【MySQL · Innodb架构简析】三、Innodb Indexes
本文内容主要是人工翻译自MySQL5.7官网手册——Innodb索引部分,读者可以结合官文手册阅读。如有错误请指出,感谢阅读,欢迎讨论!
1. Innodb聚簇索引和二级索引
每个Innodb表都有一个特殊的索引叫做聚簇索引,它存储了全部的行数据。一般来说,聚簇索引就等同于主键,所以一张表只能有一个聚簇索引。设计聚簇索引的目的是优化表的增删改查操作,所以理解其中原理很重要。
- 当你给表定义一个主键的时候,Innodb就会用它作为聚簇索引。
- 如果你没有定义主键,Innodb会使用第一个
unique非null索引列作为聚簇索引 - 如果你没有定义任何索引,Innodb就会生成一个隐藏的叫做
GEN_CLUST_INDEX的聚簇索引,它由隐藏的6-byte的RowID列组成,具有单调递增的属性。所以在物理上,行排列的顺序是由RowID决定。
1.1 聚簇索引如何加速查询
先把它当做普通索引使用,Innodb引擎通过主键条件搜索到对应页后,因为索引页包含了完全行数据,所以无需通过主键做二次查找,可直接返回数据,最多只有一次磁盘I/O。
1.2 二级索引如何关联聚簇索引
与聚簇索引形成对比的就是二级索引。后者的索引页中包含了被索引的列以及对应主键列,所以通过二级索引查找到对应的主键列后,再通过主键列在聚簇索引中找到对应数据,最多两次磁盘I/O。
如果主键很长,那么二级索引也会使用更多空间,建议使用更短的主键(根据需要,2021年,空间不是首要考虑因素)。
关于更多聚簇索引和二级索引的优点,参考这里
2. Innodb索引的物理结构
除了空间索引是使用R-tree,Innodb的索引都是B-tree结构。R-tree用于索引多维数据。不管是R-tree或是B-tree,索引记录都是存储在它们的叶子节点。默认索引页大小是16KB,由参数innodb_page_size在mysql启动时指定。
当新数据插入innodb聚簇索引时,innodb会留下1/16的页面空间来存放以后的插入和更新。如果索引数据是顺序插入的,那单个索引页的填充率约为15/16;若是随机插入,则为1/2 到 15/16;意思是随机插入不能很好的利用页空间,容易产生页分裂。
Innodb在创建和重建B-tree索引时是执行批量加载,这种创建方式叫做有序索引构建。参数innodb_fill_factor定义了有序索引构建时每个B-tree索引页的填充空间百分比,剩余空间用于以后的索引增长。有序索引不支持空间索引类型。关于有序索引在下面说明。比如innodb_fill_factor设置为100,那就留1/16的聚簇索引页空间给以后的索引增长。(这1/16是必留的)
如果填充因子低于MERGE_THRESHOLD(默认50%,可指定),innodb会尝试收缩索引树以释放页。MERGE_THRESHOLD应用于B-tree和R-tree。更多关于merge_threshold
3. 有序索引构建
上面说过,Innodb在创建和重建B-tree索引时是执行批量加载,这种创建方式叫做有序索引构建。
索引构建有3个阶段:
- step1:扫描聚簇索引,生成索引条目并添加到sort buffer,当buffer满了后,有序过的索引条目写入到一个临时中间文件,这个过程叫做
run - step2:在一次或多次写入到临时文件后,再对文件内的所有条目执行归并有序
- step3:将排好序的索引条目插入B-tree
在介绍有序索引构建之前,索引条目一般使用insert API一次插入一条记录到B-tree,这个过程涉及到打开一个B-tree指针,然后找到插入位置,再使用乐观方式插入B-tree页。但如果页满而插入失败,就会再执行一次悲观方式的插入,悲观方式一般就涉及到B-tree节点的分裂和合并。这种自顶向下的索引构建方式的主要成本在于:找到插入位置,以及经常性的分裂和合并B-tree节点。
有序索引构建采用的是自下而上的方式。这部分的描述主要是将索引B-tree的插入动态过程,但非常不好理解,建议还是阅读原文。
With this approach, a reference to the right-most leaf page is held at all levels of the B-tree. The right-most leaf page at the necessary B-tree depth is allocated and entries are inserted according to their sorted order. Once a leaf page is full, a node pointer is appended to the parent page and a sibling leaf page is allocated for the next insert. This process continues until all entries are inserted, which may result in inserts up to the root level. When a sibling page is allocated, the reference to the previously pinned leaf page is released, and the newly allocated leaf page becomes the right-most leaf page and new default insert location.
