机器学习Sklearn实战——决策树算法
sklearn-str类型数据量化操作
OrdinalEncoder
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import OrdinalEncoder,OneHotEncoder,LabelEncoder
salary = pd.read_csv("/Users/zhucan/Desktop/salary.txt")
salary.drop(labels=["final_weight","education_num","capital_gain","capital_loss"],axis = 1,inplace=True)
ordinalEncoder = OrdinalEncoder()
data = ordinalEncoder.fit_transform(salary)
u = salary["education"].unique()
uarray(['Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'], dtype=object)u.sort()
uarray(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object)salary_ordinal = pd.DataFrame(data,columns=salary.columns)
salary_ordinal.head()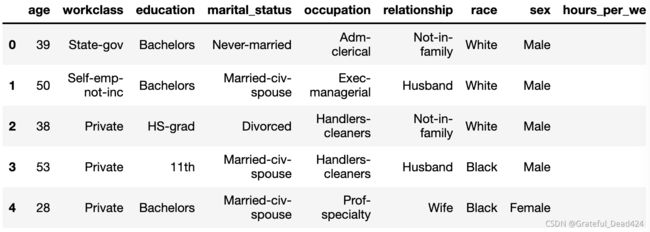

LabelEncoder
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import OrdinalEncoder,OneHotEncoder,LabelEncoder
salary = pd.read_csv("/Users/zhucan/Desktop/salary.txt")
salary.drop(labels=["final_weight","education_num","capital_gain","capital_loss"],axis = 1,inplace=True)
labelEncode = LabelEncoder()
salary_label = labelEncode.fit_transform(salary["education"]) #一列转换
for col in salary.columns:
salary[col] = labelEncode.fit_transform(salary[col])
salary
OnehotEncoder
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import OrdinalEncoder,OneHotEncoder,LabelEncoder
salary = pd.read_csv("/Users/zhucan/Desktop/salary.txt")
salary.drop(labels=["final_weight","education_num","capital_gain","capital_loss"],axis = 1,inplace=True)
edu = salary[["education"]]
onehotEncoder = OneHotEncoder()
onehot = onehotEncoder.fit_transform(edu)
# one-hot
onehot.toarray()[:10] #一共16列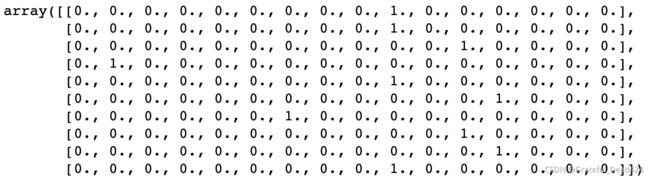
nd1.argmax(axis = 1)array([ 9, 9, 11, 1, 9, 12, 6, 11, 12, 9])

np.sort(edu.education.unique())array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object)
决策树的熵原理
熵或者基尼系数分裂




