作
@Test
public void testSelectByBatchIds(){
HashMap<String, Object> map = new HashMap<>();
// 自定义要查询
map.put("name","Java1");
map.put("age",13);
List<User> users = userMapper.selectByMap(map);
users.forEach(System.out::println);
}
void contextLoads() {
// 查询name不为空的用户,并且邮箱不为空的用户,年龄大于等于12
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper
.isNotNull(User::getName)
.isNotNull(User::getEmail)
.eq(User::getName,"test12")
.between(User::getAge,30,80)
.ge(User::getVersion,0);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
users.forEach(System.out::println);
}
// 模糊查询
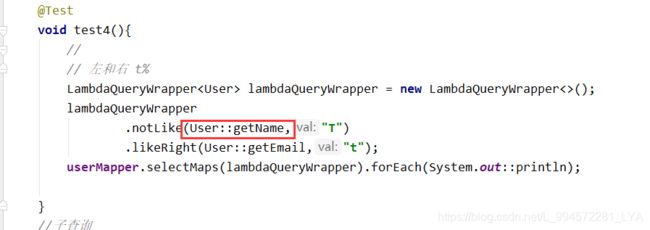
@Test
void test4(){
//
// 左和右 t%
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper
.notLike(User::getName,"T")
.likeRight(User::getEmail,"t");
userMapper.selectMaps(lambdaQueryWrapper).forEach(System.out::println);
}
//子查询
@Test
void test5(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.inSql(User::getAge,"select age from User where age >30 ");
userMapper.selectMaps(lambdaQueryWrapper).forEach(System.out::println);
}
//排序
@Test
void test6(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.orderByAsc(User::getAge);
userMapper.selectList(lambdaQueryWrapper).forEach(System.out::println);
}
运用Wapper做查询时,LambdaQueryWrapper与QueryWrapper区别是LambdaQueryWrapper在方法里可以直接如图
直接获取数据库字段名称。但是QueryWrapper则需要手动输入如图
3.4.2 分页查询
1、配置拦截器组件
// 分页插件
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
2、直接使用Page对象
// 测试分页查询
@Test
public void testPage(){
// 参数一:当前页
// 参数二:页面大小
// 使用了分页插件之后,所有的分页操作也变得简单的!
Page<User> page = new Page<>(1,5);
userMapper.selectPage(page,null);
page.getRecords().forEach(System.out::println);
System.out.println(page.getTotal());
}
四、性能分析插件
我们在平时的开发中,会遇到一些慢sql。测试! druid,
作用:性能分析拦截器,用于输出每条 SQL 语句及其执行时间
MP也提供性能分析插件,如果超过这个时间就停止运行
1、导入插件
/**
* SQL执行效率插件
*/
@Bean
@Profile({"dev","test"})// 设置 dev test 环境开启,保证我们的效率
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor performanceInterceptor = new
PerformanceInterceptor();
performanceInterceptor.setMaxTime(100); // ms设置sql执行的最大时间,如果超过了则不
执行
performanceInterceptor.setFormat(true); // 是否格式化代码
return performanceInterceptor;
}
在SpringBoot中配置环境为dev或者 test 环境
2、测试使用
@Test
void contextLoads() {
// 参数是一个 Wrapper ,条件构造器,这里我们先不用 null
// 查询全部用户
List<User> users = userMapper.selectList(null);
users.forEach(System.out::println);
}