3.1 预留空间给未来索引扩增
上面已经讲过,略。
3.2 有序索引构建和全文索引支持
全文索引支持有序索引构建。以前,SQL 用于将条目插入到全文索引中(后半句博主也不太理解,不过无大碍)。
3.3 有序索引构建和Redo logging
在有序索引构建过程中,redo log是禁用的,有一个checkpoint来确保索引构建可以承受意外退出或失败。检查点强制将所有脏页写入磁盘。在有序索引构建期间,page cleaner线程会定期收到信号以刷新脏页面,以确保可以快速处理检查点操作。通常,当clean-page的数量低于设置的阈值时,page cleaner线程会刷新脏页面。对于有序索引构建,脏页会被及时刷盘以减少checkpoint开销,和并行 I/O 和 CPU 活动。
博主注:这段话描述的比较概括,读者需要先了解redo log的checkpoint机制,才能更好理解。
3.4 有序索引构建和优化器统计
排序索引构建可能会导致优化器统计信息与以前的索引创建方法生成的统计信息不同。统计数据的差异(预计不会影响工作负载性能)是由于用于填充索引的算法不同。
4. Innodb全文索引
全文索引是创建在文本列上的,比如char,varchar,text,它可以加速表的CRUD操作。
创建方式和其他索引类似,可以通过create table , alter table , create index几个语句创建。全文搜索的语法是match() ... against,详细用法参考这里。
4.1 全文索引的设计
InnoDB全文索引采用倒排索引设计。倒排索引存储的是一系列单词列表,这些单词都是从字段中抽出来的。为了支持邻近搜索,还将每个单词的位置信息存储为字节偏移量。
4.2 全文索引表
创建 InnoDB 全文索引时,会创建一组索引表,如下例所示:
mysql> CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200),
FULLTEXT idx (opening_line)
) ENGINE=InnoDB;
mysql> SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_SYS_TABLES
WHERE name LIKE 'test/%';
+----------+----------------------------------------------------+-------+
| table_id | name | space |
+----------+----------------------------------------------------+-------+
| 333 | test/FTS_0000000000000147_00000000000001c9_INDEX_1 | 289 |
| 334 | test/FTS_0000000000000147_00000000000001c9_INDEX_2 | 290 |
| 335 | test/FTS_0000000000000147_00000000000001c9_INDEX_3 | 291 |
| 336 | test/FTS_0000000000000147_00000000000001c9_INDEX_4 | 292 |
| 337 | test/FTS_0000000000000147_00000000000001c9_INDEX_5 | 293 |
| 338 | test/FTS_0000000000000147_00000000000001c9_INDEX_6 | 294 |
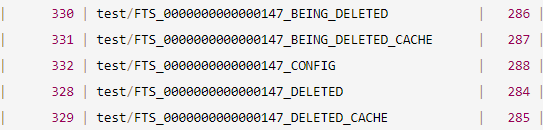
| 330 | test/FTS_0000000000000147_BEING_DELETED | 286 |
| 331 | test/FTS_0000000000000147_BEING_DELETED_CACHE | 287 |
| 332 | test/FTS_0000000000000147_CONFIG | 288 |
| 328 | test/FTS_0000000000000147_DELETED | 284 |
| 329 | test/FTS_0000000000000147_DELETED_CACHE | 285 |