ID3——信息增益
C4.5——可以使用连续数据作为特征值
C5.0——准确率更高了
CART——和C4.5相似,但是支持回归
决策树的使用
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
iris = datasets.load_iris()
X = iris["data"]
y = iris["target"]
feature_names = iris.feature_names
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1024)
clf = DecisionTreeClassifier(criterion="entropy")
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
print(accuracy_score(y_test,y_))
plt.figure(figsize=(12,9),dpi=80)
tree.plot_tree(clf,filled = True,feature_names = feature_names)
39/120*np.log2(120/39)+42/120*np.log2(120/42)+39/120*np.log2(120/39)
1.5840680553754911决策树属性列分时计算
为什么一开始依靠petal_length<=2.6区分?
X_train.std(axis = 0)array([0.82300095, 0.42470578, 1.74587112, 0.75016619])第三列波动大选第三列
np.sort(X_train[:,2])array([1. , 1.1, 1.2, 1.2, 1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.4, 1.4, 1.4,
1.4, 1.4, 1.4, 1.4, 1.4, 1.4, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5,
1.5, 1.5, 1.5, 1.5, 1.5, 1.6, 1.6, 1.6, 1.7, 1.7, 1.7, 1.7, 1.9,
3.3, 3.5, 3.5, 3.6, 3.7, 3.8, 3.9, 3.9, 3.9, 4. , 4. , 4. , 4. ,
4.1, 4.1, 4.1, 4.2, 4.2, 4.2, 4.2, 4.3, 4.4, 4.4, 4.4, 4.5, 4.5,
4.5, 4.5, 4.5, 4.5, 4.5, 4.6, 4.6, 4.6, 4.7, 4.7, 4.7, 4.7, 4.8,
4.8, 4.8, 4.8, 4.9, 4.9, 4.9, 5. , 5. , 5. , 5.1, 5.1, 5.1, 5.1,
5.1, 5.1, 5.1, 5.2, 5.2, 5.3, 5.3, 5.4, 5.4, 5.5, 5.5, 5.5, 5.6,
5.6, 5.6, 5.7, 5.8, 5.9, 5.9, 6. , 6. , 6.1, 6.1, 6.1, 6.3, 6.4,
6.7, 6.7, 6.9])(1.9+3.3)/2=2.6
X_train[y_train != 0].std(axis = 0)array([0.66470906, 0.32769349, 0.80409522, 0.4143847 ])X_train2 = X_train[y_train != 0]
np.sort(X_train2[:,3])array([1. , 1. , 1. , 1. , 1. , 1. , 1.1, 1.1, 1.2, 1.2, 1.2, 1.2, 1.2,
1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.3, 1.4, 1.4, 1.4,
1.4, 1.4, 1.4, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5,
1.6, 1.6, 1.6, 1.6, 1.7, 1.7, 1.8, 1.8, 1.8, 1.8, 1.8, 1.8, 1.8,
1.8, 1.8, 1.9, 1.9, 1.9, 1.9, 1.9, 2. , 2. , 2. , 2. , 2. , 2.1,
2.1, 2.1, 2.1, 2.2, 2.2, 2.3, 2.3, 2.3, 2.3, 2.3, 2.3, 2.3, 2.3,
2.4, 2.5, 2.5])X_train2 = X_train[y_train != 0]
y_train2 = y_train[y_train!=0]
index = np.argsort(X_train2[:,3])
display(X_train[:,1][index])
y_train2[index]array([3. , 3.2, 3.2, 3.1, 3.5, 3.1, 3.7, 3. , 2.6, 3.6, 2.9, 3.8, 2.6,
3.4, 2.9, 2.8, 3.3, 3.1, 2.9, 2.8, 3.4, 3. , 3. , 2.4, 2.2, 3. ,
3.2, 3. , 3.1, 2.9, 3. , 2.9, 3.2, 3.4, 3.2, 2. , 3. , 2.5, 2.8,
3.3, 2.7, 2.9, 3.2, 2.7, 2.4, 3. , 3.5, 3.2, 2.8, 3. , 4. , 2.5,
3.8, 2.8, 2.7, 2.2, 3.7, 2.4, 2.7, 3.1, 2.8, 2.7, 2.8, 2.2, 3.6,
3.8, 3.3, 3.2, 3. , 3.8, 3. , 3. , 3.1, 3. , 2.8, 3.9, 2.8, 2.8,
3.2, 2.8, 3.4])
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 2, 2, 1, 1, 1, 2,
1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])属性
决策树gini系数
决策树进行数据处理的时候不需要对数据进行去量纲化,规划化,标准化

随机森林原理
100个原始样本,抽取样本可重复0,0,0,2,3,4......
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier
from sklearn import datasets
import pandas as pd
from sklearn.model_selection import train_test_split
wine =datasets.load_wine()
X = wine["data"]
y = wine["target"]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
clf = RandomForestClassifier()
clf.fit(X_train,y_train)
y_ = clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_)1.0