| 327 | test/opening_lines | 283 |
+----------+----------------------------------------------------+-------+
opening_lines是我们定义的表,叫做主表,或者被索引的表。
前六个索引表构成倒排索引,称为辅助索引表。当插入的数据被token化(分词)时,单个词(也称为token)与位置信息和关联的DOC_ID一起插入索引表中。插入时根据单词的第一个字符的字符集排序,在六个索引表中对单词进行完全排序和分区。
博主注;在全文索引环境中,MySQL将row称为document(doc),所以doc_id就是row_id;doc会被用来分词,分好的词被称为token
倒排索引被分区为六个辅助索引表,以支持并行索引创建。默认情况下,两个线程对单词和相关数据进行分词、排序和插入到索引表中。如果是较大的表(索引字段size较大),可以考虑增大innodb_ft_sort_pll_degree以增加工作线程数,默认是2。
可以看到,每个辅助索引表名的格式是FTS_000***_000***_INDEX_#。而每个辅助索引表是通过其表名中的十六进制数 和 table_id 来与索引表关联的。
例如,test/opening_lines表的table_id是327,对应十六进制为0x147。所以此表关联的辅助索引表是FTS_000147_000***_INDEX_#,也在查询结果中。
这个出现在辅助索引表名中的十六进制数,同样也是全文索引的index_id。例如,test/FTS_0000000000000147_00000000000001c9_INDEX_1其中的1c9换为十进制是457,则可以通过查询INFORMATION_SCHEMA.INNODB_SYS_INDEXES 表以获取此值 (457) 来识别在 opening_lines表 (idx) 上定义的索引。
博主注:手册的描述也是不够清晰的。可见,这里有两个概念,一个是“索引表”,另一个是与之关联的多个“辅助索引表”,关联方式就先不用记了。这里的十六进制数有2个,对应辅助表名中的000A_000B,根据上文描述,这两个十六进制数都是用来起关联作用的。
mysql> SELECT index_id, name, table_id, space from INFORMATION_SCHEMA.INNODB_SYS_INDEXES
WHERE index_id=457;
+----------+------+----------+-------+
| index_id | name | table_id | space |
+----------+------+----------+-------+
| 457 | idx | 327 | 283 |
+----------+------+----------+-------+
如果主表存储的表空间是file_per_table的,则这些索引表也是存在单独的表空间。否则就是存在主表所存的位置。
前面示例中显示的其他索引表称为公共索引表,用于删除处理和存储全文索引的内部状态。例如:
这些表同样可存储其他包含全文索引列的表的相关数据。
删除全文索引时,会保留为该索引创建的 FTS_DOC_ID列,因为删除 FTS_DOC_ID列将需要重建先前索引的表。
FTS_*_DELETED and FTS_*_DELETED_CACHE表
这两个表存储了已经从主表删除的记录的索引列的分词的doc_id。FTS_*_DELETED_CACHE是FTS_*_DELETED的内存版本(缓存)。FTS_*_BEING_DELETED and FTS_*_BEING_DELETED_CACHE
这两个表存储了已经从主表删除的记录,但其索引列的分词正在被删除的doc_id。同样,后者是前者的内存版本。FTS_*_CONFIG
存储了全文索引的内部状态。最重要的,它存了FTS_SYNCED_DOC_ID,此ID标识了一个已经分词并刷盘的doc_id。在crash恢复的时候,此ID用来标识那些还没有刷盘的doc,以便能将那些doc再次解析并写入全文索引缓存。我们可以通过查询INFORMATION_SCHEMA.INNODB_FT_CONFIG来查看数据。(博主注:这里逻辑貌似不通?)
4.3 全文索引缓存
当一个doc插入时,它会被分词,然后将每个词以及关联数据插入全文索引表中。这个过程中,即使是小的doc,也会好几次轻量的辅助索引表插入操作,简言之就是写入慢。为了避免此问题,Innodb使用了全文索引缓存来加速索引的插入操作。缓存会一直保存插入数据直到缓存满了被批量刷盘(刷到辅助索引表)。我们可以通过查询INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE来查看数据。
这个缓存还可以避免同一个词的多次插入,最小化条目重复问题。
变量innodb_ft_cache_size可以配置每张表的全文索引的可用缓存空间大小限制。
变量innodb_ft_total_cache_size可以配置全局的所有表加起来的可用缓存空间大小限制。
有一点需要注意,缓存只存储最近插入数据的分词数据,并且查询并不会将磁盘中的索引数据载入缓存。所以,每次查询都是直接查缓存+查磁盘索引,将二者结果合并后返回。
4.4 DOC_ID 和 FTS_DOC_ID
InnoDB 使用称为DOC_ID的唯一文档标识符将全文索引中的单词映射到该单词出现的文档记录。映射还需要索引表的FTS_DOC_ID列,如果未定义,mysql会在全文索引创建时自动添加一个隐藏的FTS_DOC_ID列。
例如下表,没有定义该列:
mysql> CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200)
) ENGINE=InnoDB;
在你创建全文索引的时候,会出现一个warning,那就是mysql在自动创建FTS_DOC_ID列
mysql> CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);
Query OK, 0 rows affected, 1 warning (0.19 sec)
Records: 0 Duplicates: 0 Warnings: 1
mysql> SHOW WARNINGS;
+---------+------+--------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------+
| Warning | 124 | InnoDB rebuilding table to add column FTS_DOC_ID |
+---------+------+--------------------------------------------------+
同样的,alter table语句创建全文索引也会有这个warning,但create table方式创建全文索引时是没有的。
显然,在 CREATE TABLE 时定义 FTS_DOC_ID 列比在已加载数据的表上创建全文索引成本更低,因为不需要改表。当然,一般情况下,我们就可以不考虑这点性能损失。
如果我们要自己创建该字段的话,必须是BIGINT UNSIGNED NOT NULL,字段名必须是FTS_DOC_ID,且全大写。auto_increment是非必要,加上可以提高部分性能。如下:
mysql> CREATE TABLE opening_lines (
FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200)
) ENGINE=InnoDB;
如果要自行添加该列,就要对这列的数据正确性负责,不能为空不能重复。我们可以可选的给这列添加一个unique索引FTS_DOC_ID_INDEX。
mysql> CREATE UNIQUE INDEX FTS_DOC_ID_INDEX on opening_lines(FTS_DOC_ID);
但其实不用,因为Innodb会自动添加。
在 MySQL 5.7.13 之前,最大使用的 FTS_DOC_ID值和新的 FTS_DOC_ID值之间允许的差距为 10000。在 MySQL 5.7.13 及更高版本中,允许的差距为 65535。(博主也没看太懂这句话,但感觉不需要太关心)
为了避免重建表,所以即使后面再删除全文索引,也不会删除
FTS_DOC_ID列。
4.5 全文索引的删除处理(优化)
与上文所说的插入记录会多次更新索引表导致性能降低类似,删除记录也会这个情况。为了优化,Innodb将被删除记录的DOC_ID记录到前面说的FTS_*_DELETED表,在查询返回结果前,会将辅助索引表中查到的DOC_ID拿到该表中过滤。这样的好处是删除快且低开销,缺点是删除记录后,索引数据不会立即删除。想要删除无效记录的索引数据,前提要设置innodb_optimize_fulltext_only=ON,然后执行命令:OPTIMIZE TABLE XXX,关于全文索引的优化,参考这里。
4.6 全文索引的事务处理
由于全文索引的缓存和批量操作,所以它有一些特定的事务特征。 具体来说,全文索引上的更新和插入在事务提交时处理,意思是说,全文搜索只能看到提交后的数据。
演示略。
4.7 监控全文索引
监控INFORMATION_SCHEMA库下面这些表:
- INNODB_FT_CONFIG
- INNODB_FT_INDEX_TABLE
- INNODB_FT_INDEX_CACHE
- INNODB_FT_DEFAULT_STOPWORD
- INNODB_FT_DELETED
- INNODB_FT_BEING_DELETED
也可以通过INNODB_SYS_INDEXESand INNODB_SYS_TABLES查看全文索引的基本信息。
5.扩展(非官方内容)
此处内容引用自link
stopword 列表(stopword list)表示该列表中的 word 不需要对其进行索引分词操作。InnoDB 存储引擎有一张默认的 stopword 列表,其在information_schema.INNODB_FT_DEFAULT_STOPWORD下 ,默认共用 36 个 stopword。
此外用户也可以通过参数 innodb_ft_server_stopword_table 来自定义 stopword 列表:
SHOW GLOBAL VARIABLES LIKE 'innodb_ft_server_stopword_table';
SET GLOBAL innodb_ft_server_stopword_table = '库/表';
当前 InnoDB 存储引擎的全文索引还存在以下的限制:
- 每张表只能有一个全文检索的索引;
- 由多个组合而成的全文索引列必须使用相同的字符集和排序规则;
不支持没有单词界定符(delimiter)的语言,如中文、日语、韩语等。MySQL5.7.6起提供的ngram全文解析器支持对中文、日语、韩语进行分词。